【深入理解XML】:xml.sax模块解析机制详解,专家级解读
发布时间: 2024-10-04 20:53:11 阅读量: 41 订阅数: 32 

Python使用sax模块解析XML文件示例
# 1. XML基础概述
可扩展标记语言(XML)是定义数据和描述信息结构的标准方式。与HTML类似,XML使用标签和属性来描述数据,但其主要功能是存储和传输数据,而不是显示数据。XML文档是自描述的,使得不同系统间的数据交换成为可能,是数据交换和业务通信的重要工具。
## 1.1 XML的基本结构
XML文档遵循一套严格的结构规则,这包括:
- XML声明:通常出现在文档的第一行,用于声明文档的版本和编码。
- 元素:由开始标签、内容和结束标签组成。例如 `<element>Content</element>`。
- 属性:元素可以有属性,提供额外信息。例如 `<element attribute="value">Content</element>`。
## 1.2 XML的特点
XML的特点使其成为数据交换的理想选择:
- 可扩展性:用户可以定义自己的标签和属性。
- 格式化:易于阅读和书写,同时能够通过格式化工具进行优化。
- 中立性:与平台无关,可以跨操作系统和编程语言使用。
- 层次结构:天然支持数据的层次化表示,便于理解和处理。
理解XML的基础结构和特点为深入学习如xml.sax模块这类处理XML的工具提供了必要的背景知识。接下来我们将探索xml.sax模块,它是如何在Python中高效解析XML文档的。
# 2. 深入解析xml.sax模块
## 2.1 xml.sax模块介绍
### 2.1.1 xml.sax模块的组成
xml.sax模块是Python标准库中的一个轻量级XML解析器,它利用了事件驱动模型来解析XML文档。xml.sax模块主要由以下几个核心组件构成:
- 解析器(Parser):核心组件,用于读取XML文档并产生事件。
- 内容处理器(ContentHandler):一个接口,定义了事件处理函数,用于处理解析器产生的各种事件。
- 错误处理器(ErrorHandler):用于处理解析过程中出现的错误。
除了这些核心组件,xml.sax模块还包括一些辅助工具,比如用于解析特定格式文件的工厂类等。
### 2.1.2 xml.sax模块的工作原理
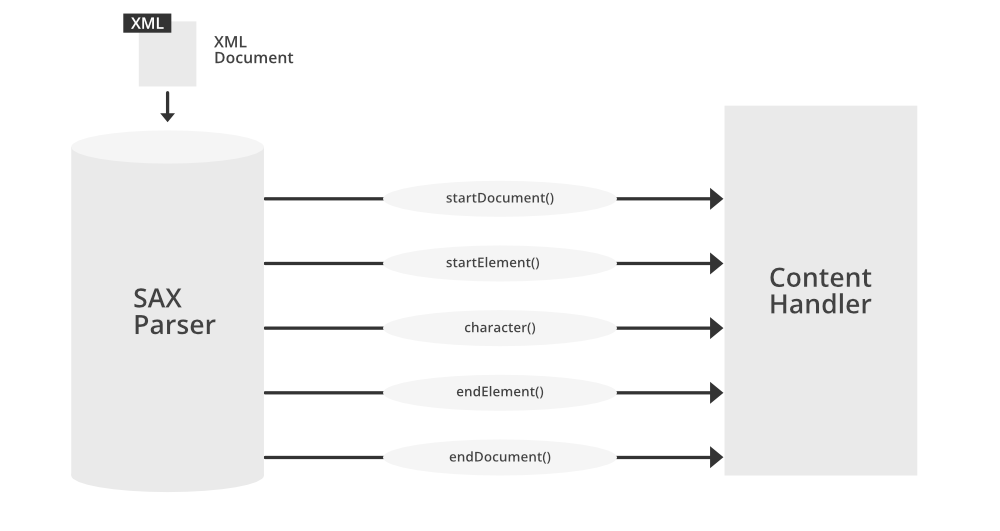
xml.sax模块的工作原理基于事件驱动模型,它将XML文档的解析过程分解为一系列的事件。例如,文档开始解析时触发`startDocument`事件,遇到元素节点时触发`startElement`事件,遇到文本内容时触发`characters`事件,结束解析时触发`endDocument`事件。
解析器在读取XML文档的过程中,每当遇到这些定义好的事件节点,就会调用内容处理器中相应的事件处理函数来进行处理。这种模式允许开发者能够针对性地处理XML文档中的各种数据,而不需要加载整个文档到内存中,这对于处理大型XML文件尤其有用。
## 2.2 xml.sax模块的事件驱动模型
### 2.2.1 事件驱动模型的基本概念
事件驱动模型是一种编程范式,它依赖于事件(如用户输入、传感器信号、消息等)来触发代码执行。在XML解析中,事件驱动模型通过解析器自动识别文档中的各种结构(如元素、属性、文本等),然后发出相应的事件,开发者通过编写事件处理代码来响应这些事件。
在xml.sax模块中,主要的事件类型包括:
- 文档开始和结束的事件(`startDocument`和`endDocument`)
- 元素开始标签和结束标签的事件(`startElement`和`endElement`)
- 文本内容事件(`characters`)
- 错误事件(通过`ErrorHandler`接口处理)
### 2.2.2 事件驱动模型的工作机制
xml.sax模块的事件驱动模型工作机制如下:
1. 解析器读取XML文档,从文件或字符串中提取信息。
2. 解析器识别出XML文档中的不同组件,并将其转换成事件。
3. 解析器调用注册好的事件处理器(即内容处理器中的方法)来响应事件。
4. 事件处理器根据事件类型执行相应的逻辑处理代码,如提取数据、进行验证等。
5. 错误处理器负责处理解析过程中遇到的任何问题。
整个流程以非阻塞方式执行,处理完一个事件后,解析器会继续读取文档并等待下一个事件的发生。这种模型特别适合于需要边读边处理的场景,例如实时数据处理或网络数据流解析。
## 2.3 xml.sax模块的核心组件
### 2.3.1 解析器的作用和使用
在xml.sax模块中,解析器负责读取XML文档并生成事件。解析器通过创建实例来初始化,并接受一个内容处理器作为参数,解析器会把读取到的事件转发给内容处理器进行处理。
以下是一个简单的解析器使用示例:
```python
import xml.sax
class MyHandler(xml.sax.ContentHandler):
def startElement(self, name, attrs):
print('Start Element:', name)
def endElement(self, name):
print('End Element:', name)
def characters(self, data):
print('Characters:', data)
if __name__ == '__main__':
parser = xml.sax.make_parser()
parser.setContentHandler(MyHandler())
parser.parse('example.xml')
```
在这个例子中,我们定义了一个自定义的`ContentHandler`,实现了`startElement`, `endElement`和`characters`方法来处理元素开始、元素结束和文本内容事件。然后我们创建了一个解析器实例,将自定义处理器作为参数传递给它,并通过调用`parse`方法来解析文件。
### 2.3.2 内容处理器的结构和功能
内容处理器是xml.sax模块中非常关键的一部分,它需要实现`ContentHandler`接口。内容处理器定义了一系列的方法,这些方法会在解析器生成对应事件时被调用。常用的方法包括:
- `startDocument`: 文档开始时调用。
- `endDocument`: 文档结束时调用。
- `startElement`: 遇到元素开始标签时调用。
- `endElement`: 遇到元素结束标签时调用。
- `characters`: 遇到元素内的文本内容时调用。
通过重写这些方法,内容处理器可以实现对XML文档结构的分析和处理。
### 2.3.3 错误处理器的处理策略
错误处理器负责处理解析过程中遇到的错误和警告。它需要实现`ErrorHandler`接口,该接口包含三个方法:
- `error`: 当解析器遇到可恢复的错误时调用。
- `warning`: 当解析器遇到非致命警告时调用。
- `fatalError`: 当解析器遇到致命错误(如文档格式错误)时调用。
以下是错误处理器的一个简单实现示例:
```python
import xml.sax
class MyErrorHandler(xml.sax.ErrorHandler):
def error(self, exception):
print('XML Error:', exception.getMessage())
def warning(self, exception):
print('XML Warning:', exception.getMessage())
def fatalError(self, exception):
print('XML Fatal Error:', exception.getMessage())
raise exception
if __name__ == '__main__':
parser = xml.sax.make_parser()
parser.setFeature(xml.sax.handler.feature_validation, True)
parser.setContentHandler(MyHandler())
parser.setErrorHandler(MyErrorHandler())
parser.parse('example.xml')
```
在上面的例子中,自定义的错误处理器`MyErrorHandler`对解析器产生的错误进行了处理。当解析器在解析`example.xml`文件时,任何错误都会通过这些方法传递给错误处理器,然后可以根据不同的错误类型执行相应的处理逻辑。
# 3. xml.sax模块在XML解析中的应用
在本章中,我们将深入探讨xml.sax模块在XML解析中的实际应用,包括其如何读取和解析XML文件、处理XML事件以及其高级特性。xml.sax模块是一个强大的库,它基于事件驱动模型,允许程序在解析XML文件时仅处理相关的事件,这对于处理大型文件和流式数据特别有用。通过本章的学习,读者将能够理解和掌握xml.sax模块的核心组件,并将其应用于复杂的数据处理场景中。
## 3.1 xml.sax模块解析XML文件
### 3.1.1 读取和解析XML文件的基本步骤
在开始之前,需要了解xml.sax模块的基本工作原理。xml.sax是基于事件的解析器,它在读取XML文件时,会触发一系列事件,并将这些事件传递给注册的事件处理器。开发者通过编写自定义的事件处理器来响应这些事件,从而实现对XML内容的读取和解析。
以下是使用xml.sax模块解析XML文件的基本步骤:
1. 导入xml.sax模块中的相关组件。
2. 创建一个解析器实例。
3. 创建内容处理器(ContentHandler)和错误处理器(ErrorHandler),并将其注册到解析器。
4. 使用解析器的`parse`方法读取并解析XML文件。
5. 实现内容处理器中定义的方法以处理元素、文本等事件。
```python
from xml.sax.handler import ContentHandler, ErrorHandler
from xml.sax import parse
class MyContentHandler(ContentHandler):
def startElement(self, name, attrs):
print("Start element:", name)
def endElement(self, name):
print("End element:", name)
def characters(self, content):
print("Content:", content)
def main():
# 创建解析器
parser = parse("example.xml", MyContentHandler())
if __name__ == "__main__":
main()
```
### 3.1.2 解析XML文件中的节点和属性
XML文件的节点通常包含元素(elements)、文本(text)和属性(attributes)。xml.sax模块提供了丰富的API来处理这些不同的元素。例如,`startElement`方法会在遇到XML元素的开始标签时被调用,而`endElement`方法则在遇到结束标签时被调用。属性可以通过`startElement`方法的`attrs`参数获取。
```python
class MyContentHandler(ContentHandler):
def startElement(self, name, attrs):
print(f"Start element: {name}, Attributes: {attrs}")
# 获取属性
for attr in attrs.keys():
print(f"Attribute: {attr} = {attrs[attr]}")
# 示例执行逻辑
```
## 3.2 xml.sax模块处理XML事件
### 3.2.1 事件处理的实现方法
在xml.sax中,事件处理是通过实现一个或多个`ContentHandler`接口的方法来完成的。每种类型的事件,如元素开始、元素结束、文本内容、处理指令等,都对应一个方法。在这些方法中,开发者可以根据实际需求编写业务逻辑。
### 3.2.2 自定义事件处理器的应用实例
下面是一个自定义事件处理器的实例,展示了如何使用`ContentHandler`和`ErrorHandler`来处理XML解析过程中的各种事件,并打印出相关信息。
```python
class MyHandler(ContentHandler, ErrorHandler):
def __init__(self, data):
self.data = data
# 省略其他方法实现...
def characters(self, data):
# 处理文本事件
if self.data.strip():
print(f"Characters: {self.data}")
def error(self, exception):
# 错误处理
print(f"Error: {exception}")
# 省略其他方法实现...
```
## 3.3 xml.sax模块的高级特性
### 3.3.1 命名空间处理
在处理复杂的XML文档时,命名空间是一个重要的概念。xml.sax模块允许开发者通过`namespaceURI`和`qname`参数来识别元素和属性所属于哪个命名空间,并作出相应的处理。
### 3.3.2 实现XML验证和约束
XML验证和约束的实现可以通过关联一个`EntityResolver`来完成,它能够解析外部实体,以及通过`DocumentLocator`获取XML文件的文档位置信息,用于验证和约束XML文件的结构。
```python
class MyEntityResolver(EntityResolver):
def resolveEntity(self, public_id, system_id):
# 自定义实体解析逻辑
return InputSource(None)
# 示例执行逻辑
```
在本章中,我们详细探讨了xml.sax模块在XML解析中的应用,包括读取和解析XML文件、处理XML事件以及高级特性如命名空间和验证等。通过对xml.sax模块的深入理解和实践,开发者可以有效地处理XML数据,并在项目中发挥其强大的功能。接下来的章节将通过实际案例,展示xml.sax模块在不同类型项目中的具体应用。
# 4. xml.sax模块在实际项目中的应用案例
## 4.1 从网络爬虫到xml.sax模块的实践
### 网络爬虫的需求分析
网络爬虫是一种自动化获取网络信息的程序或脚本,它通过模拟浏览器的行为,可以按照既定的规则,从互联网上抓取所需数据。在许多情况下,网络爬虫需要处理的网页数据量大且结构复杂,这就要求爬虫具有高效、稳定的解析机制。在这一领域,xml.sax模块由于其事件驱动的处理方式,能够高效地处理大量的XML和HTML数据,因此在网络爬虫中有着广泛的应用。
### xml.sax模块在网络爬虫中的应用
使用xml.sax模块可以有效地处理网络爬虫中的HTML和XML数据。由于其事件驱动特性,对于大型文件或网络请求的数据流, sax模块可以边下载边解析,大大提高了处理效率。
下面是一个简单的例子,展示如何使用xml.sax来解析从网络上获取的HTML内容:
```python
import urllib.request
from xml.sax import make_parser
from xml.sax.handler import ContentHandler
class MyHTMLHandler(ContentHandler):
def startElement(self, name, attrs):
print("Start element:", name)
if attrs:
print("Attributes:")
for key in attrs.keys():
print(" ", key, "=", attrs[key])
def endElement(self, name):
print("End element:", name)
def characters(self, content):
if content.strip():
print("Characters:", repr(content))
# 从网络获取HTML内容
response = urllib.request.urlopen('***')
html = response.read()
# 创建解析器并连接处理器
parser = make_parser()
parser.setContentHandler(MyHTMLHandler())
parser.parse(html)
```
在该示例中,我们创建了一个自定义的处理器`MyHTMLHandler`,重写了`startElement`、`endElement`和`characters`方法。当解析器在解析HTML时遇到开始标签、结束标签或字符数据时,会调用相应的处理器方法。这样,就可以在运行时收集标签和数据信息,并进行处理。
## 4.2 xml.sax模块在数据交换中的角色
### 数据交换标准和XML的关系
数据交换是指两个或多个系统之间传输数据的过程。这种交换往往需要一个通用的数据格式,以确保不同系统之间能够无缝对接。XML由于其良好的跨平台性、可读性和可扩展性,成为了数据交换的理想格式之一。
### xml.sax模块在数据交换中的应用案例
在数据交换中,xml.sax模块可以解析来自不同来源的XML文件,无论是在互联网上传输的数据还是系统间交换的文件。由于它的事件驱动特性,可以很容易地将解析逻辑与业务逻辑分离,从而提高模块化和重用性。
下面是一个使用xml.sax模块处理XML数据交换的例子,假设我们需要解析合作伙伴发送过来的订单信息:
```python
import xml.sax
class MyOrderHandler(xml.sax.ContentHandler):
def __init__(self):
self.in_order = False
def startElement(self, name, attrs):
if name == 'order':
self.in_order = True
print("New order found.")
def endElement(self, name):
if name == 'order':
self.in_order = False
def characters(self, data):
if self.in_order and data.strip():
print("Order data:", data)
# 使用sax解析器解析订单信息
parser = xml.sax.make_parser()
handler = MyOrderHandler()
parser.setContentHandler(handler)
parser.parse('orders.xml')
```
在上述代码中,我们定义了一个`MyOrderHandler`类,它在发现`<order>`标签时记录订单信息,并在遇到数据时输出。这使得我们可以轻松处理合作伙伴以XML格式发送的订单信息。
## 4.3 xml.sax模块在企业级应用中的实践
### 企业级应用的特殊要求
企业级应用通常需要处理的数据量较大,且对数据的准确性和安全性有较高要求。企业级应用往往涉及到复杂的业务逻辑和频繁的数据交换,因此要求所使用的XML解析技术具备高性能、高可靠性和良好的扩展性。
### xml.sax模块在企业级应用中的优势和案例
xml.sax模块在企业级应用中具有以下优势:一是事件驱动模型减少了内存消耗,适合处理大型文件;二是模块化设计可以与业务逻辑分开,易于维护和升级;三是支持标准的XML处理功能,如命名空间和有效性验证。
下面是一个案例,展示企业使用xml.sax模块处理客户订单数据:
```python
import xml.sax
class CustomerOrderHandler(xml.sax.ContentHandler):
# 处理订单数据的逻辑
# ...
# 配置解析器
parser = xml.sax.make_parser()
handler = CustomerOrderHandler()
parser.setContentHandler(handler)
parser.setFeature(xml.sax.handler.feature_namespaces, True)
# 解析订单XML文件
try:
parser.parse("customer_orders.xml")
except xml.sax.SAXParseException as e:
print(f"Error parsing file: {e}")
except Exception as e:
print(f"Error: {e}")
```
在这个例子中,`CustomerOrderHandler`类需要具体实现,包括对订单数据的解析和处理逻辑。该处理器可以进一步扩展以支持各种业务规则和数据校验,以确保企业级应用中数据的准确性和完整性。
# 5. xml.sax模块的扩展与优化
## 5.1 第三方库对xml.sax模块的扩展
### 5.1.1 常用第三方库的选择和安装
随着xml.sax模块在各种应用中变得越来越普遍,开发者也逐渐开始寻求扩展其功能的方法。一些流行的第三方库可以极大地增强xml.sax模块的能力,比如`lxml`和`pysax`等。
安装这些库通常非常简单,可以通过`pip`包管理器进行安装。例如,安装`lxml`库,可以在命令行中输入以下命令:
```bash
pip install lxml
```
### 5.1.2 第三方库对xml.sax模块功能的增强
第三方库通常提供额外的特性,比如更加丰富的解析器选择、更快的解析速度以及与XML Schema的集成等。使用`lxml`库,开发者可以利用其内置的`etree`模块进行XML的读取、修改和序列化,同时兼容SAX接口。下面是`lxml`与SAX结合使用的示例代码:
```python
from lxml import etree
# 使用lxml的etree sax接口
parser = etree.SAXParser()
parser.feed(xml_data) # xml_data是包含XML数据的字符串或文件对象
```
使用第三方库不仅可以扩展功能,还可以在一些特定场景下提供更好的性能和易用性。
## 5.2 xml.sax模块的性能优化策略
### 5.2.1 常见的性能瓶颈分析
在使用xml.sax模块处理大型XML文件时,常见的性能瓶颈主要体现在内存的使用上。 SAX 解析器是事件驱动的,这意味着它在解析XML文件时会创建大量的临时对象,这在处理大型文档时可能会导致显著的内存使用。
为了诊断和理解性能瓶颈,开发者可以使用性能分析工具来监控内存的使用情况和执行时间。Python中常用的性能分析工具包括`cProfile`和`memory_profiler`。
### 5.2.2 针对xml.sax模块的性能优化技巧
针对xml.sax模块的性能优化,可以采取以下几个策略:
- **使用迭代器**: SAX 解析器本质上就是一个事件迭代器,因此应尽量避免在事件处理过程中创建额外的临时对象。
- **优化事件处理器**: 事件处理函数应该尽可能简洁高效,避免在这些函数中执行耗时操作。
- **利用缓存**: 如果需要多次访问某些特定的元素,可以考虑在内存中缓存这些元素的引用,而不是每次都进行解析。
- **并行解析**: 对于非常大的XML文件,可以考虑将文件分割成多个部分,然后在多个线程或进程中并行解析。
下面是一个使用Python的`memory_profiler`模块来监控内存使用情况的示例:
```python
import memory_profiler
@memory_profiler.profile
def sax_parser_process(xml_file):
# SAX parser的处理逻辑
pass
# 运行性能分析
if __name__ == '__main__':
sax_parser_process('large_file.xml')
```
执行上述脚本,`memory_profiler`将输出每个函数调用的内存使用情况,帮助我们识别和优化内存瓶颈。
## 5.3 xml.sax模块未来的发展趋势
### 5.3.1 新标准和新技术的影响
随着新标准的不断出现和技术的发展,xml.sax模块也在不断地演进。例如,为了更好地支持XML 1.1和其它新的XML技术,xml.sax模块未来可能会集成更多的标准规范和更高效的解析算法。
### 5.3.2 xml.sax模块的发展前景预测
xml.sax模块的发展前景是乐观的,它将继续作为Python语言中处理XML数据的重要工具之一。随着互联网的发展和数据交换的增多,对于高效、灵活的XML处理工具的需求也在不断增加。xml.sax模块的轻量级和事件驱动模型使其成为处理大型XML文件的理想选择,未来可能会有更多针对它的优化和扩展库被开发出来,以满足各种复杂应用场景的需求。
总之,xml.sax模块作为一种成熟的XML处理工具,不仅拥有稳定的用户基础,而且随着技术的不断进步,它也将继续发展和完善,以适应不断变化的应用需求。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中用于 XML 解析的 xml.sax 库。从基础概念到高级技术,我们涵盖了以下主题:
* xml.sax 解析机制和事件驱动模型
* 构建自定义 XML 解析器
* 数据转换和结构化
* 避免常见解析错误和安全威胁
* 多线程并发解析
* 与其他 Python XML 库的比较
* 最佳实践、错误处理和内存管理
* 内容定制处理和 XML 与 JSON 的对比
通过这些文章,开发者将全面了解 xml.sax 库,并掌握高效解析 XML 数据所需的技能和技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【JMeter 性能优化全攻略】:9个不传之秘提高你的测试效率
# 摘要
本文全面介绍了JMeter这一开源性能测试工具的基础知识、工作原理、实践技巧及性能优化高级技术。首先,通过解析JMeter的基本架构、线程组和采样器的功能,阐述了其在性能测试中的核心作用。随后,作者分享了设计和优化测试计划的技巧,探讨了高级组件的应用,负载生成与结果分析的方法。此外,文章深入探讨了性能优化技术,包括插件使用、故障排查、调优策略和测试数据管理。最后,本文介绍
【提升文档专业度】:掌握在Word中代码高亮行号的三种专业方法
# 摘要
本文详细探讨了在文档处理软件Word中代码高亮与行号的重要性及其实现技巧。首先介绍了代码高亮和行号在文档中的重要性,紧接着讨论了Word基础操作和代码高亮技巧,包
【PHY62系列SDK实战全攻略】:内存管理、多线程编程与AI技术融合
# 摘要
本文综合探讨了PHY62系列SDK的内存管理、多线程编程以及AI技术的融合应用。文章首先介绍了SDK的基本环境搭建,随后深入分析了内存管理策略、内存泄漏及碎片问题,并提供了内存池和垃圾回收的优化实践。在多线程编程方面,本文探讨了核心概念、SDK支持以及在项目中的实际应用。此外,文章还探讨了AI技术如何融入SDK,并通过
【Matlab代理建模实战】:复杂系统案例一步到位

# 摘要
代理建模作为一种数学和计算工具,广泛应用于复杂系统的仿真和预测,其中Matlab提供了强大的代理建模工具和环境配
LabVIEW进阶必看:动态图片按钮的5大构建技巧
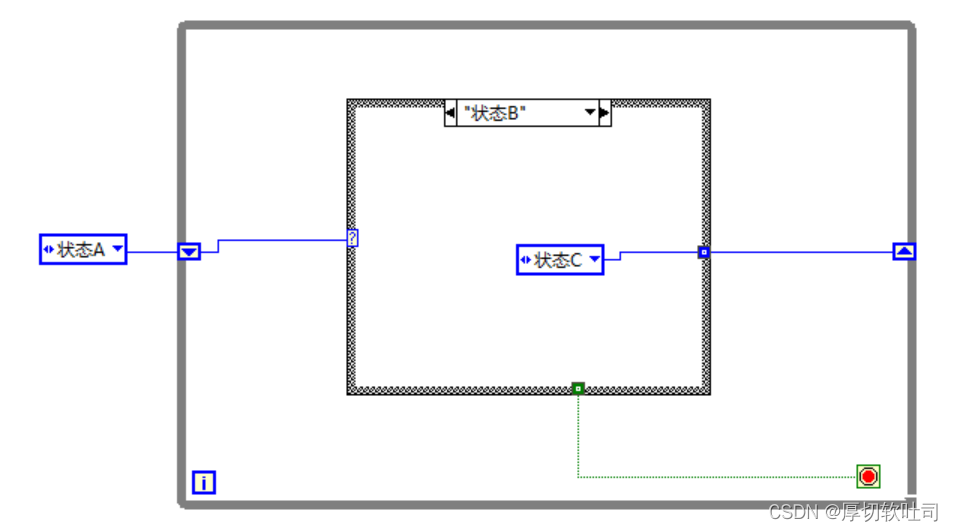
# 摘要
LabVIEW作为一种图形化编程语言,广泛应用于数据采集、仪器控制等领域,其动态图片按钮的开发对于提升交互性和用户体验具有重要意义。本文从动态图片按钮的概述出发,深入探讨了其理论基础、设计技巧、实战开发以及高级应用。文章详细阐述了图形用户界面的设计原则、图片按钮的功能要求、实现技术和优化策略。实战开发章节通过具体案例分析,提供了从创建基础按钮到实现复杂交互逻辑的详细步骤。最后,探讨了动态图片按钮
AXI-APB桥系统集成:掌握核心要点,避免常见故障
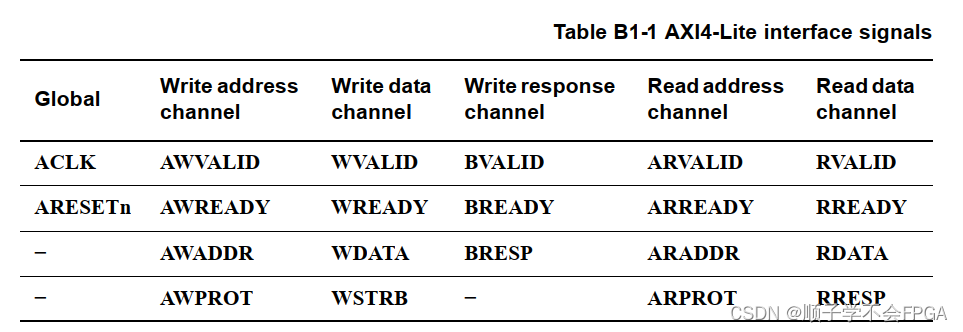
# 摘要
本文全面介绍了AXI-APB桥在系统集成中的应用,包括其理论基础、工作原理和实践应用。首先,介绍了AXI和APB协议的主要特性和在SoC中的作用,以及AXI-APB桥的数据转换、传输机制和桥接信号处理方法。其次,详细阐述了将AXI-APB桥集成到SoC设计中的步骤,包括选择合适的实现、连接处理器与外设,并介绍了调试、验证及兼容性问题的处理。最后,文中针对AXI-APB桥的常见故障
【SMAIL命令行秘籍】:24小时掌握邮件系统操作精髓

# 摘要
本文旨在全面介绍SMAIL命令行工具的基础使用方法、邮件发送与接收的理论基础、邮件系统架构、网络安全措施,以及通过实战操作提高工作效率的技巧。文章深入探讨了SMTP、POP3与IMAP协议的工作原理,以及MTA和MUA在邮件系统中的角色。此外,文章还涵盖了SMAIL命令行的高级使用技巧、自动化脚本编写和集成,以及性能优化与故障排除方
CCU6编程大师课:提升系统性能的高级技巧

# 摘要
CCU6系统性能优化是一个复杂而关键的课题,涉及对系统架构的深入理解、性能监控、调优策略以及安全性能提升等多个方面。本文首先概述了CCU6系统性能优化的重要性,并详细探讨了系统架构组件及其工作原理、性能监控与分析工具以及系统调优的策略,包括硬件资源和软件配置的优化。接着,本文介绍了高级性能提升技巧
【CListCtrl行高调整全攻略】:打造极致用户体验的10个技巧

# 摘要
本文深入探讨了CListCtrl控件在软件开发中的应用,特别是其行高调整的相关技术细节和实践技巧。首先,我们介绍了CListCtrl的基础知识及其行高的基本概念,然后分析了行高特性、绘制机制和技术方法。接着,本文重点讲解了如何根据内容、用户交互和自定义绘制来动态调整
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )