Java.lang深度剖析:解决常见问题的最佳实践案例
发布时间: 2024-09-24 16:29:35 阅读量: 176 订阅数: 43 

java.lang.NoSuchFieldError: Companion
# 1. Java.lang包概览和核心组件
在Java编程语言中,`java.lang`包扮演着至关重要的角色,它提供了一系列基础的核心类和接口,是几乎所有Java程序不可或缺的一部分。`java.lang`包中的类自动导入到每一个Java源文件中,因此开发者无需显式地导入即可使用其中的类。
## 1.1 Java.lang包的核心组件
`java.lang`包中包含了一些Java语言的基础类,如`Object`、`String`、`System`、`Math`和`Class`等。这些类是构建Java程序的基础。
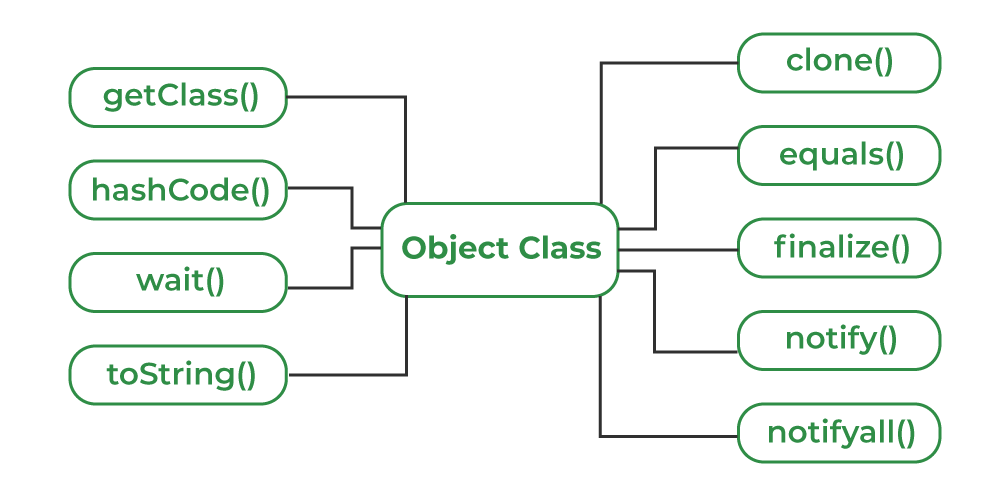
- `Object`类:它是所有类的根类,在面向对象编程中提供了一些基本的方法,比如`toString()`和`equals()`。
- `String`类:用于处理不可变的字符序列,它是Java中使用最频繁的类之一。
- `System`类:提供了一系列与系统相关的方法,比如用于输入输出的标准流对象。
- `Math`类:提供了执行基本数学运算的方法,如幂、平方根和三角函数等。
- `Class`类:代表了Java程序运行时的数据类型,提供了加载和反射等操作。
## 1.2 核心组件的实际应用
了解`java.lang`包中的核心组件,可以帮助开发者编写更优雅、高效的Java代码。例如:
```java
String message = "Hello, Java.lang!";
System.out.println(message.toUpperCase()); // 输出转换为大写的字符串
int a = 10;
int b = 20;
int sum = Math.addExact(a, b); // 使用Math类进行精确计算
```
通过这些核心组件,Java开发者能够构建稳定、高效的Java应用。本章将为读者深入剖析`java.lang`包中的这些核心组件,以及如何在实际开发中发挥它们的最大效用。
# 2. Java.lang包中的数据类型与类
### 2.1 基本数据类型的封装类
#### 2.1.1 封装类的设计初衷与使用场景
Java是一种面向对象的编程语言,在Java的世界里,几乎一切都被视为对象。然而,基本数据类型(如int, char, double等)并不遵循这一原则。为了弥补这种设计上的不足,Java提供了一系列的封装类(也称为包装类),这些类位于`java.lang`包中,为每种基本数据类型提供了一个对应的对象版本。
封装类的主要设计初衷包括:
1. 将基本数据类型包装为对象,使其能够享受对象的待遇。
2. 为基本数据类型添加了与面向对象相关的功能,比如方法和属性。
3. 使得基本数据类型能够在需要对象的上下文中使用,例如集合类。
使用场景包括但不限于:
- 使用泛型集合时,因为Java的泛型是基于擦除实现的,所以集合类不能直接存储基本类型,这时就需要封装类。
- 需要使用对象方法来操作基本类型数据,例如字符串表示形式(通过`toString()`方法)。
- 在并发编程中,因为基本数据类型不是线程安全的,使用封装类可以提供线程安全的属性。
### 2.1.2 自动装箱和拆箱机制解析
自动装箱和拆箱是Java提供的特性,允许开发者在基本类型和相应的封装类之间进行自动转换。
- **自动装箱**:将一个基本类型的值转换为对应的封装类对象。例如,将`int`类型的值`1`自动转换成`Integer`对象。
- **自动拆箱**:将一个封装类对象转换为对应的原始类型值。例如,将`Integer`对象转换成`int`。
自动装箱和拆箱的发生通常在以下几种情况下:
- 将基本类型赋值给封装类对象时。
- 将封装类对象赋值给基本类型时。
- 在进行算术运算时,如果涉及到封装类对象和基本类型的混合使用。
- 在调用方法或构造函数时,如果参数类型是基本类型或封装类。
自动装箱和拆箱在底层是通过调用封装类的`valueOf`和`intValue`等方法实现的。
```java
Integer i = 10; // 自动装箱
int iVal = i; // 自动拆箱
```
#### 代码逻辑分析:
在上述代码中,`10`是一个基本类型的`int`值,而`i`是一个`Integer`对象。在第一行代码中,`10`被自动装箱成了`Integer`对象。在第二行代码中,`i`被自动拆箱成了基本类型`int`值`iVal`。
自动装箱和拆箱简化了代码,使得开发者在使用基本数据类型和封装类之间切换时更加方便。但是,这也会带来性能影响和空指针异常的风险,特别是在频繁的自动装箱和拆箱过程中。
### 2.2 String和StringBuilder的性能比较
#### 2.2.1 String不可变性的深入解析
`String`类在Java中是最常见的类之一,它的一个显著特点是不可变性(immutable)。不可变性意味着一旦一个`String`对象被创建,它包含的字符序列就不能被改变。
不可变性的设计初衷包括:
1. 确保字符串在多线程环境中的安全性,因为不可变对象是线程安全的。
2. 便于实现字符串常量池,提高内存使用效率和性能。
因为`String`的不可变性,任何对字符串的修改操作都会生成一个新的`String`对象,而不是修改原有的对象。这样就保证了原对象的不可变性。
例如,字符串连接操作:
```java
String s = "Hello";
s += " World";
```
上述代码中,`s`在执行连接操作后会指向一个新的`String`对象,而不是在原有对象的基础上进行修改。
#### 2.2.2 StringBuilder和StringBuffer的选择与应用
当需要频繁修改字符串时,使用`String`类会导致大量不必要的对象创建,从而降低程序的性能。此时,`StringBuilder`和`StringBuffer`是更好的选择。
- `StringBuilder`:非线程安全,适用于单线程环境下对字符串的修改操作,速度快,性能高。
- `StringBuffer`:线程安全,适用于多线程环境下的字符串修改操作,速度比`StringBuilder`慢,因为它涉及到同步处理。
在单线程环境中,推荐使用`StringBuilder`,因为它提供了更快的执行速度和更高的性能。在多线程环境中,如果需要确保线程安全,则应选择`StringBuffer`。
#### 代码逻辑分析:
```java
StringBuilder sb = new StringBuilder("Hello");
sb.append(" World");
System.out.println(sb.toString());
```
在上述代码中,创建了一个`StringBuilder`对象`sb`并初始化为"Hello"。然后通过`append`方法将" World"添加到字符串末尾。最后,调用`toString`方法将`StringBuilder`对象转换成`String`对象并打印。
选择使用`StringBuilder`和`StringBuffer`时,需要权衡性能和线程安全的要求。在实际开发中,通常使用`StringBuilder`,因为大多数字符串操作不是在多线程环境中进行的。如果字符串操作在多线程环境中执行,应该使用`StringBuffer`或使用其他线程安全的方法,如`String.format`等。
### 2.3 Object类的通用方法和继承体系
#### 2.3.1 equals()和hashCode()的正确实现
`Object`类是所有Java类的根类。它提供了几个通用方法,如`equals()`, `hashCode()`, `toString()`, `getClass()`等。正确实现这些方法是所有自定义类的重要责任。
`equals()`方法用于判断两个对象是否逻辑上相等。默认实现比较的是两个对象的引用,而不是它们的内容。通常需要在子类中重写`equals()`方法以比较对象的内容。
`hashCode()`方法应该与`equals()`方法一起重写,确保符合"相等的对象必须具有相等的哈希码"这一约定。`hashCode()`的默认实现返回对象的内存地址。
例如,重写`equals()`和`hashCode()`方法的一个简单示例:
```java
public class Person {
private String name;
private int age;
// Constructor, getters and setters omitted for brevity
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null || getClass() != obj.getClass()) return false;
Person person = (Person) obj;
return age == person.age && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
```
#### 2.3.2 toString()方法的重写最佳实践
`toString()`方法用于返回对象的字符串表示形式。在调试时,这个方法非常有用,因为它可以提供对象状态的快速概览。
在自定义类中重写`toString()`方法时,应该包含对象的关键信息,并遵循易于阅读的格式,例如:
```java
@Override
public String toString() {
return "Person{name='" + name + "', age=" + age + '}';
}
```
#### 代码逻辑分析:
在上述代码中,`Person`类通过重写`toString()`方法,提供了一个格式化字符串,包含类名和属性。这样,当使用`System.out.println(person)`打印`Person`对象时,输出将是可读性强的"Person{name='John Doe', age=30}",而不是默认的`Person@15db9742`。
正确的重写`equals()`, `hashCode()`和`toString()`方法,可以使得自定义类的实例在集合操作、比较和调试时表现得更加合理和方便。这些方法的合理实现也符合Java的通用约定,有助于避免潜在的运行时问题。
# 3. Java.lang包中的异常处理机制
## 3.1 异常类层次结构及分类
### 3.1.1 运行时异常和检查型异常的区别
异常是Java程序中的一种错误处理机制,用于处理程序运行中出现的非预期情况,以保证程序的健壮性。Java的异常类都继承自`java.lang.Throwable`类。其中,异常类体系主要分为两大类:`RuntimeException`(运行时异常)和`Exception`(检查型异常)。
运行时异常(`RuntimeException`),顾名思义,是在程序运行时抛出的异常。这类异常的特点是在编译期不需要被强制处理,但如果在运行期发生,它们往往会导致程序的非正常终止。运行时异常通常指示了程序的逻辑错误,比如数组越界、空指针引用等。
检查型异常(`Exception`),是在编译时期需要被程序捕获或声明抛出的异常。这类异常通常由外部条件引起,如文件不存在、网络中断等,是可以预见的错误。它们不应该是程序逻辑的一部分,而是程序运行时环境的问题,因此它们的处理对程序的健壮性至关重要。
### 3.1.2 自定义异常的设计原则
在设计程序时,有时候内置的异常类不能完全满足我们的需求。在这种情况下,我们可能需要自定义异常。自定义异常可以提供更具体的错误信息和行为,有助于调用者更好地理解和处理错误情况。
设计自定义异常时,应该遵循以下原则:
- **继承合适的父类**:自定义异常通常继承自`Exception`或其子类。如果异常情况可以在运行时被修复,可以继承自`RuntimeException`。
- **合理分类**:可以定义多个层次的异常类,以便于异常处理时可以更精确地捕获异常。
- **异常信息清晰**:提供有意义的异常信息,有助于调试和错误处理。
- **异常处理方便**:自定义异常应设计得易于捕捉和处理,比如通过特定的异常类型、状态码等。
- **保持异常的线程安全**:如果异常的构造器中涉及到线程安全的操作,应确保这些操作是线程安全的。
自定义异常通常需要提供两个构造方法:一个是无参构造方法,另一个是带有详细错误信息的构造方法。此外,还可以提供一些自定义方法来扩展异常的可用功能。
```java
public class MyCustomException extends Exception {
public MyCustomException() {
super();
}
public MyCustomException(String message) {
super(message);
}
// 可以添加自定义方法来提供额外的功能
public void additionalFunctionality() {
// 实现额外功能
}
}
```
## 3.2 异常捕获与处理的最佳实践
### 3.2.1 try-catch-finally的使用策略
在Java中,异常捕获通常使用`try-catch-finally`结构。`try`块中包含可能抛出异常的代码,`catch`块用于捕获并处理异常,而`finally`块中的代码无论是否发生异常都会执行。
为了编写高质量的异常处理代码,应遵循以下最佳实践:
- **最小化`try`块**:仅将可能抛出异常的代码放入`try`块中,以减少异常捕获范围,提高代码可读性。
- **具体异常类型的捕获**:尽量捕获具体的异常类型,而不是捕获所有异常的基类。这样可以提供更明确的错误处理逻辑。
- **异常处理的完整性**:确保所有可能的异常都被妥善处理,避免因未处理的异常导致程序中断。
- **避免空的`catch`块**:空的`catch`块会隐藏异常信息,使得问题难以追踪。如果确实不需要处理异常,应至少记录异常信息。
示例代码:
```java
try {
// 代码块,其中可能抛出异常
} catch (SpecificException e) {
// 针对SpecificException的具体处理
} catch (Exception e) {
// 针对其他异常的默认处理
} finally {
// 无论是否发生异常都要执行的代码
}
```
### 3.2.2 异常链和异常信息的详细记录
异常链是一种将一个异常包装成另一个异常的技术,通常用于在捕获低级异常时,向调用者提供更高级别的异常信息。Java提供了`initCause()`和`getCause()`方法来支持异常链的构建。
异常信息的详细记录是异常处理中的重要组成部分,它能帮助开发者或运维人员快速定位问题。在记录异常信息时,应记录足够的上下文信息,包括但不限于:
- 异常的类型
- 异常发生的时间和地点
- 异常的堆栈跟踪信息
- 程序中相关的状态信息
- 输入和输出数据的详细内容
```java
try {
// 代码块,可能抛出异常
} catch (Exception e) {
throw new MyCustomException("处理异常时发生错误", e);
}
```
记录异常时,可以使用日志框架(如`java.util.logging`, `log4j`, `slf4j`等)来记录异常和堆栈跟踪信息。这些日志信息通常存储在文件、数据库或远程服务器上,便于分析和追踪。
## 3.3 异常与日志记录的结合
### 3.3.1 日志级别与异常记录的对应关系
在软件开发中,日志记录是用来记录程序运行时的各类信息的一种机制。日志级别定义了日志消息的重要程度和紧急程度,通常分为以下几种:DEBUG、INFO、WARN、ERROR和FATAL。
异常记录与日志级别有着密切关系,它们的对应关系如下:
- DEBUG:记录异常的详细信息,通常在调试时使用,不会影响程序的正常运行。
- INFO:记录异常发生的情况,但是不会导致系统故障的信息。
- WARN:记录可能会影响系统正常运行的异常,但这类异常并没有导致系统故障。
- ERROR:记录已经导致系统出现故障的异常,需要立即进行处理。
- FATAL:记录系统无法继续运行的致命错误,这类错误会导致程序立即终止。
在记录异常时,根据异常的严重程度选择合适的日志级别,可以帮助开发人员快速定位和解决问题。
示例代码:
```java
try {
// 可能会抛出异常的代码
} catch (Exception e) {
// 根据异常的类型和严重程度选择日志级别
log.error("发生严重错误", e);
}
```
### 3.3.2 使用日志框架处理异常的策略
为了有效地记录异常,推荐使用成熟的日志框架而不是直接使用Java内置的`System.out.println()`或`System.err.println()`方法。日志框架提供了更多的配置选项和灵活性,能够更方便地集成到不同的系统和环境之中。
在处理异常时,可以采取以下策略:
- **统一日志配置**:在一个应用中只使用一个日志框架,确保日志记录的一致性。
- **详细记录异常堆栈信息**:使用日志框架提供的异常记录方法,它可以自动捕获并记录异常的堆栈跟踪。
- **遵循日志规范**:遵循业界认可的日志记录规范,如SLF4J、Logback等,它们提供了丰富的日志记录功能和日志格式化工具。
```java
try {
// 代码块,可能抛出异常
} catch (Exception e) {
// 使用日志框架记录异常
logger.error("发生错误", e);
}
```
在记录异常时,还应遵循如下策略:
- 记录异常的名称、消息和堆栈跟踪信息。
- 避免记录过多的异常信息,以免影响日志的可读性。
- 定期分析和审查日志文件,以便及时发现并解决问题。
# 4. Java.lang包中的并发编程支持
在计算机科学领域,特别是在Java编程语言中,能够支持多线程并发操作是至关重要的。Java语言通过Java.lang包提供的并发编程支持,让开发者能够更好地管理和优化多线程应用程序。本章节将深入探讨Java并发编程中的关键概念和高级技术,包括线程的生命周期管理、同步机制、锁的使用以及并发工具类的实用案例。
## 4.1 线程的生命周期与管理
Java中的线程可以处于多种状态,这些状态之间的转换构成了线程的生命周期。理解线程状态和状态转换对于管理并发应用程序至关重要。
### 4.1.1 理解线程状态和状态转换
Java虚拟机(JVM)规范定义了线程的六种状态:
- **New(新建)**:当线程对象被创建后,但尚未启动。
- **Runnable(可运行)**:线程可以被JVM调度执行。
- **Blocked(阻塞)**:线程等待监视器锁。
- **Waiting(等待)**:线程在等待另一个线程执行一个(或多个)特定操作。
- **Timed Waiting(计时等待)**:线程在指定的时间内等待另一个线程执行一个(或多个)特定操作。
- **Terminated(终止)**:线程的执行已经结束。
通过使用Java的Thread类提供的方法,我们可以检查和改变线程的状态。
```java
Thread thread = new Thread(() -> {
System.out.println("Thread is running...");
});
// Start the thread
thread.start();
// Check thread state
Thread.State state = thread.getState();
System.out.println("Thread state: " + state);
// Wait until thread terminates
thread.join();
```
在上述代码中,我们创建了一个新的线程并启动它。使用`getState()`方法可以获取线程的当前状态。调用`join()`方法会使当前线程等待直到目标线程完成。
### 4.1.2 创建和管理线程的高级技术
Java提供了多种高级技术来创建和管理线程。除了使用Thread类,还可以通过实现Runnable接口来定义线程的任务。此外,可以利用线程池来有效地管理线程资源。
```java
ExecutorService executorService = Executors.newFixedThreadPool(4);
for (int i = 0; i < 10; i++) {
final int taskNumber = i;
executorService.submit(() -> {
System.out.println("Task number " + taskNumber + " is running.");
});
}
executorService.shutdown();
```
在这个例子中,我们使用了`Executors`类创建了一个固定大小的线程池,并提交了多个任务。这种方式可以有效管理线程资源,减少创建和销毁线程的开销。
## 4.2 同步机制和锁的使用
在多线程环境中,数据的一致性和线程的安全性是至关重要的。Java提供了多种同步机制来解决线程安全问题,包括`synchronized`关键字和`ReentrantLock`类。
### 4.2.1 synchronized关键字的深入讲解
`synchronized`是Java中的一个关键字,它用于控制对共享资源的并发访问。使用`synchronized`时,它可以作用在方法或代码块上,保证同一时刻只有一个线程可以执行该部分代码。
```java
public class Counter {
private int count = 0;
public synchronized void increment() {
count++;
}
public synchronized int getCount() {
return count;
}
}
```
在上述代码中,我们使用`synchronized`关键字同步了`increment`和`getCount`方法,确保了对`count`变量的线程安全访问。
### 4.2.2 ReentrantLock与Condition的进阶应用
`ReentrantLock`是另一种同步机制,它是`java.util.concurrent.locks`包中的一个类,提供了比`synchronized`更灵活的锁定操作。
```java
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
import java.util.concurrent.locks.Condition;
public class ConditionExample {
private final Lock lock = new ReentrantLock();
private final Condition condition = lock.newCondition();
private boolean isReady = false;
public void await() {
lock.lock();
try {
while (!isReady) {
condition.await();
}
System.out.println("Resource is ready to be consumed");
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
lock.unlock();
}
}
public void signal() {
lock.lock();
try {
isReady = true;
condition.signalAll();
} finally {
lock.unlock();
}
}
}
```
在这个例子中,我们创建了一个`ReentrantLock`的实例以及一个`Condition`对象。`await`方法会在某个条件成立之前使当前线程等待,`signal`方法则用于唤醒等待线程。
## 4.3 并发工具类的实用案例
Java并发包`java.util.concurrent`提供了许多并发工具类,以解决多线程编程中的一些常见问题。我们接下来将讨论如何使用`ConcurrentHashMap`和`Atomic`类。
### 4.3.1 使用ConcurrentHashMap优化线程安全的Map
`ConcurrentHashMap`是线程安全的Map实现,它的设计目的就是为了在多线程环境下提供高效的并发访问。
```java
ConcurrentHashMap<String, String> concurrentMap = new ConcurrentHashMap<>();
// Thread 1
concurrentMap.put("key1", "value1");
// Thread 2
String value = concurrentMap.get("key1");
```
在多线程环境下,使用`ConcurrentHashMap`可以避免使用同步Map时所带来的性能开销,特别是在高并发的情况下。
### 4.3.2 Atomic类和CAS机制的应用实例
`Atomic`类(如`AtomicInteger`, `AtomicLong`, `AtomicBoolean`等)使用了CAS(Compare-And-Swap)机制来实现无锁的线程安全操作。
```java
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicIntegerExample {
private AtomicInteger counter = new AtomicInteger(0);
public void increment() {
counter.incrementAndGet();
}
public int get() {
return counter.get();
}
}
```
在这个例子中,`AtomicInteger`的`incrementAndGet`方法会安全地递增计数器,所有操作都是原子的,且无需使用显式的锁。
以上所展示的并发编程工具和技巧是Java开发者在多线程环境中进行高效、安全编程的基础。理解并熟练运用这些工具将大大提高开发人员解决并发问题的能力。
# 5. Java.lang包中的反射机制与类加载
## 5.1 反射机制的原理和应用场景
### 5.1.1 Class类的结构与反射方法
反射机制是Java语言中一个非常重要的特性,它允许程序在运行时访问和操作类的内部信息。反射机制提供了动态创建对象、调用方法、访问属性、处理异常等功能,这在许多高级应用,如框架开发、依赖注入以及实现通用数据库操作等场景中非常有用。
在Java中,每个类在被加载到内存中之后,都会在JVM中对应一个唯一的`java.lang.Class`对象。这个`Class`对象描述了类的基本信息,包括类的名称、方法、字段等。通过这个`Class`对象,我们可以获取到关于类的所有信息,并且可以动态地创建类的实例、访问其私有字段、调用其私有方法等。
使用反射时,首先需要获取到对应类的`Class`对象,可以通过以下三种方式之一来获取:
```java
// 1. 使用类名获取
Class<?> clazz = MyClass.class;
// 2. 使用实例对象的 getClass 方法获取
MyClass obj = new MyClass();
Class<?> clazz = obj.getClass();
// 3. 使用 Class.forName 方法获取
Class<?> clazz = Class.forName("com.example.MyClass");
```
一旦有了`Class`对象,就可以通过它来获取类中定义的字段、方法、构造器等:
```java
// 获取字段
Field field = clazz.getDeclaredField("fieldName");
// 获取方法
Method method = clazz.getMethod("methodName", 参数类型1.class, 参数类型2.class);
// 获取构造器
Constructor<?> constructor = clazz.getConstructor(参数类型1.class, 参数类型2.class);
```
反射在动态创建对象和调用方法时非常强大,但也带来了性能损耗和安全风险。由于反射需要在运行时进行类的解析,因此相比直接代码调用,反射的性能损耗较大。此外,反射绕过了Java的访问控制机制,因此可能带来安全问题。
### 5.1.2 动态代理和反射在框架中的应用
动态代理是反射机制在框架设计中的一项重要应用。动态代理允许在运行时动态创建接口的实现类,并可以拦截接口方法的调用,这对于实现AOP(面向切面编程)非常有用。例如,在Spring框架中,Spring AOP使用动态代理来实现声明式事务管理。
在Java中,可以使用`java.lang.reflect.Proxy`类来生成动态代理对象。要使用动态代理,首先需要定义一个或多个接口,并提供一个实现`java.lang.reflect.InvocationHandler`接口的处理器,该处理器将定义方法调用时如何进行拦截处理。
```java
// 创建InvocationHandler
InvocationHandler handler = new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 在这里可以对方法调用进行拦截和增强
return method.invoke(target, args);
}
};
// 创建动态代理对象
Class<?>[] interfaces = {SomeInterface.class};
Object proxy = Proxy.newProxyInstance(
SomeInterface.class.getClassLoader(),
interfaces,
handler
);
```
在上述代码中,`SomeInterface.class`是要代理的接口类型,`handler`是具体的拦截处理器。这样创建的`proxy`对象实现了`SomeInterface`接口,并且所有接口方法的调用都会被`handler`中的`invoke`方法拦截。
使用反射和动态代理的框架通常需要在代码中实现额外的复杂性,以处理运行时的操作。然而,这种灵活性是值得的,因为它允许框架为开发者提供更为强大和灵活的功能。
【技术细节拓展】
在处理代理对象和原始对象之间的交互时,通常需要有一个目标对象(target object),该对象是实际业务逻辑的承载者。在上面示例的`invoke`方法中,`target`是指向实际业务对象的引用,通过反射的`method.invoke(target, args)`,可以在不改变原有方法签名和逻辑的基础上,增加额外的行为。
这种模式被广泛应用于各种Java框架中,以实现横切关注点的分离和功能的解耦。在这些应用中,开发者可以利用反射和动态代理的特性,从而使得框架更加灵活,同时也为开发者提供了强大的编程抽象。
## 5.2 类加载机制详解
### 5.2.1 类加载器的层次结构
在Java中,类加载是一个将类的`.class`文件转换为方法区内的运行时数据结构,并在Java堆中生成一个`java.lang.Class`对象的过程。类的加载和链接过程涉及到类加载器,它负责从文件系统或网络中加载Class文件。
Java虚拟机中的类加载器大致可以分为以下三类:
1. **引导类加载器(Bootstrap ClassLoader)**:
- 这是Java类加载层次中最顶层的加载器。
- 它负责加载存放在`<JAVA_HOME>/lib`目录或者被`-Xbootclasspath`参数指定路径中的,并且能被虚拟机识别的类库。
- 它是用C++语言实现的,没有继承自`java.lang.ClassLoader`。
2. **扩展类加载器(Extension ClassLoader)**:
- 这个加载器负责加载`<JAVA_HOME>/lib/ext`目录下,或者由`java.ext.dirs`系统属性指定位置中的所有类库。
- 它是`sun.misc.Launcher$ExtClassLoader`类的实例。
3. **应用程序类加载器(Application ClassLoader)**:
- 这个加载器负责加载用户类路径(Classpath)上所指定的类库。
- 它是`sun.misc.Launcher$AppClassLoader`类的实例。
- 如果应用程序中没有自定义过类加载器,那么这个就是默认的类加载器。
### 5.2.2 双亲委派模型的工作原理
双亲委派模型(Parent Delegation Model)是类加载器实现中的一个重要概念。当一个类加载器收到类加载请求时,它首先不会尝试自己加载这个类,而是将这个请求委派给父类加载器去完成,每一层都是如此。只有当父类加载器在它的搜索范围中没有找到所需的类时,子加载器才会尝试自己去加载该类。
这个模型的实现确保了Java平台的安全性和稳定性,因为它可以避免类的重复加载,同时也可以防止恶意代码通过类加载机制破坏Java虚拟机的安全。
类加载器之间的这种协作关系,通常可以用以下的伪代码来表示:
```java
protected synchronized Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException {
Class c = findLoadedClass(name);
if (c == null) {
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// 如果父类加载器无法加载,则尝试自己加载
}
if (c == null) {
c = findClass(name);
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
```
在上述代码中,`findLoadedClass`方法用于检查该类是否已经被加载过,`parent.loadClass`是调用父加载器加载类的方法,`findBootstrapClassOrNull`用于尝试加载基础类库中的类,如果这些方法都无法找到或加载类,则最终通过`findClass`方法自己尝试加载类。
双亲委派模型在Java中得到了广泛的应用,而开发者也可以创建自定义的类加载器来覆盖默认的类加载行为,比如为了支持热部署,或者是需要从不同的数据源加载类文件等场景。
## 5.3 安全性和性能考虑
### 5.3.1 反射和类加载的性能影响
尽管反射提供了一种强大的运行时操作能力,但它也对程序的性能和安全性带来了潜在的负面影响。反射操作通常比普通的成员访问要慢,因为它需要在运行时解析类型信息,并且可能需要进行安全检查和权限验证。因此,在涉及性能敏感的应用程序中,应谨慎使用反射。
为了减少性能损耗,可以采取以下措施:
- **缓存`Class`对象引用**:避免在频繁调用的方法中重复调用`Class.forName()`来获取`Class`对象,因为它是一个比较耗时的操作。
- **减少反射调用**:如果可以通过正常编码实现相同的功能,尽量避免使用反射。
- **预先验证参数类型**:在使用反射调用方法或构造器之前,预先验证参数类型和方法签名,以避免在运行时发生类型不匹配的异常。
### 5.3.2 提高反射操作安全性的实践方法
使用反射时,需要特别注意安全性问题,因为它允许程序绕过正常的访问控制。以下是提高反射操作安全性的实践方法:
- **限制访问**:使用`setAccessible(false)`方法可以防止反射访问类中的私有成员,通过这种方式可以保护私有成员不被外部访问,从而提高安全性。
- **最小权限原则**:只使用反射来访问那些在编译时无法访问的类和成员,避免使用反射来访问那些可以正常访问的成员,这样可以降低安全风险。
- **异常处理**:在使用反射时,应该妥善处理可能出现的`ExceptionInInitializerError`、`ClassNotFoundException`、`NoSuchMethodException`等异常,确保程序在运行时的健壮性。
- **审计跟踪**:在使用反射时记录关键的反射操作日志,以便在出现问题时进行审计和追踪。
通过以上的措施,可以在使用Java.lang包中的反射机制时,尽可能地保障应用的安全性与性能表现。
# 6. Java.lang包中的系统级操作与优化
## 6.1 系统属性和运行环境的获取
系统属性是Java运行时环境的一些配置信息,它们可以用来了解和影响Java程序的运行环境。`System`类提供了一系列静态方法来检索和设置这些属性。
### 6.1.1 系统属性的检索和设置
系统属性可以通过`System.getProperty()`方法检索。例如,要获取Java版本,可以使用以下代码:
```java
String javaVersion = System.getProperty("java.version");
System.out.println("Java Version: " + javaVersion);
```
如果需要设置新的系统属性,可以使用`System.setProperty()`方法。请注意,并非所有的系统属性都可以被设置,有些是只读的。
```java
System.setProperty("myApp.version", "1.0");
String myAppVersion = System.getProperty("myApp.version");
System.out.println("My App Version: " + myAppVersion);
```
### 6.1.2 环境变量的作用和配置技巧
环境变量是操作系统级别的变量,它们可以影响Java程序的行为。`System.getenv()`方法可以用来获取环境变量。
```java
String path = System.getenv("PATH");
System.out.println("PATH: " + path);
```
在开发中,配置环境变量对于调试和设置不同的运行时参数至关重要。例如,可以通过设置`JAVA_HOME`环境变量来指定Java的安装路径,这对于运行Java程序和使用JDK工具非常有用。
## 6.2 内存管理和垃圾回收机制
### 6.2.1 JVM内存模型的详细剖析
JVM内存模型定义了Java虚拟机如何在内存中存储对象,以及如何将对象引用存储到各种引用类型中。通常分为几个部分:
- 堆(Heap):用于存放对象实例。
- 方法区(Method Area):存储类信息、常量、静态变量等。
- 虚拟机栈(VM Stack):用于存储局部变量和方法调用。
- 本地方法栈(Native Method Stack):与VM栈类似,但是用于本地方法调用。
- 程序计数器(Program Counter):用于存储当前线程所执行的字节码行号指示器。
### 6.2.2 常用的垃圾回收器和调优策略
垃圾回收(GC)是JVM管理内存的重要机制。常见的垃圾回收器有:
- Serial GC
- Parallel GC
- CMS GC
- G1 GC
- ZGC
- Shenandoah
每种垃圾回收器都有其特点和适用场景。例如,G1 GC是为大内存服务器设计,而ZGC和Shenandoah是为了低延迟而设计的。
在JVM启动参数中,可以通过设置不同的参数来选择垃圾回收器:
```bash
-XX:+UseG1GC
```
调优策略通常包括合理配置堆大小、调整垃圾回收器参数、监控内存使用情况等。
## 6.3 性能监控和调试工具的使用
性能监控和调试是确保Java应用程序性能和稳定性的重要环节。
### 6.3.1 JConsole和VisualVM的高级功能
JConsole和VisualVM是JDK自带的监控工具,它们可以用来监控Java应用程序的性能,并提供丰富的信息。
- JConsole可以连接到运行中的Java应用程序,显示内存使用、线程状态、类加载情况等。
- VisualVM提供更高级的监控和故障排除功能,支持插件扩展,可以显示更详尽的信息,并对JVM进行更深入的分析。
### 6.3.2 使用jstack和jmap进行问题诊断
`jstack`用于生成JVM中线程的堆栈跟踪信息,这对于诊断线程死锁和性能瓶颈非常有用。命令如下:
```bash
jstack -l <pid>
```
`jmap`用于生成JVM内存映射文件,它可以帮助我们分析内存使用情况。例如:
```bash
jmap -dump:format=b,file=heapdump.hprof <pid>
```
通过这些工具和命令的使用,可以有效地识别和解决应用程序中的问题。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
“java.lang库入门介绍与使用”专栏深入探讨了Java语言的核心库,全面解析其20年的发展历程。专栏涵盖了从入门到高级的各种主题,包括:
* Java.lang库的深度剖析,揭示其背后的秘密
* 实用手册,提供从入门到专家的全方位技术指南
* 解决常见问题的最佳实践案例
* String类等高级用法的详细解析
* Object类及其应用场景的全面介绍
* try-catch机制的深层解读与优化
* System类使用与自定义设置技巧
* Math库的数学运算原理与效率提升策略
* Class类的动态世界,涵盖类加载与反射
* Comparable与Comparator接口的实战指南
* Thread类使用与线程安全策略
* 垃圾回收机制的深入探索
* List、Set与Map底层实现原理
* Calendar与Date类的使用
* ExecutorService与Future的深入实践
* 数组操作效率与性能提升策略
* Pattern与Matcher的高效使用指南
* System.in、out与err的优化技巧
* ThreadMXBean与StackWalking的调试与诊断
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘ETA6884移动电源的超速充电:全面解析3A充电特性

# 摘要
本文详细探讨了ETA6884移动电源的技术规格、充电标准以及3A充电技术的理论与应用。通过对充电技术的深入分析,包括其发展历程、电气原理、协议兼容性、安全性理论以及充电实测等,我们提供了针对ETA6884移动电源性能和效率的评估。此外,文章展望了未来充电技术的发展趋势,探讨了智能充电、无线充电以
【编程语言选择秘籍】:项目需求匹配的6种语言选择技巧

# 摘要
本文全面探讨了编程语言选择的策略与考量因素,围绕项目需求分析、性能优化、易用性考量、跨平台开发能力以及未来技术趋势进行深入分析。通过对不同编程语言特性的比较,本文指出在进行编程语言选择时必须综合考虑项目的特定需求、目标平台、开发效率与维护成本。同时,文章强调了对新兴技术趋势的前瞻性考量,如人工智能、量子计算和区块链等,以及编程语言如何适应这些技术的变化。通
【信号与系统习题全攻略】:第三版详细答案解析,一文精通

# 摘要
本文系统地介绍了信号与系统的理论基础及其分析方法。从连续时间信号的基本分析到频域信号的傅里叶和拉普拉斯变换,再到离散时间信号与系统的特性,文章深入阐述了各种数学工具如卷积、
微波集成电路入门至精通:掌握设计、散热与EMI策略

# 摘要
本文系统性地介绍了微波集成电路的基本概念、设计基础、散热技术、电磁干扰(EMI)管理以及设计进阶主题和测试验证过程。首先,概述了微波集成电路的简介和设计基础,包括传输线理论、谐振器与耦合结构,以及高频电路仿真工具的应用。其次,深入探讨了散热技术,从热导性基础到散热设计实践,并分析了散热对电路性能的影响及热管理的集成策略。接着,文章聚焦于EMI管理,涵盖了EMI基础知识、
Shell_exec使用详解:PHP脚本中Linux命令行的实战魔法

# 摘要
本文详细探讨了PHP中的Shell_exec函数的各个方面,包括其基本使用方法、在文件操作与网络通信中的应用、性能优化以及高级应用案例。通过对Shell_exec函数的语法结构和安全性的讨论,本文阐述了如何正确使用Shell_exec函数进行标准输出和错误输出的捕获。文章进一步分析了Shell_exec在文件操作中的读写、属性获取与修改,以及网络通信中的Web服
NetIQ Chariot 5.4高级配置秘籍:专家教你提升网络测试效率

# 摘要
NetIQ Chariot是网络性能测试领域的重要工具,具有强大的配置选项和高级参数设置能力。本文首先对NetIQ Chariot的基础配置进行了概述,然后深入探讨其高级参数设置,包括参数定制化、脚本编写、性能测试优化等关键环节。文章第三章分析了Net
【信号完整性挑战】:Cadence SigXplorer仿真技术的实践与思考
# 摘要
本文全面探讨了信号完整性(SI)的基础知识、挑战以及Cadence SigXplorer仿真技术的应用与实践。首先介绍了信号完整性的重要性及其常见问题类型,随后对Cadence SigXplorer仿真工具的特点及其在SI分析中的角色进行了详细阐述。接着,文章进入实操环节,涵盖了仿真环境搭建、模型导入、仿真参数设置以及故障诊断等关键步骤,并通过案例研究展示了故障诊断流程和解决方案。在高级
【Python面向对象编程深度解读】:深入探讨Python中的类和对象,成为高级程序员!

# 摘要
本文深入探讨了面向对象编程(OOP)的核心概念、高级特性及设计模式在Python中的实现和应用。第一章回顾了面向对象编程的基础知识,第二章详细介绍了Python类和对象的高级特性,包括类的定义、继承、多态、静态方法、类方法以及魔术方法。第三章深入讨论了设计模式的理论与实践,包括创建型、结构型和行为型模式,以及它们在Python中的具体实现。第四
Easylast3D_3.0架构设计全解:从理论到实践的转化
# 摘要
Easylast3D_3.0是一个先进的三维设计软件,其架构概述及其核心组件和理论基础在本文中得到了详细阐述。文中详细介绍了架构组件的解析、设计理念与原则以及性能评估,强调了其模块间高效交互和优化策略的重要性。
【提升器件性能的秘诀】:Sentaurus高级应用实战指南

# 摘要
Sentaurus是一个强大的仿真工具,广泛应用于半导体器件和材料的设计与分析中。本文首先概述了Sentaurus的工具基础和仿真环境配置,随后深入探讨了其仿真流程、结果分析以及高级仿真技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )