比较乐观锁和悲观锁的实现方式和适用场景
发布时间: 2024-02-27 21:50:50 阅读量: 55 订阅数: 17 
# 1. 简介
## 1.1 介绍乐观锁和悲观锁的基本概念
在并发编程中,乐观锁和悲观锁是两种常见的并发控制机制。乐观锁假设对数据的并发访问是不会造成冲突的,因此只在更新数据的时候检查是否有其他线程对数据进行了修改。而悲观锁则认为数据的并发访问会导致冲突,因此在访问数据之前先加锁,确保数据操作的原子性和一致性。
## 1.2 相关概念和术语的定义
在深入讨论乐观锁和悲观锁的实现方式之前,我们需要先了解一些相关的概念和术语。这些术语包括但不限于:
- 并发控制
- 版本号
- CAS(Compare and Swap)算法
- 锁机制
- 数据一致性
- 并发读写
- 事务控制
在接下来的章节中,我们将详细讨论乐观锁和悲观锁的实现方式、适用场景以及对比分析。
# 2. 乐观锁的实现方式
乐观锁是一种乐观地认为数据不会发生冲突的锁机制。在并发操作中,乐观锁并不对数据加锁,而是在更新数据时检查数据是否被其他线程修改过,从而决定是否进行更新。乐观锁通常适用于读多写少的场景,可以有效提高系统的并发能力和性能。
#### 2.1 版本号比对
乐观锁的一种常见实现方式是通过版本号比对来实现。每个数据记录都有一个版本号,当读取数据时,同时也会读取其版本号。在更新数据时,检查当前数据的版本号是否与读取时的版本号一致,如果一致则执行更新操作,否则说明数据已被其他线程修改,需要进行相应的处理(例如抛出异常或者进行重试)。
```java
// Java示例代码:使用版本号比对实现乐观锁
public class OptimisticLockExample {
// 数据对象
static class Data {
private int id;
private String value;
private long version;
// 更新数据操作
public void update(String newValue) {
this.value = newValue;
this.version++;
}
}
public static void main(String[] args) {
Data data = new Data();
// 初始版本号为0
data.version = 0;
// 线程1读取数据
new Thread(() -> {
int expectedVersion = data.version;
// 读取数据...
// 在更新数据时检查版本号
if (data.version == expectedVersion) {
data.update("New Value 1");
} else {
// 处理版本号不一致的情况
System.out.println("Data has been modified by other thread");
}
}).start();
// 线程2同时读取数据
new Thread(() -> {
int expectedVersion = data.version;
// 读取数据...
// 在更新数据时检查版本号
if (data.version == expectedVersion) {
data.update("New Value 2");
} else {
// 处理版本号不一致的情况
System.out.println("Data has been modified by other thread");
}
}).start();
}
}
```
在上面的示例中,两个线程同时读取数据,并尝试进行更新操作。在更新数据时,通过比对版本号来判断数据是否被其他线程修改过,从而保证数据的一致性。
#### 2.2 CAS(Compare and Swap)算法
另一种常见的乐观锁实现方式是使用CAS(Compare and Swap)算法。CAS是一种原子操作,通过比较内存中的值和预期值,如果相符则将新值写入内存,否则不进行任何操作。CAS能够解决多线程并发情况下的数据一致性问题,是乐观锁的重要实现基础之一。
```java
// Java示例代码:使用CAS算法实现乐观锁
import java.util.concurrent.atomic.AtomicReference;
public class OptimisticLockCASExample {
// 数据对象
static class Data {
private AtomicReference<String> value = new AtomicReference<>();
}
public static void main(String[] args) {
Data data = new Data();
// 线程1更新数据
new Thread(() -> {
String expectedValue = data.value.get();
String newValue = "New Value 1";
// 使用CAS进行更新操作
if (data.value.compareAndSet(expectedValue, newValue)) {
System.out.println("Update successful");
} else {
System.out.println("Update failed, data has been modified by other thread");
}
}).start();
// 线程2同时更新数据
new Thread(() -> {
String expectedValue = data.value.get();
String newValue = "New Value 2";
// 使用CAS进行更新操作
if (data.value.compareAndSet(expectedValue, newValue)) {
System.out.println("Update successful");
} else {
System.out.println("Update failed, data has been modified by other thread");
}
}).start();
}
}
```
在上面的示例中,通过AtomicReference和compareAndSet方法实现了CAS算法的乐观锁方式。两个线程同时尝试更新数据,通过CAS算法进行比对和更新操作,保证数据的一致性。
#### 2.3 乐观锁的原理和实现细节
乐观锁的原理是乐观地认为数据不会发生冲突,因此在读取数据时并不会对数据进行加锁,而是在更新时通过版本号比对或CAS算法来确保数据的正确性。乐观锁适用于并发读多写少的场景,并且能够有效提高系统的并发能力和性能。在实现乐观锁时,需要考虑版本号的设计和更新策略,以及CAS算法的正确使用和处理失败情况的方法。
# 3. 乐观锁的适用场景
乐观锁通常适用于以下场景:
### 3.1 并发读多写少的场景
在读操作远多于写操作的情况下,使用乐观锁可以减少对数据的锁定,提高并发性能。通过版本号比对或CAS算法,实现对数据的乐观并发操作,避免了不必要的阻塞和性能损耗。
```java
// Java示例代码
public class OptimisticLockingDemo {
private int data;
private int version;
public void updateData(int newData) {
// 读取数据和版本号
int oldData = data;
int oldVersion = version;
// 模拟其他并发操作修改了数据
if (oldVersion == version) {
// 使用CAS算法更新数据和版本号
if (compareAndSet(oldData, newData, oldVersion, oldVersion + 1)) {
System.out.println("数据更新成功");
} else {
System.out.println("数据更新失败,版本号不匹配");
}
} else {
System.out.println("数据已被其他线程修改,更新失败");
}
}
}
```
### 3.2 分布式环境下的应用
在分布式系统中,乐观锁能够更好地适应多个节点之间的数据一致性和并发控制需求。通过版本号或CAS算法的方式,可以在分布式环境下实现对数据的乐观并发操作,减少对全局锁的依赖,提高系统的扩展性和性能。
```go
// Go示例代码
type Data struct {
Value int
Version int
}
func UpdateData(d *Data, newValue int) {
// 读取数据和版本号
oldValue := d.Value
oldVersion := d.Version
// 模拟其他并发操作修改了数据
if oldVersion == d.Version {
// 使用CAS算法更新数据和版本号
if CompareAndSwap(&d.Value, oldValue, newValue) && CompareAndSwap(&d.Version, oldVersion, oldVersion+1) {
fmt.Println("数据更新成功")
} else {
fmt.Println("数据更新失败,版本号不匹配")
}
} else {
fmt.Println("数据已被其他节点修改,更新失败")
}
}
```
### 3.3 性能优化和资源利用
乐观锁相比悲观锁在并发场景下更容易实现性能优化和资源利用。在高并发情况下,乐观锁由于不依赖显式的锁机制,可以更好地发挥多核处理器的计算能力,有效减少了线程的竞争和阻塞,提高了系统的吞吐量和性能表现。
以上是乐观锁的适用场景,下一节将深入探讨悲观锁的实现方式和适用场景。
# 4. 悲观锁的实现方式
悲观锁是一种悲观地认为数据会发生并发修改的锁机制,因此在访问数据之前先获取锁,确保数据不会被其他线程修改。下面我们将介绍悲观锁的实现方式和相关细节。
#### 4.1 锁机制的实现
悲观锁的实现通常会利用传统的锁机制,例如使用关键字 `synchronized`、`ReentrantLock` 等来对共享数据进行保护。当一个线程获取了锁之后,其他线程将无法访问该数据,直到持有锁的线程释放锁。
以下是 Java 中使用 `synchronized` 实现悲观锁的示例:
```java
public class PessimisticLockExample {
private final Object lock = new Object();
private int count = 0;
public void increment() {
synchronized (lock) {
count++;
}
}
}
```
#### 4.2 数据库级别的锁
在关系型数据库中,悲观锁通常通过数据库提供的锁机制来实现。例如,可以通过在 SQL 查询语句中添加 `FOR UPDATE` 等锁定语句来获取悲观锁,防止其他事务对数据进行修改。
以下是 MySQL 中使用 `SELECT ... FOR UPDATE` 实现悲观锁的示例:
```sql
START TRANSACTION;
SELECT * FROM your_table WHERE id = 1 FOR UPDATE;
-- 进行数据操作
COMMIT;
```
#### 4.3 悲观锁的原理和实现细节
悲观锁的原理是在访问数据之前先获取锁,以防止数据被其他线程修改。其实现细节主要包括锁机制的选择、锁粒度的确定以及死锁的预防和处理等方面。
悲观锁通过锁机制来保证数据的独占性,但在高并发情况下会影响系统的性能,因此需要合理选择锁粒度,并注意死锁等并发问题的处理。
以上是悲观锁的实现方式和相关细节,下一节将介绍悲观锁的适用场景。
# 5. 悲观锁的适用场景
悲观锁适用于以下场景:
#### 5.1 高并发写入的场景
在高并发的写入场景中,多个线程或进程同时需要对同一份数据进行修改操作,为了保证数据的一致性和避免资源竞争,悲观锁可以有效地控制对数据的访问,确保只有一个线程可以对数据进行修改,从而避免数据异常和脏读的问题。
#### 5.2 事务控制和数据一致性要求高的场景
在需要强制事务控制和保障数据一致性的应用场景下,悲观锁可以提供对数据的排他性访问,避免数据修改过程中出现异常情况,确保数据的完整性和一致性。
#### 5.3 性能瓶颈和资源竞争的情况下的应用
在面临性能瓶颈和资源竞争的情况下,悲观锁可以有效地控制对共享资源的访问,避免多个线程同时修改数据导致的性能下降和资源浪费,保障系统的稳定性和可靠性。
悲观锁通过对数据或资源进行加锁,限制了其他线程对资源的访问能力,从而保证了一定的安全性和稳定性。然而,悲观锁在性能上存在一定的开销,需要谨慎选择使用。
# 6. 对比与总结
在实际的应用中,乐观锁与悲观锁都有各自的优势和适用场景。下面对它们进行对比分析:
#### 6.1 乐观锁与悲观锁的对比分析
- 乐观锁适用于并发读多写少的场景,通过版本号比对或CAS算法实现,性能较好,适合用于资源竞争不激烈的情况;
- 悲观锁适用于高并发写入的场景,通过锁机制或数据库级别的锁实现,能够保证数据的一致性,但性能稍逊于乐观锁,适合对数据安全性要求较高的场景。
#### 6.2 在实际应用中如何选择合适的锁机制
- 针对不同的业务场景,可以根据并发读写比例和数据安全性要求来选择乐观锁或悲观锁;
- 对于读多写少的情况,可以优先考虑采用乐观锁来提升性能;
- 对于需要保证数据一致性和避免并发更新的情况,可以选择悲观锁来确保数据的正确性。
#### 6.3 如何避免锁机制的误用和陷阸
- 在使用乐观锁时,需要注意处理版本号冲突的情况,可以通过重试机制或异常处理来解决;
- 在使用悲观锁时,需要注意锁粒度的控制,避免大范围锁定导致性能问题;
- 在实际应用中,需要根据具体情况综合考虑锁的选择,避免过度使用锁机制导致性能下降。
通过对乐观锁和悲观锁的对比分析和实际应用指导,可以更好地理解和使用这两种常见的锁机制,提升系统并发处理能力和数据安全性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《深入理解MySQL锁与事务隔离级别》是一篇专栏,旨在帮助读者深入了解MySQL数据库中的锁机制和事务隔离级别。专栏将从比较乐观锁和悲观锁的实现方式和适用场景入手,让读者清晰地理解不同类型锁的特点及适用情况。同时,也将深入探讨死锁及其在MySQL中的检测与解决方法,帮助读者有效应对潜在的死锁问题。此外,专栏还会分享实际MySQL性能调优案例和经验总结,让读者从实际应用中获得更多可操作的指导和建议。通过本专栏,读者将能够全面了解MySQL中的锁机制和事务隔离级别,掌握相关性能调优的实用技巧,提升对MySQL数据库的综合应用能力。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
HALCON基础教程:轻松掌握23.05版本HDevelop操作符(专家级指南)

# 摘要
本文全面介绍HALCON 23.05版本HDevelop环境及其图像处理、分析和识别技术。首先概述HDevelop开发环境的特点,然后深入探讨HALCON在图像处理领域的基础操作,如图像读取、显示、基本操作、形态学处理等。第三章聚焦于图像分析与识别技术,包括边缘和轮廓检测、图像分割与区域分析、特征提取与匹配。在第四章中,本文转向三维视觉处理,介绍三维
【浪潮英信NF5460M4安装完全指南】:新手也能轻松搞定
# 摘要
本文详细介绍了浪潮英信NF5460M4服务器的安装、配置、管理和性能优化过程。首先概述了服务器的基本信息和硬件安装步骤,包括准备工作、物理安装以及初步硬件设置。接着深入讨论了操作系统的选择、安装流程以及基础系统配置和优化。此外,本文还包含了服务器管理与维护的最佳实践,如硬件监控、软件更新与补丁管理以及故障排除支持。最后,通过性能测试与优化建议章节,本文提供了测试工具介绍、性能调优实践和长期维护升级规划,旨在帮助用户最大化服务器性能并确保稳定运行。
# 关键字
服务器安装;操作系统配置;硬件监控;软件更新;性能测试;故障排除
参考资源链接:[浪潮英信NF5460M4服务器全面技术手
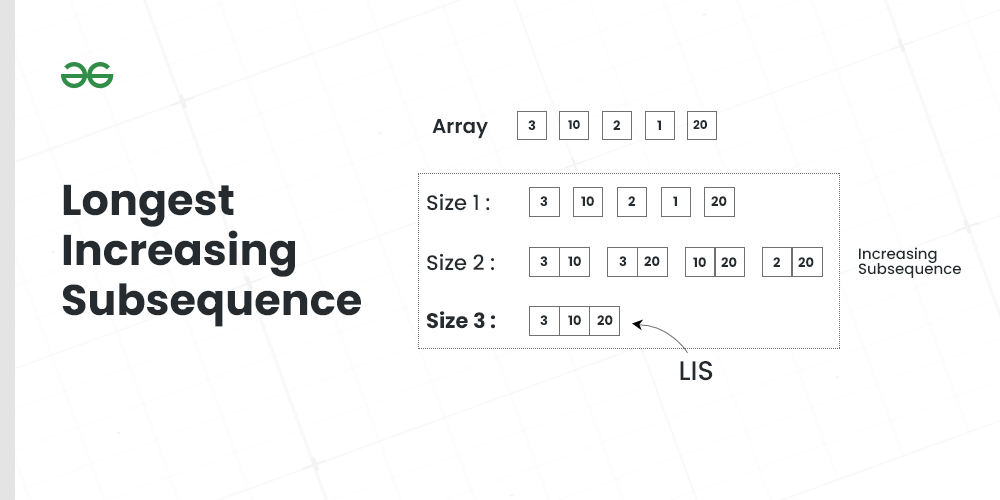
ACM动态规划专题:掌握5大策略与50道实战演练题
# 摘要
动态规划是解决复杂优化问题的一种重要算法思想,涵盖了基础理论、核心策略以及应用拓展的全面分析。本文首先介绍了ACM中动态规划的基础理论,并详细解读了动态规划的核心策略,包括状态定义、状态转移方程、初始条件和边界处理、优化策略以及复杂度分析。接着,通过实战演练的方式,对不同难度等级的动态规划题目进行了深入的分析与解答,涵盖了背包问题、数字三角形、石子合并、最长公共子序列等经典问题
Broyden方法与牛顿法对决:非线性方程组求解的终极选择

# 摘要
本文旨在全面探讨非线性方程组求解的多种方法及其应用。首先介绍了非线性方程组求解的基础知识和牛顿法的理论与实践,接着
【深度剖析】:掌握WindLX:完整用户界面与功能解读,打造个性化工作空间
# 摘要
本文全面介绍了WindLX用户界面的掌握方法、核心与高级功能详解、个性化工作空间的打造技巧以及深入的应用案例研究。通过对界面定制能力、应用管理、个性化设置等核心功能的详细解读,以及窗口管理、集成开发环境支持和多显示器设置等高级功能的探索,文章为用户提供了全面的WindLX使用指导。同时,本文还提供了实际工作
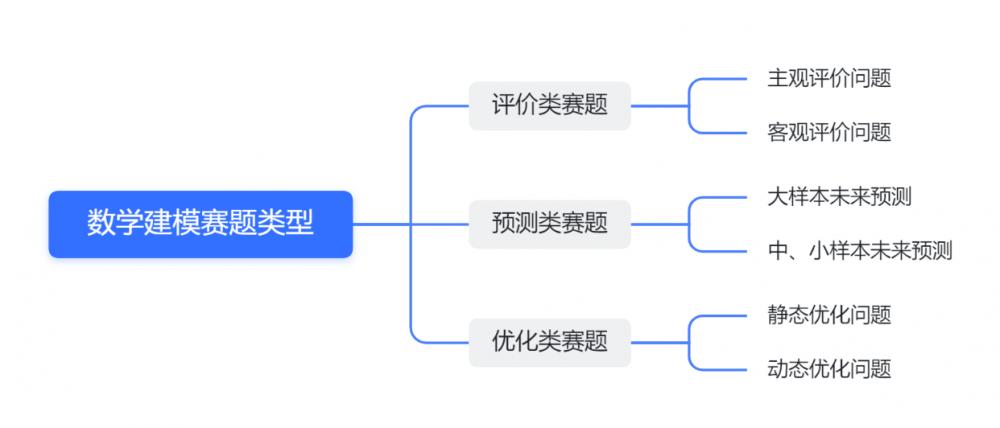
【数学建模竞赛速成攻略】:6个必备技巧助你一臂之力
# 摘要
数学建模竞赛是一项综合性强、应用广泛的学术活动,旨在解决实际问题。本文旨在全面介绍数学建模竞赛的全过程,包括赛前准备、基本理论和方法的学习、实战演练、策略和技巧的掌握以及赛后分析与反思。文章详细阐述了竞赛规则、团队组建、文献收集、模型构建、论文撰写等关键环节,并对历届竞赛题目进行了深入分析。此外,本文还强调了时间管理、团队协作、压力管理等关键策略,以及对个人和团队成长的反思,以及对
【SEED-XDS200仿真器使用手册】:嵌入式开发新手的7日速成指南
# 摘要
SEED-XDS200仿真器作为一款专业的嵌入式开发工具,其概述、理论基础、使用技巧、实践应用以及进阶应用构成了本文的核心内容。文章首先介绍了SEED-XDS200仿真器的硬件组成及其在嵌入式系统开发中的重要性。接着,详细阐述了如何搭建开发环境,掌握基础操作以及探索高级功能。本文还通过具体项目实战,探讨了如何利用仿真器进行入门级应用开发、系统性能调优及故障排除。最后,文章深入分析了仿真器与目标系统的交互,如何扩展第三方工具支持,以及推荐了学习资源,为嵌入式开发者提供了一条持续学习与成长的职业发展路径。整体而言,本文旨在为嵌入式开发者提供一份全面的SEED-XDS200仿真器使用指南。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )