深入理解Kubernetes中Pod的调度和生命周期管理
发布时间: 2024-03-08 15:34:29 阅读量: 35 订阅数: 26 

Kubernetes资源调度及管理详解
# 1. Kubernetes概述
Kubernetes(容器编排引擎)是一个开源的容器编排平台,用于自动化应用程序的部署、扩展和管理。它提供了一个强大的基础架构,使开发人员能够轻松地部署应用程序并有效地管理它们的生命周期。在Kubernetes中,最小的调度单位是Pod。
## 1.1 什么是Kubernetes
Kubernetes是Google开源的容器编排引擎,最初由Google设计并维护,后来捐赠给Cloud Native Computing Foundation(CNCF)。Kubernetes基于容器技术(如Docker)构建,可以实现容器化应用程序的自动化部署、扩展和管理。
## 1.2 Kubernetes中的Pod概念和作用
Pod是Kubernetes中最小的调度单元,可以包含一个或多个紧密相关的容器。Pod内的容器共享网络和存储资源,它们可以协同工作来实现特定的应用程序功能。Pod提供了一个抽象层,将容器组合在一起,实现了应用程序的微服务架构。
## 1.3 Pod与容器的关系
Pod是包含一个或多个容器的逻辑单元,Pod内的多个容器共享网络和存储空间,它们可以共同协作完成应用程序的功能。容器是Pod的基本构成单元,一个Pod通常包含一个主容器和多个辅助容器,它们共同组成了一个逻辑单元。
在下一章节中,我们将深入探讨Pod的调度机制,包括节点选择器、亲和性和反亲和性调度以及Pod的优先级设置。
# 2. Pod的调度机制
在Kubernetes中,Pod的调度是非常重要的一个环节,它决定了应用程序在集群中的运行位置。下面我们来详细了解Pod的调度机制。
### 2.1 节点选择器
Pod的调度通过节点选择器(Node Selector)来指定运行的节点。节点选择器是通过在Pod的配置文件中指定标签(label)的方式来实现的。Kubernetes调度器在安排Pod时会根据Pod的节点选择器和节点的标签来匹配合适的节点进行调度。
```yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: nginx
nodeSelector:
size: Large
```
### 2.2 亲和性和反亲和性调度
除了节点选择器外,Kubernetes还支持亲和性(Affinity)和反亲和性(Anti-Affinity)调度。亲和性调度可以让Pod更倾向于与其他Pod调度在一起,而反亲和性调度则会尽量避免将Pod调度在某些节点上。
```yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: failure-domain.beta.kubernetes.io/zone
```
### 2.3 Pod的优先级
Kubernetes中的Pod可以设置优先级,用于指定Pod的重要程度,调度器会根据优先级来决定Pod的调度顺序。通过设置优先级,可以确保重要的应用程序获得更高的资源分配和调度权利。
```yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
priorityClassName: high-priority
containers:
- name: my-container
image: nginx
```
以上就是Pod的调度机制的基本介绍,通过灵活配置节点选择器、亲和性、反亲和性以及优先级,可以更好地控制Pod在集群中的调度情况。
# 3. Pod的生命周期管理
在Kubernetes中,Pod的生命周期管理是非常重要的,它涉及到Pod的创建、运行、销毁等一系列重要过程。了解Pod的生命周期管理对于设计和管理Kubernetes集群至关重要。
#### 3.1 Pod的创建过程
在Kubernetes中,创建一个Pod的过程是比较复杂的,主要包括以下几个步骤:
- **定义Pod的配置文件**:在YAML或JSON格式的配置文件中定义Pod的容器、网络、存储等信息。
```yaml
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mycontainer
image: nginx
ports:
- containerPort: 80
```
- **通过API服务器创建Pod**:将定义好的配置文件提交到Kubernetes的API服务器,API服务器会解析配置文件并创建Pod对象。
```bash
kubectl create -f pod.yaml
```
- **调度Pod到合适的节点**:Kubernetes的调度器会根据Pod的资源需求和调度策略将Pod调度到合适的节点上执行。
- **容器镜像拉取**:Pod被调度到节点后,各个容器的镜像会被拉取到节点上,以便后续运行。
- **启动容器**:Pod中的各个容器会按照配置顺序被逐个启动,直至所有容器均成功运行起来。
#### 3.2 Pod的生命周期状态
在Kubernetes中,Pod的生命周期主要包括以下几种状态:
- **Pending**:Pod已被创建,但容器尚未创建。
- **Running**:Pod中的容器正在运行。
- **Succeeded**:Pod中的所有容器已经成功运行并且已经退出。
- **Failed**:Pod中的一个或多个容器退出运行或者异常退出。
- **Unknown**:Pod的状态未知。
#### 3.3 Pod的重启策略
Kubernetes允许为Pod定义重启策略,以定义在容器故障时的处理方式。在Pod的配置文件中,可以通过设置`.spec.restartPolicy`字段来指定重启策略,常见的有以下几种策略:
- **Always**:无论容器如何退出,都将自动重启容器。
- **OnFailure**:只有在容器非正常退出时才会重启容器。
- **Never**:容器退出时不会重启容器。
以上就是Pod的生命周期管理相关内容的介绍。对于Kubernetes中Pod的创建和状态管理有了更深入的理解之后,我们可以更好地设计和管理Kubernetes集群中的应用程序。
# 4. Pod的调度策略
在Kubernetes中,Pod的调度是非常重要的一环,它涉及到集群资源的合理分配和任务的高效运行。本章将深入探讨Pod的调度策略,包括请求和限制、调度器的工作原理以及优化调度策略。
#### 4.1 请求和限制
Pod通常会定义对资源(如CPU和内存)的请求和限制。请求表示Pod运行所需资源的最低要求,而限制则指定了Pod能够使用的资源的最大限制。
以下是一个示例Pod的定义,指定了资源的请求和限制:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: resource-pod
spec:
containers:
- name: my-container
image: nginx
resources:
requests:
cpu: "0.5"
memory: "512Mi"
limits:
cpu: "1"
memory: "1Gi"
```
在上述示例中,容器请求了0.5个CPU核心和512Mi内存,并设置了最大可用资源为1个CPU核心和1Gi内存。
#### 4.2 Pod的调度器
Kubernetes中的调度器负责将Pod调度到集群中的合适节点上。调度器根据节点的资源情况、Pod的调度要求(如亲和性、反亲和性)、Pod的优先级等因素来选择最优的节点。
Kubernetes默认的调度器是`kube-scheduler`,它会按照一定的调度策略来决定Pod的最终位置。
#### 4.3 Pod的优化调度策略
除了默认的调度器外,Kubernetes还支持用户自定义调度策略。通过编写调度器插件或使用调度器扩展点,可以实现更加灵活和智能的Pod调度策略,例如基于自定义的调度算法或业务逻辑来实现特定需求的调度行为。
通过合理设置调度策略,可以实现资源的最优利用、工作负载的高效调度,并进一步提升集群的稳定性和性能。
本章介绍了Pod的调度策略,包括资源的请求和限制、调度器的工作原理以及如何实现优化的调度策略。深入理解这些内容将有助于更好地管理和优化Kubernetes集群中Pod的调度过程。
# 5. Pod的监控和健康检查
在Kubernetes中,对Pod的监控和健康检查是非常重要的,可以帮助管理员实时了解Pod的状态并进行必要的处理。下面我们将详细介绍Pod的监控和健康检查相关内容。
#### 5.1 监控Pod的状态
在Kubernetes中,可以通过以下方式来监控Pod的状态:
- 使用命令行工具`kubectl`:可以通过执行`kubectl get pods`命令来查看所有Pod的状态,包括运行状态、重启次数等信息。
```bash
kubectl get pods
```
- 使用Kubernetes Dashboard:Dashboard是Kubernetes的官方Web管理界面,可以通过Dashboard直观地查看Pod的状态和详细信息。
- 使用监控工具Prometheus:Prometheus是一个流行的监控工具,可以通过Prometheus来收集、存储和展示Pod的监控数据,帮助管理员进行监控和预警。
#### 5.2 容器的健康检查
容器的健康检查是保证Pod正常运行的关键,Kubernetes提供了以下三种健康检查方式:
- **Liveness Probe(存活探针)**:用于检测容器是否存活,如果存活探针失败则Kubernetes会尝试重启该容器。
```yaml
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 3
periodSeconds: 5
```
- **Readiness Probe(就绪探针)**:用于检测容器是否已经准备好接受流量,如果就绪探针失败则Pod将被标记为不可用,直到探测成功。
```yaml
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 3
```
- **Startup Probe(启动探针)**:用于检测容器是否已经启动成功,仅在Pod启动时运行一次,用于解决容器长时间无法启动的问题。
```yaml
startupProbe:
httpGet:
path: /startup
port: 8080
failureThreshold: 30
```
#### 5.3 通过指标监控Pod的性能
除了基本的状态监控和健康检查外,还可以通过指标监控来了解Pod的性能状况。Kubernetes提供了`Metrics-server`来收集Pod的性能指标,可以通过以下方式查看:
```bash
kubectl top pods
kubectl top nodes
```
通过这些指标可以及时发现Pod的性能瓶颈,进行调优和优化,确保应用程序的稳定运行。
以上是关于Pod的监控和健康检查的详细介绍,希望能够帮助您更好地管理和监控Kubernetes集群中的Pod。
# 6. Pod的故障处理与调试
在使用Kubernetes中的Pod时,难免会遇到一些故障情况,这时候需要了解如何处理这些问题以及如何进行调试。本章将详细介绍Pod的故障处理与调试的相关内容。
### 6.1 Pod的故障处理机制
当Pod出现故障时,Kubernetes会根据定义的重启策略来进行处理。在Pod的配置文件中,有三种重启策略可以选择:
- **Always**: 总是重启
- **OnFailure**: 只在失败时重启
- **Never**: 从不重启
通过合理设置重启策略,可以在一定程度上帮助我们处理Pod的故障情况。
### 6.2 Pod的日志管理
在调试Pod时,查看Pod的日志信息是非常重要的。我们可以通过kubectl命令来获取Pod的日志:
```bash
kubectl logs <pod-name>
```
此命令将输出指定Pod的日志信息,可以帮助我们定位问题所在。
### 6.3 Pod的调试技巧与工具使用
除了查看日志外,还可以通过一些其他工具和技巧来进行Pod的调试,比如使用`kubectl exec`命令进入Pod内部进行实时调试,使用`port-forward`命令将Pod内部服务暴露到外部进行测试等。
另外,Kubernetes还提供了一些调试工具,比如**Kubernetes Dashboard**、**Kube-Prometheus**等,可以帮助我们更方便地进行调试和故障处理工作。
通过合理使用这些工具和技巧,能够更快速、高效地解决Pod的故障情况,确保应用的稳定性和可靠性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【PX4飞行控制深度解析】:ECL EKF2算法全攻略及故障诊断
# 摘要
本文对PX4飞行控制系统中的ECL EKF2算法进行了全面的探讨。首先,介绍了EKF2算法的基本原理和数学模型,包括核心滤波器的架构和工作流程。接着,讨论了EKF2在传感器融合技术中的应用,以及在飞行不同阶段对算法配置与调试的重要性。文章还分析了EKF2算法在实际应用中可能遇到的故障诊断问题,并提供了相应的优化策略和性能提升方法。最后,探讨了EKF2算法与人工智能结合的前景、在新平台上的适应性优化,以及社区和开
【电子元件检验工具:精准度与可靠性的保证】:行业专家亲授实用技巧
# 摘要
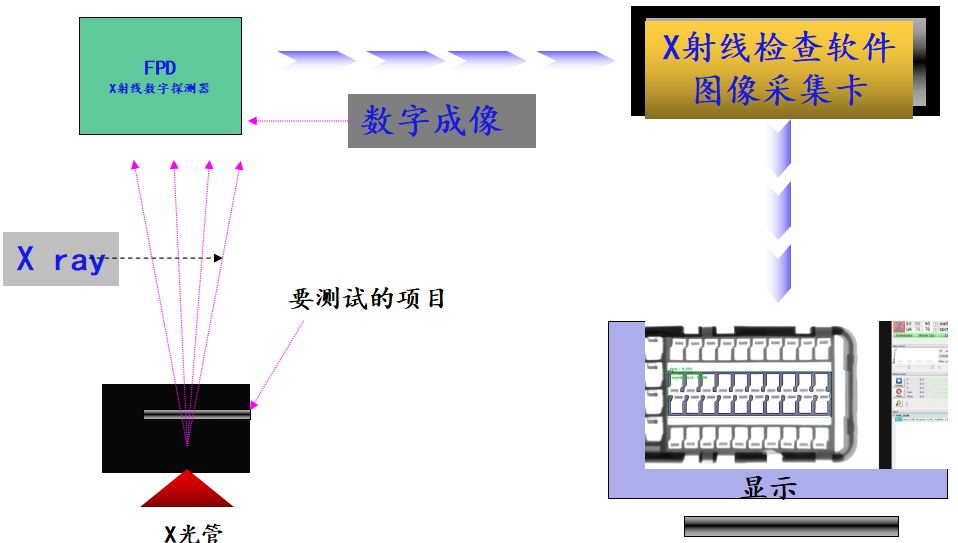
电子元件的检验在现代电子制造过程中扮演着至关重要的角色,确保了产品质量与性能的可靠性。本文系统地探讨了电子元件检验工具的重要性、基础理论、实践应用、精准度提升以及维护管理,并展望了未来技术的发展趋势。文章详细分析了电子元件检验的基本原则、参数性能指标、检验流程与标准,并提供了手动与自动化检测工具的实践操作指导。同时,重点阐述了校准、精确度提
Next.js状态管理:Redux到React Query的升级之路

# 摘要
本文全面探讨了Next.js应用中状态管理的不同方法,重点比较了Redux和React Query这两种技术的实践应用、迁移策略以及对项目性能的影响。通过详细分析Next.js状态管理的理论基础、实践案例,以及从Redux向React Query迁移的过程,本文为开发者提供了一套详细的升级和优化指南。同时,文章还预测了状态管理技术的未来趋势,并提出了最
【802.3BS-2017物理层详解】:如何应对高速以太网的新要求

# 摘要
随着互联网技术的快速发展,高速以太网成为现代网络通信的重要基础。本文对IEEE 802.3BS-2017标准进行了全面的概述,探讨了高速以太网物理层的理论基础、技术要求、硬件实现以及测试与验证。通过对物理层关键技术的解析,包括信号编码技术、传输介质、通道模型等,本文进一步分析了新标准下高速以太网的速率和距离要求,信号完整性与链路稳定性,并讨论了功耗和环境适应性问题。文章还介绍了802.3
【CD4046锁相环实战指南】:90度移相电路构建的最佳实践(快速入门)

# 摘要
本文对CD4046锁相环的基础原理、关键参数设计、仿真分析、实物搭建调试以及90度移相电路的应用实例进行了系统研究。首先介绍了锁相环的基本原理,随后详细探讨了影响其性能的关键参数和设计要点,包括相位噪声、锁定范围及VCO特性。此外,文章还涉及了如何利用仿真软件进行锁相环和90度移相电路的测试与分析。第四章阐述了CD
数据表分析入门:以YC1026为例,学习实用的分析方法

# 摘要
随着数据的日益增长,数据分析变得至关重要。本文首先强调数据表分析的重要性及其广泛应用,然后介绍了数据表的基础知识和YC1026数据集的特性。接下来,文章深入探讨数据清洗与预处理的技巧,包括处理缺失值和异常值,以及数据标准化和归一化的方法。第四章讨论了数据探索性分析方法,如描述性统计分析、数据分布可视化和相关性分析。第五章介绍了高级数据表分析技术,包括高级SQL查询
Linux进程管理精讲:实战解读100道笔试题,提升作业控制能力
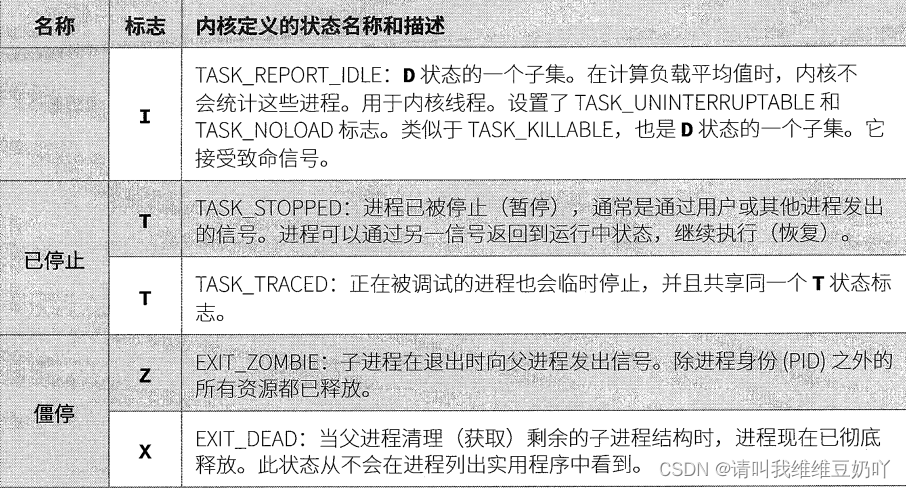
# 摘要
Linux进程管理是操作系统核心功能之一,对于系统性能和稳定性至关重要。本文全面概述了Linux进程管理的基本概念、生命周期、状态管理、优先级调整、调度策略、进程通信与同步机制以及资源监控与管理。通过深入探讨进程创建、终止、控制和优先级分配,本文揭示了进程管理在Linux系统中的核心作用。同时,文章也强调了系统资源监控和限制的工具与技巧,以及进程间通信与同步的实现,为系统管理员和开
STM32F767IGT6外设扩展指南:硬件技巧助你增添新功能
# 摘要
本文全面介绍了STM32F767IGT6微控制器的硬件特点、外设扩展基础、电路设计技巧、软件驱动编程以及高级应用与性
【精密定位解决方案】:日鼎伺服驱动器DHE应用案例与技术要点

# 摘要
本文详细介绍了精密定位技术的概览,并深入探讨了日鼎伺服驱动器DHE的基本概念、技术参数、应用案例以及技术要点。首先,对精密定位技术进行了综述,随后详细解析了日鼎伺服驱动器DHE的工作原理、技术参数以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )