MATLAB自动化脚本大全:解放双手,提升效率,自动化办公
发布时间: 2024-06-16 23:57:37 阅读量: 107 订阅数: 43 

# 1. MATLAB自动化脚本概述**
MATLAB自动化脚本是一种强大的工具,可用于简化和自动化重复性任务,从而提高工作效率和生产力。这些脚本使用MATLAB编程语言编写,该语言专为科学计算和数据分析而设计。
MATLAB自动化脚本的优势包括:
* **节省时间:**通过自动化重复性任务,脚本可以释放宝贵的时间,让用户专注于更具战略意义的工作。
* **提高准确性:**脚本可以消除手动操作中的人为错误,确保任务以一致和准确的方式执行。
* **增强可重复性:**脚本可以轻松地重复使用和修改,从而确保任务以标准化和可重复的方式执行。
# 2. MATLAB脚本编程基础
### 2.1 变量和数据类型
#### 2.1.1 变量声明和赋值
在MATLAB中,变量是存储数据的容器。变量的声明使用`=`运算符,语法如下:
```
variable_name = value;
```
例如,声明一个名为`x`的变量并赋值为5:
```
x = 5;
```
#### 2.1.2 数据类型和转换
MATLAB支持多种数据类型,包括:
| 数据类型 | 描述 |
|---|---|
| 数值 | 整数、浮点数、复数 |
| 字符串 | 文本数据 |
| 逻辑 | 真或假 |
| 单元格数组 | 存储不同类型数据的数组 |
| 结构体 | 存储相关数据的集合 |
可以使用`whos`命令查看变量的数据类型:
```
>> x = 5;
>> whos x
Name Size Bytes Class Attributes
x 1x1 8 double
```
MATLAB提供多种函数进行数据类型转换,例如:
* `int2str`:将整数转换为字符串
* `str2num`:将字符串转换为数字
* `logical`:将非零值转换为真,零值转换为假
### 2.2 流程控制
#### 2.2.1 条件语句
条件语句用于根据条件执行不同的代码块。MATLAB支持以下条件语句:
* `if`语句:如果条件为真,则执行代码块
* `elseif`语句:如果上一个条件为假,则检查下一个条件
* `else`语句:如果所有条件都为假,则执行代码块
* `end`语句:结束条件语句
例如,根据输入的数字判断其奇偶性:
```
number = input('Enter a number: ');
if mod(number, 2) == 0
disp('The number is even.');
elseif mod(number, 3) == 0
disp('The number is divisible by 3.');
else
disp('The number is odd.');
end
```
#### 2.2.2 循环语句
循环语句用于重复执行一段代码块。MATLAB支持以下循环语句:
* `for`循环:根据指定的范围或序列迭代
* `while`循环:只要条件为真,就重复执行代码块
* `break`语句:退出循环
* `continue`语句:跳过当前迭代并继续下一个迭代
例如,使用`for`循环打印从1到10的数字:
```
for i = 1:10
disp(i);
end
```
#### 2.2.3 函数和参数传递
函数是封装代码块的独立单元。函数可以接受参数并返回结果。在MATLAB中,函数使用`function`关键字声明。
例如,声明一个计算两个数和的函数:
```
function sum = add(a, b)
sum = a + b;
end
```
调用函数时,将参数传递给函数:
```
x = 5;
y = 10;
result = add(x, y);
```
### 2.3 调试和优化
#### 2.3.1 常见错误和解决方法
在编写MATLAB脚本时,可能会遇到各种错误。常见的错误包括:
* 语法错误:代码中存在语法错误
* 运行时错误:代码在运行时出错
* 逻辑错误:代码逻辑不正确
可以使用`dbstop`函数设置断点,在特定行停止代码执行,以便调试错误。
#### 2.3.2 性能优化技巧
为了提高MATLAB脚本的性能,可以采用以下技巧:
* 使用向量化操作:避免使用循环,而是使用向量化函数
* 预分配内存:使用`zeros`或`ones`函数预分配内存,避免多次分配
* 避免不必要的函数调用:将重复的计算存储在变量中
* 使用并行化:利用多核处理器进行并行计算
# 3. MATLAB脚本实践
### 3.1 文件操作
#### 3.1.1 文件读写
**文件读写函数**
MATLAB提供了多种文件读写函数,包括:
- `fopen()`:打开文件并返回文件标识符。
- `fclose()`:关闭文件。
- `fread()`:从文件读取数据。
- `fwrite()`:向文件写入数据。
- `fseek()`:设置文件指针位置。
**文件读写示例**
```matlab
% 打开文件
fid = fopen('myfile.txt', 'r');
% 读取文件内容
data = fread(fid, inf);
% 关闭文件
fclose(fid);
```
**参数说明**
- `fopen()`:
- `myfile.txt`:要打开的文件名。
- `'r'`:打开模式,'r'表示只读。
- `fread()`:
- `fid`:文件标识符。
- `inf`:读取文件所有内容。
**逻辑分析**
1. `fopen()`函数打开文件并返回文件标识符。
2. `fread()`函数从文件中读取数据,`inf`表示读取所有内容。
3. `fclose()`函数关闭文件。
#### 3.1.2 文件权限和属性
**文件权限**
MATLAB允许设置文件权限,包括:
- `read`:读取权限。
- `write`:写入权限。
- `execute`:执行权限。
**文件属性**
MATLAB还可以获取文件属性,包括:
- `name`:文件名。
- `size`:文件大小(字节)。
- `date`:文件修改日期。
**文件权限和属性示例**
```matlab
% 获取文件权限
perms = dir('myfile.txt').perms;
% 设置文件权限
chmod('myfile.txt', 'u+w');
% 获取文件属性
fileInfo = dir('myfile.txt');
```
**参数说明**
- `dir()`:获取文件属性。
- `chmod()`:设置文件权限。
- `u+w`:为用户添加写入权限。
**逻辑分析**
1. `dir()`函数获

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
MATLAB迅雷下载专栏汇集了MATLAB编程领域的各种实用指南和教程。从性能优化到图像处理,再到机器学习和深度学习,专栏涵盖了MATLAB各个方面的知识。此外,还提供了并行计算、数据结构和算法、数据库连接、自动化脚本和文件读写等方面的宝贵信息。通过这些全面的教程,读者可以掌握MATLAB的强大功能,提升编程技能,并解决实际问题。专栏旨在帮助MATLAB用户充分利用该软件,释放其潜力,并推动其在各个领域的应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【SketchUp设计自动化】

# 摘要
本文系统地探讨了SketchUp设计自动化在现代设计行业中的概念与重要性,着重介绍了SketchUp的基础操作、脚本语言特性及其在自动化任务中的应用。通过详细阐述如何通过脚本实现基础及复杂设计任务的自动化
【科大讯飞语音识别:二次开发的6大技巧】:打造个性化交互体验
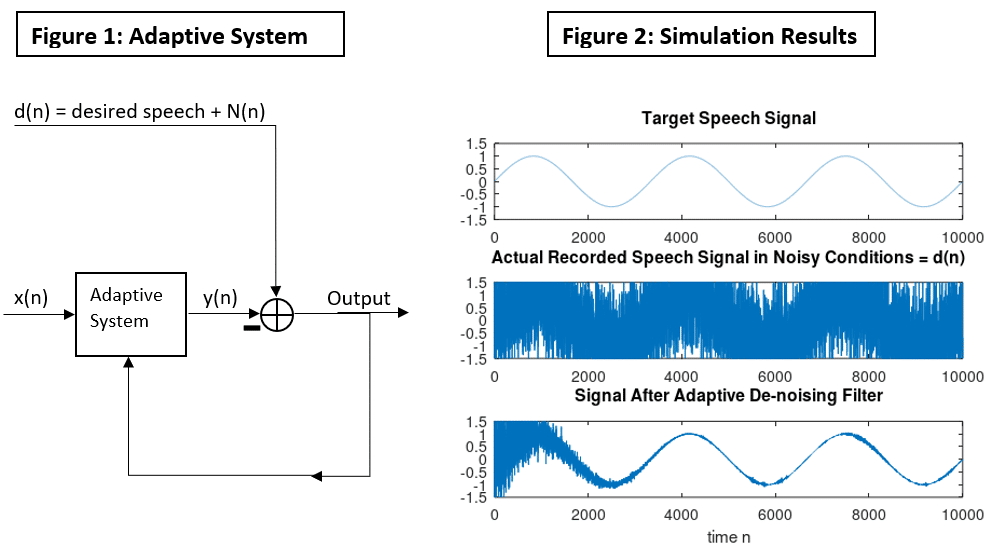
# 摘要
科大讯飞作为领先的语音识别技术提供商,其技术概述与二次开发基础是本篇论文关注的焦点。本文首先概述了科大讯飞语音识别技术的基本原理和API接口,随后深入探讨了二次开发过程中参数优化、场景化应用及后处理技术的实践技巧。进阶应用开发部分着重讨论了语音识别与自然语言处理的结合、智能家居中的应用以及移动应用中的语音识别集成。最后,论文分析了性能调优策略、常见问题解决方法,并展望了语音识别技术的未来趋势,特别是人工
【电机工程独家技术】:揭秘如何通过磁链计算优化电机设计

# 摘要
电机工程的基础知识与磁链概念是理解和分析电机性能的关键。本文首先介绍了电机工程的基本概念和磁链的定义。接着,通过深入探讨电机电磁学的基本原理,包括电磁感应定律和磁场理论基础,建立了电机磁链的理论分析框架。在此基础上,详细阐述了磁链计算的基本方法和高级模型,重点包括线圈与磁通的关系以及考虑非线性和饱和效应的模型。本文还探讨了磁链计算在电机设计中的实际应
【用户体验(UX)在软件管理中的重要性】:设计原则与实践

# 摘要
用户体验(UX)是衡量软件产品质量和用户满意度的关键指标。本文深入探讨了UX的概念、设计原则及其在软件管理中的实践方法。首先解析了用户体验的基本概念,并介绍了用户中心设计(UCD)和设计思维的重要性。接着,文章详细讨论了在软件开发生命周期中整合用户体验的重要性,包括敏捷开发环境下的UX设计方法以及如何进行用户体验度量和评估。最后,本文针对技术与用户需求平
【MySQL性能诊断】:如何快速定位和解决数据库性能问题

# 摘要
MySQL作为广泛应用的开源数据库系统,其性能问题一直是数据库管理员和技术人员关注的焦点。本文首先对MySQL性能诊断进行了概述,随后介绍了性能诊断的基础理论,包括性能指标、监控工具和分析方法论。在实践技巧章节,文章提供了SQL优化策略、数据库配置调整和硬件资源优化建议。通过分析性能问题解决的案例,例如慢
【硬盘管理进阶】:西数硬盘检测工具的企业级应用策略(企业硬盘管理的新策略)

# 摘要
硬盘作为企业级数据存储的核心设备,其管理与优化对企业信息系统的稳定运行至关重要。本文探讨了硬盘管理的重要性与面临的挑战,并概述了西数硬盘检测工具的功能与原理。通过深入分析硬盘性能优化策略,包括性能检测方法论与评估指标,本文旨在为企业提供硬盘维护和故障预防的最佳实践。此外,本文还详细介绍了数据恢复与备份的高级方法,并探讨了企业硬盘管理的未来趋势,包括云存储和分布式存储的融合,以及智能化管理工具的发展
【sCMOS相机驱动电路调试实战技巧】:故障排除的高手经验
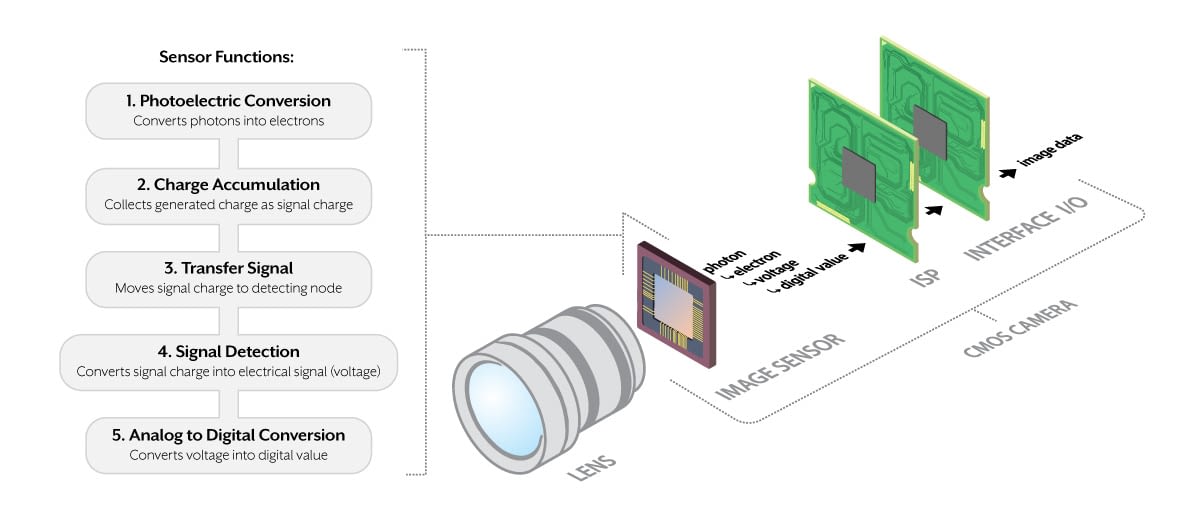
# 摘要
sCMOS相机驱动电路是成像设备的重要组成部分,其性能直接关系到成像质量与系统稳定性。本文首先介绍了sCMOS相机驱动电路的基本概念和理论基础,包括其工作原理、技术特点以及驱动电路在相机中的关键作用。其次,探讨了驱动电路设计的关键要素,
【LSTM双色球预测实战】:从零开始,一步步构建赢率系统
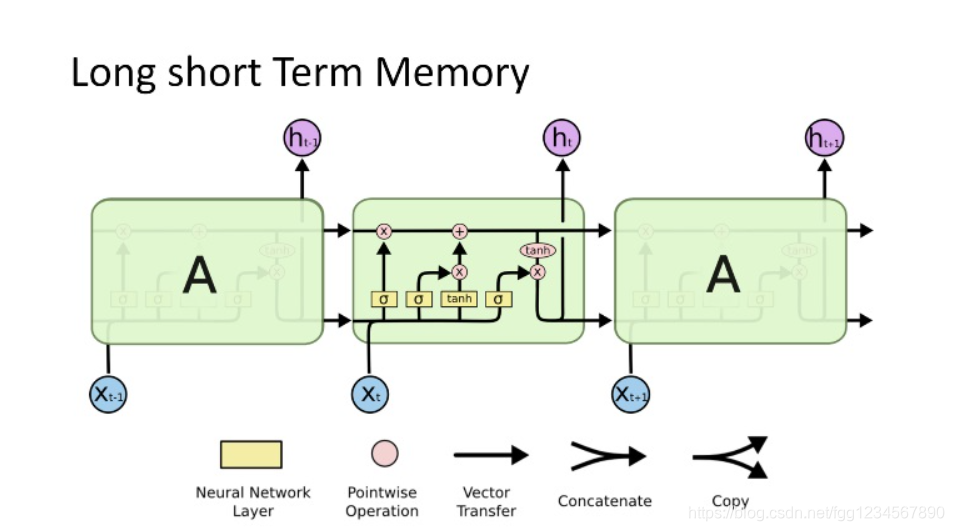
# 摘要
本文旨在通过LSTM(长短期记忆网络)技术预测双色球开奖结果。首先介绍了LSTM网络及其在双色球预测中的应用背景。其次,详细阐述了理
EMC VNX5100控制器SP更换后性能调优:专家的最优实践

# 摘要
本文全面介绍了EMC VNX5100存储控制器的基本概念、SP更换流程、性能调优理论与实践以及故障排除技巧。首先概述了VNX5100控制器的特点以及更换服务处理器(SP)前的准备工作。接着,深入探讨了性能调优的基础理论,包括性能监控工具的使用和关键性能参数的调整。此外,本文还提供了系统级性能调优的实际操作指导
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )