迁移学习的模型评估:交叉验证、混淆矩阵与ROC曲线,全面评估模型性能
发布时间: 2024-07-21 05:13:45 阅读量: 95 订阅数: 32 
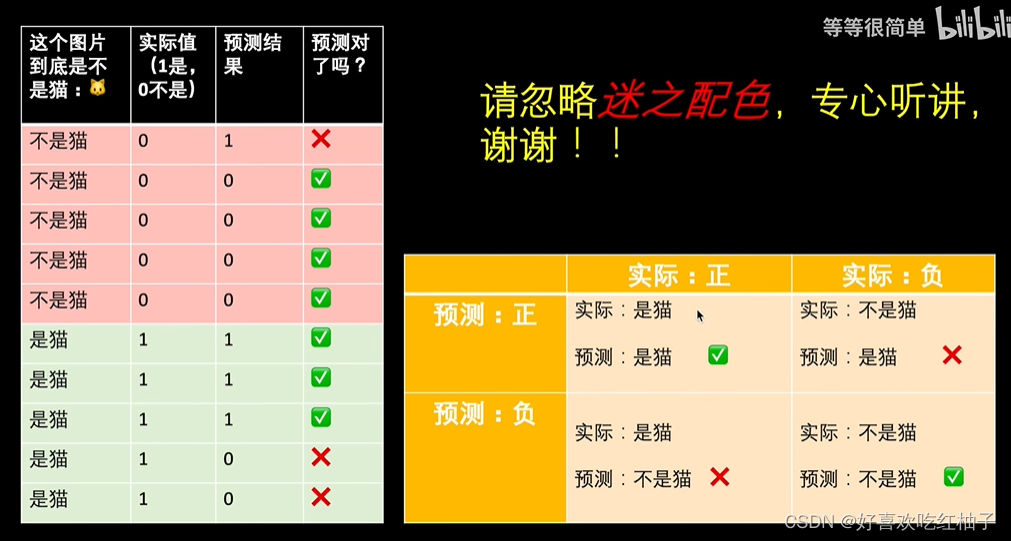
# 1. 迁移学习模型评估概述**
迁移学习是一种利用预训练模型来解决新任务的机器学习技术。评估迁移学习模型的性能至关重要,因为它可以帮助我们了解模型的有效性并指导进一步的改进。
本文将介绍迁移学习模型评估的常用方法,包括交叉验证、混淆矩阵、ROC曲线和综合评估。这些方法提供了全面的评估视角,使我们能够深入了解模型的性能并做出明智的决策。
通过对这些评估方法的深入理解,我们可以有效地评估迁移学习模型,并将其应用于各种现实世界的问题中。
# 2. 交叉验证
### 2.1 交叉验证的类型和原理
交叉验证是一种用于评估机器学习模型泛化性能的技术。它通过将数据集划分为多个子集(称为折),然后使用其中一个子集作为测试集,其余子集作为训练集,来重复训练和评估模型。
#### 2.1.1 k折交叉验证
k折交叉验证是交叉验证最常用的类型。它将数据集随机划分为k个大小相等的折。然后,它对每个折进行以下操作:
- 使用k-1个折作为训练集,剩余的折作为测试集。
- 训练模型并评估其在测试集上的性能。
该过程重复k次,每次使用不同的折作为测试集。最后,模型的性能是k次迭代的平均值。
#### 2.1.2 留一法交叉验证
留一法交叉验证是k折交叉验证的特例,其中k等于数据集中的样本数。在这种情况下,每个样本都单独用作测试集,而其余样本用作训练集。
#### 2.1.3 分层交叉验证
分层交叉验证用于处理类别不平衡数据集。它确保每个折中不同类别的样本比例与原始数据集中相同。这对于评估分类模型的性能非常重要,因为类别不平衡可能会导致模型对多数类别的偏差。
### 2.2 交叉验证的应用
交叉验证有广泛的应用,包括:
#### 2.2.1 模型选择
交叉验证可以用于比较不同模型的性能。通过使用相同的交叉验证策略评估每个模型,我们可以选择在给定数据集上泛化性能最好的模型。
#### 2.2.2 超参数优化
交叉验证可以用于优化模型的超参数。超参数是模型训练过程中不直接学习的参数,例如学习率或正则化系数。通过使用交叉验证,我们可以找到一组超参数,使模型在验证集上获得最佳性能。
```python
import numpy as np
from sklearn.model_selection import KFold
# 定义交叉验证参数
k = 5 # 折数
random_state = 42 # 随机种子
# 载入数据集
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]])
y = np.array([0, 1, 0, 1, 0])
# 创建交叉验证对象
kf = KFold(n_splits=k, random_state=random_state, shuffle=True)
# 遍历折
for train_index, test_index in kf.split(X, y):
# 划分训练集和测试集
X_train, X_test = X[train_index], X[test_index]
y_t
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了迁移学习的方方面面,从入门指南到高级技术。它涵盖了迁移学习算法的优缺点和适用场景,以及在计算机视觉、自然语言处理、医疗、金融和自动驾驶等领域的应用。专栏还探讨了迁移学习的伦理考量、最佳实践、性能指标、模型选择、数据准备、模型评估、部署和维护。通过全面而深入的分析,本专栏为读者提供了对迁移学习的透彻理解,帮助他们掌握这项强大的技术,并将其应用于各种实际问题中。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PLS UDE UAD扩展功能探索:插件与模块使用深度解析
参考资源链接:[UDE入门:Tricore多核调试详解及UAD连接步骤](https://wenku.csdn.net/doc/6412b6e5be7fbd1778d485ca?spm=1055.2635.3001.10343)
# 1. PLS UDE UAD基础介绍
在当今充满活力的信息技术领域,PLS UDE
GrblController教育应用指南:培育未来工程师的创新平台

参考资源链接:[GrblController安装与使用教程](https://wenku.csdn.net/doc/6412b792be7fbd1778d4ac76?spm=1055.2635.3001.10343)
# 1. GrblController概述与教育意义
GrblController作
【纸张尺寸问题解决】:奔图打印机不支持尺寸怎么办?专家解答全攻略
参考资源链接:[奔图打印机故障排除指南:卡纸、颜色浅、斑点与重影问题解析](https://wenku.csdn.net/doc/647841b8d12cbe7ec32e0260?spm=1055.2635.3001.10343)
# 1. 纸张尺寸问题概述
在现代办公环境中,打印机是不可或缺的设备。而纸张尺寸问题,通常是用户在使用打印机时遇到的一个基本问题。这不仅关系到打印质量,更关系到打印任务的顺利完成与否。纸张尺寸若不合适,可能会导致打印
环境化学研究新工具:Avogadro模拟污染物行为实操

参考资源链接:[Avogadro中文教程:分子建模与可视化全面指南](https://wenku.csdn.net/doc/6b8oycfkbf?spm=1055.2635.3001.10343)
# 1. 环境化学研究中模拟工具的重要性
环境化学研究中,模拟工具已成为不可
MODTRAN 5天文学新视角:天体观测数据处理的MODTRAN 5应用
参考资源链接:[MODTRAN 5.2.1用户手册:参数设置详解与更新介绍](https://wenku.csdn.net/doc/15be08sqot?spm=1055.2635.3001.10343)
# 1. MODTRAN 5软件概述及天文学意义
MODTRAN 5是一款广泛应用于天文学和大气科学领域的模拟软件,它能够模拟大气层及表面的辐射传输过程,为天体观测提供理论依据和数据支持。通过精确计算大气对电磁波的吸收和散射效应,MODTRAN 5对分析天体发射或反射的光谱具有重要意义,是现代天文学研究不可或缺的工具之一。
## 1.1 软件功能与特点
MODTRAN 5集成了丰富的物
V90 EPOS模式回零适应性:极端环境下的稳定运行分析

参考资源链接:[V90 EPOS模式下增量/绝对编码器回零方法详解](https://wenku.csdn.net/doc/6412b48abe7fbd1778d3ff04?spm=1055.2635.3001.10343)
# 1. V90 EPOS模式回零的原理与必要性
## 1.1 EPOS模式回零的基本概念
EPOS(电子位置设定)模式回零是指在电子控制系统中,自动或手动将设备的位置设定到初始的或预定的位置。这种机
【74HC154引脚布局:性能优化分析】:电路设计的性能影响关键因素

参考资源链接:[74HC154详解:4线-16线译码器的引脚功能与应用](https://wenku.csdn.net/d
版本控制的艺术:3D零件库管理历史数据与变更记录
参考资源链接:[3DSource零件库在线版:CAD软件集成的三维标准件库](https://wenku.csdn.net/doc/6wg8wzctvk?spm=1055.2635.3001.10343)
# 1. 版本控制在3D零件库管理中的作用
在当今的制造行业中,3D零件库的管理至关重要,它关系到产品设计的迭代效率、团队协作的顺畅性以及最终产品的质量保证。版本控制在此过程中发挥着核心作用,通过追踪每一次修改、保存历史记录,版本控制确保了设计的连续性和可追溯性,有效地减少了错误并提高了工作效率。
## 1.1 版本控制的重要性
版本控制作为一种软件工具,用于记录文件随时间的变化,这对
【Python pip安装包的版本控制】:精确管理依赖版本的专家指南

参考资源链接:[Python使用pip安装报错ModuleNotFoundError: No module named ‘pkg_resources’的解决方法](https://wenku.csdn.net/doc/6412b4a3be7fbd1778d4049f?spm=1055.2635.3001.10343)
# 1. Python pip安装包管理概述
P
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )