【实战XML处理】:手把手教你用xml.sax构建XML解析器
发布时间: 2024-10-04 20:57:34 阅读量: 3 订阅数: 4 
# 1. XML基础和解析器概述
## 1.1 XML的定义和作用
XML(Extensible Markup Language)可扩展标记语言,是一种用于存储和传输数据的标记语言。它允许开发者定义自己的标签,使得数据交换不受应用程序和硬件平台的限制,广泛应用于网络数据交换、配置文件、数据存储等领域。
## 1.2 XML的特性
XML拥有高度的可读性、可扩展性,同时支持多语言,数据和显示分离,是良好的数据交换格式。它还支持各种复杂的数据结构,例如嵌套的元素和属性,为复杂的数据交换提供了可能。
## 1.3 XML解析器的作用和类型
XML解析器用于读取XML文件,并将结构化的数据转换成对象或者直接在内存中处理。常见的解析器类型包括DOM(文档对象模型)解析器、SAX(简单APIs for XML)解析器和StAX(流式APIs for XML)解析器。每种解析器根据不同的需求和场景,有各自的优势和使用场景。
## 1.4 XML和解析器的使用场景
在需要处理大量数据且对性能有要求的场合,SAX解析器因其实现了事件驱动模型,无需一次性加载整个文档,而成为处理大型XML文件的首选。此外,对于需要频繁读写操作的XML文件,SAX也提供了一种高效的数据处理方式。
# 2. 深入理解xml.sax模块
## 2.1 xml.sax模块的架构
### 2.1.1 解析器接口与事件驱动模型
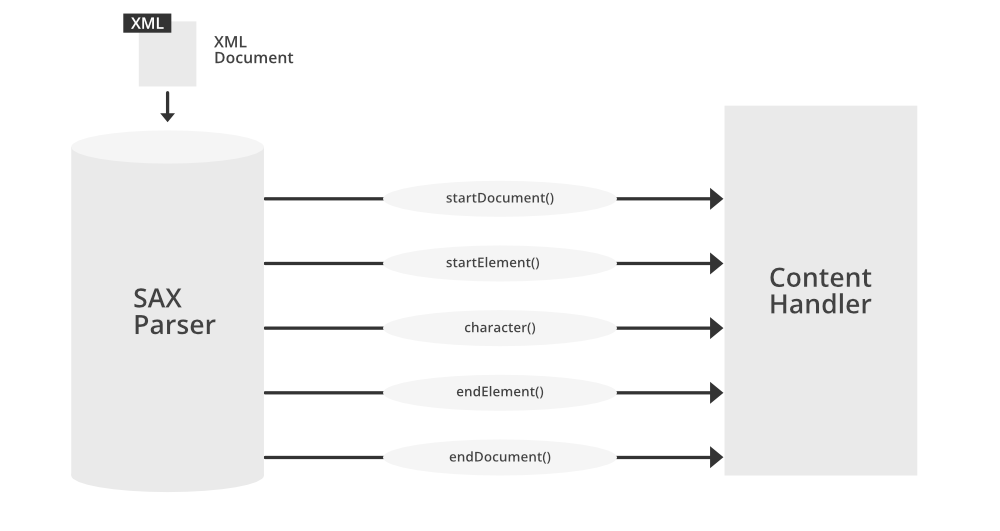
xml.sax模块采用事件驱动模型来解析XML文档。在该模型下,解析器读取XML文档,识别其中的标签、文本等组件,并触发相应的事件。这些事件被发送给注册了的事件处理器,通常是实现了特定接口的类实例,如ContentHandler。
事件驱动模型的工作流程如下:
1. 解析器从输入源(如文件、字符串等)读取XML内容。
2. 识别XML文档的语法元素(如开始标签、结束标签、文本等)。
3. 触发对应的事件,例如:startElement、endElement、characters等。
4. 事件处理器根据这些事件执行相关操作。
事件驱动模型的优点在于其高效性和内存使用的优化。它不需要将整个文档加载到内存中,特别适合处理大型文件。
### 2.1.2 xml.sax的主要组件和类
xml.sax模块主要包括以下几个关键组件和类:
- `XMLReader`: 这是核心解析器接口,所有的XML解析器类都必须实现它。`XMLReader` 提供了用于解析XML文档的方法,并允许注册事件处理器。
- `InputSource`: 一个用于包装输入源的类,它抽象了XML文档的来源,允许从多种类型的数据源读取数据。
- `DocumentHandler`: 一个旧接口,现在已经很少使用,被`ContentHandler`替代。
- `ContentHandler`: 这是主要的事件处理器接口。当XML解析器识别到不同的XML结构组件时,会调用`ContentHandler`接口中的相应方法。比如,当遇到开始标签时,会调用`startElement`方法。
这些组件和类的设计使得xml.sax模块具有良好的扩展性和模块化特性,方便用户根据需要自定义解析逻辑。
## 2.2 使用xml.sax构建简单的解析器
### 2.2.1 从零开始创建解析器
构建一个简单的XML解析器需要理解和实现xml.sax模块提供的接口。以下是一个创建基本XML解析器的步骤:
1. 导入xml.sax模块。
2. 创建一个继承自`ContentHandler`的类。
3. 在该类中定义事件处理方法,如`startElement`和`endElement`。
4. 实例化`XMLReader`,并使用`contenthandler`设置为你的处理器实例。
5. 使用`XMLReader`的`parse`方法来解析XML文档。
```python
import xml.sax
class MyHandler(xml.sax.ContentHandler):
def startElement(self, name, attrs):
print(f'Start element: {name}')
# 处理元素属性
for attr in attrs.items():
print(f'Attribute: {attr}')
def endElement(self, name):
print(f'End element: {name}')
# 实例化解析器
parser = xml.sax.make_parser()
# 设置事件处理器
parser.setContentHandler(MyHandler())
# 开始解析
parser.parse('example.xml')
```
这个例子中,我们创建了一个名为`MyHandler`的处理器,它在开始元素和结束元素事件被触发时打印相关信息。然后,我们创建了一个解析器实例,并将其内容处理器设置为`MyHandler`的实例,最后解析了一个名为`example.xml`的XML文件。
### 2.2.2 处理简单的XML数据
一旦我们的解析器准备就绪,就可以使用它来处理实际的XML数据。对于简单的数据,我们通常需要关注标签结构和属性。下面是一个简单的XML文件示例:
```xml
<books>
<book>
<title>Python Programming</title>
<author>John Doe</author>
<year>2021</year>
</book>
<book>
<title>Learning XML</title>
<author>Jane Smith</author>
<year>2020</year>
</book>
</books>
```
当解析这样的XML文件时,`startElement`和`endElement`方法会被依次调用,根据这些回调函数,我们可以执行相应的数据提取和处理。
## 2.3 xml.sax中的内容处理器
### 2.3.1 ContentHandler的使用方法
`ContentHandler`是xml.sax模块中用于处理XML文档事件的主要接口。它定义了多个事件处理方法,让开发者能够针对XML文档结构的不同部分执行特定的代码。下面列举了几个核心方法:
- `startDocument()` 和 `endDocument()`: 文档开始和结束时调用。
- `startElement(name, attrs)` 和 `endElement(name)`: 元素开始和结束标签触发。
- `characters(data)`: 在元素标签之间遇到字符数据时触发。
- `startPrefixMapping(prefix, uri)` 和 `endPrefixMapping(prefix)`: 命名空间前缀映射开始和结束时触发。
例如,我们想要提取书籍信息(书名、作者、出版年份),可以重写`startElement`和`endElement`方法:
```python
class BooksHandler(xml.sax.ContentHandler):
def startElement(self, name, attrs):
if name == 'book':
self.book = {}
elif name == 'title':
self.current_tag = 'title'
elif name == 'author':
self.current_tag = 'author'
elif name == 'year':
self.current_tag = 'year'
def endElement(self, name):
if name == 'book':
print(self.book)
self.current_tag = None
def characters(self, data):
if self.current_tag is not None:
self.book[self.current_tag] = data.strip()
# 使用书籍处理程序
parser.setContentHandler(BooksHandler())
```
上面的代码片段定义了一个`BooksHandler`类,它能够处理书籍信息,并打印出来。
### 2.3.2 处理XML文档的结构事件
处理XML文档的结构事件要求我们了解如何通过事件处理器来跟踪和解析XML文档的层次结构。这包括识别开始标签、结束标签和文本内容等。以下是一个处理XML文档结构事件的示例:
```python
from xml.sax.handler import ContentHandler
class StructureHandler(ContentHandler):
def __init__(self):
self.depth = 0 # 用于跟踪当前层级
def startElement(self, name, attrs):
print(' ' * self.depth + f'开始标签: {name}')
self.depth += 2
def endElement(self, name):
self.depth -= 2
print(' ' * self.depth + f'结束标签: {name}')
# 创建一个解析器
parser = xml.sax.make_parser()
handler = StructureHandler()
parser.setContentHandler(handler)
# 解析XML文档
parser.parse('sample.xml')
```
在这个例子中,我们创建了`StructureHandler`类,它通过`depth`变量来跟踪当前处理的标签层级。每当解析器遇到一个开始标签时,它将层级增加2;遇到结束标签时,层级减少2。这允许我们构建出XML文档的结构层次视图。
请记住,这些示例和解析过程仅触及了xml.sax模块的皮毛。在实际的项目中,你可能需要考虑更复杂的XML结构、属性处理以及错误处理策略。不过,掌握如何构建基本的解析器和处理XML文档的结构事件是深入学习xml.sax模块的良好开端。
# 3. xml.sax在实际项目中的应用
## 3.1 读取大型XML文件
### 3.1.1 处理大型文件的内存管理
处理大型XML文件时,最大的挑战之一是内存管理。XML文件的大小有时会超过可用内存,导致解析器在加载整个文件时遇到困难。xml.sax框架提供了流式处理的方式,这意味着它可以在不完全加载文件的情况下解析文件。这种方式对于处理大型文件尤其有用,因为它可以显著减少内存消耗。
xml.sax的事件驱动模型允许我们在解析XML时逐步处理文档,而不是一次性加载整个文件。每个元素和属性的出现都会触发一个事件,我们可以即时响应这些事件并执行相应的操作,而不是等待整个文件被解析完毕。这种方法不仅提高了内存使用效率,还可以实时处理数据。
### 3.1.2 实践:逐段读取大型XML文件
为了逐段读取大型XML文件,我们可以使用xml.sax中的`XMLReader`接口,配合自定义的`ContentHandler`来实现。下面是一个简单的例子,展示了如何逐段读取一个大型XML文件:
```python
import xml.sax
class LargeFileHandler(xml.sax.ContentHandler):
def __init__(self):
super().__init__()
self.buffer = []
def startElement(self, tag, attributes):
self.buffer.append(f"Start element: {tag}\n")
def endElement(self, tag):
self.buffer.append(f"End element: {tag}\n")
if tag == "chunk": # 假设我们的分块标记是"chunk"
print(''.join(self.buffer)) # 处理分块数据
self.buffer.clear() # 清空缓冲区以便下一个分块
def characters(self, content):
self.buffer.append(content)
def parse_large_file(file_path):
parser = xml.sax.make_parser()
handler = LargeFileHandler()
parser.setContentHandler(handler)
parser.parse(file_path)
# 假设有一个名为large_file.xml的大型XML文件
parse_large_file('large_file.xml')
```
在上述代码中,我们定义了一个`LargeFileHandler`类,该类继承自`xml.sax.ContentHandler`。我们重写了`startElement`和`endElement`方法来处理开始和结束标签,并且在`endElement`方法中检测到特定的结束标签时处理缓冲区中的数据。这个特定的标签是我们在XML文件中定义的分块标记,它允许我们分段处理数据。
## 3.2 构建复杂的XML解析器
### 3.2.1 处理嵌套元素和属性
当构建用于处理复杂XML结构的解析器时,我们需要关注嵌套元素和属性的处理。xml.sax提供了丰富的事件回调,可以帮助我们捕捉和解析这些复杂的结构。
解析嵌套元素时,我们通常需要跟踪元素的层级结构,这可以通过在`ContentHandler`中维护一个堆栈来实现。而处理属性则需要我们实现`startElement`方法,并从中提取属性。
### 3.2.2 实践:编写自定义的事件处理器
以下是一个自定义事件处理器的简单示例,用于处理嵌套元素和属性。我们假设有一个具有层级结构和属性的XML文件:
```python
import xml.sax
class ComplexXMLHandler(xml.sax.ContentHandler):
def __init__(self):
super().__init__()
self.current_element = ""
self.element_stack = []
def startElement(self, tag, attributes):
self.element_stack.append((self.current_element, attributes))
self.current_element = tag
print(f"Start of element: {tag}")
def endElement(self, tag):
if self.element_stack:
self.current_element, attrs = self.element_stack.pop()
print(f"End of element: {tag}")
def characters(self, data):
if self.current_element:
print(f"Characters in element: {self.current_element}")
print(f"Data: {data}")
def parse_complex_xml(file_path):
parser = xml.sax.make_parser()
handler = ComplexXMLHandler()
parser.setContentHandler(handler)
parser.parse(file_path)
# 假设有一个名为complex_xml_file.xml的XML文件
parse_complex_xml('complex_xml_file.xml')
```
在此代码中,我们通过`startElement`和`endElement`方法跟踪当前元素及其父元素,并在`characters`方法中处理文本节点。我们使用`element_stack`列表来记录元素层级,这在处理嵌套结构时非常有用。
## 3.3 整合数据库与XML数据
### 3.3.1 数据库到XML的映射策略
在项目中将数据库数据导出为XML格式是一个常见的需求。为了将数据库转换为XML,我们需要定义一种映射策略。这种策略通常涉及指定如何将数据库字段映射到XML元素和属性。选择正确的映射策略对于创建结构良好的XML文件至关重要。
### 3.3.2 实践:从数据库生成XML报告
以下是一个从数据库生成XML报告的实践示例。假设我们有一个数据库表`employees`,我们想要生成包含员工信息的XML文件。
```python
import xml.sax
from sqlalchemy import create_engine, MetaData, Table
# 设置数据库连接参数
database_url = 'sqlite:///employees.db'
engine = create_engine(database_url)
metadata = MetaData(bind=engine)
employees_table = Table('employees', metadata, autoload=True, autoload_with=engine)
class DatabaseToXML(xml.sax.ContentHandler):
def startElement(self, tag, attrs):
self.data = ''
def characters(self, data):
self.data += data
def endElement(self, tag):
if tag == "employee":
print(f"<{tag} id='{self.data}'/>")
elif tag == "name":
print(f"<{tag}>{self.data}</{tag}>")
elif tag == "age":
print(f"<{tag}>{self.data}</{tag}>")
def generate_xml_from_db():
output = []
connection = engine.connect()
try:
for row in connection.execute(employees_table.select()):
employee_xml = f'<employee id="{row.id}">\n'
for column in employees_table.c:
if column.name not in ('id',):
employee_xml += f" <{column.name}>{row[column.name]}</{column.name}>\n"
employee_xml += '</employee>'
output.append(employee_xml)
finally:
connection.close()
return '\n'.join(output)
# 将生成的XML输出到文件
with open('employees.xml', 'w') as xml_***
***'<employees>\n')
xml_file.write(generate_xml_from_db())
xml_file.write('</employees>')
# 解析生成的XML文件
parse_complex_xml('employees.xml')
```
在这个例子中,我们使用了SQLAlchemy来与SQLite数据库进行交互,并定义了一个从数据库中提取数据并生成XML的方法。我们通过遍历`employees_table`并为每个员工生成相应的XML标签来完成这个任务。最终,我们将所有员工的XML标签包裹在一个`<employees>`标签内,并写入一个文件。然后,我们可以使用之前的`ComplexXMLHandler`来解析这个文件。
# 4. xml.sax进阶技巧与最佳实践
## 4.1 异常处理和日志记录
### 4.1.1 理解和处理解析错误
在使用xml.sax进行XML文档解析时,处理异常是不可避免的环节。xml.sax提供的解析器能够捕获解析过程中的各种错误,并触发异常。理解这些异常和知道如何处理它们是构建稳定应用的关键。
解析器通常会遇到两类主要错误:` SAXParseException `(解析异常)和 ` SAXException `(通用 SAX 异常)。前者通常指向具体的XML格式问题,如不匹配的标签或错误的字符实体;后者则是更一般的异常,可能涉及到回调方法的实现错误,或者是由于某些外部原因导致的中断。
为了妥善处理这些异常,开发者可以采取如下步骤:
1. 在实现的处理器(如 ` ContentHandler `)中捕获异常。通常是在 ` startElement() `、` endElement() `、` characters() ` 等方法中。
2. 分析异常信息,明确是由于格式问题还是程序错误引起。
3. 对于格式错误,如果可能,尝试进行修复或提供清晰的错误消息给用户。
4. 对于程序错误,应该在开发阶段修复,避免在生产环境中出现。
在代码层面,异常处理示例如下:
```python
from xml.sax.handler import ContentHandler
from xml.sax import parse, SAXParseException
class MyHandler(ContentHandler):
def startElement(self, name, attrs):
# 元素开始的处理逻辑
pass
def endElement(self, name):
# 元素结束的处理逻辑
pass
def characters(self, data):
# 文本数据处理逻辑
pass
def error(self, exception):
# 格式错误的处理逻辑
print("XML parse error:", exception)
def fatalError(self, exception):
# 致命错误的处理逻辑
print("XML parse fatal error:", exception)
try:
parse('example.xml', MyHandler())
except SAXParseException as e:
# 在此处理解析异常
print("SAXParseException occurred:", e)
```
### 4.1.2 日志记录在解析过程中的作用
日志记录在解析XML的过程中是一个重要的实践。它可以帮助开发者追踪解析进度、分析错误发生的位置,并为后续问题的诊断提供依据。在xml.sax中,日志记录不仅可以帮助定位问题,还可以在生产环境中帮助监控解析器的性能和状态。
Python中常用的日志库是 ` logging `,可以按照以下步骤集成到xml.sax的解析过程中:
1. 导入 ` logging ` 模块并配置日志记录器。
2. 在 ` ContentHandler ` 的适当方法中调用日志记录方法,记录重要事件。
3. 根据需要,可以调整日志级别来获取更详细的日志信息。
一个简单的日志记录示例如下:
```python
import logging
from xml.sax.handler import ContentHandler
logging.basicConfig(level=***)
class MyHandler(ContentHandler):
def startElement(self, name, attrs):
***(f"Starting element: {name}")
# 元素开始的处理逻辑
pass
def endElement(self, name):
***(f"Ending element: {name}")
# 元素结束的处理逻辑
pass
def characters(self, data):
***(f"Characters: {data}")
# 文本数据处理逻辑
pass
try:
# 解析XML文件
parse('example.xml', MyHandler())
except Exception as e:
logging.exception("An error occurred during parsing.")
```
## 4.2 xml.sax的安全性考量
### 4.2.1 防御XML解析的安全威胁
由于XML是一种灵活的标记语言,它可以容纳各种类型的数据和文档结构。然而,这种灵活性也使得XML成为潜在的安全威胁来源。在解析XML文档时,尤其是来自不可信源的XML,需要格外小心,因为它们可能包含恶意数据,如执行脚本或引入安全漏洞的代码。
xml.sax模块对一些常见的安全威胁提供了内置的支持,比如禁止外部实体的引用。外部实体攻击(XML External Entity, 简称XXE)是一种常见的攻击方式,攻击者通过引用外部的实体(通常是文件或网络资源)来读取或写入敏感数据。
为了提高安全性,开发者可以采取以下措施:
1. 禁用外部实体的解析。许多xml.sax的解析器提供了一个属性(如 ` XMLReader.setFeature("***", False)`),允许禁用外部实体的解析。
2. 对接收到的XML文档进行严格的验证。在解析前,使用XML Schema或其他方式对文档格式进行验证,确保文档符合预期的结构。
3. 使用白名单或黑名单来过滤掉危险的字符和元素。例如,可以编写代码来检测和删除 `<script>` 标签。
4. 使用沙箱环境运行解析器,以防解析器的执行环境被破坏。
下面是如何在xml.sax中禁用外部实体的一个例子:
```python
from xml.sax.handler import ContentHandler
from xml.sax import XMLReader
from xml.sax.handler import feature_external_ges
class MySecureHandler(ContentHandler):
# 省略其他方法实现...
def main():
# 创建一个解析器实例
parser = XMLReader()
# 设置解析器不允许解析外部实体
parser.setFeature(feature_external_ges, False)
# 设置内容处理器
parser.setContentHandler(MySecureHandler())
# 解析XML
try:
parser.parse('example.xml')
except Exception as e:
print("Error during parsing:", e)
main()
```
### 4.2.2 实践:确保解析过程的安全性
在实践中,确保xml.sax解析过程的安全性往往需要多方面的考虑。除了上一节提到的措施,还需要关注整个应用程序的安全性,确保解析器的调用不会引入新的风险。下面是一些进一步的实践步骤:
1. **输入验证**:对所有传入XML的输入进行验证,确保它们符合预期格式,不包含恶意的构造。
2. **错误处理**:恰当地处理解析过程中可能抛出的所有异常,避免因异常而造成的未定义行为。
3. **资源管理**:使用上下文管理器来自动管理解析器的资源,防止内存泄漏。
4. **最小权限**:为执行XML解析的代码设置最小的权限,减少潜在的攻击面。
5. **安全更新**:及时更新解析器库和依赖包,以防止已知漏洞被利用。
以Python为例,可以使用 ` with ` 语句来确保即使在发生异常的情况下,解析器资源也能被正确释放:
```python
with open('example.xml', 'r') as xml***
***
***
***
***
***
***
***
***"Error during parsing:", e)
```
通过这样的实践,开发者可以大大提升应用程序在解析XML时的安全性,为用户提供一个更加安全稳定的环境。
# 5. xml.sax项目案例研究
## 5.1 构建图书管理系统中的XML导入功能
### 5.1.1 需求分析与设计
在构建图书管理系统时,一个关键的需求是能够导入存储在XML文件中的图书数据。这些数据通常包含书籍的标题、作者、ISBN、出版日期以及分类等信息。为了高效地处理这些数据,我们选择使用xml.sax模块,其强大的事件驱动模型非常适合处理大型XML文件。
在设计上,我们将构建一个解析器,该解析器能够读取一个预定义结构的XML文件,并将其内容导入到数据库中。解析器会检查XML文件的结构是否正确,并且能够处理可能出现的异常情况,如文件格式错误或数据重复等。
### 5.1.2 实践:使用xml.sax实现功能
下面的代码块展示了如何使用xml.sax模块来解析一个简单的图书信息XML文件,并将解析后的数据存储到内存中。请注意,实际应用中,你需要将解析后的数据存储到数据库中。
```python
import xml.sax
class BookHandler(xml.sax.ContentHandler):
def startElement(self, tag, attributes):
if tag == "book":
book_data = {}
else:
book_data[tag] = []
def endElement(self, tag):
if tag == "book":
# 这里可以将book_data存储到数据库中
print("Book imported:", book_data)
else:
book_data[tag] = "".join(book_data[tag])
def characters(self, content):
if book_data:
current_tag = self._getCurrentTag()
book_data[current_tag].append(content)
def _getCurrentTag(self):
# 获取当前解析的标签,假设我们已经知道当前的标签
# 在实际应用中,这个方法需要根据实际解析器的状态来确定当前标签
return "title"
# 假设XML文件名为books.xml
xml.sax.parse("books.xml", BookHandler())
```
在上述代码中,我们定义了一个`BookHandler`类,它继承自`xml.sax.ContentHandler`。我们重写了`startElement`、`endElement`和`characters`方法来分别处理开始标签、结束标签和文本内容。这样,每当解析器遇到一个开始标签时,我们就初始化或更新`book_data`字典;当遇到文本内容时,我们就把文本内容追加到当前标签的列表中。
此外,为了在解析结束时能够输出完整的信息,我们在`endElement`方法中进行了处理。在真实的项目中,这里应该是将图书数据存入数据库的逻辑。
## 5.2 实现跨平台的配置文件读取器
### 5.2.1 配置文件的结构和要求
在软件开发中,配置文件是一个重要的组成部分,它允许用户或管理员自定义软件的行为而无需修改源代码。XML格式的配置文件广泛被用于跨平台应用程序中,因为XML文件易于阅读和编辑,同时也能通过XML解析器进行高效处理。
为了实现一个跨平台的配置文件读取器,我们需要考虑配置文件的结构。一个典型的配置文件可能包含应用程序的设置项,如窗口大小、颜色主题、用户偏好设置等。其XML结构可能如下所示:
```xml
<configuration>
<settings>
<setting name="window_size" value="1024x768"/>
<setting name="theme" value="dark"/>
</settings>
</configuration>
```
### 5.2.2 实践:xml.sax在配置管理中的应用
使用xml.sax模块读取上述的配置文件,并将设置项转换为应用程序可以识别的格式,可以如下进行:
```python
import xml.sax
class ConfigHandler(xml.sax.ContentHandler):
def __init__(self):
self.current = None
self.config = {}
def startElement(self, tag, attributes):
self.current = tag
def endElement(self, tag):
if tag == "setting":
setting_name = self.config["setting"].get("name")
setting_value = self.config["setting"].get("value")
self.config[setting_name] = setting_value
elif tag == "settings":
# 这里可以将配置数据应用到应用程序中
print("Settings applied:", self.config)
self.current = None
def characters(self, content):
if self.current == "name":
self.config["setting"] = {"name": content}
elif self.current == "value":
self.config["setting"]["value"] = content
xml.sax.parse("config.xml", ConfigHandler())
```
在这个例子中,`ConfigHandler`类用来处理配置文件的解析。我们为每个可能遇到的元素定义了特定的处理逻辑。当解析器遇到`setting`元素时,我们保存键值对;当遇到`settings`元素时,我们应用解析的配置。这个过程中,我们利用`startElement`和`endElement`方法来跟踪当前的解析状态,并使用`characters`方法来收集文本内容。
以上代码演示了如何使用xml.sax模块来实现一个跨平台的配置文件读取器。通过解析XML文件,我们可以轻松地从配置中读取用户偏好设置,并将这些设置应用到应用程序中。这样,无论用户在何种操作系统上,应用程序都可以提供一致的用户体验。
# 6. xml.sax的未来和展望
随着信息技术的快速发展,XML技术的应用范围也在不断扩展。xml.sax作为Python中的XML解析库之一,其发展和未来趋势备受关注。本章将深入探讨xml.sax与现代XML标准的兼容性,以及其在新兴技术领域中的地位和未来展望。
## 6.1 xml.sax与现代XML标准的兼容性
XML作为一种标记语言,不断有新的标准和规范被提出,以适应不断变化的数据交换需求。xml.sax作为一个成熟的解析器,对新规范的支持情况直接关系到它在开发者心中的地位。
### 6.1.1 对新XML规范的支持情况
xml.sax支持的最新XML规范包括了对命名空间、实体引用、字符编码以及文档类型定义(DTD)的支持。随着XML的发展,新的规范如XInclude和XPointer也被加入到xml.sax的特性列表中,提升了XML文档的互操作性和扩展性。
在处理这些新特性时,开发者需要注意的是,虽然xml.sax能够处理这些规范,但在使用时仍需要确保XML文档符合相应规范的约束和语法要求。例如,处理XInclude需要在解析之前确保文档中使用正确的include标签和相应的命名空间声明。
### 6.1.2 面向未来:兼容新特性的策略
随着XML技术的发展,未来的xml.sax库将会继续更新以支持新的XML标准。为了面向未来,开发人员应当采取以下策略:
1. **定期更新和维护**: 开发团队需要定期检查并更新其使用的xml.sax库版本,以获得最新的功能和安全更新。
2. **编写兼容性测试**: 对于正在使用的xml.sax功能,编写测试用例以确保它们在新规范引入时不会出现问题。
3. **关注社区和官方文档**: 开发者应该密切关注xml.sax社区讨论以及官方的发布说明,以便及时了解关于新特性的信息和使用方法。
## 6.2 xml.sax在新兴技术中的地位
在大数据和云服务的推动下,数据格式和解析技术的多样性使得xml.sax面临着来自其他技术的竞争,如JSON和YAML等格式因其轻量级和易读性受到青睐。
### 6.2.1 与JSON、YAML等数据格式的关系
尽管JSON和YAML等格式的流行给xml.sax带来了一定的竞争压力,但XML作为一种成熟的技术,其优势依然明显。xml.sax仍然在需要复杂结构和严格语义的场景中具有不可替代的地位,如企业级应用、数据交换标准、学术和科技出版物等领域。
JSON和YAML等格式虽然在某些方面性能更优,但它们缺乏XML所具有的严格规范和丰富的语义信息。例如,在处理具有复杂嵌套关系的数据和需要描述文档结构的场合,xml.sax提供的模式定义和命名空间等特性是JSON和YAML所不具备的。
### 6.2.2 展望xml.sax在数据处理领域的未来
展望未来,xml.sax仍将在数据处理领域占有一席之地,特别是在以下几个方面:
- **云计算与服务**: 在云服务中,对于需要严格语义和结构验证的场景,xml.sax依然是首选的解析工具。
- **数据交换**: 在跨系统或跨平台的数据交换中,XML格式的标准化和广泛支持使xml.sax成为一种可靠的选择。
- **遗留系统**: 对于已经建立在XML基础上的遗留系统,xml.sax将依然发挥重要作用,因为迁移到其他格式可能会带来高昂的成本和风险。
同时,xml.sax也需面对挑战,持续优化性能和易用性,适应新兴技术的要求,比如通过增加对新标准的支持、优化内存使用和解析速度等,以保持其在数据处理领域的竞争力。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python并发编程新高度

# 1. Python并发编程概述
在计算机科学中,尤其是针对需要大量计算和数据处理的场景,提升执行效率是始终追求的目标。Python作为一门功能强大、应用广泛的编程语言,在处理并发任务时也展现了其独特的优势。并发编程通过允许多个进程或线程同时执行,可以显著提高程序的运行效率,优化资源的使用,从而满足现代应用程序日益增长的性能需求。
在本章中,我们将探讨Python并发编程的基础知识,为理解后续章节的高级并发技术打下坚实的基础
sgmllib源码深度剖析:构造器与析构器的工作原理

# 1. sgmllib源码解析概述
Python的sgmllib模块为开发者提供了一个简单的SGML解析器,它可用于处理HTML或XML文档。通过深入分析sgmllib的源代码,开发者可以更好地理解其背后的工作原理,进而在实际工作中更有效地使用这一工具。
## 1.1 sgmllib的使用场景
NLTK与其他NLP库的比较:NLTK在生态系统中的定位
# 1. 自然语言处理(NLP)简介
自然语言处理(NLP)是计算机科学和人工智能领域中一项重要的分支,它致力于使计算机能够理解和处理人类语言。随着人工智能的快速发展,NLP已经成为了连接人类与计算机的重要桥梁。在这一章中,我们将首先对NLP的基本概念进行介绍,随后探讨其在各种实际应用中的表现和影响。
## 1.1 NLP的基本概念
自然语言处理主要涉及计算机理解、解析、生成和操控人类语言的能力。其核心目标是缩小机器理解和人类表达之间的
Polyglot在音视频分析中的力量:多语言字幕的创新解决方案

# 1. 多语言字幕的需求和挑战
在这个信息全球化的时代,跨语言沟通的需求日益增长,尤其是随着视频内容的爆发式增长,对多语言字幕的需求变得越来越重要。无论是在网络视频平台、国际会议、还是在线教育领域,多语言字幕已经成为一种标配。然而,提供高质量的多语言字幕并非易事,它涉及到了文本的提取、
【XML SAX定制内容处理】:xml.sax如何根据内容定制处理逻辑,专业解析

# 1. XML SAX解析基础
## 1.1 SAX解析简介
简单应用程序接口(Simple API for XML,SAX)是一种基于事件的XML解析技术,它允许程序解析XML文档,同时在解析过程中响应各种事件。与DOM(文档对象模型)不同,SAX不需将整个文档加载到内存中,从而具有较低的内存消耗,特别适合处理大型文件。
##
实时通信的挑战与机遇:WebSocket-Client库的跨平台实现

# 1. WebSocket技术的概述与重要性
## 1.1 什么是WebSocket技术
WebSocket是一种在单个TCP连接上进行全双工通信的协议。它为网络应用提供了一种实时的、双向的通信通道。与传统的HTTP请求-响应模型不同,WebSocket允许服务器主动向客户端发送消息,这在需要即时交互的应
FuzzyWuzzy高级应用:自定义匹配权重与分数阈值的最佳实践

# 1. FuzzyWuzzy介绍与基本使用
在当今数据驱动的世界中,文本数据的处理变得越来越重要。FuzzyWuzzy是一个流行的Python库,它可以用于执行字符串的近似匹配并量化字符串之间的相似度。这一章我们将对FuzzyWuzzy库的基础知识进行介绍,并引导读者了解如何在日常工作
【Django信号高效应用】:提升数据库交互性能的5大策略

# 1. Django信号概述
Django框架作为一个高级的Python Web框架,其设计目标之一就是快速开发和干净、实用的设计。为了实现这些目标,Dja
【多语言文本摘要】:让Sumy库支持多语言文本摘要的实战技巧
# 1. 多语言文本摘要的重要性
## 1.1 当前应用背景
随着全球化进程的加速,处理和分析多语言文本的需求日益增长。多语言文本摘要技术使得从大量文本信息中提取核心内容成为可能,对提升工作效率和辅助决策具有重要作用。
## 1.2 提升效率与
数据可视化:TextBlob文本分析结果的图形展示方法
# 1. TextBlob简介和文本分析基础
## TextBlob简介
TextBlob是一个用Python编写的库,它提供了简单易用的工具用于处理文本数据。它结合了自然语言处理(NLP)的一些常用任务,如词性标注、名词短语提取、情感分析、分类、翻译等。
## 文本分析基础
文本分析是挖掘文本数据以提取有用信息和见解的过程。通过文本分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )