




【R语言数据清洗与预处理】:使用isnev包的10大实战技巧

1. R语言与数据清洗概述
在当今的数据驱动时代,数据清洗作为数据预处理的关键环节,对于后续的数据分析、挖掘和建模具有重要的影响。R语言,作为一种功能强大的开源统计编程语言,提供了丰富的数据清洗工具和方法,是数据科学家和分析师不可或缺的工具之一。
R语言在数据清洗领域的优势首先体现在其灵活的数据结构和强大的数据处理能力。从读取和导入各种格式的数据集,到识别、处理缺失值和异常值,R语言都能够提供简洁的代码和直观的操作。此外,R语言还支持复杂的数据转换与重构技巧,包括但不限于数据分组、汇总统计、数据标准化和归一化,以及数据融合和重塑等。
本章将带领读者走进R语言数据清洗的世界,概述数据清洗的重要性和R语言在这一领域的核心功能。通过对R语言数据清洗的初步了解,为后续章节中实战技巧和案例实践打下基础。接下来,我们将深入探讨如何运用R语言进行高效的数据清洗。
2. R语言数据清洗实战技巧
2.1 数据导入与格式转换
2.1.1 使用isnerv包导入数据
在R语言中,数据导入是数据清洗流程的第一步,决定着后续操作的准确性和效率。haven包作为R中常用的数据导入工具,支持SPSS、Stata和SAS等多种统计软件的数据格式。
安装并加载haven包:
- install.packages("haven")
- library(haven)
使用haven包导入SPSS文件示例:
- # 假设我们有一个名为example.sav的SPSS文件
- spss_data <- read_spss("example.sav")
导入后,可以对数据结构进行检查:
- # 查看数据结构
- str(spss_data)
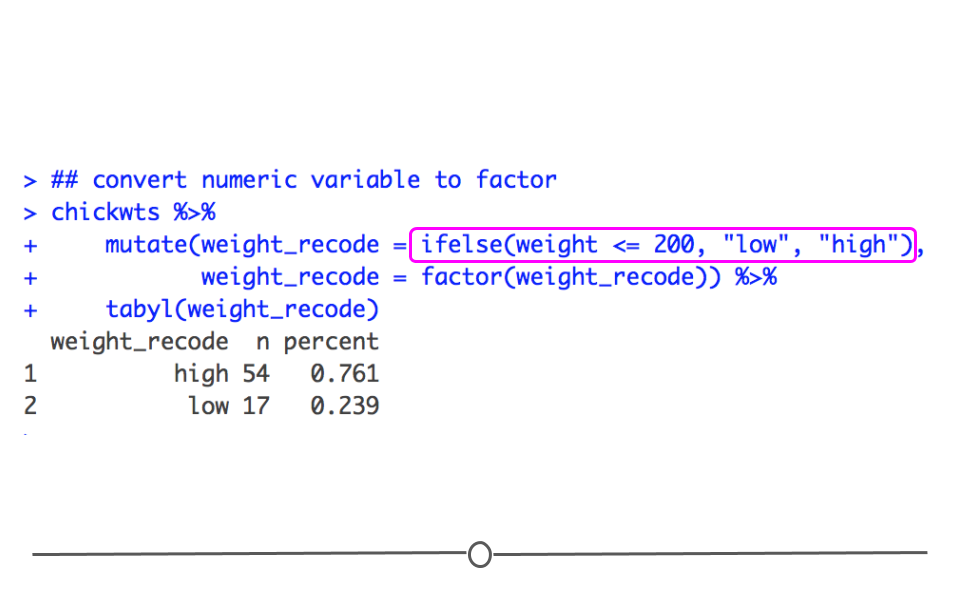
2.1.2 数据格式的转换与统一
数据在导入之后,常常需要进行格式转换以满足后续分析的需要。dplyr包提供了方便的函数来进行数据框(data frame)的转换。
安装并加载dplyr包:
- install.packages("dplyr")
- library(dplyr)
数据格式转换的一个常见需求是将宽格式(宽表)转换为长格式(长表),以适应特定的数据分析场景:
- # 假设我们有一个宽格式数据框wide_data
- long_data <- wide_data %>%
- pivot_longer(
- cols = -id, # 除了id列外,其他列都转换
- names_to = "variable",
- values_to = "value"
- )
这样,宽格式数据通过转换,变得更加紧凑,便于进一步分析。
2.2 缺失数据的处理
2.2.1 识别缺失值
数据清洗中一个常见任务是处理缺失值。使用naniar包可以帮助识别和处理缺失数据。
安装并加载naniar包:
- install.packages("naniar")
- library(naniar)
使用naniar包中的miss_var_summary函数来快速得到数据集中每个变量的缺失值统计信息:
- # 假设df是一个数据框
- miss_var_summary(df)
2.2.2 缺失值的填充与删除策略
处理缺失数据有两种主要方法:删除含有缺失值的行,或者用某种统计量填充缺失值。tidyr包提供了方便的函数来实现这些操作。
安装并加载tidyr包:
- install.packages("tidyr")
- library(tidyr)
删除含有缺失值的行:
- # 删除含有缺失值的行
- df_clean <- df %>% drop_na()
填充缺失值:
- # 用列的均值填充缺失值
- df_filled <- df %>% mutate(across(everything(), ~ifelse(is.na(.), mean(., na.rm = TRUE), .)))
2.3 异常值的检测与处理
2.3.1 异常值的定义与识别
异常值是那些与数据集中其他观测值显著不同的数据点。使用箱型图可以非常直观地识别出异常值。
安装并加载ggplot2包:
- install.packages("ggplot2")
- library(ggplot2)
创建一个箱型图来识别异常值:
- # 假设x是一个数值向量
- ggplot(data = NULL, aes(y = x)) +
- geom_boxplot() +
- labs(title = "Boxplot for Outlier Detection")
2.3.2 异常值的处理方法
处理异常值有多种方法,其中两种常见的方法是删除异常值和替换异常值。
删除异常值:
- # 删除异常值
- x_filtered <- x[x > quantile(x, 0.25) - 1.5*IQR(x) & x < quantile(x, 0.75) + 1.5*IQR(x)]
替换异常值:
- # 替换异常值
- x_replaced <- ifelse(abs(x - mean(x)) > 2*sd(x), median(x), x)
以上是本章节关于R语言数据清洗实战技巧的详细解释。接下来的章节将继续深入探讨数据转换与重构技巧以及数

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【FLUKE_8845A_8846A深度剖析】:揭秘5大高级功能与高效应用策略
【地理信息系统实用指南】:10个技巧助你精通高德地图API
时间序列分析:用R语言进行精准预测与建模的策略
无线网络设计与优化:顶尖专家的理论与实践
快速排序性能提升:在多核CPU环境下实现并行化的【秘诀】
【虚拟网络环境的性能优化】:eNSP结合VirtualBox的最佳实践
【权威指南】:掌握AUTOSAR BSW模块,专家级文档解读
MSP430与HCSR04超声波模块的距离计算优化方法
EPLAN高级功能解锁:【条件化内容】:提升设计质量的创新方法


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )









