Jsoup项目实战:构建一个新闻聚合器
发布时间: 2024-09-28 17:35:32 阅读量: 35 订阅数: 46 

FloridaMan:CalHacks 项目。 一个“新闻聚合器”

# 1. Jsoup库概述与环境配置
## 1.1 Jsoup库概述
Jsoup是一个广泛使用的Java库,用于解析HTML文档,可以从网页中提取和操作数据。它的主要特点包括:提供一个非常方便的API,能够通过CSS选择器或者jQuery风格的选择器来查询和操作DOM;支持HTML的清理功能,可以用来消除恶意代码;以及能够进行网络爬取,从指定网站抓取所需数据。
## 1.2 环境配置
要在你的Java项目中使用Jsoup库,首先需要将其添加到项目依赖中。如果你使用Maven作为构建工具,可以在项目的`pom.xml`文件中添加以下依赖代码:
```xml
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version> <!-- 请使用最新的版本号 -->
</dependency>
```
接着,你可以通过IDE或者构建工具进行项目更新,或者手动下载jar包并将之加入到项目的classpath中。一旦配置完成,就可以在项目中引入`import org.jsoup.Jsoup;`,开始使用Jsoup解析HTML文档了。
**注意**:在使用Jsoup时,需要考虑目标网站的使用协议,是否允许爬取,以及是否遵循`robots.txt`的相关规则,以确保合法合规地进行数据抓取。
# 2. Jsoup基本使用和HTML解析
在这一章中,我们将深入探讨Jsoup库的基础使用方法,包括如何利用Jsoup进行HTML文档的解析、选择器的使用、文档结构的解析与操作以及CSS选择器和HTML属性的提取与设置。这些内容将为你在构建新闻聚合器和其他需要解析和操作HTML内容的应用中提供坚实的基础。
## 2.1 Jsoup选择器的使用
### 2.1.1 了解选择器类型
Jsoup提供了多种选择器类型,允许开发者以不同的方式从HTML文档中选择元素。最基本的选择器类型包括:
- **标签选择器**:通过HTML标签名来选取元素,例如`a`选择所有的`<a>`标签。
- **类选择器**:通过元素的`class`属性来选取元素,例如`.link`选择所有`class="link"`的元素。
- **ID选择器**:通过元素的`id`属性来选取唯一的元素,例如`#main`选择`id="main"`的元素。
- **属性选择器**:通过元素的属性来选取元素,例如`[href]`选择所有含有`href`属性的元素。
除了这些基础选择器之外,Jsoup还支持组合选择器以及伪类选择器,从而实现更复杂的元素选取。
### 2.1.2 实践选择器查询
```java
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class SelectorExample {
public static void main(String[] args) {
String html = "<html><head><title>First parse</title></head>"
+ "<body><p class='first'>Hello</p><p class='first'>Another <a href='***' class='link'>example</a> link</p></body></html>";
Document doc = Jsoup.parse(html);
// 选择所有的<a>标签
Elements links = doc.select("a");
System.out.println("Total links: " + links.size());
// 选择class为'first'的元素
Elements firstElements = doc.select(".first");
System.out.println("Total first elements: " + firstElements.size());
// 选择具有href属性的元素
Elements elementsWithHref = doc.select("[href]");
System.out.println("Total elements with href: " + elementsWithHref.size());
}
}
```
在上面的代码示例中,我们创建了一个简单的HTML文档并解析它。然后,我们使用不同的选择器来选择文档中的元素,并打印出被选取元素的数量。这些操作演示了如何在实际应用中使用Jsoup选择器进行元素查询。
## 2.2 HTML文档的解析与操作
### 2.2.1 解析HTML文档结构
解析HTML文档是使用Jsoup库的基本功能之一。Jsoup不仅能够解析HTML文本,还能提供一个文档对象模型(DOM)结构,这使得对文档的导航和操作变得简单。
```java
Document doc = Jsoup.parse(htmlContent);
```
这行代码创建了一个`Document`对象,它是Jsoup DOM的根。可以通过它访问整个HTML文档的结构和内容。
### 2.2.2 修改和清理HTML内容
Jsoup提供了强大的API来修改和清理HTML内容。你可以添加新元素、移除不需要的内容、或者清理文档使其符合某些标准。
```java
// 清除脚本
doc.select("script").remove();
// 添加新的段落
Element newPara = doc.createElement("p");
newPara.text("This is a new paragraph.");
doc.body().append(newPara);
// 输出清理后的HTML
System.out.println(doc.body().html());
```
以上示例演示了如何清除文档中的脚本,添加一个新的段落,并输出修改后的HTML内容。这在新闻聚合器中尤其有用,因为我们需要确保呈现的内容是干净、安全的。
## 2.3 Jsoup的CSS选择器与属性操作
### 2.3.1 CSS选择器的应用
Jsoup支持使用CSS选择器来选择元素,这扩展了选择器的功能,使得开发者能够利用CSS选择器的灵活性来定位文档中的元素。
```java
// 使用CSS选择器选择具有特定class的元素
Elements elements = doc.select(".some-class");
// 使用伪类选择器
Elements hoveredItems = doc.select(":hover");
```
这些操作对于操作具有特定样式的元素非常有用,尤其是在处理复杂的文档结构时。
### 2.3.2 HTML属性的提取与设置
在解析HTML文档时,经常需要提取或设置元素的属性。Jsoup为这些操作提供了简洁的API。
```java
// 获取属性
String href = doc.select("a").first().attr("href");
// 设置属性
Element link = doc.select("a").first();
link.attr("href", "***");
link.attr("title", "Jsoup");
// 输出修改后的链接
System.out.println(link.outerHtml());
```
以上代码展示了如何获取和设置`href`属性。这些方法是构建动态HTML内容或处理用户输入时不可或缺

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Jsoup介绍与使用》专栏是一份全面的指南,涵盖了Jsoup HTML解析库的使用。从基础入门到高级技巧,该专栏提供了深入的指导,帮助读者理解Jsoup的强大功能。专栏内容包括:
* HTML解析库的入门指南
* 解析和操作DOM的高级技巧
* 避免解析错误和陷阱的安全使用手册
* 使用选择器和过滤器优化数据提取的进阶技巧
* 构建基于Jsoup的简单爬虫
* Jsoup与正则表达式的协同应用
* 提升爬虫效率的性能优化技巧
* 解析和重构复杂HTML页面的案例分析
* 构建动态网站内容抓取器
* 处理解析异常的错误处理技巧
* 应对JavaScript渲染页面的反爬虫策略
* 移动端数据抓取中的应用详解
* 数据清洗技巧
* 大数据分析中的数据抓取与预处理
* Jsoup与其他爬虫框架的比较分析
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【张量分解:技术革命与实践秘籍】:从入门到精通,掌握机器学习与深度学习的核心算法

# 摘要
张量分解作为数据分析和机器学习领域的一项核心技术,因其在特征提取、预测分类及数据融合等方面的优势而受到广泛关注。本文首先介绍了张量分解的基本概念与理论基础,阐述了其数学原理和优化目标,然后深入探讨了张量分解在机器学习和深度学习中的应用,包括在神经网络、循环神经网络和深度强化学习中的实践案例。进一步,文章探讨了张量分解的高级技术,如张量网络与量
【零基础到专家】:LS-DYNA材料模型定制化完全指南

# 摘要
本论文对LS-DYNA软件中的材料模型进行了全面的探讨,从基础理论到定制化方法,再到实践应用案例分析,以及最后的验证、校准和未来发展趋势。首先介绍了材料模型的理论基础和数学表述,然后阐述了如何根据应用场景选择合适的材料模型,并提供了定制化方法和实例。在实践应用章节中,分析了材料模型在车辆碰撞、高速冲击等工程问题中的应用,并探讨了如何利用材料模型进行材料选择和产品设计。最后,本论文强调了材料模型验证和校准的重要
IPMI标准V2.0实践攻略:如何快速搭建和优化个人IPMI环境
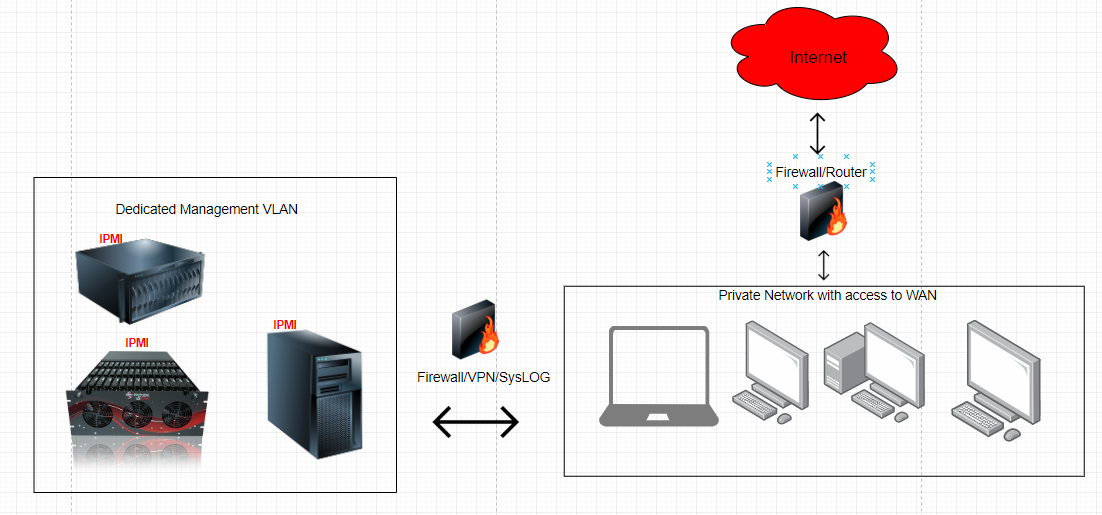
# 摘要
本文系统地介绍了IPMI标准V2.0的基础知识、个人环境搭建、功能实现、优化策略以及高级应用。首先概述了IPMI标准V2.0的核心组件及其理论基础,然后详细阐述了搭建个人IPMI环境的步骤,包括硬件要求、软件工具准备、网络配置与安全设置。在实践环节,本文通过详尽的步骤指导如何进行环境搭建,并对硬件监控、远程控制等关键功能进行了验证和测试,同时提供了解决常见问题的方案。此外,本文
SV630P伺服系统在自动化应用中的秘密武器:一步精通调试、故障排除与集成优化

# 摘要
本文全面介绍了SV630P伺服系统的工作原理、调试技巧、故障排除以及集成优化策略。首先概述了伺服系统的组成和基本原理,接着详细探讨了调试前的准备、调试过程和故障诊断方法,强调了参数设置、实时监控和故障分析的重要性。文中还提供了针对常见故障的识别、分析和排除步骤,并分享了真实案例的分析。此外,文章重点讨论了在工业自动化和高精度定位应用中
从二进制到汇编语言:指令集架构的魅力
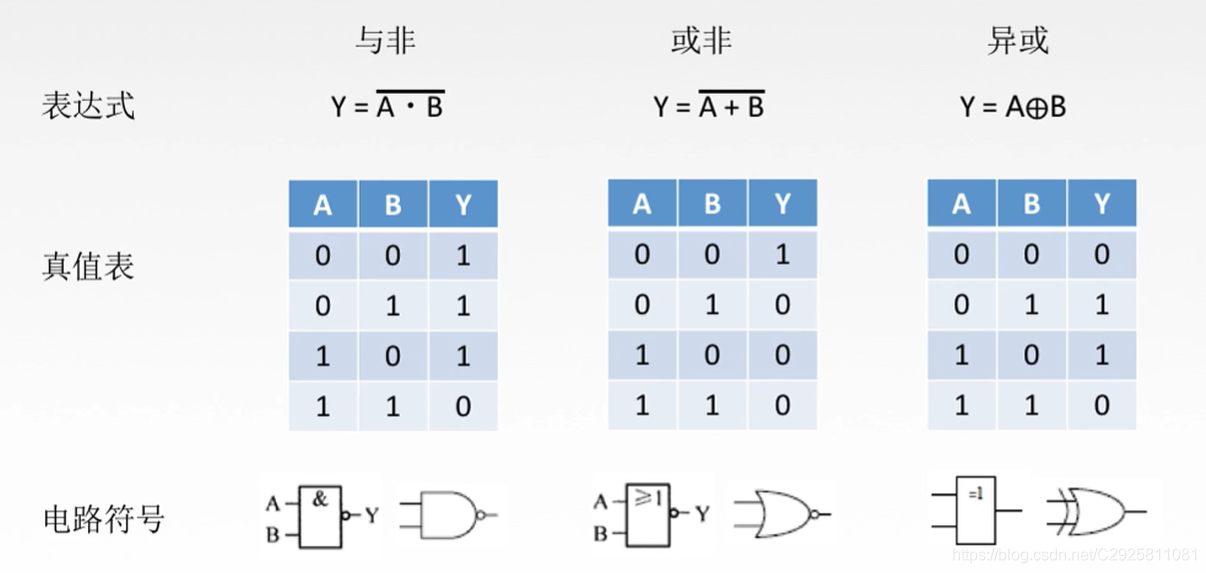
# 摘要
本文全面探讨了计算机体系结构中的二进制基础、指令集架构、汇编语言基础以及高级编程技巧。首先,介绍了指令集架构的重要性、类型和组成部分,并且对RISC和CISC架
深入解读HOLLiAS MACS-K硬件手册:专家指南解锁系统性能优化
# 摘要
本文首先对HOLLiAS MACS-K硬件系统进行了全面的概览,然后深入解析了其系统架构,重点关注了硬件设计、系统扩展性、安全性能考量。接下来,探讨了性能优化的理论基础,并详细介绍了实践中的性能调优技巧。通过案例分析,展示了系统性能优化的实际应用和效果,以及在优化过程中遇到的挑战和解决方案。最后,展望了HOLLiAS MACS-K未来的发展趋势
数字音频接口对决:I2S vs TDM技术分析与选型指南
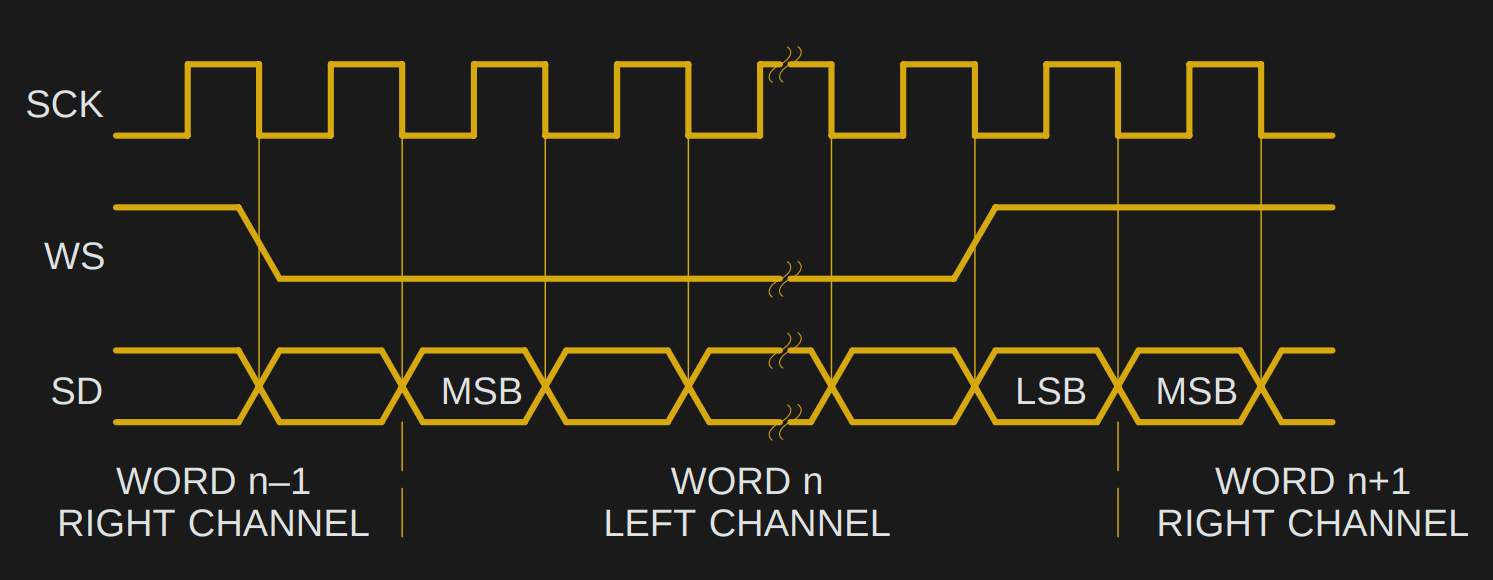
# 摘要
数字音频接口作为连接音频设备的核心技术,对于确保音频数据高质量、高效率传输至关重要。本文从基础概念出发,对I2S和TDM这两种广泛应用于数字音频系统的技术进行了深入解析,并对其工作原理、数据格式、同步机制和应用场景进行了详细探讨。通过对I2S与TDM的对比分析,本文还评估了它们在信号质量、系统复杂度、成本和应用兼容性方面的表现。文章最后提出了数字音频接口的选型指南,并展望了未来技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )