深入理解Lucene的索引结构与搜索过程
发布时间: 2024-01-13 03:39:37 阅读量: 45 订阅数: 21 

深入 Lucene 索引机制
# 1. 简介
### 1.1 什么是Lucene
Lucene是一款开源的全文检索引擎库,由Apache Software Foundation(ASF)开发和维护。Lucene提供了一个简单而强大的API,可以使开发人员很容易地在应用程序中集成全文搜索的功能。
### 1.2 Lucene的重要特性
Lucene具有以下重要特性:
- **高性能**:Lucene使用倒排索引等高效的数据结构和算法,以实现快速的搜索和索引。
- **全文搜索**:Lucene支持在文档的所有文本字段上进行全文搜索,并返回相关的文档。它还支持词项的检索和高亮显示。
- **多种查询类型**:Lucene支持各种查询类型,包括布尔查询、范围查询、模糊查询、前缀查询等。
- **多种分析器**:Lucene提供了多种分析器,用于对文本进行分词处理,以便更好地匹配搜索请求。
- **可扩展性**:Lucene允许用户自定义查询解析器、分析器和评分算法,以满足各种特定需求。
- **跨平台**:Lucene是基于Java开发的,可以在各种操作系统上运行。此外,还有其他语言的实现版本,如PyLucene(Python)、Lucy(C)、Sphinx(C++)等。
在接下来的章节中,我们将更详细地了解Lucene的索引结构、索引过程、搜索过程、性能优化以及实践应用等方面的内容。
# 2. 索引结构
在Lucene中,索引是用于快速查找和检索文档的数据结构。索引结构包括倒排索引、分词器、字典以及存储结构等。
### 2.1 倒排索引
倒排索引(Inverted Index)是Lucene中最重要的数据结构之一。它通过将每个文档中的词条与其出现的位置信息建立映射关系,从而实现了快速的词条检索。
倒排索引的建立过程分为两个步骤:
1. 分词:将文档划分为一系列的词条,称为术语(Term)。分词的目的是将文档中的内容按照一定的规则进行切割,形成可以进行索引的最小单元。
例如,在一篇文章中包含以下句子:"Lucene is a powerful Java-based search library",经过分词处理后,可以得到以下词条:["Lucene", "is", "a", "powerful", "Java-based", "search", "library"]。
2. 建立映射关系:将每个词条与其所在的文档及位置信息建立映射关系。这样,在索引过程中,可以根据词条快速找到包含该词条的文档。
例如,针对上述的词条,可以建立以下倒排索引:
```
Term Document ID Positions
---------------------------------------
"Lucene" Doc1 1
"is" Doc1 2
"a" Doc1 3
"powerful" Doc1 4
"Java-based" Doc1 5
"search" Doc1 6
"library" Doc1 7
```
倒排索引的使用使得在搜索过程中,可以快速地根据查询词条找到匹配的文档,并且支持高效的词频统计、页码定位等功能。
### 2.2 分词器
分词器(Analyzer)是Lucene中用于将文本进行词条切分的组件。Lucene提供了多种分词器,默认情况下会使用标准分词器(StandardAnalyzer)进行分词。
分词器在索引和搜索过程中,扮演着非常重要的角色。它接收输入的文本,并将其切分为一系列的词条,这些词条将作为索引的最小单元。分词器还可以进行其他文本预处理工作,例如:去除停用词、词干提取和同义词处理等。
分词器在初始化过程中,还可以指定其他的配置参数,例如:字符过滤器、分词过滤器以及词典等。这些参数可以根据实际需求进行调整,以满足特定的分词需求。
### 2.3 字典
字典(Dictionary)是Lucene索引中用于存储词条的数据结构。它维护了一系列的词条和对应的词频信息。
字典的目的是为了提供高效的词条查询和词频统计功能。在索引构建过程中,倒排索引会使用字典来存储词条信息,以便在检索过程中快速定位匹配的文档。字典还可以用于计算词条的逆文档频率(IDF)等信息,以便在评分过程中进行权重计算。
Lucene使用的字典组件包括有序词典(FST),Hash字典以及前缀字典等。这些字典组件可以根据实际需求进行选择和配置,以提供更高效的索引存储和检索能力。
### 2.4 存储结构
索引的存储结构是指Lucene在存储索引数据时所采用的结构和算法。存储结构的设计直接影响到Lucene在搜索和存储过程中的性能表现。
Lucene的索引存储结构采用了多层次的倒排索引结构,以提高索引的存储和检索效率。其中,第一层为顶层索引(Segment),它负责管理多个独立的索引片段(Index Block),每个索引片段包含一组有序的文档词条。
索引存储结构不仅对整体性能有着重要影响,还涉及到分区和分片等高级技术。通过合理的存储结构设计,可以提高索引的并发性、查询性能和数据可靠性。
# 3. 索引过程
在使用Lucene进行搜索之前,首先需要构建索引。索引是将文档中的内容进行解析和存储的过程。索引的构建是Lucene的核心功能之一,它能够高效地构建搜索所需的索引结构,以支持快速的搜索操作。
#### 3.1 索引构建流程
索引构建过程包括以下几个主要步骤:
1. 创建一个`IndexWriter`对象,用于将文档添加到索引中。
2. 使用合适的分析器对文档进行处理,将其拆分成多个字段,并进行分词。
3. 创建一个`Document`对象,用于表示一个文档。
4. 为每个字段创建一个`Field`对象,并将字段名、字段值等信息添加到`Field`对象中。
5. 将`Field`对象添加到`Document`对象中。
6. 使用`IndexWriter`将`Document`对象写入索引。
下面是一个简单的示例代码,演示了如何使用Lucene构建索引:
```java
// 创建一个IndexWriter对象
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, new StandardAnalyzer());
IndexWriter indexWriter = new IndexWriter(directory, config);
// 创建一个Document对象
Document document = new Document();
// 创建并添加Field对象
Field titleField = new TextField("title", "Apache Lucene Tutorial", Field.Store.YES);
document.add(titleField);
Field contentField = new TextField("content", "Lucene is a powerful search engine library.", Field.Store.YES);
document.add(contentField);
// 将Document对象写入索引
indexWriter.addDocument(document);
// 关闭IndexWriter
indexWriter.close();
```
在上述代码中,我们首先创建了一个`IndexWriter`对象,并指定了使用的分析器。然后,创建一个`Document`对象,添加了两个字段:`title`和`content`。最后,将`Document`对象添加到索引中。
#### 3.2 分析器的使用
在构建索引时,分析器起着重要的作用。分析器负责对文本进行分词和处理,将文本拆分成多个词语,并进行规范化处理。Lucene提供了多种分析器,可以根据需求选择合适的分析器。
下面是一个示例代码,演示了如何使用StandardAnalyzer分析器对文本进行分词和处理:
```java
StandardAnalyzer analyzer = new StandardAnalyzer();
TokenStream tokenStream = analyzer.tokenStream("content", new StringReader("Lucene is a powerful search engine library."));
// 逐个获取分词结果
CharTermAttribute termAttribute = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while (tokenStream.incrementToken()) {
System.out.println(termAttribute.toString());
}
tokenStream.close();
```
在上述代码中,我们创建了一个`StandardAnalyzer`对象,并使用该分析器获取了一个`TokenStream`对象。然后,通过循环逐个获取分词结果,并输出到控制台。
#### 3.3 文档处理和字段映射
在构建索引时,需要将文档中的内容转换成字段,并进行存储。Lucene的`Document`对象用于表示一个文档,而`Field`对象则用于表示一个字段。
`Field`对象有多种类型,常用的类型包括:
- TextField:存储文本类型的字段,适用于全文搜索。
- StringField:存储字符串类型的字段,适用于精确匹配或排序。
- IntField/LongField:存储整数类型的字段,适用于范围搜索或排序。
可以根据实际需求选择合适的字段类型,并将字段添加到`Document`对象中。
下面是一个示例代码,演示了如何使用`Document`和`Field`对象进行文档处理和字段映射:
```java
Document document = new Document();
Field titleField = new TextField("title", "Apache Lucene Tutorial", Field.Store.YES);
document.add(titleField);
Field contentField = new TextField("content", "Lucene is a powerful search engine library.", Field.Store.YES);
document.add(contentField);
```
在上述代码中,我们创建了一个`Document`对象,并添加了两个字段:`title`和`content`。其中,`title`字段使用了`TextField`类型,而`content`字段也使用了`TextField`类型。
通过使用适当的字段类型,可以提高搜索的准确性和效率。
以上就是Lucene的索引过程的简要介绍。在构建索引时,需要选择适合的分析器和字段类型,并正确映射文档中的内容。构建完成后,就可以进行搜索操作了。
# 4. 搜索过程
在这一章节中,我们将深入探讨Lucene中的搜索过程。我们将介绍查询解析器的使用、布尔查询、近似搜索、排序与评分等内容。让我们一起来了解Lucene搜索的核心原理和使用方法。
#### 4.1 查询解析器的使用
在Lucene中,查询解析器负责将用户输入的查询字符串解析成查询对象。Lucene提供了丰富的查询语法和查询解析器,用户可以根据自己的需求来构建各种复杂的查询。下面是一个简单的示例,演示了如何使用Lucene的标准查询解析器进行查询:
```java
String querystr = "java programming";
Query query = new QueryParser("content", analyzer).parse(querystr);
```
上面的代码中,我们使用了标准查询解析器来解析查询字符串,然后将其解析成查询对象。这个查询对象可以用于搜索操作,以找到与查询条件匹配的文档。
#### 4.2 布尔查询
在Lucene中,布尔查询是一种非常常见且强大的查询方式。通过组合多个查询条件,用户可以构建出复杂的查询逻辑,以满足不同的搜索需求。下面是一个示例,演示了如何使用布尔查询:
```java
TermQuery term1 = new TermQuery(new Term("content", "java"));
TermQuery term2 = new TermQuery(new Term("content", "programming"));
BooleanQuery.Builder builder = new BooleanQuery.Builder();
builder.add(term1, BooleanClause.Occur.MUST);
builder.add(term2, BooleanClause.Occur.MUST);
BooleanQuery query = builder.build();
```
在上面的示例中,我们使用布尔查询来要求搜索结果中同时包含"java"和"programming"两个词的文档。
#### 4.3 近似搜索
除了精确匹配,Lucene还支持模糊查询和近似搜索。用户可以通过模糊查询来找到与查询条件相似的文档,这在一些场景下非常有用。下面是一个示例,演示了如何使用模糊查询:
```java
FuzzyQuery query = new FuzzyQuery(new Term("content", "programing"), 2);
```
上面的代码中,我们使用了模糊查询来寻找与"programing"相似的词,允许最多两个编辑距离的差异。
#### 4.4 排序与评分
在Lucene搜索过程中,文档的排序和评分是非常重要的环节。Lucene提供了多种排序方式和评分算法,用户可以根据自己的需求进行定制。下面是一个示例,演示了如何进行排序操作:
```java
Sort sort = new Sort(new SortField("timestamp", SortField.Type.LONG, true));
TopDocs results = searcher.search(query, 10, sort);
```
在上面的示例中,我们使用时间戳字段进行倒序排序,并且限制返回结果数量为10个。
在本章节中,我们介绍了Lucene中搜索过程的核心内容,包括查询解析器的使用、布尔查询、近似搜索以及排序与评分。这些内容涵盖了搜索过程中的关键技术和方法,希望能够为你的实际应用提供帮助。
# 5. 性能优化
在使用Lucene构建和搜索索引过程中,性能优化是非常重要的。优化可以提升搜索速度、降低资源消耗,并且提供更好的用户体验。以下是一些常见的性能优化方法:
#### 5.1 硬件优化
硬件优化是提高Lucene性能的第一步。可以考虑以下几个方面:
- **存储设备**:使用快速的存储设备,如固态硬盘(SSD),可以加快索引和搜索操作的速度。
- **内存**:增加系统内存可以提高缓存效果,减少磁盘读取的次数,从而加速搜索操作。
- **CPU**:使用高性能的多核处理器可以提高索引和搜索的并发能力。
#### 5.2 分区与分片
对于大规模的索引,可以将索引分为多个分区来进行并行处理。分区可以根据索引的字段、文档类型或者其他规则进行划分。每个分区可以使用独立的线程来进行索引构建和搜索操作,从而提高系统的并发性能。
在分区的基础上,还可以使用分片来进一步提高性能。分片是将一个分区进行细分,每个分片包含部分索引数据。通过将索引数据分散到多个节点上进行处理,可以进一步提高系统的吞吐量和响应速度。
#### 5.3 查询优化
针对查询过程进行优化可以提高搜索性能。以下是一些常用的查询优化方法:
- **缓存查询结果**:对于经常被执行的查询,可以将查询结果缓存起来,避免重复的计算和搜索操作。
- **查询重写**:通过优化查询语句,可以减少不必要的计算和搜索范围,从而提高搜索效率。
- **索引优化**:根据实际需求,对索引字段进行合理选择和配置,可以提高搜索性能。例如,对于经常进行范围查询的字段,可以使用数值类型的字段进行索引。
#### 5.4 缓存机制
使用缓存可以提高搜索性能,减少磁盘读取的次数,从而加速搜索操作。可以考虑以下几种缓存机制:
- **查询结果缓存**:将查询结果缓存起来,避免重复的计算和搜索操作。可以使用内存缓存或者分布式缓存来进行优化。
- **过滤器缓存**:对于经常使用的过滤器,可以将其缓存起来,减少每次搜索时的计算量。
- **字段缓存**:对于频繁使用的字段,可以将其缓存起来,减少索引的查询次数。
通过合理使用缓存机制,可以显著提高搜索性能和系统的响应速度。
性能优化是Lucene应用过程中不可忽视的重要环节。通过合理的硬件优化、分区与分片、查询优化和缓存机制,可以提高搜索系统的性能和用户体验。
# 6. 实践应用
在本节中,我们将介绍一些实际应用场景,以便读者更好地理解Lucene在实际项目中的应用方式。
#### 6.1 实例:基于Lucene的全文搜索引擎
在这个实例中, 我们将演示如何使用Lucene构建一个简单的全文搜索引擎。首先我们创建一个索引,然后对搜索关键词进行查询。代码如下所示:
```python
# 导入必要的模块
from whoosh import index
from whoosh.fields import Schema, TEXT, KEYWORD, ID, STORED
from whoosh.analysis import SimpleAnalyzer
from whoosh.qparser import QueryParser
import os
# 创建一个Schema,指定文档包含的字段
schema = Schema(title=TEXT(stored=True), path=ID(stored=True), content=TEXT(analyzer=SimpleAnalyzer()))
# 如果目录中没有索引则创建,否则打开索引
if not os.path.exists("index"):
os.mkdir("index")
ix = index.create_in("index", schema)
# 打开一个写入的索引使用的Writer对象
writer = ix.writer()
# 添加文档到索引中
writer.add_document(title=u"First document", path=u"/a", content=u"This is the first document we've added!")
writer.add_document(title=u"Second document", path=u"/b", content=u"The second one is even more interesting!")
writer.commit()
# 构建查询解析器
with ix.searcher() as searcher:
query = QueryParser("content", ix.schema).parse("first")
results = searcher.search(query)
for result in results:
print(result)
```
在这个例子中,我们创建了一个包含三个字段的Schema,然后将两个文档添加到索引中。接着,我们构建一个查询解析器,并且使用该解析器进行关键词查询。
#### 6.2 实例:Lucene在电子商务推荐系统中的应用
在这个实例中,我们将探讨如何在电子商务领域中利用Lucene来构建推荐系统。我们可以利用Lucene构建商品索引,并使用用户行为数据来实现个性化推荐。下面是一个简化的示例代码:
```java
// 创建商品索引
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter writer = new IndexWriter(directory, config);
Document doc1 = new Document();
doc1.add(new TextField("id", "1", Field.Store.YES));
doc1.add(new TextField("name", "iPhone X", Field.Store.YES));
doc1.add(new TextField("category", "Electronics", Field.Store.YES));
writer.addDocument(doc1);
Document doc2 = new Document();
doc2.add(new TextField("id", "2", Field.Store.YES));
doc2.add(new TextField("name", "Samsung Galaxy", Field.Store.YES));
doc2.add(new TextField("category", "Electronics", Field.Store.YES));
writer.addDocument(doc2);
// 用户行为数据
String userId = "123";
String[] viewedItems = {"1", "5", "7"};
String[] purchasedItems = {"2", "3", "6"};
// 利用用户行为数据进行基于内容的推荐
IndexSearcher searcher = new IndexSearcher(DirectoryReader.open(directory));
MoreLikeThis mlt = new MoreLikeThis(searcher.getIndexReader());
mlt.setFieldNames(new String[] {"name", "category"});
Query query = mlt.like(new StringReader(String.join(" ", viewedItems)), "name");
TopDocs similarDocs = searcher.search(query, 10);
```
在这个示例中,我们首先创建了商品索引,然后利用用户的浏览和购买行为数据,利用基于内容的推荐算法来找出和用户浏览过的商品相似的商品。这个例子展示了如何利用Lucene在电子商务推荐系统中进行商品推荐。
#### 6.3 实例:Lucene在日志分析中的应用
在这个实例中,我们将介绍如何利用Lucene进行日志分析。Lucene可以帮助我们构建日志索引,并且利用强大的查询功能来实现日志数据的快速检索与分析。下面是一个简单的示例代码:
```go
// 创建日志索引
index, err := bleve.Open("log_index")
if err != nil {
indexMapping := bleve.NewIndexMapping()
index, err = bleve.New("log_index", indexMapping)
}
// 添加日志数据到索引中
logData := map[string]interface{}{
"timestamp": "2021-01-01T12:00:00",
"level": "INFO",
"message": "User1 logged in",
}
index.Index("1", logData)
// 构建查询
query := bleve.NewQueryStringQuery("message:logged")
searchRequest := bleve.NewSearchRequest(query)
searchResult, _ := index.Search(searchRequest)
```
在这个示例中,我们利用Bleve作为Go语言的Lucene实现,创建了一个简单的日志索引,并且展示了如何利用查询功能进行日志内容的检索与分析。
#### 6.4 实例:Lucene在文本分类中的应用
最后一个示例将演示如何利用Lucene进行文本分类。Lucene提供了丰富的特性来支持文本分类任务,包括强大的查询解析器和评分算法。下面是一个基于Python的文本分类示例代码:
```python
from whoosh import index
from whoosh.fields import Schema, TEXT, ID
from whoosh.analysis import StemmingAnalyzer
from whoosh.qparser import MultifieldParser
# 创建Schema
schema = Schema(title=TEXT(stored=True), content=TEXT(analyzer=StemmingAnalyzer(), stored=True), category=ID(stored=True))
# 创建索引
ix = index.create_in("index_dir", schema)
# 添加训练数据到索引
writer = ix.writer()
writer.add_document(title=u"document1", content=u"This is a document about sports", category=u"sports")
writer.add_document(title=u"document2", content=u"Document related to technology and gadgets", category=u"technology")
writer.add_document(title=u"document3", content=u"Health and fitness related document", category=u"health")
writer.commit()
# 构建查询解析器并进行文本分类预测
with ix.searcher() as searcher:
query = MultifieldParser(["title", "content"], ix.schema).parse("fitness")
results = searcher.search(query)
for result in results:
print(result)
```
在这个例子中,我们首先创建了一个包含标题、内容和类别的Schema,然后将训练数据添加到索引中。接着,我们构建了一个多字段的查询解析器,并使用该解析器进行文本分类预测。
以上是几个典型的实践应用示例,展示了Lucene在不同领域中的应用方式。通过这些示例,读者可以更好地理解Lucene在实际项目中的灵活性和强大性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏以"lucene全文检索框架 solr elasticsearch搜索引擎"为主要主题,通过多篇文章对这些搜索引擎的介绍、使用、原理和应用进行了详细讲解。其中包括了"全文检索引擎介绍及其在信息检索中的应用"、"初识Lucene:高性能全文检索框架"、"深入理解Lucene的索引结构与搜索过程"等文章,深入探讨了Lucene的原理和应用。同时也涵盖了Solr和Elasticsearch的主题,如"Solr入门:强大的企业级搜索平台"、"Elasticsearch初探:分布式搜索引擎的魅力"等。通过比较和使用案例,还介绍了Lucene与Solr、Elasticsearch的对比与选择、在电商推荐系统中的应用等。总之,该专栏系统地介绍了Lucene、Solr和Elasticsearch的基础知识、应用场景和优化技巧,适合对全文检索感兴趣的读者阅读和学习。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
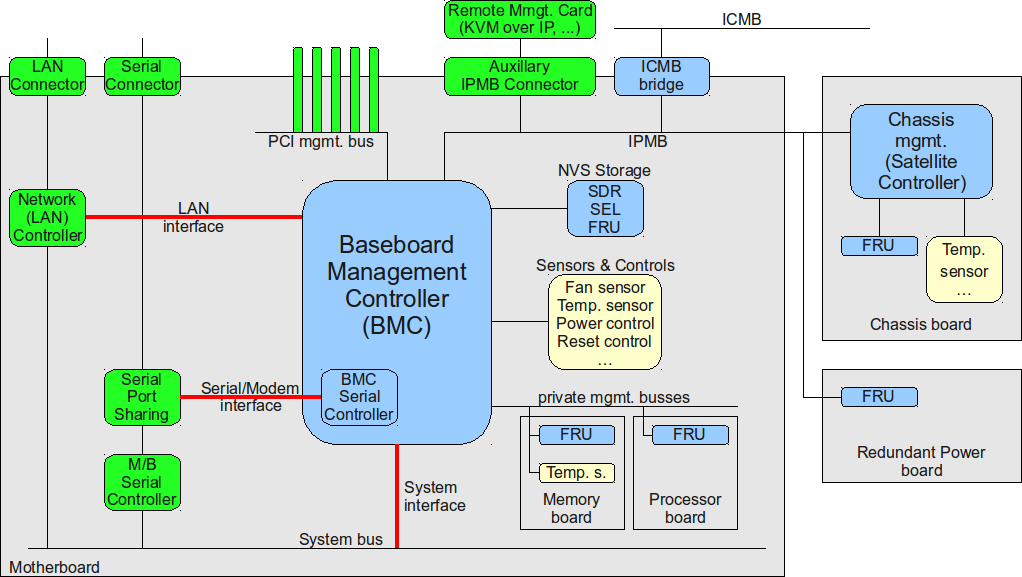
IPMI标准V2.0与物联网:实现智能设备自我诊断的五把钥匙
# 摘要
本文旨在深入探讨IPMI标准V2.0在现代智能设备中的应用及其在物联网环境下的发展。首先概述了IPMI标准V2.0的基本架构和核心理论,重点分析了其安全机制和功能扩展。随后,本文讨论了物联网设备自我诊断的必要性,并展示了IPMI标准V2.0在智能硬件设备和数据中心健康管理中的应用实例。最后,本文提出了实现智能设备IPMI监控系统的设计与开发指南,
【EDID兼容性高级攻略】:跨平台显示一致性的秘诀

# 摘要
电子显示识别数据(EDID)是数字视频接口中用于描述显示设备特性的标准数据格式。本文全面介绍了EDID的基本知识、数据结构以及兼容性问题的诊断与解决方法,重点关注了数据的深度解析、获取和解析技术。同时,本文探讨了跨平台环境下EDID兼容性管理和未来技术的发展趋势,包括增强型EDID标准的发展和自动化配置工具的前景。通过案例研究与专家建议,文章提供了在多显示器设置和企业级显示管理中遇到的ED
PyTorch张量分解技巧:深度学习模型优化的黄金法则

# 摘要
PyTorch张量分解技巧在深度学习领域具有重要意义,本论文首先概述了张量分解的概念及其在深度学习中的作用,包括模型压缩、加速、数据结构理解及特征提取。接着,本文详细介绍了张量分解的基础理论,包括其数学原理和优化目标,随后探讨了在PyTorch中的操作实践,包括张量的创建、基本运算、分解实现以及性能评估。论文进一步深入分析了张量分解在深度学习模型中的应用实例,展示如何通过张量分解技术实现模型
【参数校准艺术】:LS-DYNA材料模型方法与案例深度分析
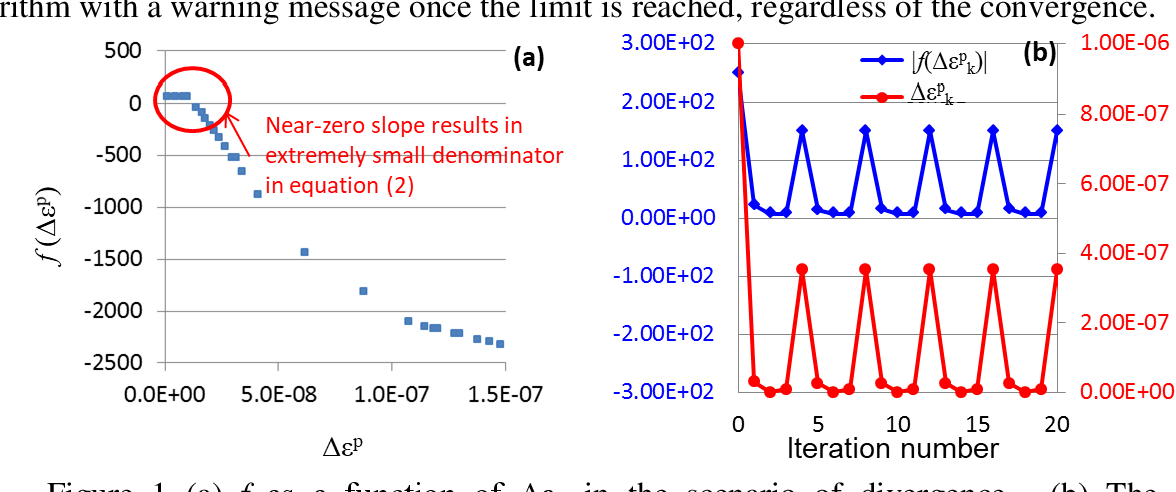
# 摘要
本文全面探讨了LS-DYNA软件在材料模型参数校准方面的基础知识、理论、实践方法及高级技术。首先介绍了材料模型与参数校准的基础知识,然后深入分析了参数校准的理论框架,包括理论与实验数据的关联以及数值方法的应用。文章接着通过实验准备、模拟过程和案例应用详细阐述了参数校准的实践方法。此外,还探
系统升级后的验证:案例分析揭秘MAC地址修改后的变化

# 摘要
本文系统地探讨了MAC地址的基础知识、修改原理、以及其对网络通信和系统安全性的影响。文中详细阐述了软件和硬件修改MAC地址的方法和原理,并讨论了系统升级对MAC地址可能产生的变化,包括自动重置和保持不变的情况。通过案例分析,本文进一步展示了修改MAC地址后进行系统升级的正反两面例子。最后,文章总结了当前研究,并对今后关于MAC地址的研究方向进行了展望。
# 关键字
华为交换机安全加固:5步设置Telnet访问权限
# 摘要
随着网络技术的发展,华为交换机在企业网络中的应用日益广泛,同时面临的安全威胁也愈加复杂。本文首先介绍了华为交换机的基础知识及其面临的安全威胁,然后深入探讨了Telnet协议在交换机中的应用以及交换机安全设置的基础知识,包括用户认证机制和网络接口安全。接下来,文章详细说明了如何通过访问控制列表(ACL)和用户访问控制配置来实现Telnet访问权限控制,以增强交换机的安全性。最后,通过具体案例分析,本文评估了安
【软硬件集成测试策略】:4步骤,提前发现并解决问题
# 摘要
软硬件集成测试是确保产品质量和稳定性的重要环节,它面临诸多挑战,如不同类型和方法的选择、测试环境的搭建,以及在实践操作中对测试计划、用例设计、缺陷管理的精确执行。随着技术的进步,集成测试正朝着性能、兼容性和安全性测试的方向发展,并且不断优化测试流程和数据管理。未来趋势显示,自动化、人工智能和容器化等新兴技术的应用,将进一步提升测试效率和质量。本文系统地分析了集成测试的必要性、理论基础、实践操作
CM530变频器性能提升攻略:系统优化的5个关键技巧

# 摘要
本文综合介绍了CM530变频器在硬件与软件层面的优化技巧,并对其性能进行了评估。首先概述了CM530的基本功能与性能指标,然后深入探讨了硬件升级方案,包括关键硬件组件选择及成本效益分析,并提出了电路优化和散热管理的策略。在软件配置方面,文章讨论了软件更新流程、固件升级准备、参数调整及性能优化方法。系统维护与故障诊断部分提供了定期维护的策略和故障排除技巧。最后,通过实战案例分析,展示了CM530在特定应用中的优化效果,并对未来技术发展和创新
CMOS VLSI设计全攻略:从晶体管到集成电路的20年技术精华
# 摘要
本文对CMOS VLSI设计进行了全面概述,从晶体管级设计基础开始,详细探讨了晶体管的工作原理、电路模型以及逻辑门设计。随后,深入分析了集成电路的布局原则、互连设计及其对信号完整性的影响。文章进一步介绍了高级CMOS电路技术,包括亚阈值电路设计、动态电路时序控制以及低功耗设计技术。最后,通过VLSI设计实践和案例分析,阐述了设计流程、
三菱PLC浮点数运算秘籍:精通技巧全解

# 摘要
本文系统地介绍了三菱PLC中浮点数运算的基础知识、理论知识、实践技巧、高级应用以及未来展望。首先,文章阐述了浮点数运算的基础和理论知识,包括表示方法、运算原理及特殊情况的处理。接着,深入探讨了三菱PLC浮点数指令集、程序设计实例以及调试与优化方法。在高级应用部分,文章分析了浮点数与变址寄存器的结合、高级算法应用和工程案例。最后,展望了三菱PLC浮点数运算技术的发展趋势,以及与物联网的结合和优化
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )