【XML SAX最佳实践】:xml.sax使用最佳经验和技巧,专家分享
发布时间: 2024-10-04 21:40:39 阅读量: 4 订阅数: 7 
# 1. XML SAX解析基础
在本章中,我们将介绍SAX(Simple API for XML)解析的基础知识。XML作为数据交换的一种常用格式,在各类应用中扮演着不可或缺的角色。SAX提供了一种基于事件驱动模型的解析方式,使得开发者可以高效地读取XML文档,而无需加载整个文档到内存中。
## 1.1 XML解析的必要性
XML(Extensible Markup Language)是一种非常灵活的数据交换格式,广泛应用于网络数据传输。然而,为了能够对XML文档中的数据进行处理,我们必须借助于XML解析技术。XML解析技术能够让我们更高效地访问和操作XML文档中的数据。
## 1.2 SAX解析方法的优势
相比其他类型的XML解析技术,如DOM(Document Object Model),SAX解析最大的优势在于其轻量级和流式的处理能力。SAX解析器在遍历XML文档的过程中,触发一系列事件,允许用户在特定的点进行数据处理,这对于处理大型文件特别有效。
```xml
<!-- 示例XML文档 -->
<books>
<book>
<title>Effective Java</title>
<author>Joshua Bloch</author>
</book>
<!-- 其他书籍信息 -->
</books>
```
以上章节内容初步介绍了XML解析的必要性以及SAX解析方法的优势,为后续章节中深入分析SAX的工作机制和实际应用奠定了基础。
# 2. SAX解析器的内部工作机制
## 2.1 SAX解析器的工作原理
### 2.1.1 事件驱动模型的介绍
SAX(Simple API for XML)解析器是基于事件驱动模型来解析XML文件的。事件驱动模型是一种编程范式,其中程序的执行是通过事件发生来驱动的,而不是通过常规的执行代码顺序。在SAX解析中,事件就是XML文档结构中的各种标记,比如开始标签、结束标签、文本内容等。
事件驱动模型的核心是事件监听器(Listener),它监听事件的发生,并对发生的事件做出响应。在XML解析的上下文中,解析器会读取XML文档,当遇到一个特定的标记时,它会触发一个事件,并通知事件处理器(如DocumentHandler或ContentHandler)。事件处理器根据监听到的事件类型执行相应的处理逻辑。
事件驱动模型的优点在于其内存效率,因为它不需要在内存中加载整个文档,这对于处理大型XML文件非常有用。此外,它允许快速的只读遍历,这在需要快速提取信息而不需要修改文档的情况下非常合适。
### 2.1.2 SAX解析器的事件处理流程
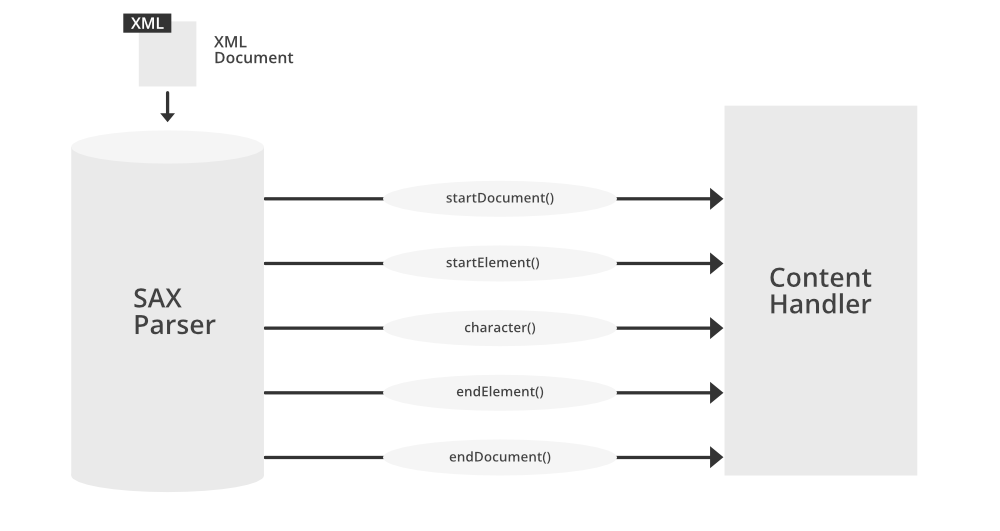
SAX解析器在解析XML文档时,会按照以下步骤触发事件:
1. **开始文档(startDocument)**:当解析器开始解析文档时触发。
2. **开始元素(startElement)**:遇到元素的开始标签时触发,如`<person>`。
3. **字符(characters)**:元素内部文本内容被处理时触发。
4. **结束元素(endElement)**:遇到元素的结束标签时触发,如`</person>`。
5. **结束文档(endDocument)**:文档解析完毕时触发。
这些事件是SAX解析器的基本构件,每个事件都对应于XML文档中的一个重要部分。事件处理器根据不同的事件类型执行相应的操作,例如收集数据、构建数据结构或执行自定义的逻辑。
在实际应用中,开发者需要创建一个或多个事件处理器,并在解析过程中实现这些处理器来处理特定的事件。以下是一个简单的SAX解析流程图,展示了解析器如何触发事件和调用相应的事件处理器。
```mermaid
graph TD
A[开始解析XML] -->|开始文档| B[startDocument]
B -->|开始元素| C[startElement]
C -->|字符| D[characters]
D -->|结束元素| E[endElement]
E --> F{是否有更多元素?}
F -->|是| C
F -->|否| G[endDocument]
G --> H[结束解析XML]
```
## 2.2 SAX解析器的配置与优化
### 2.2.1 解析器的初始化和属性设置
在Java中,使用SAX解析器通常需要通过工厂方法`SAXParserFactory`来创建`SAXParser`实例。以下是一个初始化SAX解析器的代码示例:
```java
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.XMLReaderFactory;
try {
XMLReader parser = XMLReaderFactory.createXMLReader();
// 配置parser的属性...
parser.setContentHandler(new MyContentHandler());
parser.parse("path/to/your.xml");
} catch (SAXException | IOException e) {
e.printStackTrace();
}
```
在初始化过程中,可以设置解析器的属性来控制解析行为,例如忽略空白文本、处理命名空间等。
### 2.2.2 高效解析的策略和最佳实践
要实现高效解析,开发者应遵循以下策略和最佳实践:
- **避免不必要的处理**:不要在事件处理器中执行耗时操作,只收集必要的信息。
- **使用`ContentHandler`接口**:这是一个强大的接口,可以用来跳过不需要处理的元素,减少不必要的解析。
- **利用`NamespaceSupport`**:如果XML文档使用命名空间,使用此支持类可以帮助管理复杂的命名空间。
- **注意内存管理**:虽然SAX的内存效率很高,但处理大型文档时仍需谨慎。避免创建大型临时对象,使用字符数组代替字符串可以减少内存占用。
## 2.3 错误处理与异常管理
### 2.3.1 SAX解析中常见的错误类型
在SAX解析过程中,可能会遇到多种错误类型,包括但不限于:
- **格式错误**:不符合XML规范的文档格式。
- **解析错误**:文档结构上的问题,如不匹配的标签。
- **I/O错误**:文件读取中出现的输入输出错误。
### 2.3.2 异常捕获和处理机制
正确处理这些错误和异常对于确保解析过程的健壮性至关重要。SAX解析器通过抛出`SAXParseException`来处理解析错误,通过抛出`IOException`来处理I/O错误。在异常处理代码块中,开发者可以记录错误信息、恢复解析或提供用户友好的反馈。
以下是一个异常处理的代码示例:
```java
try {
// XML解析逻辑...
} catch (SAXParseException e) {
// 解析错误处理
System.err.println("解析错误发生在 " + e.getLineNumber() + " 行");
} catch (IOException e) {
// I/O错误处理
System.err.println("读取XML文件时发生错误");
} catch (SAXException e) {
// 其他SAX错误处理
System.err.println("SAX错误: " + e.getMessage());
}
```
在处理异常时,应该确保错误信息足够详细,便于调试和用户理解。同时,应当尽量避免异常处理代码块中的复杂逻辑,以免掩盖实际的错误原因。
# 3. SAX事件处理器的编写与应用
## 3.1 事件处理器的基本结构
### 3.1.1 DocumentHandler接口的使用
在SAX解析过程中,`DocumentHandler`接口是处理XML文档内容的核心,它包含了一系列的事件处理方法,对应XML文档的各个部分。当你创建一个自定义的事件处理器类时,你需要实现这些方法以便于处理各种事件。
以下是一个简单的`DocumentHandler`接口使用示例:
```java
import org.xml.sax.*;
public class MyCustomHandler extends DefaultHandler {
@Override
public void startDocument() throws SAXException {
// XML文档开始时的处理逻辑
System.out.println("Document start");
}
@Override
public void endDocument() throws SAXException {
// XML文档结束时的处理逻辑
System.out.println("Document end");
}
// ... 其他方法的实现 ...
}
```
在`startDocument`方法中,你可以执行一些初始化的操作,比如清空缓存或初始化变量。同理,在`endDocument`方法中,你可以执行一些清理工作或者最终的数据处理。
### 3.1.2 ContentHandler接口的使用
`ContentHandler`接口继承自`DocumentHandler`,它包含了更多与文档内容相关的处理方法,如元素的开始和结束标签、字符数据和处理指令等。一个典型的`ContentHandler`的实现如下:
```java
import org.xml.sax.*;
public class MyContentHandler extends DefaultHandler {
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
// 元素开始标签的处理逻辑
System.out.println("Start Element: " + qName);
}
@Override
public void endElement(String uri, String localName, String qName)
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中用于 XML 解析的 xml.sax 库。从基础概念到高级技术,我们涵盖了以下主题:
* xml.sax 解析机制和事件驱动模型
* 构建自定义 XML 解析器
* 数据转换和结构化
* 避免常见解析错误和安全威胁
* 多线程并发解析
* 与其他 Python XML 库的比较
* 最佳实践、错误处理和内存管理
* 内容定制处理和 XML 与 JSON 的对比
通过这些文章,开发者将全面了解 xml.sax 库,并掌握高效解析 XML 数据所需的技能和技巧。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Django信号与自定义管理命令】:扩展Django shell功能的7大技巧
# 1. Django信号与自定义管理命令简介
Django作为一个功能强大的全栈Web框架,通过内置的信号和可扩展的管理命令,赋予了开
Python并发编程新高度

# 1. Python并发编程概述
在计算机科学中,尤其是针对需要大量计算和数据处理的场景,提升执行效率是始终追求的目标。Python作为一门功能强大、应用广泛的编程语言,在处理并发任务时也展现了其独特的优势。并发编程通过允许多个进程或线程同时执行,可以显著提高程序的运行效率,优化资源的使用,从而满足现代应用程序日益增长的性能需求。
在本章中,我们将探讨Python并发编程的基础知识,为理解后续章节的高级并发技术打下坚实的基础
sgmllib源码深度剖析:构造器与析构器的工作原理

# 1. sgmllib源码解析概述
Python的sgmllib模块为开发者提供了一个简单的SGML解析器,它可用于处理HTML或XML文档。通过深入分析sgmllib的源代码,开发者可以更好地理解其背后的工作原理,进而在实际工作中更有效地使用这一工具。
## 1.1 sgmllib的使用场景
【XML SAX定制内容处理】:xml.sax如何根据内容定制处理逻辑,专业解析

# 1. XML SAX解析基础
## 1.1 SAX解析简介
简单应用程序接口(Simple API for XML,SAX)是一种基于事件的XML解析技术,它允许程序解析XML文档,同时在解析过程中响应各种事件。与DOM(文档对象模型)不同,SAX不需将整个文档加载到内存中,从而具有较低的内存消耗,特别适合处理大型文件。
##
文本挖掘的秘密武器:FuzzyWuzzy揭示数据模式的技巧

# 1. 文本挖掘与数据模式概述
在当今的大数据时代,文本挖掘作为一种从非结构化文本数据中提取有用信息的手段,在各种IT应用和数据分析工作中扮演着关键角色。数据模式识别是对数据进行分类、聚类以及序列分析的过程,帮助我们理解数据背后隐藏的规律性。本章将介绍文本挖掘和数据模式的基本概念,同时将探讨它们在实际应用中的重要性以及所面临的挑战,为读者进一步了解FuzzyWuz
数据可视化:TextBlob文本分析结果的图形展示方法
# 1. TextBlob简介和文本分析基础
## TextBlob简介
TextBlob是一个用Python编写的库,它提供了简单易用的工具用于处理文本数据。它结合了自然语言处理(NLP)的一些常用任务,如词性标注、名词短语提取、情感分析、分类、翻译等。
## 文本分析基础
文本分析是挖掘文本数据以提取有用信息和见解的过程。通过文本分
【OpenCV立体视觉】:3D感知构建,双目视觉原理与应用
# 1. OpenCV立体视觉基础
在现代计算机视觉领域,立体视觉作为实现三维空间感知的重要手段,对于理解和分析场景结构至关重要。OpenCV(Open Source Computer Vision Library)作为一个强大的计算机视觉库,提供了丰富的函数和方法来支持立体视觉的实现。本章将从基础概念出发,带领读者快速入门立体视觉,并深入到OpenCV在立体视觉领域的应
【多语言文本摘要】:让Sumy库支持多语言文本摘要的实战技巧
# 1. 多语言文本摘要的重要性
## 1.1 当前应用背景
随着全球化进程的加速,处理和分析多语言文本的需求日益增长。多语言文本摘要技术使得从大量文本信息中提取核心内容成为可能,对提升工作效率和辅助决策具有重要作用。
## 1.2 提升效率与
Polyglot在音视频分析中的力量:多语言字幕的创新解决方案

# 1. 多语言字幕的需求和挑战
在这个信息全球化的时代,跨语言沟通的需求日益增长,尤其是随着视频内容的爆发式增长,对多语言字幕的需求变得越来越重要。无论是在网络视频平台、国际会议、还是在线教育领域,多语言字幕已经成为一种标配。然而,提供高质量的多语言字幕并非易事,它涉及到了文本的提取、
【源码解析篇】:揭秘MySQLdb内部机制!源码深度解析与工作原理

# 1. MySQLdb概述及应用背景
MySQLdb是Python编程语言中最流行的数据库API之一,它提供了访问MySQL数据库的接口。由于其简单易用和强大的功能,MySQLdb被广泛应用于网站开发、数据分析、自动化脚本等领域。它不仅支持标准的数据库操作,如查询、更新、事务处理等,还能与多种Python Web框架和数据处理库无缝集成
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )