Jsoup错误处理:如何优雅地处理解析异常
发布时间: 2024-09-28 17:22:22 阅读量: 124 订阅数: 45 

spring boot+java +jsoup+ 爬虫

# 1. Jsoup解析库概述与错误处理的重要性
## 1.1 Jsoup解析库概述
Jsoup 是一个功能强大的Java库,用于解析和操作HTML文档。它提供了API,允许开发者从网页上抓取并解析HTML,从而方便地处理数据。不同于其他库,Jsoup提供了一种安全且可靠的方式来处理HTML,它基于DOM(文档对象模型)并且可以防止XSS(跨站脚本攻击)等安全问题。
## 1.2 错误处理的重要性
在使用Jsoup解析HTML文档时,错误处理机制扮演着至关重要的角色。正确的错误处理不仅可以避免程序崩溃,还可以提高代码的健壮性和用户体验。因此,在开发过程中,合理设计错误处理策略能够确保解析过程稳定进行,并且能够有效地响应和处理各种异常情况。
总结来说,本章的目的是帮助读者理解Jsoup解析库的基础知识以及错误处理的重要意义,为后续章节中对Jsoup错误处理机制的详细分析和实战技巧做好铺垫。
# 2. Jsoup基础与HTML解析机制
## 2.1 Jsoup库的基本使用方法
### 2.1.1 Jsoup的文档对象模型(DOM)简介
Jsoup库是Java中一个流行的HTML解析器,允许开发者轻松地从HTML文档中提取和操作数据。它基于DOM(文档对象模型)解析机制,将HTML文档树形结构化,这样就可以轻松地遍历、修改和抽取数据。
DOM是一种以树形结构表示HTML文档的数据模型,每棵树的节点代表HTML文档中的一个元素。在Jsoup中,可以通过解析字符串或从网络获取HTML内容来创建一个Document对象,该对象就代表了DOM树。
### 2.1.2 基本的HTML文档解析流程
要使用Jsoup进行HTML解析,通常需要以下基本步骤:
1. 引入Jsoup库:首先需要将Jsoup库添加到项目的依赖中。
2. 获取HTML文档:可以通过读取本地文件或从网络URL获取HTML内容。
3. 解析HTML:使用Jsoup的parse方法将HTML内容转换成Document对象。
4. 查询和抽取数据:使用Jsoup的选择器查询DOM树,并抽取需要的数据。
下面是一个简单的示例代码:
```java
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupExample {
public static void main(String[] args) {
try {
// 从网络地址获取HTML文档
String url = "***";
Document doc = Jsoup.connect(url).get();
// 使用选择器抽取所有链接
Elements links = doc.select("a[href]");
for (Element link : links) {
System.out.println(link.attr("abs:href"));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
## 2.2 Jsoup的HTML选择器
### 2.2.1 选择器的种类与用法
Jsoup支持多种类型的选择器,例如标签选择器、类选择器、ID选择器、属性选择器等。选择器可以单独使用,也可以组合使用来提高查询的精确度。
- 标签选择器:通过标签名来选择元素,例如`p`会选择所有的`<p>`元素。
- 类选择器:以`.`开头,例如`.myClass`会选择所有具有`myClass`类的元素。
- ID选择器:以`#`开头,例如`#myId`会选择具有`id="myId"`属性的元素。
- 属性选择器:通过属性来选择元素,例如`a[href]`会选择所有具有`href`属性的`<a>`元素。
### 2.2.2 选择器在实际项目中的应用案例
选择器不仅限于简单的查询,还可以结合伪选择器或逻辑运算符来创建复杂的查询条件。例如,使用`:contains()`伪选择器可以查找包含特定文本的元素:
```java
Elements elements = doc.select("p:contains(my text)");
```
结合逻辑运算符和属性选择器,可以实现更复杂的查询:
```java
Elements elements = doc.select("a[href].myClass[title^=Google]");
```
这个查询会返回所有`href`属性值以"Google"开头且具有`myClass`类且`title`属性以"Google"开头的`<a>`元素。
## 2.3 Jsoup的安全性与性能考虑
### 2.3.1 防止XSS攻击的措施
Jsoup自动移除从外部输入的HTML的脚本内容,这有助于预防跨站脚本攻击(XSS)。但是,当使用`html()`或`outerHtml()`方法输出HTML内容时,需要手动清理输出的字符串,以防止XSS攻击。
### 2.3.2 优化解析性能的策略
解析性能是使用Jsoup时需要考虑的关键方面。为了提高性能,可以采取以下措施:
- 缓存Document对象:对于静态内容,解析一次后可以缓存Document对象,避免重复解析。
- 选择合适的解析器:Jsoup提供了不同的解析器,选择一个适合特定任务的解析器可以提高性能。
- 减少不必要的数据抽取:只抽取需要的数据,避免对DOM树进行过度遍历。
接下来,我们将深入探讨Jsoup错误处理机制分析。
# 3. Jsoup错误处理机制分析
## 3.1 Jsoup解析异常类型
### 3.1.1 文档解析异常
在使用Jsoup库解析HTML文档时,开发者可能会遇到多种文档解析异常。这些异常主要分为以下几类:
- `MalformedHTMLException`: 当HTML文档格式不正确时,Jsoup抛出此类异常。通常,这可能是由于标签未正确关闭或属性格式不正确所导致的。
- `IllegalArgumentException`: 此异常通常表示在使用Jsoup的API时传递了无效的参数,例如,传递了不合法的CSS选择器或者使用了不正确的HTML结构。
- `IOException`: 由于网络问题或文件读取问题,在加载外部HTML文档时可能会抛出此异常。
代码分析示例:
```java
try {
// 假设htmlContent是一个不完整的HTML文档字符串
Document doc = Jsoup.parse(htmlContent);
} catch (MalformedHTMLException e) {
// 在此处处理不合法的HTML文档异常
System.err.println("解析的HTML文档格式不正确: " + e.getMessage());
} catch (IOException e) {
// 在此处处理IO异常
System.err.println("文档加载时发生IO异常: " + e.getMessage());
}
```
### 3.1.2 网络请求异常
Jsoup通过HTTP连接获取页面内容时,可能会遇到的异常主要包括:
- `SocketTimeoutException`: 当服务器在指定的时间内没有返回数据时,Jsoup会抛出此异常。
- `UnknownHostException`: 如果无法解析服务器的IP地址,此异常会被抛出。
- `SSLHandshakeException`: 当SSL握手失败时,例如由于证书验证问题或不支持的协议,此异常会被抛出。
代码分析示例:
```java
try {
// 使用Jsoup连接到指定的URL并解析内容
Document doc = Jsoup.connect("***").get();
} catch (SocketTimeoutException e) {
// 在此处处理网络请求超时异常
System.err.println("网络请求超时: " + e.getMessage());
} catch (UnknownHostException e) {
// 在此处处理无法解析服务器地址的异常
System.err.println("无法解析服务器地址: " + e.getMessage());
} catch (SSLHandshakeException e) {
// 在此处处理SSL握手失败的异常
System.err.println("SSL握手失败: " + e.getMessage());
}
```
## 3.2 错误处理的最佳实践
### 3.2.1 异常捕获与处理
在使用Jsoup库进行Web爬虫或文档解析时,正确地处理异常至关重要。以下是一些处理异常的最佳实践:
- 尽可能捕获具体的异常类型,而不是仅仅捕获一般的`Exception`。这样做可以让异常处理更加精确。
- 使用日志记录详细的错误信息。记录下来的异常信息可以用于后续的错误分析和调试。
- 尝试对异常进行恢复处理,而不是简单地停止程序运行。例如,当捕获到`MalformedHTMLException`时,可能需要清理输入字符串并再次尝试解析。
代码分析示例:
```java
try {
// 尝试解析不规则的HTML文档
Document doc = Jsoup.parse(brokenHtmlString);
} catch (MalformedHTMLException e) {
// 清理HTML字符串,例如移除不匹配的标签
String cleanedHtmlString = sanitizeHtml(brokenHtmlString);
try {
// 尝试重新解析清理后的HTML
doc = Jsoup.parse(cleanedHtmlString);
} catch (MalformedHTMLException innerE) {
// 记录无法解析的错误信息
log.error("无法解析清理后的HTML: " + innerE.getMessage());
}
}
```
### 3.2.2 日志记录与错误报告
在错误处理中,日志记录和错误报告是不可或缺的环节。它们不仅有助于开发者追踪和分析错误,也可以提供给用户以获得更好的体验。
- 使用日志框架(如Log4j或SLF4J)来记录详细的错误信息、堆栈跟踪和上下文信息。
- 在生产环境中,根据错误的严重程度,将错误记录发送到不同的渠道,例如控制台、文件或远程日志管理系统。
- 实现错误报告机制,当出现严重的错误时,可以及时通知系统管理员。
代码分析示例:
```java
// 使用SLF4J记录异常
try {
// 尝试执行解析操作
} catch (MalformedHTMLException e) {
// 记录异常信息和堆栈跟踪
logger.error("解析HTML文档时发生异常", e);
// 如果需要,将错误信息发送到错误报告系统
// ...
}
```
## 3.3 Jsoup错误处理的高级特性
### 3.3.1 自定义错误处理器
Jsoup允许开发者自定义错误处理器,以便以编程方式处理解析过程中遇到的错误。通过实现`Connection.ExceptionHandler`接口,可以定制错误处理逻辑。
代码分析示例:
```java
Connection connection = Jsoup.connect("***");
// 自定义异常处理器
connection.exceptionHandler(new Connection.ExceptionHandler() {
public void onError(Connection connection, IOException e, int responseCode) {
// 在此处处理连接异常
System.err.println("连接到服务器时发生错误: " + e.getMessage());
}
});
Document doc = connection.get();
```
### 3.3.2 异常重试机制的实现
在某些情况下,例如网络波动导致的临时错误,重新尝试请求可能是一种有效的策略。可以通过实现重试逻辑来优化错误处理。
代码分析示例:
```java
int maxAttempts =
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Jsoup介绍与使用》专栏是一份全面的指南,涵盖了Jsoup HTML解析库的使用。从基础入门到高级技巧,该专栏提供了深入的指导,帮助读者理解Jsoup的强大功能。专栏内容包括:
* HTML解析库的入门指南
* 解析和操作DOM的高级技巧
* 避免解析错误和陷阱的安全使用手册
* 使用选择器和过滤器优化数据提取的进阶技巧
* 构建基于Jsoup的简单爬虫
* Jsoup与正则表达式的协同应用
* 提升爬虫效率的性能优化技巧
* 解析和重构复杂HTML页面的案例分析
* 构建动态网站内容抓取器
* 处理解析异常的错误处理技巧
* 应对JavaScript渲染页面的反爬虫策略
* 移动端数据抓取中的应用详解
* 数据清洗技巧
* 大数据分析中的数据抓取与预处理
* Jsoup与其他爬虫框架的比较分析
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【PCIe电源管理高级技巧】:打造效能卓越系统的5项策略

# 摘要
随着计算机技术的发展,PCI Express (PCIe) 接口已成为现代计算机系统中不可或缺的组件,其电源管理的效率直接影响系统性能与能效。本文首先概述了PCIe电源管理的基本概念和重要性,深入探讨了PCIe电源状态模型、设备类别的电源管理要求以及不同电源状态的工作原理和转换机制。通过设计高效的电源管理策略和优化PCIe子系统的电源配置,文章介绍了实用的实践技巧,并通过服
Git合并冲突解决艺术:掌握方法,告别代码冲突困扰
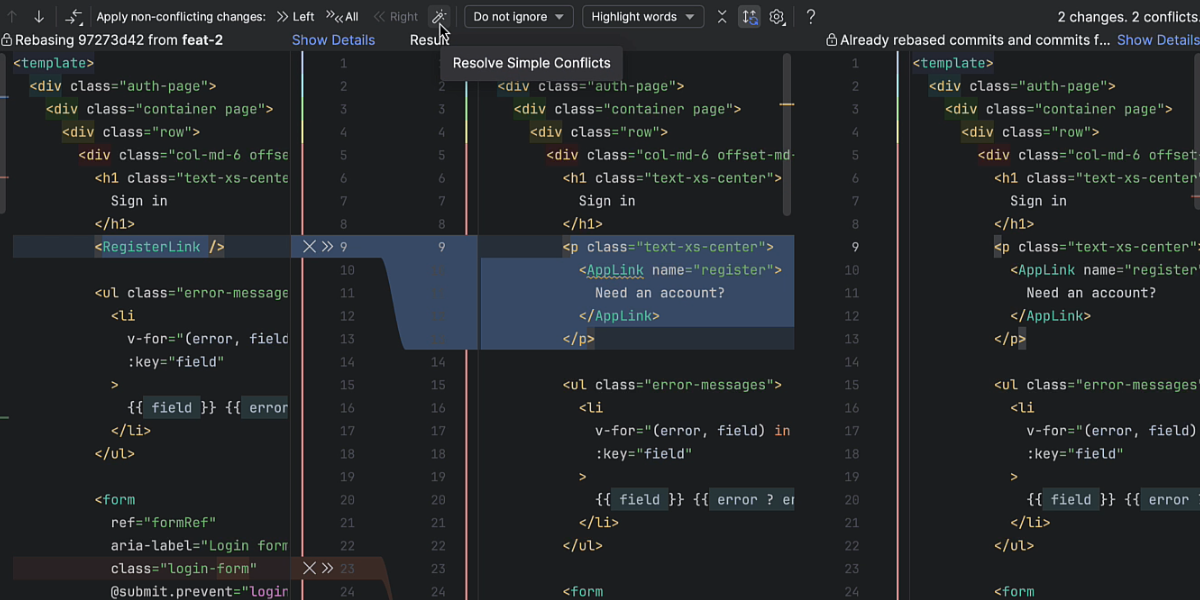
# 摘要
Git合并冲突是版本控制中常见的问题,本文首先介绍了Git合并冲突的基本概念和Git版本控制机制,包括提交图、历史记录、分支管理与合并策略。接着,深入分析了导致冲突的原因,并探讨了常见冲突类型,如代码行级冲突、文件修改与删除的冲突、功能分支与主分支的冲突。文章还提供了预防和应对冲突的心理准备和
Rational Rose进阶建模课程:掌握面向对象设计原则的7个步骤
# 摘要
本文深入探讨了面向对象设计原则,重点阐述了单一职责原则、开闭原则和里氏替换原则的核心概念、实现技巧以及在复杂系统中的应用实例。通过详细分析每个原则的定义和重要性,本文提出了在设计和实现中遵循这些原则的技巧,如类的设计、接口与抽象类的合理应用以及继承和多态的正确使用。案例分析揭示了原则在实际项目中的应用,强调了在软件开发过程中综合运用这些设计原则的必要性。本文还介绍了使用Rational Rose工具
多线程技术在EDID256位设计中的关键作用:并行处理能力的飞跃
# 摘要
多线程技术是现代软件开发中的核心组成部分,它允许程序同时执行多个线程以提高性能和效率。本文首先介绍了多线程技术的基础知识,并探讨了它在EDID256位设计中的应用,强调了多线程技术如何提升EDID256位设计的并行处理能力。接着,文章分析了多线程技术的理论基础与实践应用,通过案例展示了多线程在实际项目中的应用及优化方法。进一步,本文探讨了多线程在高性能计算和网络编程中的作用和优势。最后,文章展望了多线程技术的发展趋势,包括其
【UCINET与Gephi协同作战】:社会网络可视化的艺术与技巧
# 摘要
社会网络分析是理解和解释社会结构与个体间关系的重要工具。本文首先概述了社会网络分析的基础知识及常用工具,接着深入探讨了UCINET与Gephi两款软件的基本操作、数据处理、网络指标计算、图形化界面展示和网络布局动态分析功能。通过实例分析,本文展示了如何协同使用UCINET和Gephi进行高级网络分析,并解读分析结果。最后,文章展望了社会网络分析的理论和实践的未来发展,包括新兴技术的应用以及跨学科整合的潜在趋势。
# 关键字
社会网络分析;UCINET;Gephi;数据处理;网络指标;动态分析
参考资源链接:[UCINET6教程:社会网络分析详解](https://wenku.cs
【Eclipse企业级开发】:从开发到部署的完整流程解析
# 摘要
本文针对Eclipse企业级开发进行了全面的概述,从项目构建和管理到Java EE开发实践,再到应用服务器集成和部署,最后探讨了Eclipse的高级功能与最佳实践。文中详细介绍了工作区与项目结构的设置与配置,Maven和Git的集成及其高级应用,以及Servlet、JSP、JPA和EJB等Java EE技术的具体开发实践。此外,还涉及了应用服务器的配置、部署
61850标准深度解读:IedModeler建模要点全掌握
# 摘要
IEC 61850标准为电力系统的通信网络和系统间的数据交换提供了详细的规范,而IedModeler作为一款建模工具,为实现这一标准提供了强有力的支持。本文首先介绍了IEC 61850标准的核心概念和IedModeler的定位,然后深入探讨了基于IEC 61850标准的建模理论及其在IedModele
内存断点的局限性:识别并避免使用不当的时机
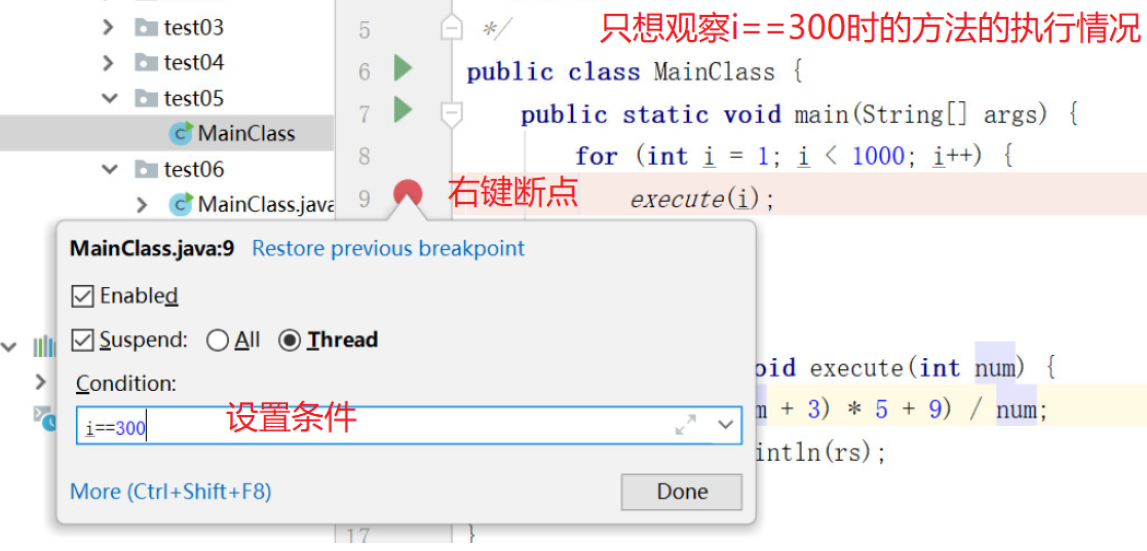
# 摘要
内存断点技术是一种在软件调试过程中广泛使用的工具,用于监控内存访问行为并及时捕获程序中特定内存位置的变化。本文首先概述了内存断点技术的基本概念和分类,然后深入分析了其工作原理及其在不同环境中的应用。继而,探讨了内存断点的局限性,包括性能影响、适用性限制和在特定条件下的失效问题。本文还提出了避免内存断点使用不当的策略,并通过案例分析,展示了内存断点的正确和错误使用
【教育互动材料制作】:PDF在教育行业的创新应用
# 摘要
PDF格式作为一种广泛应用于教育领域的文档标准,其基本应用、技术优势、内部结构和格式规范,以及在教育互动材料中的创新实践和高级开发,都是本文探讨的主题。本文将深入分析制作教育互动PDF的工具、内容制作流程,以及在不同教育场景的应用案例。同时,探讨通过JavaScript和集成外部资源来扩展PDF互动功能,进一步研究如何评估与优化这些互动材料。最后,对人工智能在PDF教育内
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )