Node.js入门:构建简单的服务器端应用程序
发布时间: 2023-12-30 07:07:02 阅读量: 38 订阅数: 31 
## 1. 简介
### 1.1 什么是Node.js
Node.js是一个基于Chrome V8引擎的JavaScript运行时环境,可以让JavaScript在服务器端运行。它采用了事件驱动、非阻塞I/O模型,使得构建高性能、可扩展的网络应用程序变得更加容易。
### 1.2 为什么选择Node.js来构建服务器端应用程序
Node.js的非阻塞I/O模型使得它能够处理大量并发请求,相比传统的多线程模型,在处理高并发请求时具有更好的性能表现。此外,由于Node.js使用JavaScript作为开发语言,开发人员可以在前后端使用相同的语言,减少了学习成本,提高了开发效率。
### 1.3 Node.js的优势和特点
- 高性能:采用非阻塞I/O模型和事件驱动机制,能够处理大量并发请求,提高系统的吞吐量和响应速度。
- 轻量级:Node.js本身占用资源较小,适合部署在分布式、云计算等环境中,能够节省服务器资源。
- 跨平台:Node.js可以在几乎所有主流操作系统上运行,包括Windows、Linux、Mac OS等。
- 强大的生态系统:NPM(Node Package Manager)是世界上最大的开源库生态系统,拥有丰富的第三方库和工具,可快速构建复杂的应用程序。
- 可扩展性:Node.js通过集群、负载均衡等方式,可以轻松地扩展应用程序的处理能力,满足高并发的需求。
在接下来的章节中,我们将详细介绍如何准备环境并开始构建基于Node.js的服务器端应用程序。
## 准备工作
Node.js的使用需要进行一些准备工作,包括安装Node.js、配置开发环境以及了解Node.js的核心模块。接下来将逐一介绍这些准备工作。
### 3. 构建基础服务器
在本章中,我们将通过Node.js来创建一个基础服务器。我们将使用Node.js的内置HTTP模块来创建服务器,并处理HTTP请求和响应。
#### 3.1 创建Node.js项目
首先,我们需要创建一个新的Node.js项目。打开命令行界面,进入你想要创建项目的目录,并执行以下命令:
```bash
mkdir my-server
cd my-server
npm init -y
```
这将在当前目录下创建一个名为`my-server`的文件夹,并初始化一个新的Node.js项目。`npm init -y`命令会使用默认选项创建一个`package.json`文件,用于管理项目的依赖和配置。
#### 3.2 使用HTTP模块创建服务器
接下来,我们将使用Node.js的HTTP模块来创建服务器。在项目的根目录下创建一个名为`server.js`的文件,并将以下代码复制到文件中:
```javascript
const http = require('http');
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('Hello, World!');
});
const port = 3000;
server.listen(port, () => {
console.log(`Server running at http://localhost:${port}/`);
});
```
在上面的代码中,我们使用`http.createServer()`方法创建一个HTTP服务器。该方法接受一个回调函数作为参数,用于处理每个HTTP请求。
在回调函数中,我们设置了响应的状态码为200,设置了响应头的`Content-Type`为`text/plain`,并发送了一个简单的字符串作为响应体。
最后,我们使用`server.listen()`方法指定服务器监听的端口号,并在回调函数中打印出服务器运行的URL。
#### 3.3 处理HTTP请求和响应
让我们来测试一下我们刚刚创建的服务器。在命令行界面中,进入项目的根目录,并执行以下命令启动服务器:
```bash
node server.js
```
如果一切顺利,你将在命令行中看到以下输出:
```
Server running at http://localhost:3000/
```
现在,打开浏览器并访问`http://localhost:3000/`,你将看到浏览器中显示了`Hello, World!`这个字符串。这表明我们的服务器已成功处理了HTTP请求,并返回了响应。
#### 3.4 静态文件服务器
除了简单的响应字符串,Node.js还可以用于创建更复杂的服务器,例如静态文件服务器。静态文件服务器可以用于提供网站的静态资源,如HTML、CSS、JavaScript文件和图像文件。
让我们来创建一个简单的静态文件服务器。在`server.js`文件中添加以下代码:
```javascript
const fs = require('fs');
const path = require('path');
const server = http.createServer((req, res) => {
const filePath = path.join(__dirname, 'public', req.url === '/' ? 'index.html' : req.url);
const contentType = getContentType(filePath);
fs.readFile(filePath, (err, content) => {
if (err) {
if (err.code === 'ENOENT') {
res.statusCode = 404;
res.end('Not Found');
} else {
res.statusCode = 500;
res.end('Internal Server Error');
}
} else {
res.statusCode = 200;
res.setHeader('Content-Type', contentType);
res.end(content);
}
});
});
function getContentType(filePath) {
const extname = path.extname(filePath);
switch (extname) {
case '.html':
return 'text/html';
case '.css':
return 'text/css';
case '.js':
return 'text/javascript';
case '.png':
return 'image/png';
case '.jpg':
case '.jpeg':
return 'image/jpeg';
default:
return 'application/octet-stream';
}
}
// 省略服务器启动部分的代码
```
在上述代码中,我们首先引入了`fs`和`path`模块,用于处理文件操作和路径相关的功能。
接下来,在`server.createServe()`的回调函数中,我们根据请求的URL路径拼接出文件的绝对路径,并使用`getContentType()`函数获取文件的Content-Type。
然后,我们使用`fs.readFile()`方法读取文件内容。如果读取过程中发生了错误,我们将根据不同的错误类型返回不同的响应码和响应内容。如果读取成功,我们将返回200状态码,设置合适的响应头,并发送文件内容作为响应体。
最后,我们在服务器启动前省略的部分添加了`getContentType()`函数,根据文件的扩展名返回对应的Content-Type。
现在,将一些静态文件(如index.html、style.css、script.js)放入`public`文件夹中,并启动服务器。你可以尝试访问不同的静态文件URL,服务器将会返回相应的文件内容。
这样,我们就创建了一个简单的静态文件服务器,可以用于构建基于Node.js的Web应用程序。
## 数据存储与管理
在构建服务器端应用程序时,数据存储与管理是至关重要的一部分。Node.js可以与多种数据库进行交互,并且使用ORM(对象关系映射)框架可以简化数据库操作。接下来,我们将深入探讨数据存储与管理的相关内容。
### 4.1 连接数据库
在Node.js中,可以使用各种库来连接数据库,比如MySQL、MongoDB、PostgreSQL等。我们将演示如何使用Node.js与MongoDB进行连接,并进行基本的数据读写操作。在这里,我们将使用Mongoose作为Node.js与MongoDB的连接工具。
```javascript
// 引入Mongoose库
const mongoose = require('mongoose');
// 连接MongoDB数据库
mongoose.connect('mongodb://localhost/mydatabase', { useNewUrlParser: true, useUnifiedTopology: true })
.then(() => {
console.log('MongoDB connected');
})
.catch((err) => {
console.error('Error connecting to MongoDB', err);
});
```
### 4.2 使用ORM框架操作数据库
ORM框架可以帮助开发者使用面向对象的方式来操作数据库,而不必直接编写SQL语句。在Node.js中,我们可以使用Mongoose作为ORM框架来操作MongoDB。以下是一个简单的示例,演示如何定义一个数据模型并进行数据的增删改查操作。
```javascript
// 定义数据模型
const Schema = mongoose.Schema;
const userSchema = new Schema({
username: String,
email: String,
password: String
});
// 创建数据模型
const User = mongoose.model('User', userSchema);
// 插入数据
const newUser = new User({ username: 'John', email: 'john@example.com', password: 'password' });
newUser.save((err, user) => {
if (err) return console.error(err);
console.log('User saved:', user);
});
// 查询数据
User.find({}, (err, users) => {
if (err) return console.error(err);
console.log('All users:', users);
});
// 更新数据
User.updateOne({ username: 'John' }, { email: 'john@example.org' }, (err, res) => {
if (err) return console.error(err);
console.log('Update result:', res);
});
// 删除数据
User.deleteOne({ username: 'John' }, (err) => {
if (err) return console.error(err);
console.log('User deleted');
});
```
### 4.3 实现用户注册和登录功能
在构建Web应用程序时,用户注册和登录功能是必不可少的部分。Node.js可以轻松实现用户的注册和登录功能,通常要涉及到用户输入的验证、密码加密存储等操作。下面是一个简单的示例,演示如何在Node.js中实现用户注册和登录功能。
```javascript
// 用户注册
app.post('/register', (req, res) => {
const { username, email, password } = req.body;
// 对密码进行加密处理
const hashedPassword = bcrypt.hashSync(password, 10);
// 将用户信息存储到数据库
User.create({ username, email, password: hashedPassword }, (err, newUser) => {
if (err) {
res.status(500).send('Error registering new user');
} else {
res.status(200).send('User registered successfully');
}
});
});
// 用户登录
app.post('/login', (req, res) => {
const { email, password } = req.body;
// 在数据库中查找用户信息
User.findOne({ email }, (err, user) => {
if (err || !user || !bcrypt.compareSync(password, user.password)) {
res.status(401).send('Invalid email or password');
} else {
res.status(200).send('Login successful');
}
});
});
```
### 4.4 数据缓存与性能优化
在Node.js应用中,数据缓存和性能优化可以极大地提升系统的响应速度和稳定性。可以使用缓存来存储频繁访问的数据,减少对数据库的访问次数。在Node.js中,可以使用诸如Redis这样的内存数据库来实现数据缓存,以下是一个简单的示例,演示如何在Node.js中使用Redis进行数据缓存。
```javascript
// 引入Redis库
const redis = require('redis');
// 连接Redis服务器
const client = redis.createClient();
// 设置数据缓存
client.set('dashboard_data', JSON.stringify({/* 缓存数据 */}), 'EX', 60 * 5, (err) => {
if (err) {
console.error('Error setting cache');
} else {
console.log('Cache set successfully');
}
});
// 获取数据缓存
client.get('dashboard_data', (err, data) => {
if (err) {
console.error('Error getting cache');
} else {
console.log('Cached data:', JSON.parse(data));
}
});
```
通过以上示例,我们可以看到如何使用Node.js进行数据库的连接、操作和优化,以及实现用户注册和登录功能。同时,也演示了如何使用Redis进行数据缓存,提升系统性能。在实际开发中,这些都是非常重要的内容,希望读者可以根据这些示例进一步学习和探索。
## 5. 异步编程和事件驱动
异步编程和事件驱动是Node.js的核心特性之一,这使得它能够高效处理大量并发请求。在本章中,我们将探讨如何利用Node.js的异步特性进行编程,并使用事件驱动的方式处理各种操作。
### 5.1 了解Node.js的事件循环机制
Node.js使用单线程的事件循环机制来处理异步操作。事件循环机制中有几个重要的概念:
- 事件循环:事件循环不断地从事件队列中取出事件并执行,直到队列为空。
- 事件队列:事件队列用于存储事件和回调函数,当某个事件触发时,对应的回调函数会被添加到事件队列中。
- 触发器:触发器用于触发某个事件,当事件触发时,对应的回调函数会被添加到事件队列中。
- 回调函数:回调函数是一种特殊的函数,它会在某个事件触发时被调用。
了解Node.js的事件循环机制对于理解它的异步编程方式非常重要,我们可以利用这种方式编写高效的、非阻塞的代码。
### 5.2 使用回调函数处理异步操作
在Node.js中,回调函数是处理异步操作的常用方式。当某个异步操作完成时,回调函数会被调用,我们可以在回调函数中处理操作的结果。
下面是一个使用回调函数处理异步文件读取的例子:
```java
const fs = require('fs');
fs.readFile('example.txt', 'utf8', (err, data) => {
if (err) {
console.error(err);
return;
}
console.log(data);
});
```
在上面的代码中,我们调用了`fs.readFile`函数来读取文件,当文件读取完成后,回调函数会被调用并传递读取到的数据或错误信息。
### 5.3 Promise和async/await的使用
除了使用回调函数外,Node.js还支持使用Promise和async/await来处理异步操作。这两种方式可以使代码更容易理解和维护。
通过使用Promise,我们可以将异步操作封装成一个Promise对象,并通过then和catch方法来处理操作的结果。
下面是一个使用Promise处理异步文件读取的例子:
```java
const fs = require('fs');
const readFile = (filename) => {
return new Promise((resolve, reject) => {
fs.readFile(filename, 'utf8', (err, data) => {
if (err) {
reject(err);
} else {
resolve(data);
}
});
});
};
readFile('example.txt')
.then(data => {
console.log(data);
})
.catch(err => {
console.error(err);
});
```
使用async/await可以更加简化异步操作的处理,使其看起来像是同步的代码。
下面是一个使用async/await处理异步文件读取的例子:
```java
const fs = require('fs');
const readFile = (filename) => {
return new Promise((resolve, reject) => {
fs.readFile(filename, 'utf8', (err, data) => {
if (err) {
reject(err);
} else {
resolve(data);
}
});
});
};
const main = async () => {
try {
const data = await readFile('example.txt');
console.log(data);
} catch (err) {
console.error(err);
}
};
main();
```
### 5.4 使用事件触发器和事件监听器
除了使用回调函数、Promise和async/await处理异步操作外,我们还可以使用事件触发器和事件监听器来进行事件驱动编程。
Node.js的核心模块`events`提供了事件触发器和事件监听器的功能,我们可以自定义事件并通过触发器触发事件,然后使用监听器处理事件。
下面是一个简单的例子:
```java
const EventEmitter = require('events');
class MyEmitter extends EventEmitter {}
const myEmitter = new MyEmitter();
myEmitter.on('foo', () => {
console.log('foo event is triggered');
});
myEmitter.emit('foo');
```
在上面的代码中,我们使用`on`方法来添加事件监听器,使用`emit`方法来触发事件。当事件被触发时,对应的监听器会被执行。
通过使用事件触发器和事件监听器,我们可以实现更复杂的事件驱动逻辑,如处理请求、处理数据库操作、进行消息传递等。
在本章中,我们学习了Node.js的异步编程和事件驱动的核心概念,了解了事件循环机制、回调函数、Promise和async/await的使用方式,以及事件触发器和事件监听器的使用方法。这些知识将帮助我们更好地理解和利用Node.js的强大功能,编写高效的服务器端应用程序。
### 6. 安全性和性能优化
在构建服务器端应用程序时,安全性和性能优化是至关重要的。本章将介绍如何防止常见的安全漏洞,优化服务器性能和响应时间,并使用负载均衡和集群技术来提高系统的稳定性和可靠性。
#### 6.1 防止常见的安全漏洞
在开发Node.js应用程序时,需要注意防止常见的安全漏洞,如跨站脚本攻击(XSS)、跨站请求伪造(CSRF)、SQL注入等。可以通过一些常用的安全措施来加强应用程序的安全性,例如:
- 对用户输入进行有效性验证和过滤,避免直接拼接用户输入的数据到SQL查询中
- 使用HTTPS协议传输敏感数据,如用户登录信息和支付信息
- 设置合适的CORS(跨源资源分享)策略,限制跨域请求
- 使用安全的认证和授权机制,如JWT(JSON Web Token)来保护API接口
#### 6.2 优化服务器性能和响应时间
Node.js在处理高并发和I/O密集型操作方面具有优势,但在实际应用中仍然需要注意性能优化。一些常见的性能优化方法包括:
- 使用适当的缓存机制,如Redis缓存常用数据
- 使用压缩算法减小网络传输的数据量,提高响应速度
- 使用性能监控工具进行性能分析,如Node.js的内置性能分析工具和其他第三方工具
- 优化数据库查询,使用合适的索引和查询方式
#### 6.3 使用负载均衡和集群技术
为了提高系统的稳定性和可靠性,可以考虑使用负载均衡和集群技术。负载均衡可以将请求分发到多个服务器上,实现流量均衡,提高系统的吞吐量和可用性;集群技术可以实现多台服务器之间的数据同步和故障转移,降低单点故障的风险。
#### 6.4 安全性和性能优化的最佳实践
最后,需要总结一些安全性和性能优化的最佳实践,包括:
- 定期进行安全漏洞扫描和修复
- 使用最新的Node.js版本和相关库,及时更新依赖包
- 设计合理的系统架构,避免过度复杂和冗余
- 进行压力测试和容量规划,保证系统在高负载下的稳定性和可靠性
通过以上的安全性和性能优化措施,可以帮助开发者构建更加稳定、安全和高性能的Node.js服务器端应用程序。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《xr》是一本以数据结构与算法为起点,深入介绍了版本控制、网页开发、服务器端应用程序、数据库设计、前端框架、容器技术、集群管理以及持续集成等多个领域的专栏。从初级到高级,通过文章标题如“初探数据结构与算法:从入门到应用”、“使用Git进行版本控制及团队协作”和“Node.js入门:构建简单的服务器端应用程序”等,读者可以逐步了解和掌握相关知识。同时,本专栏还包括了对于RESTful API安全与认证机制、微服务架构设计原则与实践以及基于GitLab的持续集成与持续交付等话题的深入讨论。精心挑选的主题和简洁明了的内容使得读者能够全面掌握这些技术,并应用于实际项目中。无论是初学者还是有经验的开发者,都能从本专栏中获得丰富的知识和实践经验,使自己在相关领域的技术能力得到提升。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
从Python脚本到交互式图表:Matplotlib的应用案例,让数据生动起来

# 1. Matplotlib的安装与基础配置
在这一章中,我们将首先讨论如何安装Matplotlib,这是一个广泛使用的Python绘图库,它是数据可视化项目中的一个核心工具。我们将介绍适用于各种操作系统的安装方法,并确保读者可以无痛地开始使用Matplotlib
【提高图表信息密度】:Seaborn自定义图例与标签技巧
# 1. Seaborn图表的简介和基础应用
Seaborn 是一个基于 Matplotlib 的 Python 数据可视化库,它提供了一套高级接口,用于绘制吸引人、信息丰富的统计图形。Seaborn 的设计目的是使其易于探索和理解数据集的结构,特别是对于大型数据集。它特别擅长于展示和分析多变量数据集。
## 1.1 Seaborn
【数据集加载与分析】:Scikit-learn内置数据集探索指南

# 1. Scikit-learn数据集简介
数据科学的核心是数据,而高效地处理和分析数据离不开合适的工具和数据集。Scikit-learn,一个广泛应用于Python语言的开源机器学习库,不仅提供了一整套机器学习算法,还内置了多种数据集,为数据科学家进行数据探索和模型验证提供了极大的便利。本章将首先介绍Scikit-learn数据集的基础知识,包括它的起源、
Pandas数据转换:重塑、融合与数据转换技巧秘籍

# 1. Pandas数据转换基础
在这一章节中,我们将介绍Pandas库中数据转换的基础知识,为读者搭建理解后续章节内容的基础。首先,我们将快速回顾Pandas库的重要性以及它在数据分析中的核心地位。接下来,我们将探讨数据转换的基本概念,包括数据的筛选、清洗、聚合等操作。然后,逐步深入到不同数据转换场景,对每种操作的实际意义进行详细解读,以及它们如何影响数
高级概率分布分析:偏态分布与峰度的实战应用

# 1. 概率分布基础知识回顾
概率分布是统计学中的核心概念之一,它描述了一个随机变量在各种可能取值下的概率。本章将带你回顾概率分布的基础知识,为理解后续章节的偏态分布和峰度概念打下坚实的基础。
## 1.1 随机变量与概率分布
Keras注意力机制:构建理解复杂数据的强大模型

# 1. 注意力机制在深度学习中的作用
## 1.1 理解深度学习中的注意力
深度学习通过模仿人脑的信息处理机制,已经取得了巨大的成功。然而,传统深度学习模型在处理长序列数据时常常遇到挑战,如长距离依赖问题和计算资源消耗。注意力机制的提出为解决这些问题提供了一种创新的方法。通过模仿人类的注意力集中过程,这种机制允许模型在处理信息时,更加聚焦于相关数据,从而提高学习效率和准确性。
## 1.2
【循环神经网络】:TensorFlow中RNN、LSTM和GRU的实现

# 1. 循环神经网络(RNN)基础
在当今的人工智能领域,循环神经网络(RNN)是处理序列数据的核心技术之一。与传统的全连接网络和卷积网络不同,RNN通过其独特的循环结构,能够处理并记忆序列化信息,这使得它在时间序列分析、语音识别、自然语言处理等多
PyTorch超参数调优:专家的5步调优指南

# 1. PyTorch超参数调优基础概念
## 1.1 什么是超参数?
在深度学习中,超参数是模型训练前需要设定的参数,它们控制学习过程并影响模型的性能。与模型参数(如权重和偏置)不同,超参数不会在训练过程中自动更新,而是需要我们根据经验或者通过调优来确定它们的最优值。
## 1.2 为什么要进行超参数调优?
超参数的选择直接影响模型的学习效率和最终的性能。在没有经过优化的默认值下训练模型可能会导致以下问题:
- **过拟合**:模型在
NumPy在金融数据分析中的应用:风险模型与预测技术的6大秘籍

# 1. NumPy基础与金融数据处理
金融数据处理是金融分析的核心,而NumPy作为一个强大的科学计算库,在金融数据处理中扮演着不可或缺的角色。本章首先介绍NumPy的基础知识,然后探讨其在金融数据处理中的应用。
## 1.1 NumPy基础
NumPy(N
硬件加速在目标检测中的应用:FPGA vs. GPU的性能对比
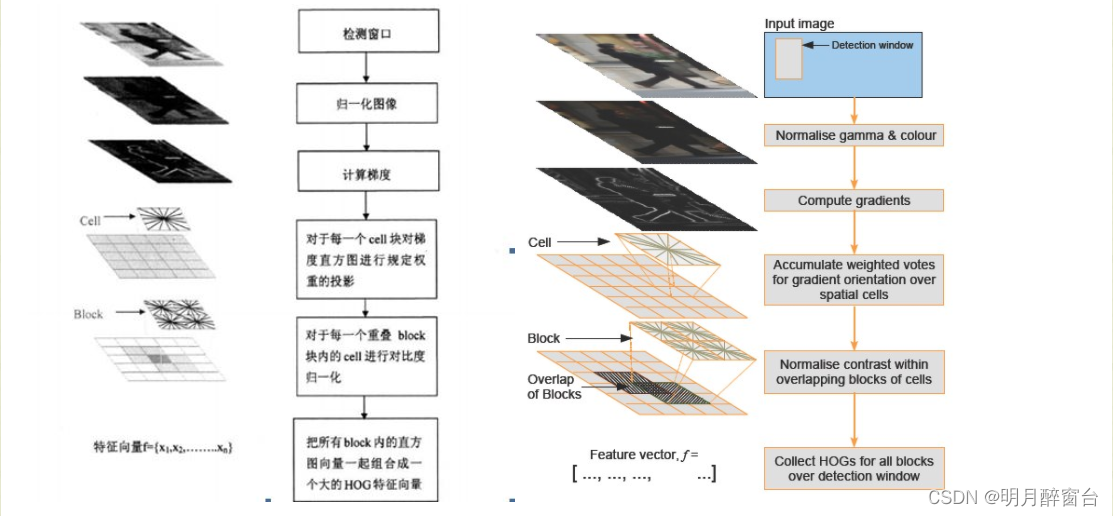
# 1. 目标检测技术与硬件加速概述
目标检测技术是计算机视觉领域的一项核心技术,它能够识别图像中的感兴趣物体,并对其进行分类与定位。这一过程通常涉及到复杂的算法和大量的计算资源,因此硬件加速成为了提升目标检测性能的关键技术手段。本章将深入探讨目标检测的基本原理,以及硬件加速,特别是FPGA和GPU在目标检测中的作用与优势。
## 1.1 目标检测技术的演进与重要性
目标检测技术的发展与深度学习的兴起紧密相关
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )