【XML解析入门】:快速掌握xml.sax库,轻松搞定XML基础解析
发布时间: 2024-10-04 20:47:54 阅读量: 35 订阅数: 32 

org.xml.sax.SAXException: Invalid element
# 1. XML解析概述及重要性
随着信息技术的飞速发展,数据交换的标准化需求越来越强烈,XML(Extensible Markup Language)以其独特的可扩展性和自我描述性成为了数据交换格式的重要选择。在各种Web服务、配置文件、甚至数据库中,XML的应用无处不在。本章首先介绍XML解析的基础知识,随后探讨其在当今IT领域的重要性,并通过比较XML与JSON等其他数据交换格式来体现其在特定场景下的优势。
XML解析不仅仅是对XML文档结构的简单阅读,它还包括数据的有效性验证、内容的提取以及数据转换等多个层面。由于XML良好的结构化特性,解析过程可以采用不同的方法,如基于事件的解析(Event-based Parsing)、基于文档对象模型的解析(Document Object Model Parsing)等。本系列将深入探讨如何使用xml.sax库进行XML解析,并在后面的章节中给出具体的代码示例和应用场景分析。
在IT行业中,无论是开发人员、测试人员还是系统架构师,了解XML解析技术都是必须的。这是因为XML广泛地应用于各种项目中,从简单的数据交换到复杂的系统集成,它都能够提供一个稳定、可扩展的解决方案。因此,对于希望保持竞争力的IT专业人士来说,掌握XML解析技术是提升自身技能的重要一步。
# 2. XML基础语法及结构解析
### 2.1 XML文档的基本结构
#### 2.1.1 XML声明及文档类型定义
XML声明是XML文档的起始部分,它指定了XML的版本和可能的编码方式,有助于阅读器了解如何处理文档。文档类型定义(DTD)是一种可选的组件,它用来定义XML文档的结构和语法,确保文档中的数据格式正确无误。
```xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE note SYSTEM "note.dtd">
```
在上述示例中,XML文档声明了版本1.0,并指定了使用UTF-8编码。文档类型定义(DTD)被引用,`note` 表示文档根元素,`SYSTEM` 关键字表示DTD位于本地系统上,并且使用了名为 `note.dtd` 的文件。
#### 2.1.2 元素、标签和属性的使用
XML文档由元素构成,元素由开始标签、结束标签以及标签之间的内容组成。标签通常成对出现,可以包含属性来描述元素的额外信息。
```xml
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>
```
在上述XML结构中,`note` 是根元素,`to`、`from`、`heading` 和 `body` 是子元素。`to` 标签具有一个属性 `Tove`,表示收件人的名字。在XML中,标签和属性名称是大小写敏感的。
### 2.2 XML文档的逻辑结构
#### 2.2.1 元素的嵌套规则
XML文档遵循严格的嵌套规则,即子元素必须完全包含在父元素内。每个开始标签必须有一个匹配的结束标签,不允许交叉。
正确的嵌套:
```xml
<parent>
<child>
<subchild>Content</subchild>
</child>
</parent>
```
不正确的嵌套(将导致解析错误):
```xml
<!-- 不正确的嵌套 -->
<parent>
<child>
<subchild>Content</subchild>
</child>
</parent>
```
#### 2.2.2 CDATA区域和注释的使用
CDATA区域用于包含那些不应该被解析器当作标记来处理的文本数据,通常用于描述符数据或代码块。注释则是用来提供文档说明,不会在文档的XML输出中显示。
```xml
<!-- CDATA区域示例 -->
<description>
CDATA 区域:<![CDATA[这里可以包含任何文本数据,包括 < 符号和 & 符号]]>
</description>
<!-- 注释示例 -->
<!-- 这是一个注释,它不会出现在处理后的XML文档中 -->
```
### 2.3 XML Schema的定义和作用
#### 2.3.1 Schema的基本结构和元素
XML Schema定义了XML文档的结构和数据类型。它比DTD更强大,更灵活,因为它支持数据类型,并且是XML格式的。
```xml
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="***">
<xs:element name="note">
<xs:complexType>
<xs:sequence>
<xs:element name="to" type="xs:string"/>
<xs:element name="from" type="xs:string"/>
<xs:element name="heading" type="xs:string"/>
<xs:element name="body" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
```
上述XML Schema定义了一个名为 `note` 的复杂类型,包含四个字符串类型的子元素:`to`、`from`、`heading` 和 `body`。
#### 2.3.2 数据类型的定义和约束
XML Schema支持各种内置数据类型,如整数、浮点数和字符串,并允许自定义数据类型。同时,Schema可以定义元素的出现次数、可选性等约束。
```xml
<xs:element name="age" type="xs:integer" minOccurs="1" maxOccurs="1"/>
```
在这个例子中,`age` 元素被定义为整数类型,`minOccurs` 和 `maxOccurs` 指定了元素必须出现一次且最多出现一次。
## 第三章:xml.sax库的介绍和安装
### 3.1 xml.sax库的概念和功能
#### 3.1.1 SAX模型的工作原理
SAX(Simple API for XML)是一种基于事件驱动的XML解析方式,通过在解析XML文档时触发一系列事件来工作。程序通过实现事件处理接口来响应这些事件。
```python
import xml.sax
class MyContentHandler(xml.sax.ContentHandler):
def startElement(self, name, attrs):
print('Start element:', name)
print('Attributes:', attrs.keys())
xml.sax.parse('example.xml', MyContentHandler())
```
在上述示例中,每当解析器遇到一个新元素的开始,它将调用 `startElement` 方法,然后 `MyContentHandler` 类会打印出元素名称和属性。
#### 3.1.2 SAX与DOM解析的对比
与SAX不同,DOM(文档对象模型)解析器会将整个XML文档读入内存,并构建为一个节点树,这样可以随意访问文档的任何部分,但代价是内存消耗较大,适用于较小的XML文件。
SAX解析器不会将整个文档加载到内存中,而是边读边解析,特别适合于处理大型XML文件。缺点是只能顺序访问XML文档,不能回溯。
### 3.2 xml.sax库的安装和配置
#### 3.2.1 在不同环境下的安装步骤
对于Python环境,`xml.sax` 是Python标准库的一部分,不需要单独安装。如果是在非Python环境中,如Java,需要安装对应的XML解析库(如JAXP)。
Python安装示例:
```bash
pip install python
```
Java安装示例:
```bash
# 下载并解压JAXP相关的jar文件,例如xercesImpl.jar和xml-apis.jar
# 然后添加到Java的CLASSPATH环境变量中
export CLASSPATH=$CLASSPATH:/path/to/xercesImpl.jar:/path/to/xml-apis.jar
```
#### 3.2.2 配置环境变量和依赖包
Python依赖包管理通常由 `pip` 完成。对于Java环境,需要手动设置 `CLASSPATH` 环境变量,以便Java虚拟机找到必要的库文件。
```bash
# 以Unix系统为例,设置CLASSPATH
export CLASSPATH=$CLASSPATH:/path/to/xml-parsers
```
在配置环境变量时,确保包括所有必要的目录,确保解析器能够找到所有的类和资源文件。
## 第四章:使用xml.sax库进行XML解析
### 4.1 xml.sax库的主要组件解析
#### 4.1.1 解析器(Parser)的使用
解析器是SAX库的核心组件,负责读取XML文档并产生一系列事件。在Python中,使用 `xml.sax.make_parser()` 创建解析器实例,并注册事件处理器。
```python
import xml.sax
# 创建解析器实例
parser = xml.sax.make_parser()
# 注册内容处理器
handler = MyContentHandler()
parser.setContentHandler(handler)
# 开始解析文档
parser.parse('example.xml')
```
在这个例子中,我们创建了一个 `MyContentHandler` 实例,并将其设置为解析器的内容处理器。
#### 4.1.2 事件处理器的角色和实现
事件处理器是响应解析器事件的对象。`ContentHandler` 是最重要的事件处理器,它定义了一系列方法,如 `startElement`、`endElement` 和 `characters` 等。
```python
class MyContentHandler(xml.sax.ContentHandler):
def startElement(self, name, attrs):
# 处理元素开始事件
print('Start element:', name)
print('Attributes:', attrs.keys())
def endElement(self, name):
# 处理元素结束事件
print('End element:', name)
def characters(self, content):
# 处理元素包含的文本内容
print('Content:', content)
```
通过实现这些方法,我们可以对XML文档进行复杂的处理。
### 4.2 编写SAX处理器处理XML
#### 4.2.1 创建ContentHandler处理元素
使用 `ContentHandler` 类可以创建自定义的处理器,用于捕获XML文档中的事件,并根据事件执行相应的操作。
```python
class MyContentHandler(xml.sax.ContentHandler):
def startElement(self, name, attrs):
print('Start element:', name)
print('Attributes:', attrs.keys())
def endElement(self, name):
print('End element:', name)
```
#### 4.2.2 使用ErrorHandler捕获错误
`ErrorHandler` 类用于处理解析过程中出现的错误和警告。通过覆盖 `error`、`warning` 和 `fatalError` 方法,我们可以自定义错误处理逻辑。
```python
class MyErrorHandler(xml.sax.handler.ErrorHandler):
def error(self, exception):
# 处理解析错误
print("Error:", exception.getMessage())
def warning(self, exception):
# 处理警告
print("Warning:", exception.getMessage())
def fatalError(self, exception):
# 处理致命错误
print("Fatal Error:", exception.getMessage())
```
将自定义的 `ErrorHandler` 注册到解析器中:
```python
parser = xml.sax.make_parser()
parser.setFeature(xml.sax.handler.feature_namespaces, False)
parser.setErrorHandler(MyErrorHandler())
```
### 4.3 实践案例分析
#### 4.3.1 从简单XML文档读取数据
解析简单XML文档时,我们可以构建事件处理逻辑来提取所需信息。
```python
from xml.sax.handler import ContentHandler
class MyDataExtractor(ContentHandler):
def startElement(self, name, attrs):
if name == 'data':
self.data = ""
def endElement(self, name):
if name == 'data':
print(self.data)
self.data = ""
def characters(self, content):
if hasattr(self, 'data'):
self.data += content
# 使用该处理器解析文档
```
在此案例中,我们创建了一个 `MyDataExtractor` 类,它专注于提取名为 `data` 的元素内容。
#### 4.3.2 处理大型XML文件和内存管理
处理大型XML文件时,尤其需要注意内存管理。由于SAX是边读边解析,我们应当避免在处理器中保留大量数据。
```python
class LargeFileHandler(ContentHandler):
def startElement(self, name, attrs):
if name == 'record':
self.record = {}
def endElement(self, name):
if name == 'record':
# 处理 record 数据,然后清空
print(self.record)
self.record = None
# 使用该处理器解析大型文件
```
在此案例中,我们在每个 `record` 元素开始和结束时创建和清理记录,从而避免内存溢出。
## 第五章:xml.sax库高级应用和技巧
### 5.1 使用xml.sax扩展库
#### 5.1.1 xml.sax.handler模块深入讲解
`xml.sax.handler` 模块提供了用于定义SAX事件处理器的类。除了 `ContentHandler`,还有 `EntityResolver`、`DTDHandler` 和 `ErrorHandler`。
```python
class MyEntityResolver(xml.sax.handler.EntityResolver):
def resolveEntity(self, publicId, systemId):
# 自定义实体解析逻辑
print("Resolving Entity:", publicId, systemId)
return xml.sax.handler.InputSource("dummy.xml")
```
在这个例子中,`EntityResolver` 可以用于控制外部实体的解析。
#### 5.1.2 xml.sax.utils模块的实用工具
`xml.sax.utils` 模块包含一些用于创建解析器和事件处理器的便捷工具,比如 `make_parser` 函数和 `format_list` 函数。
```python
from xml.sax.utils import make_parser, ISO8601DateHandler
# 创建解析器
parser = make_parser()
# 注册日期处理器
handler = ISO8601DateHandler()
parser.setContentHandler(handler)
# 开始解析
parser.parse('example.xml')
```
在这个例子中,`ISO8601DateHandler` 允许解析器处理符合ISO 8601日期格式的字符串。
### 5.2 在XML解析中使用命名空间
#### 5.2.1 命名空间的定义和使用
命名空间可以解决XML文档中元素和属性的命名冲突问题。它们通过为元素和属性名称添加唯一标识符来实现。
```xml
<note xmlns:h="***">
<h:to>Tove</h:to>
<h:from>Jani</h:from>
<h:heading>Reminder</h:heading>
<h:body>Don't forget me this weekend!</h:body>
</note>
```
在上述XML文档中,`h` 命名空间被用于所有子元素,以区分标准HTML元素。
#### 5.2.2 处理复杂的XML文档结构
在处理包含多个命名空间的复杂XML文档时,需要在事件处理器中适当地识别和处理这些命名空间。
```python
class NamespaceHandler(ContentHandler):
def startElement(self, name, attrs):
print('Start element:', name)
print('Attributes:', attrs.keys())
# 过滤出特定命名空间的属性
for k, v in attrs.items():
if k.startswith('{***}'):
print('Namespace attribute:', k, v)
```
### 5.3 解析过程中的性能优化
#### 5.3.1 事件处理的效率问题
由于SAX是事件驱动模型,处理大量元素时可能会遇到效率瓶颈。可以通过减少事件处理器中的逻辑来优化性能。
```python
class FastContentHandler(ContentHandler):
def startElement(self, name, attrs):
# 简化处理逻辑,减少资源消耗
pass
```
#### 5.3.2 缓存和事件处理优化策略
对某些任务(例如,构建大型数据结构),可以利用缓存来避免在每次事件触发时都进行昂贵的计算。
```python
class CachingContentHandler(ContentHandler):
def __init__(self):
self.cache = {}
def startElement(self, name, attrs):
# 利用缓存处理数据
if name in self.cache:
# 使用缓存数据
pass
else:
# 处理新数据并存储到缓存
self.cache[name] = self.extract_data(attrs)
```
## 第六章:XML解析在实际项目中的应用
### 6.1 XML在数据交换中的应用
#### 6.1.1 使用XML进行数据封装和传输
XML经常用于数据交换,因为它支持复杂的层级结构,并且易于人类阅读。它可以用作各种应用程序之间的通用数据格式。
```xml
<book>
<title>Learning XML</title>
<author>Elliotte Rusty Harold</author>
<year>2004</year>
<price>39.95</price>
</book>
```
上述XML片段可用于封装书籍信息,并通过网络协议进行传输。
#### 6.1.2 解析XML数据的常见场景
解析XML数据的常见场景包括配置文件读取、跨平台数据交换和Web服务交互等。
```python
# 解析来自Web服务的XML格式响应
from xml.etree.ElementTree import fromstring
response_xml = '<response><status>success</status><message>Operation completed</message></response>'
response = fromstring(response_xml)
if response.find('status').text == 'success':
# 处理成功状态下的响应
pass
```
### 6.2 将xml.sax集成到Web服务中
#### 6.2.1 使用XML处理RESTful API
RESTful API使用XML或JSON作为数据交换格式。XML的结构化特性使其在处理复杂数据时具有优势。
```python
import requests
from xml.etree.ElementTree import fromstring
# 发送GET请求获取XML响应
response = requests.get('***')
if response.status_code == 200:
data = fromstring(response.content)
# 解析XML响应内容
for element in data.findall('item'):
print(element.find('name').text, element.find('price').text)
```
#### 6.2.2 在服务端解析XML数据实例
在服务端,可以使用SAX库快速处理大量XML数据,尤其适用于需要实时处理数据流的场景。
```python
import xml.sax
def handler(element):
# 自定义处理逻辑
print(element)
parser = xml.sax.make_parser()
parser.setContentHandler(xml.sax.handler.ContentHandler())
parser.setContentHandler(xml.sax.handler.ContentHandler())
# 读取并解析XML文件
parser.parse('data.xml')
```
### 6.3 XML解析的未来趋势和替代技术
#### 6.3.1 当前XML解析技术的局限性
XML虽然功能强大,但其在解析时需要消耗较多的内存,对错误的处理也不够灵活。随着数据量的增加,性能问题可能会变得更加明显。
#### 6.3.2 JSON等新技术与XML的比较
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,比XML更简单、更易于阅读和编写。由于其较小的内存占用和快速解析能力,JSON逐渐成为Web应用中的首选数据格式。
```json
{
"book": {
"title": "Learning XML",
"author": "Elliotte Rusty Harold",
"year": 2004,
"price": 39.95
}
}
```
上述JSON数据片段在结构上与前文的XML示例类似,但更为紧凑。
# 3. xml.sax库的介绍和安装
## 3.1 xml.sax库的概念和功能
### SAX模型的工作原理
XML简单API(Simple API for XML,简称SAX)是一个常用于解析XML文档的编程接口。它以事件驱动的方式工作,这意味着解析器在读取XML文档的过程中,每当遇到XML文档中的元素,例如标签、属性或者文本等,就会触发一个事件。这些事件可以被应用程序捕捉,并且进行相应的处理。
在SAX中,核心是解析器(parser),它逐个读取XML文件的每一个字符,并且在处理过程中,生成上述提到的事件。SAX模型通常包含以下几种事件:
- 开始标签(startElement)
- 结束标签(endElement)
- 文本内容(characters)
- 处理指令(processingInstruction)
- 注释(comment)
事件处理器负责对这些事件做出响应。由于SAX在处理XML文档时并不需要构建整个文档的树状结构,所以它对内存的需求相对较低,特别适合处理大型的XML文件。
### SAX与DOM解析的对比
与SAX不同,文档对象模型(Document Object Model,简称DOM)解析器会读取整个XML文档,并在内存中构建一个树状结构表示文档的内容。这意味着DOM允许用户对整个文档结构进行随机访问,同时也可以修改文档的内容。
相比之下,SAX是基于流的,适合于只需要顺序遍历一次XML文件的应用场景。它更加轻量级,并且在文件非常大或者内存受限的情况下表现更好。然而,如果需要多次访问文档内容或者需要频繁地进行随机访问,DOM可能是一个更好的选择。
## 3.2 xml.sax库的安装和配置
### 在不同环境下的安装步骤
在Python环境中,SAX库通常指的是`xml.sax`模块,它是Python标准库的一部分,因此不需要安装额外的包即可使用。这个模块包含了一个简单的API,用于将SAX解析器与应用程序连接起来。
要使用`xml.sax`模块,首先确保Python环境已经安装。在大多数现代操作系统上,Python是预装的或者通过包管理器可以轻松安装。例如,在Ubuntu系统上可以通过以下命令安装Python:
```bash
sudo apt-get update
sudo apt-get install python3
```
对于其他操作系统,可以访问Python官方网站下载相应的安装程序。
### 配置环境变量和依赖包
对于Python,通常不需要特别配置环境变量,除非需要使用特定版本的Python或者有特殊的环境需求。在大多数情况下,Python的安装程序会自动配置好必要的环境变量。
如果是在虚拟环境中工作(强烈推荐),则需要创建一个新的虚拟环境或者激活现有的虚拟环境。创建和激活虚拟环境的步骤通常如下:
创建一个新的虚拟环境:
```bash
python3 -m venv myenv
```
激活虚拟环境(Windows系统):
```cmd
myenv\Scripts\activate
```
激活虚拟环境(Unix或MacOS系统):
```bash
source myenv/bin/activate
```
一旦配置好环境,就可以在该环境中安装依赖包,并使用`xml.sax`模块了。然而,对于标准的SAX功能,不需要安装额外的依赖包。
## 3.3 使用xml.sax进行XML解析
### 解析器(Parser)的使用
要使用`xml.sax`进行XML解析,首先需要导入相应的模块,并创建一个解析器实例。Python内置的`xml.sax`模块提供了`make_parser`函数,用于生成一个SAX解析器的实例。以下是一个简单的示例代码,展示了如何使用这个解析器:
```python
import xml.sax
def startElementHandler(tag, attributes):
print("Start element:", tag, attributes.keys())
def endElementHandler(tag):
print("End element:", tag)
# 创建一个SAX解析器实例
parser = xml.sax.make_parser()
# 设置事件处理器
parser.setContentHandler(xml.sax.handler.ContentHandler())
parser.setContentHandler(xml.sax.handler.XMLGenerator())
# 开始解析XML文件
parser.parse("example.xml")
```
### 事件处理器的角色和实现
在SAX解析过程中,事件处理器扮演着至关重要的角色。事件处理器是一些实现了特定接口的类。`xml.sax.handler.ContentHandler`类就是这样一个事件处理器,它定义了文档解析时会触发的所有事件的回调方法。
在上面的代码示例中,我们定义了两个事件处理函数`startElementHandler`和`endElementHandler`,分别用于处理开始标签和结束标签事件。通过重写这些方法,可以实现对XML文档的解析逻辑。
另一个重要的事件处理器是`ErrorHandler`,它可以用于捕获解析过程中的错误,并进行处理。例如,下面的代码示例展示了如何创建一个简单的错误处理器:
```python
class MyErrorHandler(xml.sax.handler.ErrorHandler):
def error(self, exception):
print("Error:", exception)
def fatalError(self, exception):
print("Fatal Error:", exception)
# 创建一个错误处理器实例
handler = MyErrorHandler()
# 绑定错误处理器到解析器
parser setErrorHandler(handler)
# 开始解析XML文件
parser.parse("example.xml")
```
在本章节中,我们了解了`xml.sax`库的基本概念和功能,包括SAX模型的工作原理以及它与DOM解析器的对比。随后,我们讨论了如何在不同环境下安装和配置`xml.sax`模块,并介绍了解析器的使用和事件处理器的角色。在下一章节中,我们将继续深入了解如何编写SAX处理器来处理XML文档中的内容,包括创建`ContentHandler`来读取数据和使用`ErrorHandler`来捕获错误。
# 4. 使用xml.sax库进行XML解析
## 4.1 xml.sax库的主要组件解析
### 4.1.1 解析器(Parser)的使用
xml.sax库是Python中用于处理XML数据的一个库,它基于SAX(Simple API for XML)标准,提供了一个事件驱动的解析器。事件驱动解析最大的特点是无需将整个文档加载到内存中,这样对于大型XML文件的处理效率很高。
在使用SAX解析XML时,我们不需要了解整个文档结构,只需对感兴趣的事件做出反应。例如,开始标签、字符数据、结束标签等,都是SAX解析过程中的事件。
以下是一个使用xml.sax的基本步骤示例:
```python
import xml.sax
class MyHandler(xml.sax.ContentHandler):
def startElement(self, name, attrs):
print("Start element:", name)
def endElement(self, name):
print("End element:", name)
def characters(self, content):
print("Characters:", content)
if __name__ == '__main__':
# 创建一个XML阅读器
parser = xml.sax.make_parser()
# 设置自定义的处理器
parser.setContentHandler(MyHandler())
# 解析XML文件
parser.parse("example.xml")
```
在这个例子中,`MyHandler`类继承自`xml.sax.ContentHandler`,重写了三个方法,分别对应三个不同的事件:开始标签、结束标签和字符数据。这个处理器被设置到解析器上,并使用`parse`方法开始解析指定的XML文件。
解析器的每个事件都会调用处理器中对应的方法。这意味着在解析过程中,代码逻辑与XML结构完全分离,仅处理感兴趣的事件。
### 4.1.2 事件处理器的角色和实现
事件处理器在SAX解析过程中扮演着极为关键的角色。它定义了解析XML时触发的回调函数,决定了如何响应每一个XML解析事件。事件处理器中的每一个方法对应XML解析过程中可能发生的一个事件。
例如,`startElement`方法对应XML元素开始标签事件,`endElement`对应结束标签事件,而`characters`方法则对应元素中包含的文本数据事件。
此外,还可以实现错误处理器`ErrorHandler`来捕获和处理解析过程中的错误。错误处理器同样包含几个方法,如`error`、`fatalError`和`warning`,分别用于处理不同级别的解析错误。
以下是使用错误处理器的一个例子:
```python
class MyErrorHandler(xml.sax.handler.ErrorHandler):
def warning(self, exception):
print("Warning:", exception)
def error(self, exception):
print("Error:", exception)
def fatalError(self, exception):
print("Fatal Error:", exception)
# 通常情况下,致命错误会导致解析器立即停止
raise exception
parser = xml.sax.make_parser()
parser.setFeature(xml.sax.handler.feature_namespaces, False)
parser.setContentHandler(MyHandler())
parser.setErrorHandler(MyErrorHandler())
parser.parse("example.xml")
```
在上述代码中,`MyErrorHandler`类重写了`ErrorHandler`中的方法来打印错误信息,并且在遇到致命错误时抛出异常,这通常会停止解析过程。通过设置错误处理器,可以让程序在遇到错误时做出更合适的处理,而不是依赖默认行为。
# 5. xml.sax库高级应用和技巧
## 5.1 使用xml.sax扩展库
XML的解析在许多高级应用场合中需要使用到额外的扩展库,例如xml.sax.handler和xml.sax.utils模块。这些模块提供了额外的功能和工具,可以帮助开发者以更高效的方式来处理XML数据。
### 5.1.1 xml.sax.handler模块深入讲解
xml.sax.handler模块为XML的解析提供了额外的处理器接口。开发者可以通过继承xml.sax.handler中的基类,来实现自定义的事件处理器。这些处理器能够响应XML解析器在解析过程中触发的不同事件。
下面是一段代码示例,展示了如何创建一个自定义的ContentHandler来处理文档的开始和结束标签:
```python
import xml.sax
class MyContentHandler(xml.sax.ContentHandler):
def startElement(self, name, attrs):
print(f"Start tag: {name}")
# 处理属性
for attr in attrs.items():
print(f"Attribute: {attr[0]}, {attr[1]}")
def endElement(self, name):
print(f"End tag: {name}")
# 创建解析器并使用自定义的处理器
parser = xml.sax.make_parser()
handler = MyContentHandler()
parser.setContentHandler(handler)
# 开始解析
parser.parse("example.xml")
```
在这个例子中,`MyContentHandler`类继承自`xml.sax.ContentHandler`,并重写了`startElement`和`endElement`方法。当解析器遇到XML文档的开始和结束标签时,会调用这些方法,并传入标签名和属性信息,从而可以进行相应的处理。
### 5.1.2 xml.sax.utils模块的实用工具
xml.sax.utils模块提供了许多实用的工具函数,用于操作和处理XML数据。比如`make_parser`函数用于创建一个新的XML解析器实例,而`parse`函数则可以简化XML文件的解析流程。
除了这些,`xml.sax.utils`还包括了用于生成XML字符串的工具,以及一些辅助函数,例如用于将XML元素转换为Python字典的函数。这些工具对于在应用程序中灵活处理XML数据非常有用。
## 5.2 在XML解析中使用命名空间
XML中的命名空间是一种机制,用于区分具有相同名称的元素和属性。它是通过URI来唯一标识的,并允许在同一文档内混合使用来自不同源的数据。
### 5.2.1 命名空间的定义和使用
命名空间通常在XML元素的标签上定义,通过指定`xmlns`属性来实现。例如,假设我们有一个来自不同源的XML数据,可以使用命名空间来区分不同的数据源。
```xml
<books xmlns:sh="***">
<sh:book id="bk101">
<sh:name>XML Fundamentals</sh:name>
<sh:price>29.99</sh:price>
</sh:book>
<sh:book id="bk102">
<sh:name>Learning XML</sh:name>
<sh:price>39.99</sh:price>
</sh:book>
</books>
```
在上述例子中,`***` 是一个命名空间的URI,用来区分不同的书籍信息。
### 5.2.2 处理复杂的XML文档结构
当处理包含多个命名空间的大型XML文档时, SAX解析器需要正确地识别和处理这些命名空间。为了解决这个问题,开发者可以使用`xml.sax.handler`模块中的`NamespaceSupport`类。这个类可以帮助管理不同命名空间的声明,并在解析过程中自动处理这些命名空间。
## 5.3 解析过程中的性能优化
在处理大型XML文件时,性能优化是一个关键的考虑因素。 SAX解析器通过事件驱动的方式处理XML文档,能够快速地从文件流中读取数据,并且通常比DOM解析器有更好的性能。
### 5.3.1 事件处理的效率问题
由于SAX解析器是基于事件的,因此在事件处理函数中执行复杂的操作会直接影响解析效率。为了优化性能,应当尽量减少在事件处理函数中的计算量,特别是在`startElement`和`endElement`方法中。
```python
def startElement(self, name, attrs):
# 可以在这里初始化一些与元素相关的信息,但避免执行耗时操作
pass
def endElement(self, name):
# 可以在这里收集和处理元素信息,但同样避免耗时操作
pass
```
### 5.3.2 缓存和事件处理优化策略
为了进一步提升性能,可以考虑使用缓存技术。比如,在解析过程中缓存某些只读的数据,或者在解析大型文件时采用分片技术,将文件分成小块进行处理,可以有效减轻内存压力。
下面是一个使用缓存来提升性能的简单示例:
```python
class CachedContentHandler(xml.sax.ContentHandler):
def __init__(self):
self._cache = {}
def startElement(self, name, attrs):
# 将属性信息缓存到字典中,避免每次调用都进行相同的计算
self._cache[name] = dict(attrs.items())
def endElement(self, name):
# 处理缓存中的数据
# ...
```
通过使用缓存,我们能够减少对同一数据的重复处理,从而在大型XML文件解析中取得更好的性能。
在本章节中,我们探讨了使用xml.sax库进行高级应用和技巧,包括扩展库的使用、命名空间的处理以及性能优化策略。这些高级技术能够帮助开发者在面对复杂或大型XML数据时,提升解析效率和处理能力。接下来的章节将更深入地讲解XML解析在实际项目中的应用,包括数据交换、Web服务集成以及与新技术的比较。
# 6. XML解析在实际项目中的应用
在实际开发中,XML解析技术的运用无处不在,无论是数据交换、Web服务还是集成应用,XML解析都有着不可或缺的作用。在这一章节中,我们将重点探讨XML在项目中的具体应用,并展望XML解析的未来趋势及可能的替代技术。
## 6.1 XML在数据交换中的应用
XML是数据交换的标准格式之一,它允许不同系统之间共享数据。在这一部分,我们将了解XML在数据封装和传输中的应用。
### 6.1.1 使用XML进行数据封装和传输
数据封装指的是将数据按照特定的格式组织起来,以便于传输和处理。在Web服务和API调用中,XML因其结构清晰、易于读写而被广泛采用。
#### 实例
```xml
<order>
<customer>
<name>John Doe</name>
<email>***</email>
</customer>
<items>
<item>
<name>Widget</name>
<quantity>10</quantity>
</item>
<item>
<name>Gadget</name>
<quantity>5</quantity>
</item>
</items>
</order>
```
此XML示例描述了一个订单,包含客户信息和订单项。该格式可以很容易地在客户端和服务端之间传输,以满足数据交换的需求。
### 6.1.2 解析XML数据的常见场景
解析XML数据是指从一个包含XML数据的文档中提取所需的信息。这在多种开发场景中非常常见,例如:
- **电子商务平台:** 从供应商获取产品目录。
- **社交网络服务:** 处理用户生成的内容和元数据。
- **企业应用集成:** 在不同的系统之间同步数据。
解析过程通常涉及选择合适的解析器(如xml.sax),以及编写事件处理器或DOM树遍历逻辑,以提取和处理XML文档中的数据。
## 6.2 将xml.sax集成到Web服务中
Web服务依赖于数据交换,而XML与Web服务天然契合。在本部分中,我们将关注如何使用xml.sax库处理RESTful API中的XML数据。
### 6.2.1 使用XML处理RESTful API
RESTful API经常使用XML作为其消息格式。通过xml.sax,开发者可以构建高效的XML处理器来解析和生成XML数据。
#### 示例代码
```python
from xml.sax.handler import ContentHandler
import xml.sax
class MyHandler(ContentHandler):
def startElement(self, name, attrs):
print("Start Element:", name)
def endElement(self, name):
print("End Element:", name)
def characters(self, content):
print("Content:", content)
# 使用xml.sax解析器
parser = xml.sax.make_parser()
handler = MyHandler()
parser.setContentHandler(handler)
parser.parse("api_data.xml")
```
### 6.2.2 在服务端解析XML数据实例
解析XML数据通常涉及到在服务端接收、解析请求数据并相应地生成响应。下面是一个简化的例子,演示了如何在Flask Web应用中集成XML解析。
```python
from flask import Flask, request, Response
import xml.etree.ElementTree as ET
app = Flask(__name__)
@app.route('/process_xml', methods=['POST'])
def process_xml():
# 从POST请求中获取XML数据
xml_data = request.data
# 解析XML数据
root = ET.fromstring(xml_data)
# 处理XML数据...
# 返回响应
return Response("XML processed", mimetype="text/plain")
if __name__ == '__main__':
app.run()
```
## 6.3 XML解析的未来趋势和替代技术
尽管XML至今仍广泛使用,但它面临着一些挑战和限制。我们将在本节探讨XML解析技术的局限性,并与现代替代技术进行比较。
### 6.3.1 当前XML解析技术的局限性
XML解析技术的主要问题包括:
- **复杂性:** XML的灵活性导致了过于复杂的数据结构。
- **性能开销:** 由于其结构的复杂性,解析XML通常比解析其他格式如JSON消耗更多的计算资源。
- **可读性:** 对于非技术人员而言,XML文档可能难以阅读和理解。
### 6.3.2 JSON等新技术与XML的比较
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它在可读性和简洁性方面优于XML。下面是XML与JSON的简单比较:
| 特性 | XML | JSON |
|------------|------------------------|------------------|
| 可读性 | 较低,需要标签和结构 | 较高,结构简单 |
| 数据大小 | 较大,文本格式 | 较小,紧凑格式 |
| 开发工具支持 | 有广泛的库和工具支持 | 支持广泛且不断增长 |
虽然XML在某些领域仍然是不可替代的,但在新的Web应用和API开发中,JSON正成为更受欢迎的选择。然而,XML由于其悠久的历史和应用广泛性,它在可见的将来仍将保持其相关性。
在本章中,我们深入探讨了XML解析技术在实际项目中的应用,并比较了其与现代替代技术的差异。开发者在选择技术时,应根据项目需求和未来扩展性来权衡利弊。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中用于 XML 解析的 xml.sax 库。从基础概念到高级技术,我们涵盖了以下主题:
* xml.sax 解析机制和事件驱动模型
* 构建自定义 XML 解析器
* 数据转换和结构化
* 避免常见解析错误和安全威胁
* 多线程并发解析
* 与其他 Python XML 库的比较
* 最佳实践、错误处理和内存管理
* 内容定制处理和 XML 与 JSON 的对比
通过这些文章,开发者将全面了解 xml.sax 库,并掌握高效解析 XML 数据所需的技能和技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【银行系统建模基础】:UML图解入门与实践,专业破解建模难题
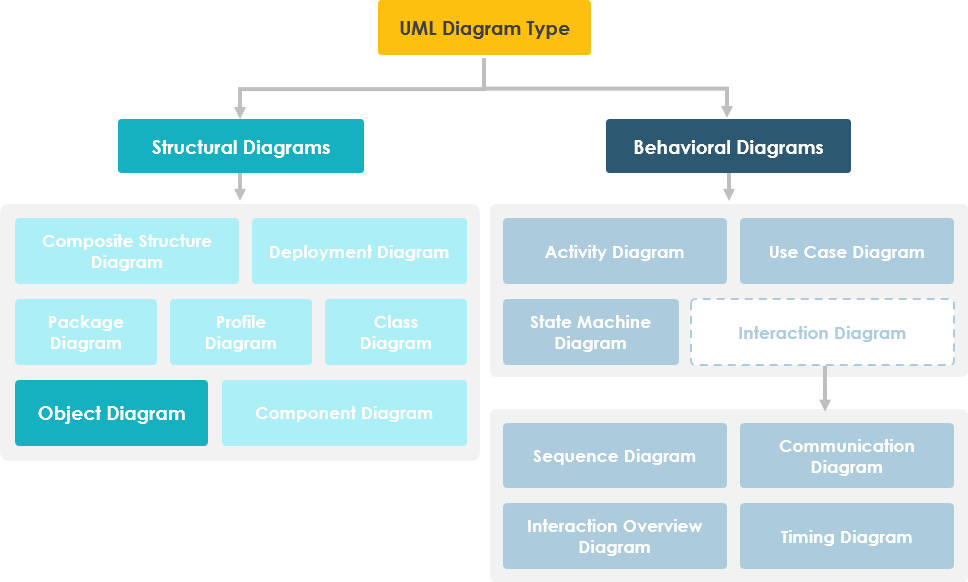
# 摘要
本文系统地介绍了UML在银行系统建模中的应用,从UML基础理论讲起,涵盖了UML图解的基本元素、关系与连接,以及不同UML图的应用场景。接着,本文深入探讨了银行系统用例图、类图的绘制与分析,强调了绘制要点和实践应用。进一步地,文章阐释了交互图与活动图在系统行为和业务流程建模中的设
深度揭秘:VISSIM VAP高级脚本编写与实践秘籍
# 摘要
本文详细探讨了VISSIM VAP脚本的编程基础与高级应用,旨在为读者提供从入门到深入实践的完整指导。首先介绍了VAP脚本语言的基础知识,包括基础语法、变量、数据类型、控制结构、类与对象以及异常处理,为深入编程打下坚实的基础。随后,文章着重阐述了VAP脚本在交通模拟领域的实践应用,包括交通流参数控制、信号动态管理以及自定义交通规则实现等。本文还提供了脚本优化和性能提升的策略,以及高级数据可视化技术和大规模模拟中的应用。最
【软件实施秘籍】:揭秘项目管理与风险控制策略
# 摘要
软件实施项目管理是一个复杂的过程,涉及到项目生命周期、利益相关者的分析与管理、风险管理、监控与控制等多个方面。本文首先介绍了项目管理的基础理论,包括项目定义、利益相关者分析、风险管理框架和方法论。随后,文章深入探讨了软件实施过程中的风险控制实践,强调了风险预防、问题管理以及敏捷开发环境下的风险控制策略。在项目监控与控制方面,本文分析了关键指标、沟通管理与团队协作,以及变
RAW到RGB转换技术全面解析:掌握关键性能优化与跨平台应用策略

# 摘要
本文系统地介绍了RAW与RGB图像格式的基础知识,深入探讨了从RAW到RGB的转换理论和实践应用。文章首先阐述了颜色空间与色彩管理的基本概念,接着分析了RAW
【51单片机信号发生器】:0基础快速搭建首个项目(含教程)
# 摘要
本文系统地介绍了51单片机信号发生器的设计、开发和测试过程。首先,概述了信号发生器项目,并详细介绍了51单片机的基础知识及其开发环境的搭建,包括硬件结构、工作原理、开发工具配置以及信号发生器的功能介绍。随后,文章深入探讨了信号发生器的设计理论、编程实践和功能实现,涵盖了波形产生、频率控制、编程基础和硬件接口等方面。在实践搭建与测试部分,详细说明了硬件连接、程序编写与上传、以
深入揭秘FS_Gateway:架构与关键性能指标分析的五大要点

# 摘要
FS_Gateway作为一种高性能的系统架构,广泛应用于金融服务和电商平台,确保了数据传输的高效率与稳定性。本文首先介绍FS_Gateway的简介与基础架构,然后深入探讨其性能指标,包括吞吐量、延迟、系统稳定性和资源使用率等,并分析了性能测试的多种方法。针对性能优化,本文从硬件和软件优化、负载均衡及分布式部署角度提出策略。接着,文章着重阐述了高可用性架构设计的重要性和实施策略,包括容错机制和故障恢复流程。最后,通过金
ThinkServer RD650故障排除:快速诊断与解决技巧

# 摘要
本文全面介绍了ThinkServer RD650服务器的硬件和软件故障诊断、解决方法及性能优化与维护策略。首先,文章对RD650的硬件组件进行了概览,随后详细阐述了故障诊断的基础知识,包括硬件状态的监测、系统日志分析、故障排除工具的使用。接着,针对操作系统级别的问题、驱动和固件更新以及网络与存储故障提供了具体的排查和处理方法。文章还探讨了性能优化与
CATIA粗糙度参数实践指南:设计师的优化设计必修课
# 摘要
本文详细探讨了CATIA软件中粗糙度参数的基础知识、精确设定及其在产品设计中的综合应用。首先介绍了粗糙度参数的定义、分类、测量方法以及与材料性能的关系。随后,文章深入解析了如何在CATIA中精确设定粗糙度参数,并阐述了这些参数在不同设计阶段的优化作用。最后,本文探讨了粗糙度参数在机械设计、模具设计以及质量控制中的应用,提出了管理粗糙度参数的高级策略,包括优化技术、自动化和智能
TeeChart跨平台部署:6个步骤确保图表控件无兼容问题
# 摘要
本文介绍TeeChart图表控件的跨平台部署与兼容性分析。首先,概述TeeChart控件的功能、特点及支持的图表类型。接着,深入探讨TeeChart的跨平台能力,包括支持的平台和部署优势。第三章分析兼容性问题及其解决方案,并针对Windows、Linux、macOS和移动平台进行详细分析。第四章详细介绍TeeChart部署的步骤,包括前期准备、实施部署和验证测试。第五
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )