




Python爬虫数据可视化:用图表展示爬取结果,直观呈现数据价值
发布时间: 2024-06-18 17:47:23 阅读量: 172 订阅数: 56 
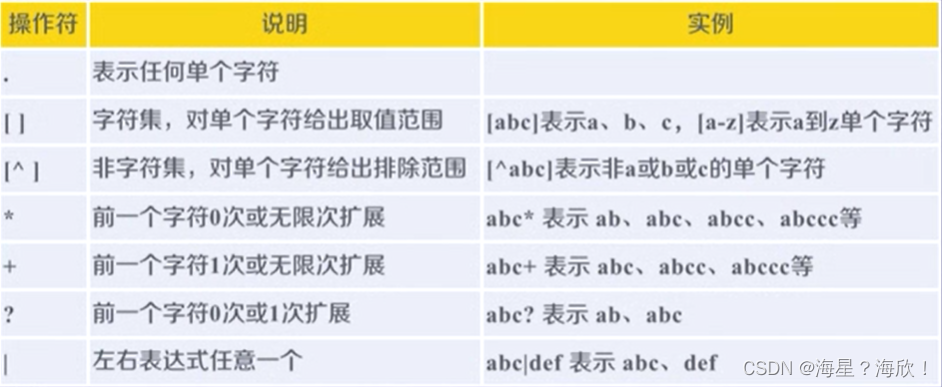
1. Python爬虫数据可视化概述
数据可视化是将数据以图形方式呈现的过程,它可以帮助我们更直观地理解和分析数据。Python是一种流行的编程语言,提供了丰富的库和工具,用于从网络爬取数据并进行可视化。
通过使用Python爬虫,我们可以从各种网站和在线平台中提取数据。这些数据可以包含产品信息、用户行为、财务数据等。一旦数据被爬取,我们就可以使用Python数据可视化库将其转换为可视化表示形式,例如图表、图形和地图。
数据可视化在IT行业和相关行业中具有广泛的应用。它可以帮助我们识别趋势、发现模式、进行预测并做出明智的决策。通过使用Python爬虫和数据可视化技术,我们可以从海量数据中提取有价值的见解,并以更有效的方式传达信息。
2. Python数据可视化库介绍
2.1 Matplotlib:基础绘图和图表库
Matplotlib是Python中广泛使用的基础绘图和图表库。它提供了各种绘图功能,包括折线图、柱状图、散点图等,以及对图表进行自定义和美化的选项。
2.1.1 折线图、柱状图、散点图绘制
Matplotlib提供了绘制折线图、柱状图和散点图的简单方法。

代码逻辑分析:
plt.plot():绘制折线图,参数为x轴和y轴数据。plt.xlabel()和plt.ylabel():设置x轴和y轴标签。plt.title():设置图表标题。plt.show():显示图表。
2.1.2 图表自定义和美化
Matplotlib提供了丰富的选项来自定义和美化图表,包括设置颜色、线宽、标记样式等。
代码逻辑分析:
color:设置折线颜色。linewidth:设置折线宽度。marker:设置散点标记样式。grid():显示网格线。legend():添加图例。title()、xlabel()和ylabel():设置标题和标签。
3.1 数据爬取技术
3.1.1 网页解析和数据提取
网页解析是爬虫技术的基础,其目的是从网页中提取所需的数据。常用的网页解析技术包括:
- **HTML解析:**使用HTML解析器(如BeautifulSoup)解析网页的HTML结构,提取特定标签或属性中的数据。
- **正则表达式:**使用正则表达式匹配和提取网页中的特定数据模式。
- **XPath:**使用XPath表达式在XML文档中查找和提取数据。
3.1.2 爬虫框架和工具介绍
为了简化爬虫开发,出现了各种爬虫框架和工具,它们提供了丰富的功能和易用性。一些流行的爬虫框架和工具包括:
- **Scrapy:**一个功能强大的爬虫框架,提供数据提取、持久化和并发处理等功能。
- **Beautiful Soup:**一个HTML解析库,支持多种解析方法和选择器语法。
- **Selenium:**一个浏览器自动化工具,可以模拟用户在浏览器中的操作,用于动态网页的爬取。
代码块:
- import requests
- from bs4 import BeautifulSoup
- # 获取网页内容
- url = 'https://www.example.com'
- response = requests.get(url)
- # 解析HTML
- soup = BeautifulSoup(response.text, 'html.parser')
- # 提取特定数据
- title = soup.find('title').text
逻辑分析:
该代码块演示了如何使用Requests库获取网页内容,然后使用BeautifulSoup库

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏简介
本专栏提供全面的 Python 爬虫教程,涵盖从入门到进阶的各个方面。从零基础快速上手爬取网页数据,到构建完整的爬虫项目,掌握爬虫开发秘诀。此外,还深入探讨了异步并发爬虫、反反爬机制、数据清洗、分析和可视化,以及数据建模、常见问题解决和性能优化等主题。专栏还介绍了动态页面处理、无头浏览器、分布式爬虫等高级技术,并提供了电商网站数据爬取、新闻网站数据分析和社交媒体数据挖掘等实际案例。最后,还涉及了机器学习和人工智能在爬虫中的应用,让爬虫更智能、更高效。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【VCS高可用案例篇】:深入剖析VCS高可用案例,提炼核心实施要点

# 摘要
本文深入探讨了VCS高可用性的基础、核心原理、配置与实施、案例分析以及高级话题。首先介绍了高可用性的概念及其对企业的重要性,并详细解析了VCS架构的关键组件和数据同步机制。接下来,文章提供了VC
Cygwin系统监控指南:性能监控与资源管理的7大要点

# 摘要
本文详尽探讨了使用Cygwin环境下的系统监控和资源管理。首先介绍了Cygwin的基本概念及其在系统监控中的应用基础,然后重点讨论了性能监控的关键要点,包括系统资源的实时监控、数据分析方法以及长期监控策略。第三章着重于资源管理技巧,如进程优化、系统服务管理以及系统安全和访问控制。接着,本文转向C
【Arcmap空间参考系统】:掌握SHP文件坐标转换与地理纠正的完整策略

# 摘要
本文旨在深入解析Arcmap空间参考系统的基础知识,详细探讨SHP文件的坐标系统理解与坐标转换,以及地理纠正的原理和方法。文章首先介绍了空间参考系统和SHP文件坐标系统的基础知识,然后深入讨论了坐标转换的理论和实践操作。接着,本文分析了地理纠正的基本概念、重要性、影响因素以及在Arcmap中的应用。最后,文章探讨了SHP文
ISO_IEC 27000-2018标准实施准备:风险评估与策略规划的综合指南

# 摘要
随着数字化时代的到来,信息安全成为企业管理中不可或缺的一部分。本文全面探讨了信息安全的理论与实践,从ISO/IEC 27000-2018标准的概述入手,详细阐述了信息安全风险评估的基础理论和流程方法,信息安全策略规划的理论基础及生命周期管理,并提供了信息安全风险管理的实战指南。
【精准测试】:确保分层数据流图准确性的完整测试方法
# 摘要
分层数据流图(DFD)作为软件工程中描述系统功能和数据流动的重要工具,其测试方法论的完善是确保系统稳定性的关键。本文系统性地介绍了分层DFD的基础知识、测试策略与实践、自动化与优化方法,以及实际案例分析。文章详细阐述了测试的理论基础,包括定义、目的、分类和方法,并深入探讨了静态与动态测试方法以及测试用
戴尔笔记本BIOS语言设置:多语言界面和文档支持全面了解

# 摘要
本文全面介绍了戴尔笔记本BIOS的基本知识、界面使用、多语言界面设置与切换、文档支持以及故障排除。通过对BIOS启动模式和进入方法的探讨,揭示了BIOS界面结构和常用功能,为用户提供了深入理解和操作的指导。文章详细阐述了如何启用并设置多语言界面,以及在实践操作中可能遇到的问题及其解决方法。此外,本文深入分析了BIOS操作文档的语
【内存分配调试术】:使用malloc钩子追踪与解决内存问题
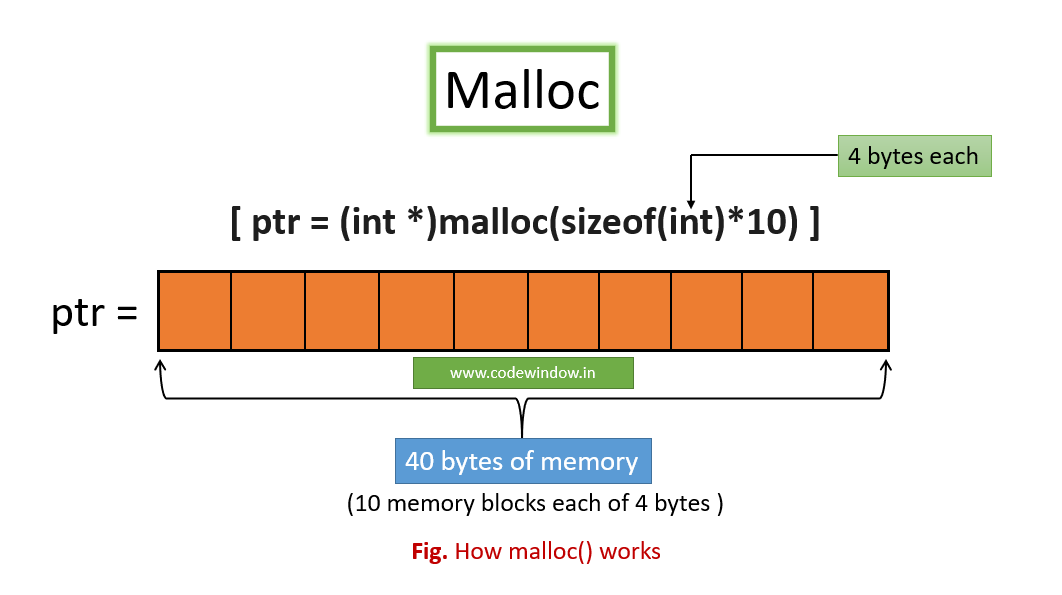
# 摘要
本文深入探讨了内存分配的基础知识,特别是malloc函数的使用和相关问题。文章首先分析了内存泄漏的成因及其对程序性能的影响,接着探讨内存碎片的产生及其后果。文章还列举了常见的内存错误类型,并解释了malloc钩子技术的原理和应用,以及如何通过钩子技术实现内存监控、追踪和异常检测。通过实践应用章节,指导读者如何配置和使用malloc钩子来调试内存问题,并优化内存管理策略。最后,通过真实世界案例的分析
【T-Box能源管理】:智能化节电解决方案详解

# 摘要
随着能源消耗问题日益严峻,T-Box能源管理系统作为一种智能化的能源管理解决方案应运而生。本文首先概述了T-Box能源管理的基本概念,并分析了智能化节电技术的理论基础,包括发展历程、科学原理和应用分类。接着详细探讨了T-Box系统的架构、核心功能、实施路径以及安全性和兼容性考量。在实践应用章节,本文分析了T-Bo
Fluentd与日志驱动开发的协同效应:提升开发效率与系统监控的魔法配方

# 摘要
随着信息技术的发展,日志数据的采集与分析变得日益重要。本文旨在详细介绍Fluentd作为一种强大的日志驱动开发工具,阐述其核心概念、架构及其在日志聚合和系统监控中的应用。文中首先介绍了Fluentd的基本组件、配置语法及其在日志聚合中的实践应用,随后深入探讨了F
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















