【自然语言处理】:TensorFlow构建文本分类和情感分析模型
发布时间: 2024-11-22 00:58:55 阅读量: 60 订阅数: 35 

# 1. 自然语言处理与TensorFlow简介
在当今数字化世界中,自然语言处理(NLP)是人工智能领域的核心分支之一。NLP专注于建立计算机和人类语言之间的桥梁,使得机器能够理解、解释和生成人类语言。借助NLP,机器能够处理大量非结构化文本数据,提取有价值信息,从而实现自动化的客户服务、情感分析、机器翻译等多种应用。
TensorFlow是一个由Google开发的开源机器学习框架,它被广泛应用于研究和生产环境,支持从单个CPU到大型GPU集群的计算任务。TensorFlow的核心能力之一是处理和分析大量数据集,并在此基础上训练高效的机器学习模型。因此,它已经成为NLP领域的重要工具之一。
在自然语言处理项目中使用TensorFlow,我们可以从构建基础的文本分类模型开始,逐步深入到更复杂的序列模型,如循环神经网络(RNN)和长短时记忆网络(LSTM)。我们还将探讨如何利用预训练模型来提升NLP任务的性能和效率。通过本章的学习,你将对TensorFlow在NLP应用中的作用有一个全面的认识,并为深入研究后续章节打下坚实的基础。
# 2. 文本预处理和特征提取
### 2.1 文本数据的预处理方法
在处理自然语言数据时,数据预处理是一个至关重要的步骤,它直接影响后续特征提取的效果和模型训练的准确度。文本预处理通常包括以下几个关键步骤:
#### 2.1.1 分词与标准化
分词(Tokenization)是将一段文本分割为一系列有意义的单词(tokens)的过程。在不同的语言中,分词的方式可能有很大差异。例如,英文单词之间通常用空格分隔,而中文则是连续的字符流,没有空格分隔,需要采用特定的算法进行分词。
**代码块:Python分词示例**
```python
import jieba
text = "自然语言处理是计算机科学、人工智能和语言学领域中的一个重要方向。"
tokens = jieba.lcut(text)
print(tokens)
```
**逻辑分析和参数说明**
- 上述代码使用了`jieba`库进行中文分词。`jelba.lcut`函数会将输入的字符串`text`分割成一个token列表,并存储在变量`tokens`中。
- 输出结果中的`tokens`包含了多个分词后的中文词汇,为后续的文本分析和特征提取打下了基础。
#### 2.1.2 去除停用词和文本清洗
在分词之后,通常需要去除一些出现频率高但对分析贡献小的词汇,如中文的“的”,英文的“the”,“is”等,这些词称为停用词(Stop Words)。文本清洗还包括去除特殊字符、数字等非语言信息,以及转换大小写等操作。
**代码块:Python去除停用词和文本清洗示例**
```python
stopwords = set(["的", "是", "和", ...]) # 此处省略了完整的停用词表
cleaned_tokens = [token for token in tokens if token not in stopwords]
print(cleaned_tokens)
```
**逻辑分析和参数说明**
- 在这段代码中,首先定义了一个停用词集合`stopwords`,然后通过列表推导式构建了一个新的列表`cleaned_tokens`,其中不包含任何停用词。
- 清洗后的`cleaned_tokens`列表将用于后续的特征提取和模型训练,有助于提高模型的效率和准确性。
### 2.2 文本特征的表示
文本数据是非结构化的,为了能够被机器学习模型处理,必须转换为数值型的特征表示。在这一部分,我们将重点介绍两种常用的文本特征表示方法:词袋模型(Bag of Words)和TF-IDF,以及近年来广泛使用的Word Embeddings和预训练模型。
#### 2.2.1 词袋模型和TF-IDF
词袋模型(Bag of Words)是一种简单而广泛使用的文本表示方法。它忽略了文本中单词的顺序和语法结构,只考虑单词出现的频率。
**代码块:Python实现词袋模型示例**
```python
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(cleaned_tokens)
print(X.toarray())
```
**逻辑分析和参数说明**
- `CountVectorizer`类用于实现词袋模型,它会将输入的单词列表转换为词频矩阵。
- `fit_transform`方法接收处理过的单词列表,拟合数据并进行转换。
- 输出的`X.toarray()`显示了每个单词在每个文档中出现的次数,也就是词频矩阵。
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索与文本挖掘的常用加权技术,其目的是评估一个词在一份文档集合中的重要程度。
**代码块:Python实现TF-IDF示例**
```python
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer()
X_tfidf = tfidf_vectorizer.fit_transform(cleaned_tokens)
print(X_tfidf.toarray())
```
**逻辑分析和参数说明**
- `TfidfVectorizer`类用于实现TF-IDF模型。这个类同样会将单词列表转换为词频矩阵,但会对词频进行加权。
- 加权的目的是减少常见词对文档内容表示的影响,同时突出稀有词的重要性。
- 输出的`X_tfidf.toarray()`展示了每个词在各文档中的TF-IDF权重。
#### 2.2.2 Word Embeddings和预训练模型
词嵌入(Word Embeddings)是将单词转换为稠密向量的技术,这些向量可以捕捉单词之间的语义关系。预训练词嵌入模型如Word2Vec、GloVe等,能在大规模语料库上学习词的向量表示。
**代码块:Python加载预训练词嵌入示例**
```python
import gensim.downloader as api
word2vec_model = api.load('word2vec-google-news-300')
print(word2vec_model["自然"])
```
**逻辑分析和参数说明**
- 上述代码使用`gensim`库加载了一个预训练的Word2Vec模型。
- `word2vec_model["自然"]`获取了词汇“自然”在该模型中的300维向量表示。
- 预训练模型通常能够提供丰富的语义信息,但它们需要大量的计算资源和数据来训练。
预训练的语言模型如BERT、GPT等,在特定任务上通过微调可以达到很高的性能。这些模型不仅能够提供单词级别的表示,还能够理解上下文中的单词含义。
**代码块:使用预训练模型进行文本表示**
```python
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = TFBertModel.from_pretrained('bert-base-chinese', from_pt=True)
inputs = tokenizer.encode_plus(
"我爱自然语言处理",
add_special_tokens=True,
return_tensors='tf'
)
output = model(inputs)
print(output.last_hidden_state)
```
**逻辑分析和参数说明**
- `BertTokenizer`和`TFBertModel`分别用于处理文本输入和加载预训练的BERT模型。
- `encode_plus`方法处理输入文本,为模型提供合适的输入格式。
- `model(inputs)`调用BERT模型,输出文本的隐藏状态表示,该表示可以用于后续的下游任务。
### 2.3 构建输入数据管道
随着深度学习模型越来越复杂,数据处理也变得更加重要。良好的数据管道可以高效地加载、处理、预处理和批量化数据,以供模型训练和评估使用。TensorFlow提供了一整套数据管道API,方便我们构建数据管道。
#### 2.3.1 TensorFlow数据集API的使用
TensorFlow的`tf.data.Dataset` API是一个强大的数据管道构建工具,它允许用户以高效和可扩展的方式加载、操作和批量化数据。
**代码块:使用TensorFlow构建数据集**
```python
import tensorflow as tf
# 创建一个简单的数据集
dataset = tf.data.Dataset.from_tensor_slices((X, y))
# 批量化数据集
batched_dataset = dataset.batch(32)
# 预处理步骤:标准化和数据增强
def preprocess(x, y):
# 这里可以添加数据清洗和增强逻辑
return x, y
preprocessed_dataset = batched_dataset.map(preprocess)
# 迭代数据集
for x, y in preprocessed_dataset:
# 这里可以添加模型训练的代码
pass
```
**逻辑分析和参数说明**
- 通过`tf.data.Dataset.from_tensor_slices`函数,我们可以创建一个包含训练特征和标签的数据集。
- 使用`.batch(32)`方法可以将数据集批量化,每次为模型提供32个样本。
- `map`方法用于对数据集进行转换,可以在这里添加数据预处理的逻辑。
- 最后,通过遍历数据集,我们可以逐批将数据输入到模型中进行训练。
#### 2.3.2 批处理和数据增强
批处理是将多个样本组合成一个批次以供模型一次性处理。数据增强则是在不改变数据标签的前提下,通过一系列变换来扩大训练集的规模和多样性。
在文本数据处理中,数据增强可以通过同义词替换、回译、噪声注入等技术实现。
**代码块:使用TensorFlow进行文本数据增强**
```python
import tensorflow_text as text # TensorFlow Text 库提供了文本处理功能
import tensorflow as tf
# 定义数据增强函数
def data_augmentation(x):
# 这里可以实现同义词替换等增强技术
return x
# 将数据增强函数应用到数据集上
augmented_dataset = dataset.map(lambda x, y: (data_augmentation(x), y))
```
**逻辑分析和参数说明**
- 在这段代码中,`data_augmentation`函数用于增强输入数据。
- `dataset.map`方法将数据增强函数应用到整个数据集上,从而生成增强后的数据集。
- 实际上,数据增强需要针对特定任务定制,以确保增强后的数据仍然是有意义的。
以上就是第二章的核心内容,我们从文本数据的预处理方法、文本特征的表示,到构建输入数据管道进行了深入的讲解。通过这些方法和技术,我们可以为机器学习模型提供高质量的输入数据,从而进一步提高模型的性能和泛化能力。
# 3. TensorFlow模型构建与训练
## 3.1 理解TensorFlow模型结构
### 3.1.1 图(Graph)和张量(Tensor)
在TensorFlow中,一切运算都是在图(Graph)中定义并执行的。图是用于描述计算任务的数据结构,它由节点(Node)和边(Edge)组成,节点代表数学运算,边代表在节点之间流动的数据(即张量Tensor)。图被编译成可执行的计算图(Calculation Graph)后,TensorFlow可以根据计算图并行地执行计算任务,极大地提升了大规模数值计算的效率。
张量则是多维数组的泛化,它在TensorFlow中表示所有的数据。你可以将张量想象成存储数字信息的容器,其中包含了各种维度的数据。图的节点执行计算操作时,其输入输出都是张量,这意味着在构建模型时,我们所做的大部分工作都是对张量进行操作。
#### 示例代码:
```python
import tensorflow as tf
# 创建一个常量张量
a = tf.constant([[1, 2], [3, 4]], dtype=tf.int32)
b = tf.constant([[1, 2], [3, 4]], dtype=tf.int32)
# 定义一个简单的计算图:张量加法
with tf.Graph().as_default():
c = tf.add(a, b) # 'c'代表加法操作的结果
# 创建一个会话.Session,用于执行定义的计算图
with tf.compat.v1.Session() as sess:
print(sess.run(c)) # 输出张量c的值
```
在这个简单的例子中,我们创建了两个常量张量`a`和`b`,并定义了一个加法计算图。通过会话.Session运行计算图后,我们可以得到张量`c`的值。需要注意的是,在TensorFlow 1.x版本中,通常使用`tf.Session()`来运行图,而在TensorFlow 2.x中,这一

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《TensorFlow基础概念与常用方法》专栏深入浅出地介绍了TensorFlow的原理和实践。专栏涵盖了从TensorFlow核心组件到变量管理等一系列主题,旨在帮助读者从零基础入门TensorFlow,并掌握构建高效深度学习模型所需的技能。
专栏中,读者将了解TensorFlow的基础概念,例如张量、图和会话。他们还将学习如何创建、初始化和保存变量,这是深度学习模型中至关重要的参数。此外,专栏还提供了7个秘诀,帮助读者充分利用TensorFlow构建高效的深度学习模型。
通过阅读本专栏,读者将获得全面且实用的TensorFlow知识,为他们在深度学习领域的探索奠定坚实的基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ZW10I8性能提升秘籍:专家级系统升级指南,让效率飞起来!
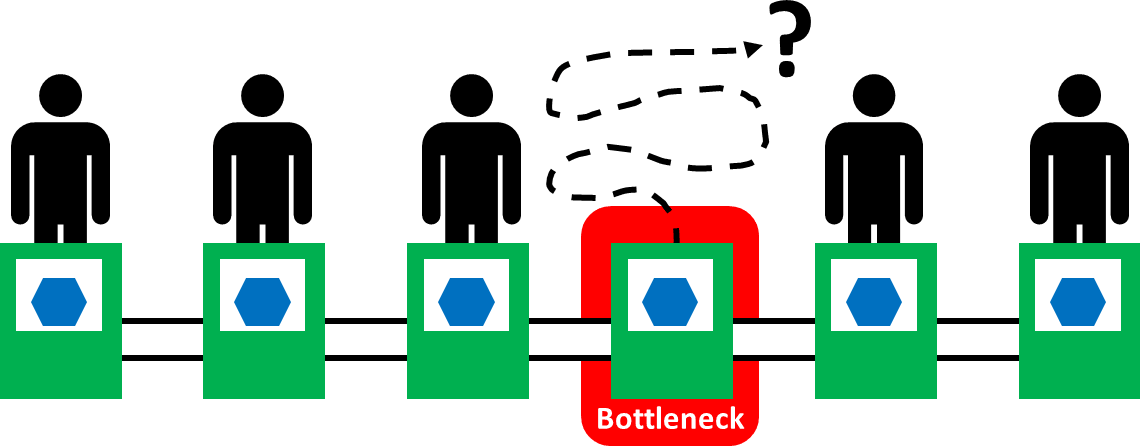
# 摘要
ZW10I8系统作为当前信息技术领域的关键组成部分,面临着性能提升与优化的挑战。本文首先对ZW10I8的系统架构进行了全面解析,涵盖硬件和软件层面的性能优化点,以及性能瓶颈的诊断方法。文章深入探讨了系统级优化策略,资源管理,以及应用级性能调优的实践,强调了合理配置资源和使用负载均衡技术的重要性。此外,本文还分析了ZW10I8系统升级与扩展的
【ArcGIS制图新手速成】:7步搞定标准分幅图制作

# 摘要
本文详细介绍了使用ArcGIS软件进行制图的全过程,从基础的ArcGIS环境搭建开始,逐步深入到数据准备、地图编辑、分幅图制作以及高级应用技巧等各个方面。通过对软件安装、界面操作、项目管理、数据处理及地图制作等关键步骤的系统性阐述,本文旨在帮助读者掌握ArcGIS在地理信息制图和空间数据分析中的应用。文章还提供了实践操作中的问题解决方案和成果展示技
QNX Hypervisor故障排查手册:常见问题一网打尽
# 摘要
本文首先介绍了QNX Hypervisor的基础知识,为理解其故障排查奠定理论基础。接着,详细阐述了故障排查的理论与方法论,包括基本原理、常规步骤、有效技巧,以及日志分析的重要性与方法。在QNX Hypervisor故障排查实践中,本文深入探讨了启动、系统性能及安全性方面的故障排查方法,并在高级故障排查技术章节中,着重讨论了内存泄漏、实时性问题和网络故障的分析与应对策略。第五章通过案例研究与实战演练,提供了从具体故障案例中学习的排查策略和模拟练习的方法。最后,第六章提出了故障预防与系统维护的最佳实践,包括常规维护、系统升级和扩展的策略,确保系统的稳定运行和性能优化。
# 关键字
Q
SC-LDPC码构造技术深度解析:揭秘算法与高效实现

# 摘要
本文全面介绍了SC-LDPC码的构造技术、理论基础、编码和解码算法及其在通信系统中的应用前景。首先,概述了纠错码的原理和SC-LDPC码的发展历程。随后,深入探讨了SC-LDPC码的数学模型、性能特点及不同构造算法的原理与优化策略。在编码实现方面,本文分析了编码原理、硬件实现与软件实现的考量。在解码算法与实践中
VisualDSP++与实时系统:掌握准时执行任务的终极技巧
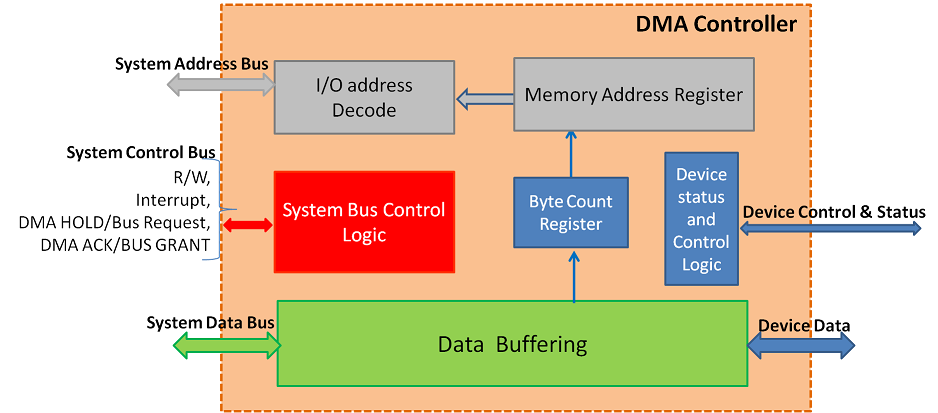
# 摘要
本文系统地介绍了VisualDSP++开发环境及其在实时系统中的应用。首先对VisualDSP++及其在实时系统中的基础概念进行概述。然后,详细探讨了如何构建VisualDSP++开发环境,包括环境安装配置、界面布局和实时任务设计原则。接着,文章深入讨论了VisualDSP++中的实时系
绿色计算关键:高速串行接口功耗管理新技术

# 摘要
随着技术的不断进步,绿色计算的兴起正推动着对能源效率的重视。本文首先介绍了绿色计算的概念及其面临的挑战,然后转向高速串行接口的基础知识,包括串行通信技术的发展和标准,以及高速串行接口的工作原理和对数据完整性的要求。第三章探讨了高速串行接口的功耗问题,包括功耗管理的重要性、功耗测量与分析方法以及功耗优化技术。第四章重点介绍了功耗管理的新技术及其在高速串行接口中
MK9019数据管理策略:打造高效存储与安全备份的最佳实践
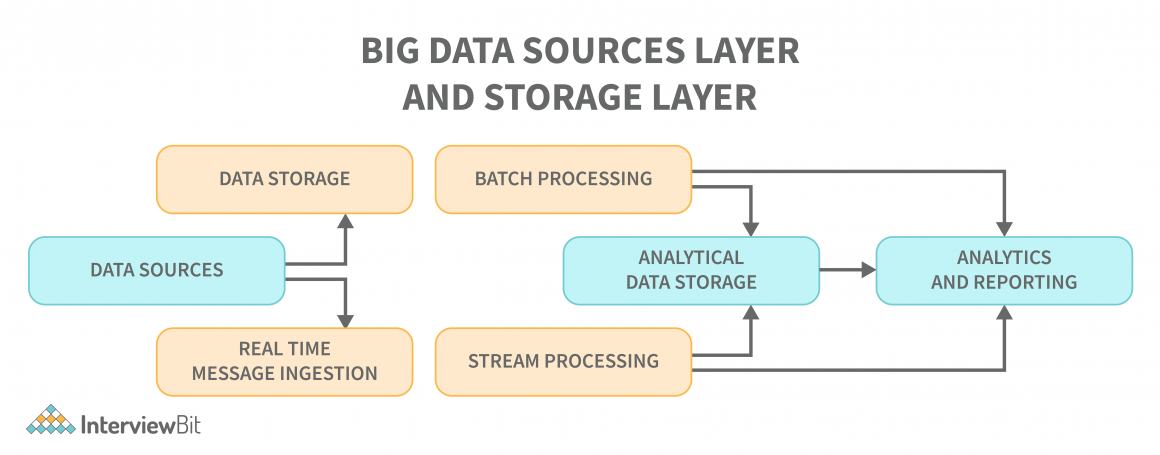
# 摘要
随着信息技术的飞速发展,数据管理策略的重要性日益凸显。本文系统地阐述了数据管理的基础知识、高效存储技术、数据安全备份、管理自动化与智能化的策略,并通过MK9019案例深入分析了数据管理策略的具体实施过程和成功经验。文章详细探讨了存储介质与架构、数据压缩与去重、分层存储、智能数据管理以及自动化工具的应用,强调了备份策略制定、数据安全和智能分析技术
【电脑自动关机脚本编写全攻略】:从初学者到高手的进阶之路
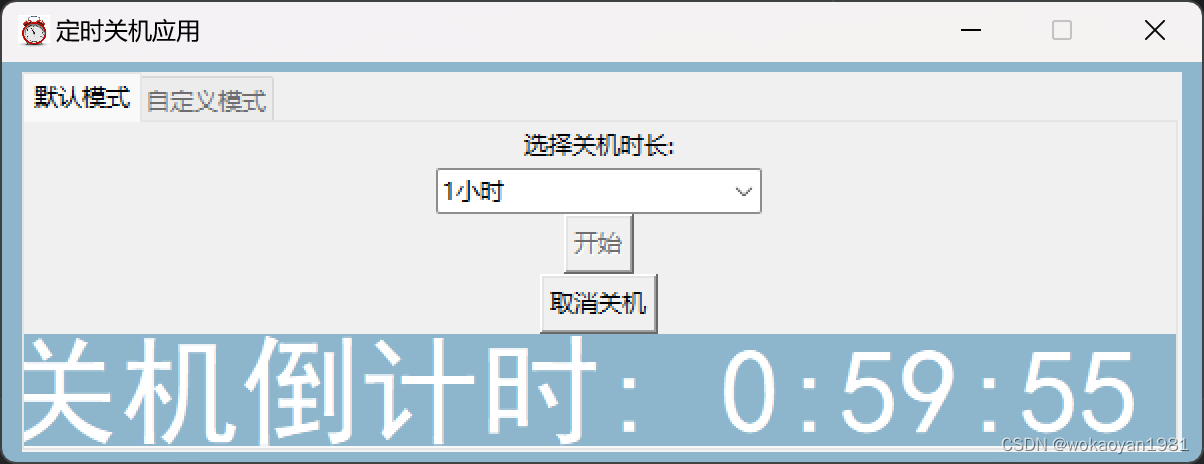
# 摘要
本文系统介绍了电脑自动关机脚本的全面知识,从理论基础到高级应用,再到实际案例的应用实践,深入探讨了自动关机脚本的原理、关键技术及命令、系统兼容性与安全性考量。在实际操作方面,本文详细指导了如何创建基础和高级自动关机脚本,涵盖了脚本编写、调试、维护与优化的各个方面。最后,通过企业级和家庭办公环境中的应用案例,阐述了自动关机脚本的实际部署和用户教育,展望了自动化技术在系统管理中的未来趋势,包
深入CU240BE2硬件特性:进阶调试手册教程

# 摘要
CU240BE2作为一款先进的硬件设备,拥有复杂的配置和管理需求。本文旨在为用户提供全面的CU240BE2硬件概述及基本配置指南,深入解释其参数设置的细节和高级调整技巧,
BRIGMANUAL性能调优实战:监控指标与优化策略,让你领先一步
# 摘要
本文全面介绍了BRIGMANUAL系统的性能监控与优化方法。首先,概览了性能监控的基础知识,包括关键性能指标(KPI)的识别与定义,以及性能监控工具和技术的选择和开发。接着,深入探讨了系统级、应用和网络性能的优化策略,强调了硬件、软件、架构调整及资源管理的重要性。文章进一步阐述了自动化性能调优的流程,包括测试自动化、持续集成和案例研究分析。此外,探讨了在云计算、大
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )