【缓存机制高效构建】:数据结构在JavaScript中的实战应用
发布时间: 2024-09-14 09:36:30 阅读量: 124 订阅数: 52 

Scratch图形化编程语言入门与进阶指南

# 1. 缓存机制与数据结构基础
在信息技术领域,缓存机制是优化性能和提高数据处理效率的关键技术之一。缓存能够存储临时数据,使得对这些数据的重复访问变得更加迅速。理解缓存机制的运作离不开对基础数据结构的深入探讨,因为数据结构的选择直接影响缓存的性能表现。本章节将为读者介绍缓存机制的基本概念,并探讨在缓存中经常使用到的数据结构,如哈希表、链表、树等。我们将从数据结构的角度来解析它们在缓存中的应用,为进一步深入理解后续章节中的JavaScript缓存策略打下坚实的基础。
# 2. JavaScript中的缓存策略
### 2.1 常见的缓存机制解析
在Web开发中,缓存策略是提升应用性能的关键技术之一。通过缓存技术,开发者能够减少数据的重复处理,提高数据检索的效率,从而加快页面加载速度。在JavaScript中,常见的缓存策略可以分为本地缓存与服务器缓存,以及它们的有效性与失效策略。
#### 2.1.1 本地缓存与服务器缓存
**本地缓存**:
本地缓存是存储在客户端(用户浏览器)的数据副本。它主要包括了HTTP缓存和应用内缓存(如IndexedDB、Web Storage等)。利用这些缓存机制,可以实现页面快速加载和离线访问等功能。
**服务器缓存**:
服务器缓存是将数据存储在服务器端,通常包括代理缓存(如CDN)、应用服务器缓存(如Redis)以及数据库缓存。服务器缓存能够减少数据库的访问次数和网络带宽,提高整体响应速度。
```javascript
// 示例:使用localStorage进行本地缓存
localStorage.setItem('cachedData', JSON.stringify({key: 'value'}));
const data = JSON.parse(localStorage.getItem('cachedData'));
```
在上述代码中,我们演示了如何使用`localStorage`存储和获取数据。这种方法适合缓存少量不经常变化的数据。
**服务器端示例**:
```javascript
// 示例:在Node.js中使用Redis进行服务器端缓存
const redis = require('redis');
const client = redis.createClient();
// 设置缓存数据
client.set('key', 'value', redis.print);
// 获取缓存数据
client.get('key', (err, data) => {
console.log(data); // 输出 'value'
});
```
在这个示例中,我们通过Node.js和Redis模块设置和获取了服务器端缓存的数据。
#### 2.1.2 缓存的有效性与失效策略
**缓存失效策略**:
- **过期失效**:设定缓存数据的有效期限,时间一到就自动失效。
- **条件失效**:根据数据是否发生变化来决定缓存是否失效。
- **被动失效**:当外部依赖的数据发生变化时,由外部系统通知缓存失效。
**示例**:
```javascript
// HTTP缓存的失效策略
const http = require('http');
const url = require('url');
const options = {
hostname: '***',
path: '/',
headers: {
'Cache-Control': 'max-age=3600' // 缓存有效期为3600秒
}
};
http.get(options, (res) => {
let data = '';
res.on('data', (chunk) => {
data += chunk;
});
res.on('end', () => {
console.log(data);
});
});
```
在这个HTTP客户端请求示例中,我们使用了`Cache-Control`头来指定缓存的有效期。
### 2.2 数据结构在缓存中的作用
缓存技术的关键之一是如何高效地存储和检索数据。不同的数据结构有不同的特点,它们在缓存中的应用也各不相同。
#### 2.2.1 数据结构选择对缓存性能的影响
选择合适的数据结构对缓存性能有显著的影响。例如,使用哈希表可以实现快速的数据检索,而树结构适合数据的排序和范围查询。
- **哈希表**:通过键值对的方式存储数据,通常具有很高的查找效率。
- **树**:如二叉搜索树、红黑树等,可以高效地完成排序、范围查找等操作。
**哈希表示例**:
```javascript
// 哈希表实现
function HashTable() {
this.table = new Array(1024);
this.size = 0;
}
HashTable.prototype.put = function(key, value) {
// 简单的哈希函数
const hash = key % this.table.length;
if (!this.table[hash]) {
this.table[hash] = [];
}
const entry = this.table[hash].find((e) => e.key === key);
if (entry) {
entry.value = value;
} else {
this.table[hash].push({key, value});
this.size++;
}
};
HashTable.prototype.get = function(key) {
const hash = key % this.table.length;
const entry = this.table[hash] && this.table[hash].find((e) => e.key === key);
return entry ? entry.value : null;
};
const hashTable = new HashTable();
hashTable.put('key', 'value');
console.log(hashTable.get('key')); // 输出 'value'
```
**树结构示例**:
```javascript
// 二叉搜索树的简单实现
class TreeNode {
constructor(key, value) {
this.key = key;
this.value = value;
this.left = null;
this.right = null;
}
}
class BinarySearchTree {
constructor() {
this.root = null;
}
insert(key, value) {
// 插入操作,省略具体实现...
}
find(key) {
// 查找操作,省略具体实现...
}
}
// 使用二叉搜索树进行存储和查找
const bst = new BinarySearchTree();
bst.insert('key', 'value');
console.log(bst.find('key').value); // 输出 'value'
```
在这个示例中,我们展示了二叉搜索树的框架和基本操作。
#### 2.2.2 数据结构实例:哈希表与树
为了深入理解哈希表和树在缓存中的应用,我们分析了两种数据结构的实现和它们的优势。
**哈希表优势**:
- **时间复杂度**:平均情况下,哈希表的查找、插入和删除操作的时间复杂度为O(1)。
- **应用**:缓存的数据项可以快速地通过键值对进行访问,非常适用于快速检索的场景。
**树优势**:
- **有序数据**:树结构维护了数据的排序,便于实现范围查询和有序遍历。
- **应用**:适用于需要频繁进行排序或者范围查找的缓存场景。
### 2.3 缓存算法的实现
在缓存管理中,合理的缓存淘汰策略对于保持缓存的有效性至关重要。常用的缓存算法包括最近最少使用(LRU)和最不经常使用(LFU)。
#### 2.3.1 LRU与LFU算法的原理与实现
**LRU(Least Recently Used)**:
LRU算法淘汰最长时间未被使用的数据。实现LRU通常使用双向链表和哈希表的组合。
```javascript
// LRU缓存的简单实现
class LRUCache {
constructor(capacity) {
this.capacity = capacity;
this.cache = new Map();
}
get(key) {
if (!this.cache.has(key)) {
return -1;
}
const val = this.cache.get(key);
this.cache.delete(key);
this.cache.set(key, val);
return val;
}
put(key, value) {
if (this.cache.has(key)) {
this.cache.delete(key);
} else if (this.cache.size >= this.capacity) {
this.cache.delete(this.cache.keys().next().value);
}
this.cache.set(key, value);
}
}
const lruCache = new LRUCache(2);
lruCache.put(1, 1);
lruCache.put(2, 2);
console.log(lruCache.get(1)); // 输出 1
lruCache.put(3, 3); // 此时缓存为 2, 3
console.log(lruCache.get(2)); // 输出 -1 (未找到)
```
**LFU(Least Frequently Used)**:
LFU算法淘汰最不经常使用的数据项,即在给定的窗口期内被访问次数最少的数据项。
```javascript
// LFU缓存的简单实现
class LFUCache {
constructor(capacity) {
this.capacity = capacity;
this.cache = new Map();
}
get(key) {
// LFU的实现较为复杂,需要维护每个数据项的访问频率
// 此处省略具体实现...
}
put(key, val
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨 JavaScript 程序结构和数据结构,旨在帮助开发者提升代码性能和效率。文章涵盖广泛主题,包括:
* 数据结构优化技巧,例如数组与对象性能对比。
* 数据结构实战应用,如链表、树结构和图结构。
* 算法设计与实践,如栈、队列和搜索排序算法。
* 内存管理和垃圾回收机制。
* 数据结构对 JavaScript 性能的影响。
* 数据结构在社交网络算法和前端性能中的应用。
* 二叉搜索树、堆结构和散列表等具体数据结构的深入分析。
* 数据结构瓶颈分析和优化策略。
* 面试必备的 JavaScript 数据结构和算法知识。
通过深入理解数据结构,开发者可以编写出高效、可扩展且可维护的 JavaScript 代码,从而提升应用程序性能并优化用户体验。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【TongWeb8.0新手速成手册】:从零开始的环境搭建与优化指南

# 摘要
本文全面介绍了TongWeb8.0的应用和管理,首先提供了该平台的概述和安装指南,然后深入探讨了环境搭建的最佳实践,包括系统需求的分析、安装步骤以及Web服务器的配置。接着,本文重点分析了TongWeb8.0的核心功能,如应用管理、性能监控和故障排除,强调了性能调优和系统维护的重要性。在高级特性方面,本文详述了集群部署、第三方服务集成和自动化脚本编写等策略。最
ASPEN PLUS 10.0反应器模型深度剖析:从入门到精通
# 摘要
本文综合介绍了ASPEN PLUS 10.0中反应器模型的构建、高级应用、优化以及自定义功能,强调了理论基础在模型搭建中的重要性,包括热力学原理、物性方法和热力学模型的选择。同时,探讨了反应器模型的类型、特性、搭建流程以及高级应用,包括非理想流动模型的应用、参数敏感性分析和优化策略。此外,本文还讨论了ASPEN PLUS的自定义功能和宏编程在实际化工问题中的应用,提供了工业级反应器模型的案例分析。最后,展望了未来趋势,包括数字化工厂的集成、AI/ML技术的应用以及绿色化学原则在化工过程设计中的实践。
# 关键字
ASPEN PLUS;反应器模型;热力学;参数优化;宏编程;数字化工厂
Amlogic S805显示技术进阶:精通显示标准与配置方法
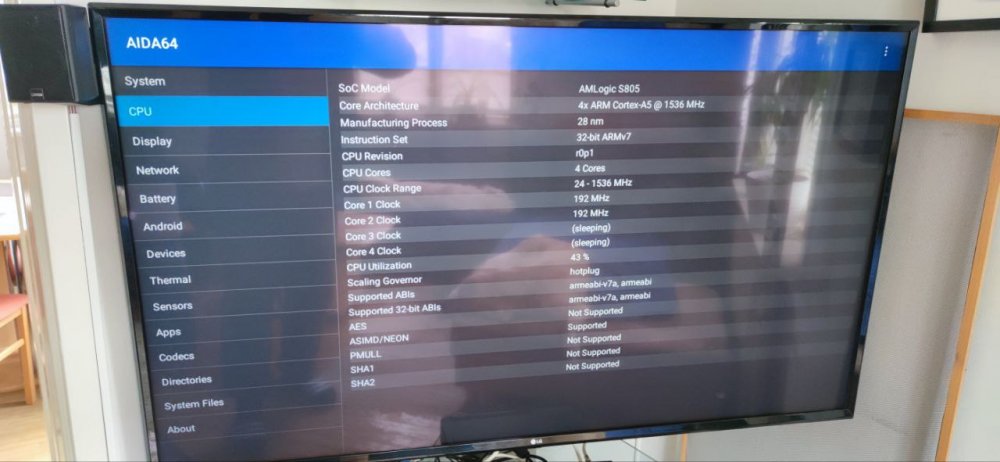
# 摘要
本文系统地介绍了Amlogic S805显示技术的理论基础、配置方法、性能优化和实际应用案例。首先,从显示技术的发展历程讲起,概述了各类显示标准及其在分辨率和刷新率方面的重要性。接着,通过实战角度阐述了Amlogic S805的硬件接口、驱动程序安装配置以及高级显
系统规划与管理师:打造个人记忆宫殿的8个技巧

# 摘要
记忆宫殿是一种古老而强大的记忆增强技术,其起源和科学原理深植于认知心理学。本文探讨了记忆宫
【刷机实战秘笈】:中兴B860AV1.1与晨星MSO9280芯片案例深度剖析
# 摘要
本文全面概述了智能手机刷机的基础知识,深入探讨了中兴B860AV1.1和晨星MSO9280芯片的刷机原理、步骤及其相关工具和环境配置。通过具体案例分析,本文揭示了刷机过程中应关注的芯片特性、系统兼容性以及升级要点。进阶技巧章节着重介绍了刷机脚本编写、数据备份与恢复以及系统性能优化和稳定性提升的策略。最后,本文详细探讨了刷机风险、故障诊断与排除,并为刷机后的检查与维护提供了指导性建议,
LSM6DS3在机器人技术中的应用:引领机器人感知新时代
# 摘要
LSM6DS3传感器作为一款多功能惯性测量单元,在现代机器人技术中扮演了核心角色。本文首先概述了LSM6DS3传感器,并探讨了机器人感知系统的理论基础,包括感知技术的重要性及传感器在决策过程中的作用。接着详细分析了LSM6DS3的工作原理、技术规格以及数据融合和处理算法。随后,本文讨论了LSM6DS3在机器人技术中的实际应用,包括硬件集成和软件编程,并通过应用案
成本效益分析:EIA-481-D中文版对电子元件包装的经济价值

# 摘要
EIA-481-D标准作为电子元件包装行业的指导性文件,对于提升供应链效率、降低成本以及增强企业竞争力具有重要作用。本文从EIA-481-D标准概述开始,深入探讨了电子元件包装的重要性及其在供应链中的作用,特别是如何通过标准化流程提高材料利用率和减少浪费。文章接着分析了该标准所带来的经济效益,包括材料成本、生产效率的提升以及供应链风险的降低。在企业战略规划方
脚本自动化实战:用SecureCRT打造个性化运维脚本
# 摘要
本论文全面介绍了SecureCRT的基础知识及其自动化脚本的编写与应用。首先,概述了SecureCRT的基础概念及其脚本语言的理论基础,包括命令集、脚本结构、变量、数组、控制流程以及高级特性如正则表达式和错误处理。接着,深入探讨了SecureCRT脚本在自动化日常运维任务、远程管理与配置以及安全审计与监控中的实战应用。进一步地,本文探讨了如何通过Secur
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )