【异步并发爬虫】:提升爬虫效率的利器,极速获取海量数据
发布时间: 2024-06-18 17:39:42 阅读量: 100 订阅数: 49 

超牛逼的异步协程爬虫

# 1. 异步并发爬虫概述
异步并发爬虫是一种利用多线程、协程等技术实现高并发、高效率的爬虫技术。它通过同时处理多个请求,充分利用计算机资源,大幅提升爬虫速度和效率。
异步并发爬虫与传统同步爬虫相比,具有以下优势:
- **高并发性:**能够同时处理多个请求,提高爬取效率。
- **低资源占用:**避免创建大量线程或进程,降低系统资源消耗。
- **响应速度快:**通过事件驱动机制,及时响应请求,缩短爬取时间。
- **可扩展性强:**易于扩展并发度,适应不同规模的爬取任务。
# 2. 异步并发爬虫的理论基础
### 2.1 并发编程的原理和模型
并发编程是一种编程范式,它允许多个任务同时执行,从而提高程序的性能和效率。并发编程有两种主要模型:多线程和多进程。
#### 2.1.1 多线程和多进程
**多线程**
多线程是一种并发编程模型,它允许在单个进程中创建和运行多个线程。每个线程都是一个独立的执行单元,拥有自己的栈空间,但共享相同的堆空间。多线程编程可以提高程序的性能,因为多个线程可以同时执行不同的任务,而无需等待其他线程完成。
**多进程**
多进程是一种并发编程模型,它允许在不同的进程中创建和运行多个进程。每个进程都是一个独立的执行单元,拥有自己的内存空间和资源。多进程编程可以提高程序的稳定性,因为一个进程的崩溃不会影响其他进程。
#### 2.1.2 协程和事件循环
**协程**
协程是一种轻量级的线程,它允许在不创建新线程的情况下暂停和恢复执行。协程与线程类似,但它们共享相同的栈空间,并且由事件循环调度。协程编程可以提高程序的性能,因为它避免了线程创建和销毁的开销。
**事件循环**
事件循环是一种机制,它不断轮询事件队列,并执行与事件关联的回调函数。协程由事件循环调度,当协程需要暂停执行时,它会将自己注册到事件队列中。当事件触发时,事件循环会调用协程的回调函数,继续执行协程。
### 2.2 异步IO的原理和实现
异步IO是一种编程技术,它允许在不阻塞主线程的情况下执行IO操作。异步IO有两种主要实现方式:非阻塞IO和事件驱动。
#### 2.2.1 非阻塞IO和阻塞IO
**非阻塞IO**
非阻塞IO是一种IO操作,它不会阻塞主线程。当执行非阻塞IO操作时,主线程会立即返回,而IO操作会在后台继续进行。当IO操作完成时,操作系统会通知应用程序,应用程序可以继续处理IO操作的结果。
**阻塞IO**
阻塞IO是一种IO操作,它会阻塞主线程。当执行阻塞IO操作时,主线程会一直等待IO操作完成,然后再继续执行。阻塞IO操作会降低程序的性能,因为主线程无法在IO操作期间执行其他任务。
#### 2.2.2 事件驱动和回调机制
**事件驱动**
事件驱动是一种编程范式,它基于事件循环。事件驱动程序不断轮询事件队列,并执行与事件关联的回调函数。异步IO操作通常是事件驱动的,当IO操作完成时,操作系统会触发一个事件,应用程序可以注册回调函数来处理该事件。
**回调机制**
回调机制是一种编程技术,它允许在事件发生时调用函数。在异步IO中,回调函数用于处理IO操作完成时的事件。当IO操作完成时,操作系统会调用与该操作关联的回调函数,应用程序可以在回调函数中处理IO操作的结果。
# 3. 异步并发爬虫的实践应用
### 3.1 基于多线程的异步并发爬虫
#### 3.1.1 线程池的创建和管理
在基于多线程的异步并发爬虫中,线程池是管理和调度线程的重要机制。线程池可以有效地控制并发线程的数量,避免系统资源的过度消耗。
```python
import concurrent.futures
# 创建一个线程池,最大并发线程数为 10
executor = concurrent.futures.ThreadPoolExecutor(max_workers=10)
# 提交任务到线程池
executor.submit(task_function, arg1, arg2)
```
**代码逻辑分析:**
- `concurrent.futures.ThreadPoolExecutor` 类用于创建线程池。
- `max_workers` 参数指定了线程池的最大并发线程数。
- `submit()` 方法用于提交任务到线程池。
#### 3.1.2 线程间的通信和同步
在多线程环境中,线程之间需要进行通信和同步,以确保数据的正确性和一致性。
**锁:** 锁是一种同步机制,用于防止多个线程同时访问共享资源。
```python
import threading
# 创建一个锁
lock = threading.Lock()
# 使用锁保护共享资源
with lock:
# 对共享资源进行操作
```
**代码逻辑分析:**
- `threading.Lock()` 类用于创建锁。
- `with` 语句用于获取锁,并确保在语句块执行期间锁被持有。
**事件:** 事件是一种同步机制,用于通知线程某个事件已发生。
```python
import threading
# 创建一个事件
event = threading.Event()
# 设置事件
event.set()
# 等待事件
event.wait()
```
**代码逻辑分析:**
- `threading.Event()` 类用于创建事件。
- `set()` 方法用于设置事件。
- `wait()` 方法用于等待事件。
### 3.2 基于协程的异步并发爬虫
#### 3.2.1 协程的创建和调度
协程是一种轻量级的线程,它可以暂停和恢复执行。协程调度器负责管理协程的执行顺序。
```python
import asyncio
# 创建一个协程
async def coroutine_function():
# 协程代码
# 创建一个协程调度器
loop = asyncio.get_event_loop()
# 运行协程
loop.run_until_complete(coroutine_function())
```
**代码逻辑分析:**
- `async` 关键字用于声明一个协程函数。
- `asyncio.get_event_loop()` 方法用于获取协程调度器。
- `run_until_complete()` 方法用于运行协程。
#### 3.2.2 协程间的通信和同步
在协程环境中,协程之间需要进行通信和同步,以确保数据的正确性和一致性。
**通道:** 通道是一种通信机制,用于在协程之间发送和接收数据。
```python
import asyncio
# 创建一个通道
channel = asyncio.Queue()
# 向通道发送数据
await channel.put(data)
# 从通道接收数据
data = await channel.get()
```
**代码逻辑分析:**
- `asyncio.Queue()` 类用于创建通道。
- `put()` 方法用于向通道发送数据。
- `get()` 方法用于从通道接收数据。
**锁:** 锁也可以用于在协程环境中进行同步。
```python
import asyncio
# 创建一个锁
lock = asyncio.Lock()
# 使用锁保护共享资源
async with lock:
# 对共享资源进行操作
```
**代码逻辑分析:**
- `asyncio.Lock()` 类用于创建锁。
- `async with` 语句用于获取锁,并确保在语句块执行期间锁被持有。
# 4. 异步并发爬虫的性能优化
### 4.1 爬虫性能的评估和监控
**4.1.1 爬虫速度和效率的指标**
* **爬虫速度:**每秒爬取的页面数量。
* **爬虫效率:**爬取有用信息的页面数量与总爬取页面数量的比值。
* **响应时间:**爬虫从发送请求到收到响应所花费的时间。
* **并发度:**同时执行的爬虫任务数量。
**4.1.2 性能瓶颈的识别和定位**
* **CPU利用率:**爬虫进程占用的CPU资源百分比。
* **内存使用率:**爬虫进程占用的内存资源百分比。
* **网络带宽:**爬虫进程发送和接收数据的速率。
* **数据库访问:**爬虫进程访问数据库的频率和时间。
### 4.2 爬虫性能的优化策略
**4.2.1 并发度的优化**
* **合理设置并发度:**根据服务器资源和网络带宽,选择合适的并发度。
* **动态调整并发度:**根据爬虫的实时性能数据,动态调整并发度。
**4.2.2 缓存和持久化的应用**
* **页面缓存:**将爬取过的页面存储在内存或磁盘中,避免重复爬取。
* **数据持久化:**将爬取到的数据持久化到数据库或文件系统中,避免数据丢失。
#### 代码示例:
```python
# 使用 Redis 作为页面缓存
import redis
cache = redis.Redis(host='localhost', port=6379)
def get_page_from_cache(url):
return cache.get(url)
def set_page_in_cache(url, content):
cache.set(url, content)
```
#### 逻辑分析:
* `get_page_from_cache` 函数从 Redis 缓存中获取指定 URL 的页面内容。
* `set_page_in_cache` 函数将指定 URL 的页面内容存储到 Redis 缓存中。
#### 参数说明:
* `url`: 要获取或存储的页面 URL。
* `content`: 要存储的页面内容。
#### mermaid格式流程图:
```mermaid
graph LR
subgraph 爬虫性能优化策略
并发度的优化 --> 缓存和持久化的应用
end
```
#### 表格示例:
| 性能优化策略 | 描述 |
|---|---|
| 并发度的优化 | 合理设置并发度,动态调整并发度 |
| 缓存和持久化的应用 | 使用页面缓存,数据持久化 |
# 5. 异步并发爬虫的案例分析
### 5.1 基于异步并发爬虫的电商商品信息抓取
**5.1.1 爬虫架构设计和实现**
基于异步并发爬虫的电商商品信息抓取系统采用多线程架构,利用线程池管理线程资源。爬虫流程如下:
```mermaid
sequenceDiagram
participant Crawler
participant Scheduler
participant Parser
participant Storage
Crawler->>Scheduler: Request URL
Scheduler->>Parser: Parse URL
Parser->>Storage: Save data
```
**线程池管理:**
```python
from concurrent.futures import ThreadPoolExecutor
# 创建线程池
executor = ThreadPoolExecutor(max_workers=10)
# 提交任务
executor.submit(crawler.crawl, url)
```
**任务分发:**
```python
class Scheduler:
def __init__(self):
self.queue = Queue()
def add_task(self, url):
self.queue.put(url)
def get_task(self):
return self.queue.get()
```
**商品信息解析:**
```python
class Parser:
def parse(self, url):
# 解析商品信息
product_info = {
"name": "",
"price": "",
"description": ""
}
# 返回商品信息
return product_info
```
**数据存储:**
```python
class Storage:
def save(self, product_info):
# 存储商品信息到数据库
pass
```
### 5.1.2 爬虫性能和效果评估
**性能评估指标:**
- 爬取速度:单位时间内爬取的商品数量
- 效率:爬取成功率,即爬取到的商品数量与请求的商品数量之比
**性能优化策略:**
- 并发度优化:调整线程池中的线程数量,找到最佳并发度
- 缓存和持久化:将爬取到的商品信息缓存到内存或数据库中,减少重复爬取

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供全面的 Python 爬虫教程,涵盖从入门到进阶的各个方面。从零基础快速上手爬取网页数据,到构建完整的爬虫项目,掌握爬虫开发秘诀。此外,还深入探讨了异步并发爬虫、反反爬机制、数据清洗、分析和可视化,以及数据建模、常见问题解决和性能优化等主题。专栏还介绍了动态页面处理、无头浏览器、分布式爬虫等高级技术,并提供了电商网站数据爬取、新闻网站数据分析和社交媒体数据挖掘等实际案例。最后,还涉及了机器学习和人工智能在爬虫中的应用,让爬虫更智能、更高效。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【掌握电路表决逻辑】:裁判表决电路设计与分析的全攻略
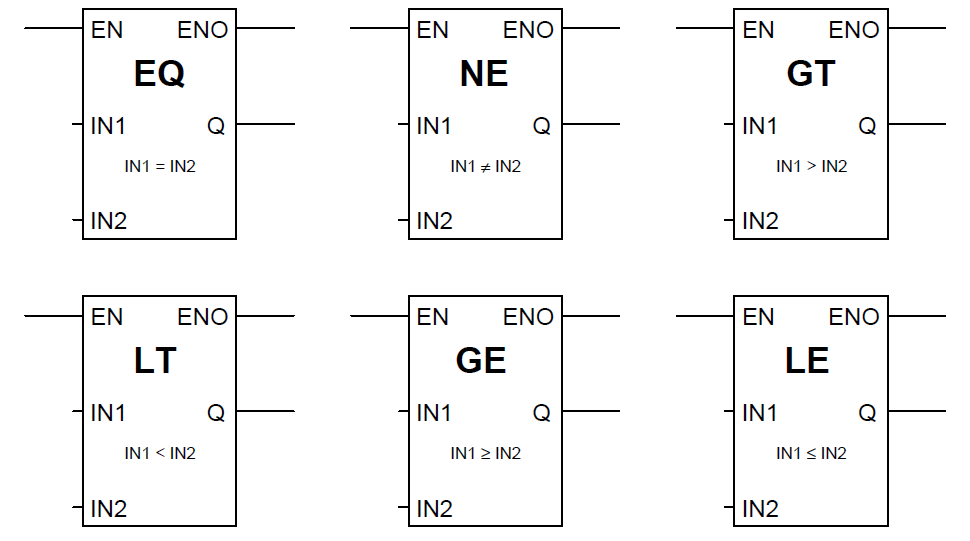
# 摘要
本文对电路表决逻辑进行了全面的概述,包括基础理论、设计实践、分析与测试以及高级应用等方面。首先介绍了表决逻辑的基本概念、逻辑门和布尔代数基础,然后详细探讨了表决电路的真值表和功能表达。在设计实践章节中,讨论了二输入和多输入表决电路的设计流程与实例,并提出了优化与改进方法。分析与测试
C# WinForm程序打包优化术:5个技巧轻松减小安装包体积
# 摘要
WinForm程序打包是软件分发的重要步骤,优化打包流程可以显著提升安装包的性能和用户体验。本文首先介绍了WinForm程序打包的基础知识,随后详细探讨了优化打包流程的策略,包括依赖项分析、程序集和资源文件的精简,以及配置优化选项。接着深入到代码级别,阐述了如何通过精简代码、优化数据处理和调整运行时环境来进一步增强应用程序。文章还提供了第三方打包工具的选择和实际案例分析,用以解决打包过程中的常见问题。最后,本
【NI_Vision调试技巧】:效率倍增的调试和优化方法,专家级指南

# 摘要
本文全面介绍了NI_Vision在视觉应用中的调试技术、实践案例和优化策略。首先阐述了NI_Vision的基础调试方法,进而深入探讨了高级调试技术,包括图像采集与处理、调试工具的使用和性能监控。通过工业视觉系统调试和视觉测量与检测应用的案例分析,展示了NI_Vision在实际问题解决中的应用。本文还详细讨论了代码、系统集成、用户界面等方面的优化方法,以及工具
深入理解Windows内存管理:第七版内存优化,打造流畅运行环境
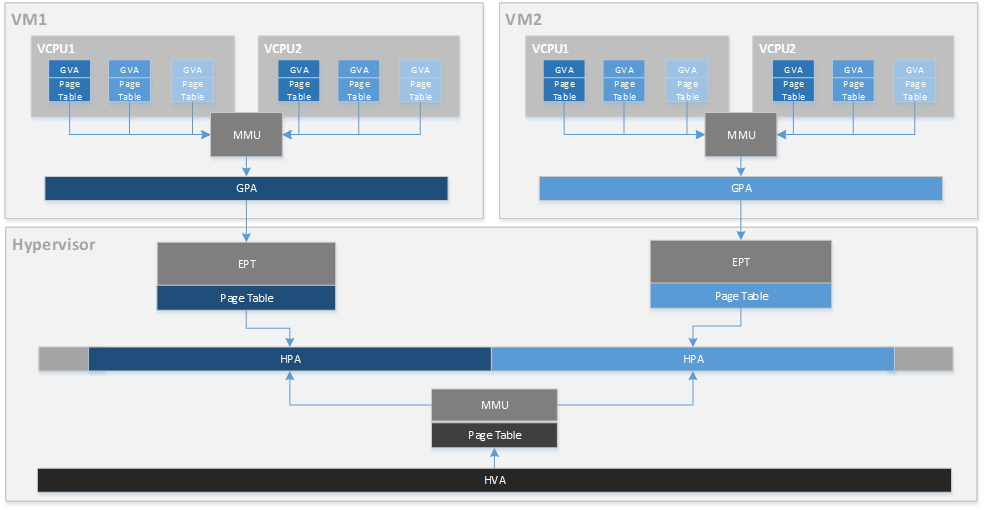
# 摘要
本文深入探讨了Windows环境下内存管理的基础知识、理论与实践操作。文章首先介绍内存管理的基本概念和理论框架,包括不同类型的内存和分页、分段机制。接着,本文详细阐述了内存的分配、回收以及虚拟内存管理的策略,重点讨论了动态内存分配算法和内存泄漏的预防。第三章详细解析了内存优化技术,包括监控与分析工具的选择应用、内存优化技巧及故障诊断与解决方法。第四章聚焦于打造高性能运行环境,分别从系统、程
专家揭秘:7个技巧让威纶通EasyBuilder Pro项目效率翻倍
# 摘要
本论文旨在为初学者提供威纶通EasyBuilder Pro的快速入门指南,并深入探讨高效设计原则与实践,以优化用户界面的布局和提高设计的效率。同时,本文还涵盖了通过自动化脚本编写和高级技术提升工作效率的方法。项目管理章节着重于资源规划与版本控制策略,以优化项目的整体执行。最后,通过案例分析,本文提供了问题解决的实践方法和技巧,旨在帮助读者将理论知识应用于实际工作中,解决常见的开发难题,
Jetson Nano编程入门:C++和Python环境搭建,轻松开始AI开发

# 摘要
Jetson Nano作为NVIDIA推出的边缘计算开发板,以其实惠的价格和强大的性能,为AI应用开发提供了新的可能性。本文首先介绍了Jetson Nano的硬件组成、接口及配置指南,并讨论了其安全维护的最佳实践。随后,详细阐述了如何为Jetson Nano搭建C++和P
软件操作手册撰写:遵循这5大清晰易懂的编写原则

# 摘要
软件操作手册是用户了解和使用软件的重要参考文档,本文从定义和重要性开始,详细探讨了手册的受众分析、需求评估、友好的结构设计。接下来,文章指导如何编写清晰的操作步骤,使用简洁的语言,并通过示例和截图增强理解。为提升手册的质量,本文进一步讨论了实现高级功能的说明,包含错误处理、自定义设置以及技术细节。最后,探讨了格式选择、视觉布局和索引系统的设计,以及测试、反馈收集与文档持续改进的策略。本文旨在为编写高
西门子G120变频器维护秘诀:专家告诉你如何延长设备寿命

# 摘要
本文对西门子G120变频器的基础知识、日常维护实践、故障诊断技术、性能优化策略进行了系统介绍。首先,概述了变频器的工作原理及关键组件功能,然后深入探讨了变频器维护的理论基础,包括日常检查、定期维护流程以及预防性维护策略的重要性。接着,文章详述了西门子G
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )