迁移学习深度探索:图像识别数据增强技术全接触
发布时间: 2024-09-02 12:38:16 阅读量: 279 订阅数: 34 

深度学习中的迁移学习:图像识别的加速器
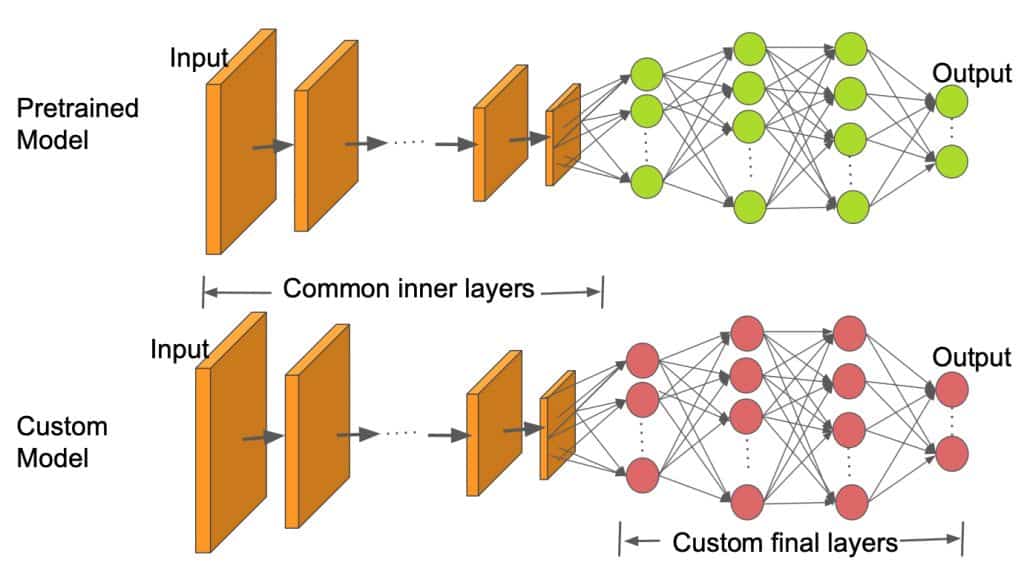
# 1. 迁移学习与图像识别基础
## 1.1 迁移学习简介
迁移学习是一种机器学习方法,允许我们将一个问题上学到的知识应用到另一个相关问题上。在图像识别领域,它通常指的是利用在一个大型图像数据集上预训练的模型,来解决另一个具有相似特征空间但样本数量有限的数据集上的问题。例如,使用在ImageNet数据集上预训练的深度卷积神经网络(CNN)模型作为起点,来识别医学图像中的病变。
## 1.2 图像识别的重要性
图像识别是计算机视觉的核心问题之一,它涉及到从图片或视频中识别和处理信息。在医疗、安防、自动驾驶等众多领域中,图像识别技术的应用为智能化提供了可能,提高了工作效率,加强了安全性。
## 1.3 迁移学习在图像识别中的应用
在迁移学习的实际应用中,我们通常对预训练模型进行微调,即在新的数据集上继续训练模型的全部或部分层,以适应新的特定任务。这一过程包括替换顶层分类器以适应新的类别数,以及可选地调整网络中的其他层来适应新数据的特征。
```python
# 示例代码:使用预训练模型进行迁移学习
from tensorflow.keras.applications import VGG16
from tensorflow.keras.layers import Dense
from tensorflow.keras.models import Model
# 加载预训练的VGG16模型
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
# 在顶层添加新的层以适配新的任务
x = base_model.output
x = Dense(1024, activation='relu')(x)
predictions = Dense(num_classes, activation='softmax')(x)
# 构建最终模型
model = Model(inputs=base_model.input, outputs=predictions)
# 冻结预训练模型的层
for layer in base_model.layers:
layer.trainable = False
# 编译模型
***pile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
```
在上述代码中,我们使用了TensorFlow框架加载了VGG16模型,然后添加了新的全连接层来适配新的分类任务。最后我们编译模型,为训练做准备。通过调整训练过程中模型的参数,我们能进一步提高模型对特定图像识别任务的准确率。
# 2. 数据增强技术理论
## 2.1 数据增强的目的与重要性
### 2.1.1 数据增强在图像识别中的作用
在图像识别和机器学习任务中,模型的性能往往受到可用数据量的直接影响。数据增强技术的引入,其主要作用在于通过一系列变换来人为地扩展原始数据集,从而提高模型的泛化能力。
数据增强通过以下方式对图像识别产生积极影响:
- **缓解过拟合**:增强技术通过对已有图像执行各种变换,创造新的图片,减少模型对训练数据的过度依赖。
- **提升鲁棒性**:通过数据增强,模型可以更好地适应新的、未曾见过的数据,因为增强过程中产生的数据变化模拟了现实世界中的各种变化。
- **提高准确率**:对数据集的增加,有助于模型更好地学习到数据的内在结构,从而使模型在识别和分类任务上达到更高的准确率。
### 2.1.2 数据多样性的需求分析
数据多样性是提高模型泛化能力的关键因素之一。在图像识别领域,数据多样性尤其重要,因为现实世界中的图像往往变化多端,包含了各种不同的条件和因素,例如光照变化、遮挡、变形等。
为了在数据集中模拟出这些变化,数据增强技术可以被用来:
- **模仿现实世界的条件**:通过旋转、缩放、裁剪等方式模拟不同的拍摄角度和距离。
- **增强类内变化**:通过对同一物体进行颜色变化、对比度调整等变换来模拟不同的视觉效果。
- **模拟噪声与损坏**:引入高斯噪声、模糊效果等,训练模型能够更好地处理不完美条件下的图像。
## 2.2 常见的数据增强技术
### 2.2.1 几何变换
几何变换是数据增强的一个重要分支,它包括一系列操作,比如平移、旋转、缩放、翻转等,这些操作可以在不改变图像内容本质的情况下,创造出新的训练样本。
几何变换操作通常包括:
- **平移**:图像沿着x轴或y轴移动一定距离,模拟物体在画面中的不同位置。
- **旋转**:图像绕着中心点或边缘旋转,这在处理非正向排列的图像时特别有用。
- **缩放**:改变图像的尺寸,模拟物体在不同距离下的外观。
- **翻转**:水平或垂直翻转图像,以模拟镜像效果。
几何变换对模型的影响通常表现在模型的空间不变性上,使模型对空间位置的改变具有更好的适应能力。
### 2.2.2 颜色空间变换
颜色空间变换涉及改变图像颜色,以此模拟不同的光照条件和颜色偏差。这不仅增加了图像的多样性,而且对模型在不同颜色环境下的识别能力提出了更高的要求。
颜色空间变换的常用方法包括:
- **亮度调整**:增亮或减暗图像,模拟不同的照明条件。
- **对比度调整**:改变图像的对比度,使得模型能识别出在亮度变化中保持不变的特征。
- **颜色饱和度调整**:增加或减少颜色的饱和度,测试模型对颜色变化的鲁棒性。
通过这些变换,模型可以更加关注图像中的形状、纹理等其他特征,而不是简单地依赖颜色信息。
### 2.2.3 噪声注入与滤波技术
在现实世界中,图像往往受到各种噪声的影响,如传感器噪声、压缩噪声等。因此,数据增强中引入噪声注入与滤波技术,以提高模型对噪声的抵抗力。
噪声注入和滤波技术包括:
- **高斯噪声**:向图像中添加一定量的高斯噪声,模拟图像的随机噪声干扰。
- **椒盐噪声**:引入椒盐噪声,模拟图像的脉冲干扰和缺陷。
- **滤波**:应用各种滤波器(例如高斯滤波器、中值滤波器)对图像进行平滑处理。
在加入噪声和进行滤波后,模型的训练将帮助其更好地处理不干净的数据,并可能提高其在实际应用中的表现。
## 2.3 数据增强方法的比较与选择
### 2.3.1 不同增强方法对模型性能的影响
不同的数据增强方法会对模型训练和测试性能产生不同的影响。这取决于数据增强的类型、参数设置,以及模型本身的复杂性。
模型在经过数据增强之后,其性能变化可以从以下几个方面评估:
- **准确率**:增强后的模型在验证集上的准确率是否得到提升。
- **鲁棒性**:模型对不同类型增强操作后的数据的适应性。
- **过拟合情况**:观察增强数据后模型是否减少了过拟合现象。
为了具体分析不同增强方法的影响,可以构建一个实验设置,通过对比实验前后模型在各项指标上的变化,来量化增强的效果。
### 2.3.2 实战案例分析:如何选择合适的数据增强策略
在实际操作中,选择合适的数据增强策略需要考虑到多个方面,包括数据集的特性、任务需求以及模型的架构。
- **数据集特性**:如果数据集本身包含了多样化的场景和条件,那么简单的增强方法可能就足够了。对于较小或者变化较少的数据集,可能需要更多的增强策略来提高多样性。
- **任务需求**:在某些任务中,比如医学图像分析,需要更加细致和专业的增强方法,以确保模拟真实世界中的变化。
- **模型架构**:一些复杂的模型,比如深度卷积神经网络(CNNs),可以从更复杂的增强技术中受益,以更好地学习数据的特征。
最终,选择合适的数据增强策略需要结合实验结果和专家经验。通过不断迭代和调整,找到最适合当前任务和模型的数据增强方案。
# 3. 数据增强实践与应用
在现代的图像识别任务中,数据增强技术扮演了极其重要的角色。它的应用不仅限于传统图像处理库,例如OpenCV,更深入到深度学习框架的核心模块中,比如TensorFlow和PyTorch。本章将深入探讨数据增强的实践工具与库,并展示如何从零开始实现数据增强流程,以及它在不同图像识别任务中的应用。
## 3.1 数据增强的实践工具与库
数据增强技术的实现离不开各种工具与库的支持。从传统的图像处理库到现代的深度学习框架,不同的工具和库提供了不同的数据增强方法。
### 3.1.1 图像处理常用库介绍(如OpenCV)
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉和机器学习软件库。OpenCV提供了许多用于图像增强的函数,包括但不限于滤波、形态变换、几何变换、颜色空间转换等。
**代码实现:**
```python
import cv2
import numpy as np
# 读取图像
image = cv2.imread('image.jpg')
# 转换为灰度图像
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 应用高斯模糊
blurred_image = cv2.GaussianBlur(gray_image, (5, 5), 0)
# 边缘检测
edges = cv2.Canny(blurred_image, 100, 200)
# 显示结果
cv2.imshow('Original Image', image)
cv2.imshow('Gray Image', gray_image)
cv2.imshow('Blurred Image', blurred_image)
cv2.imshow('Edges', edges)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
**逻辑分析:**
以上代码展示了如何使用OpenCV进行基本的图像处理操作。首先读取一张图像,然后将其转换为灰度图像,接着应用高斯模糊以去除噪声,最后使用Canny算法进行边缘检测。
### 3.1.2 深度学习框架中的数据增强模块(如TensorFlow, PyTorch)
深度学习框架为了方便用户操作,通常内置了强大的数据预处理与增强模块。TensorFlow提供了`tf.data.Dataset` API,而PyTorch提供了`torchvision.transforms`模块。
**代码实现(PyTorch示例):**
```python
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义数据转换
data_transforms = ***pose([
transforms.Resize(256), # 调整图像大小
transforms.CenterCrop(224), # 中心裁剪到224x224
transforms.ColorJitter(brightness=0.5, contrast=0.5), # 颜色抖动
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 转换为Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])
# 创建数据集
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=data_transforms)
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# 训练循环
for epoch in range(num_epochs):
for images, labels in train_loader:
# 训练过程代码省略
pass
```
**参数说明:**
- `***pose`: 将多个数据转换操作组合在一起。
- `transforms.Resize` 和 `transforms.CenterCrop`: 调整图像大小并裁剪。
- `transforms.ColorJitter`: 随机改变图像的亮度和对比度。
- `transforms.RandomHorizontalFl

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【本土化术语详解】:GMW14241中的术语本土化实战指南

# 摘要
术语本土化作为国际交流与合作的关键环节,在确保信息准确传达及提升用户体验中扮演重要角色。本文深入探讨了GMW14241术语本土化的理论与实践,阐述了本土化的目标、原则、语言学考量以及标准化的重要性。文中详述了本土化流程的规划与实施,本土化术语的选取与调整,以及质量控制的标准和措施。案例分析部分对成功本土化的术语进行实例研究,讨论了本土化过程中遇到的挑战及其解决方案,并提出了在实际应用中的反馈与持续改进策略。未
持续集成中文档版本控制黄金法则

# 摘要
随着软件开发流程的日益复杂,持续集成和版本控制成为提升开发效率和产品质量的关键实践。本文首先介绍了持续集成与版本控制的基础知识,探讨了不同版本控制系统的优劣及其配置。随后,文章深入解
Cyclone进阶操作:揭秘高级特性,优化技巧全攻略

# 摘要
Cyclone是一种注重安全性的编程语言,本论文首先概述了Cyclone的高级特性,深入解析了其核心概念,包括类型系统、并发模型和内存管理。接着,提供了实践指南,包括高级函数与闭包、模块化编程和构建部署策略。文章进一步探讨了优化技巧与性能调优,涵盖性能监控、代码级别和系统级别的优化。此外,通过分析实际项目案例,展示了Cyclone在
三菱MR-JE-A伺服电机网络功能解读:实现远程监控与控制的秘诀

# 摘要
本文对三菱MR-JE-A伺服电机的网络功能进行了全面的探讨。首先,介绍了伺服电机的基础知识,然后深入讨论了网络通信协议的基础理论,并详细分析了伺服电机网络功能的框架及其网络安全性。接着,探讨了远程监控的实现方法,包括监控系统架构和用户交互界面的设计。文章还探讨了远程控制的具体方法和实践,包括控制命令
【从图纸到代码的革命】:探索CAD_CAM软件在花键加工中的突破性应用

# 摘要
随着制造业的快速发展,CAD/CAM软件的应用逐渐兴起,成为提高设计与制造效率的关键技术。本文探讨了CAD/CAM软件的基本理论、工作原理和关键技术,并分析了其在花键加工领域的具体应用。通过对CAD/CAM软件工作流程的解析和在花键加工中设计与编程的案例分析,展现了其在提高加工精度和生产效率方面的创新应用。同时,文章展望了CAD/CAM软件未来的发展趋势,重
【S7-200 Smart通信编程秘笈】:通过KEPWARE实现数据交互的极致高效

# 摘要
本文详细探讨了S7-200 Smart PLC与KEPWARE通信协议的应用,包括KEPWARE的基础知识、数据交互、优化通信效率、故障排除、自动化项目中的应用案例以及深度集成与定制化开发。文章深入解析了KEPWARE的架构、工作原理及与PLC的交互模式,并比较了多种工业通信协议,为读者提供了选择指南。同时,介绍了数据映射规则、同步实现、通信效率优化的技巧和故障排除方法。此外,文章还
【CAN2.0网络设计与故障诊断】:打造高效稳定通信环境的必备指南

# 摘要
本文系统地介绍了CAN2.0网络的基础知识、硬件设计、协议深入解析、故障诊断技术、性能优化以及安全防护措施。首先概述了CAN2.0网络的技术基础,接着详细探讨了其硬件组成和设计原则,包括物理层设计、控制器与收发器选择以及网络拓扑结构的构建。文章深入解析了CAN协议的数据封装、时间触发与容错机制,并探讨了其扩展标准。针对网络故障,本文提供了诊断理论、工具使用和案例分析的详细讨论。最后,文章针
VISA函数实战秘籍:测试与测量中的高效应用技巧
# 摘要
VISA(虚拟仪器软件架构)函数库在测试测量领域中扮演着关键角色,它为与各种测试仪器的通信提供了一套标准的接口。本文首先介绍了VISA函数库的基础知识,包括其作用、组成、适用范围以及安装与配置的详细步骤。接着,本文通过编程实践展示了如何利用VISA函数进行数据读写操作和状态控制,同时也强调了错误处理和日志记录的
【完美转换操作教程】:一步步Office文档到PDF的转换技巧

# 摘要
本文旨在提供关于Office文档到PDF格式转换的全面概览,从Office软件内置功能到第三方工具的使用技巧,深入探讨了转换过程中的基础操作、高级技术以及常见问题的解决方法。文章分析了在不同Office应用(Word, Excel, PowerPoint)转换为PDF时的准备工作、操作步骤、格式布局处理和特定内容的兼容性。同时,文中还探讨了第三方软件如
【组态王自动化脚本编写】:提高效率的12个关键脚本技巧
# 摘要
组态王自动化脚本作为一种高效的自动化编程工具,在工业自动化领域中扮演着关键角色。本文首先概述了组态王自动化脚本的基本概念及其在实践中的应用。接着,深入探讨了脚本基础,包括选择合适的脚本语言、脚本组件的使用、以及脚本错误处理方法。本文重点介绍了脚本优化技巧,涵盖代码重构、性能提升、可维护性增强及安全性考虑。通过案例分析,文中展示了组态王脚本在数据处理、设备控制和日志管理等实际应用中的效果。最后,本文展望了组态王脚本的进阶技术及未来发展趋势,提供了一系列先进技术和解决方
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )