R语言数据分析入门到精通:20个技巧提升你的分析能力
发布时间: 2024-11-05 15:02:02 阅读量: 73 订阅数: 37 

R语言学习资料打包下载(中文版)

# 1. R语言数据分析基础
R语言作为一款开源统计和图形软件,其在数据分析领域具有广泛的应用。本章我们将介绍R语言的基本概念、功能和如何在数据分析中运用它。
## R语言概述
R语言是一种功能强大的开源语言,它主要用于统计分析、数据挖掘、图形表示和报告制作。R语言拥有庞大的社区支持和丰富的包库,使得它几乎可以处理各种类型的数据分析任务。
## R语言的应用场景
在商业、金融、生物医学、社会科学研究等多个领域,R语言都扮演着重要角色。它能够进行数据清洗、数据处理、统计分析、机器学习等。
## 如何开始使用R语言
为了开始使用R语言,读者需要下载并安装R语言软件和RStudio IDE(集成开发环境)。通过学习R的基础语法,如变量赋值、数据类型和操作符,逐步深入到向量、矩阵、数据框的使用中。
```r
# 示例:创建一个向量并进行基本操作
my_vector <- c(1, 2, 3, 4, 5) # 创建一个向量
mean(my_vector) # 计算平均值
sum(my_vector) # 计算总和
```
通过上述简单步骤,您可以轻松入门R语言,并为进一步学习数据分析打下基础。随着对R语言功能的深入理解,您将能够更加自信地处理复杂的数据分析任务。
# 2. 数据处理与清洗技巧
数据处理与清洗是数据分析流程中的重要步骤,它直接影响到分析结果的准确性和可信度。一个数据集通常需要经过清洗,才能确保数据的质量,为后续的数据分析工作打下坚实的基础。本章将详细探讨R语言中的数据结构,基本的数据清洗操作,以及一些高级的数据转换技巧。
### 2.1 R语言中的数据结构
#### 2.1.1 向量、矩阵与数组
在R语言中,向量是最基本的数据结构,用于存储一系列同类型的元素。一个向量可以是数值型、字符型或逻辑型。矩阵是二维的向量,而数组可以理解为是多维的矩阵。向量、矩阵和数组在R中的创建和操作都非常直观,下面通过一些代码示例来进行说明:
```r
# 创建向量
numeric_vector <- c(1, 2, 3, 4, 5)
character_vector <- c("a", "b", "c", "d", "e")
# 创建矩阵
matrix_data <- matrix(1:10, nrow = 2, ncol = 5)
matrix_data
# 创建数组
array_data <- array(1:18, dim = c(2, 3, 3))
array_data
```
在处理实际数据时,我们通常需要访问向量的特定部分,或对矩阵和数组执行运算。例如,我们可以提取矩阵的特定列或者对数组的特定维度进行操作。
```r
# 提取矩阵的第二列
second_column <- matrix_data[, 2]
# 计算数组第一维度的总和
sum_first_dim <- apply(array_data, 1, sum)
```
向量、矩阵和数组在R中的使用非常灵活,它们的结构和操作是数据分析的基石。
#### 2.1.2 数据框与列表
数据框(data frame)是R中最常用的数据结构之一,用于存储表格数据,可以包含不同类型的数据列。列表(list)则是R中的一种复合数据结构,可以包含不同类型和结构的元素。列表可以包含向量、数据框、矩阵等,它为复杂数据的组织提供了一种方式。
下面展示如何创建和操作数据框和列表:
```r
# 创建数据框
data_frame <- data.frame(
ID = 1:5,
Name = c("Alice", "Bob", "Charlie", "David", "Eva"),
Score = c(95, 80, 75, 90, 85)
)
# 创建列表
list_data <- list(
vector = c(1, 2, 3),
matrix = matrix_data,
data.frame = data_frame
)
# 访问数据框的第二列
second_column_df <- data_frame$Score
# 访问列表中的矩阵元素
matrix_in_list <- list_data$matrix
```
数据框和列表在数据清洗和转换中的应用十分广泛,它们可以容纳多样化的数据,并提供了多种数据操作的可能性。
### 2.2 数据清洗的基本操作
数据清洗是数据分析的一个关键步骤,它包括处理缺失值、异常值、数据合并与重塑等。我们接下来将详细探讨如何进行基本的数据清洗操作。
#### 2.2.1 缺失值处理
数据集中存在缺失值是常见的问题。在R中处理缺失值通常有几种方法,比如删除含有缺失值的行或列、用均值、中位数、众数等统计值填充缺失值,或者利用模型预测缺失值。下面是使用R语言处理缺失值的代码示例:
```r
# 创建含有缺失值的数据框
data_with_na <- data.frame(
ID = 1:5,
Score = c(95, NA, 75, NA, 85)
)
# 删除含有缺失值的行
data_without_na <- na.omit(data_with_na)
# 用均值填充缺失值
mean_value <- mean(data_with_na$Score, na.rm = TRUE)
data_filled_na <- data.frame(
ID = data_with_na$ID,
Score = ifelse(is.na(data_with_na$Score), mean_value, data_with_na$Score)
)
```
处理缺失值对于确保数据分析的准确性至关重要。
#### 2.2.2 异常值检测与处理
异常值是那些与数据集中的其他数据点显著不同的数据点。异常值可以由多种原因造成,包括测量错误、数据输入错误或真正的异常值。在R中,我们可以通过可视化(如箱线图)、统计测试(如Z得分、IQR方法)来检测异常值。下面是如何用IQR方法来检测和处理异常值的代码示例:
```r
# 创建数据框
data_with_outliers <- data.frame(
ID = 1:100,
Values = rnorm(100, mean = 100, sd = 15)
)
# 添加几个异常值
data_with_outliers$Values[c(2, 50, 90)] <- c(300, -100, 350)
# 使用IQR方法检测异常值
Q1 <- quantile(data_with_outliers$Values, 0.25)
Q3 <- quantile(data_with_outliers$Values, 0.75)
IQR <- Q3 - Q1
lower_bound <- Q1 - 1.5 * IQR
upper_bound <- Q3 + 1.5 * IQR
outliers <- data_with_outliers$Values < lower_bound | data_with_outliers$Values > upper_bound
# 替换或移除异常值
data_cleaned <- data_with_outliers
data_cleaned$Values[outliers] <- NA
data_cleaned <- na.omit(data_cleaned)
```
处理异常值有助于提高模型的稳定性和预测的准确性。
#### 2.2.3 数据的合并与重塑
数据合并是指将多个数据集整合到一起,而数据重塑则是指改变数据的结构以适应分析的需要。在R中,`merge()`函数用于数据合并,`reshape()`函数或`tidyverse`包中的`dplyr`和`tidyr`函数用于数据重塑。以下是使用这些函数来合并和重塑数据的示例:
```r
# 创建两个数据框
df1 <- data.frame(ID = 1:5, X = rnorm(5))
df2 <- data.frame(ID = 1:5, Y = rnorm(5))
# 合并数据框
merged_data <- merge(df1, df2, by = "ID")
# 长格式转宽格式
df_long <- data.frame(ID = rep(1:5, each = 2), Time = rep(c("Time1", "Time2"), 5), Value = c(rnorm(5), rnorm(5, mean = 1)))
df_wide <- reshape(df_long, idvar = "ID", timevar = "Time", direction = "wide")
# 使用tidyverse包的工具来转换数据
library(tidyverse)
df_long %>%
spread(Time, Value) %>%
mutate(Difference = Time2 - Time1)
```
数据的合并与重塑是数据分析中非常常见的任务,正确的操作可以使得数据更加适合分析。
### 2.3 数据转换的高级技巧
在进行数据处理与清洗之后,往往需要进行一系列的数据转换,以适应不同的分析需求。这一节将探讨分组与汇总、数据透视表的制作以及数据标准化与归一化的高级技巧。
#### 2.3.1 分组与汇总
分组与汇总是数据分析中的重要步骤,用于对数据集按照某一变量进行分组并计算每组的统计量。在R中,可以使用`dplyr`包提供的函数来轻松实现分组与汇总。以下是一个使用`dplyr`进行分组与汇总的示例:
```r
# 加载dplyr包
library(dplyr)
# 创建数据框
group_data <- data.frame(
Group = c("A", "B", "A", "B", "C", "A"),
Value = c(2.5, 4.0, 2.7, 3.9, 3.3, 2.4)
)
# 按Group列分组并计算每组的平均值
grouped_data <- group_data %>%
group_by(Group) %>%
summarise(Average = mean(Value))
# 按Group列分组并计算每组的标准差
grouped_data <- group_data %>%
group_by(Group) %>%
summarise(StdDev = sd(Value))
```
分组与汇总能够让我们快速地从数据中获得洞察。
#### 2.3.2 数据透视表的制作
数据透视表是数据分析中不可或缺的工具,它可以帮助我们快速汇总、比较和分析数据。在R中,`reshape2`包中的`dcast()`函数和`tidyverse`包中的`pivot_table()`函数可以用来制作数据透视表。以下是一个使用`reshape2`包制作数据透视表的示例:
```r
# 加载reshape2包
library(reshape2)
# 使用dcast函数制作数据透视表
pivot_table <- dcast(group_data, Group ~., value.var = "Value", fun.aggregate = mean)
```
数据透视表对于理解数据中的模式和趋势特别有帮助。
#### 2.3.3 数据标准化与归一化
数据标准化和归一化是数据预处理过程中的重要步骤,它们可以使数据更加适合进行一些特定的分析方法,比如聚类分析和机器学习。数据标准化通常指的是将数据按比例缩放,使之落入一个小的特定区间,如0到1之间。归一化通常指的是使数据的分布标准化,使之符合正态分布。以下是一个使用`scale()`函数进行标准化的示例:
```r
# 创建数据框
scale_data <- data.frame(
Feature1 = c(10, 20, 30, 40),
Feature2 = c(15, 25, 35, 45)
)
# 数据标准化
scaled_data <- scale(scale_data)
```
通过数据标准化和归一化,我们可以确保分析过程中各个特征的公平性。
在本章中,我们深入探讨了R语言中的数据处理与清洗技巧,涵盖了数据结构的基本理解、数据清洗的基本操作,以及数据转换的高级技巧。这些内容构成了数据分析的坚实基础,有助于我们准备出高质量的数据集进行后续的分析工作。在下一章中,我们将转向数据可视化与探索性分析的介绍,进一步挖掘数据背后的故事。
# 3. 数据可视化与探索性分析
#### 3.1 图形化展示数据
在数据科学领域,数据可视化是一个关键的环节,它允许我们直观地理解数据,发现模式和趋势,以及传达复杂的数据概念给非专业人士。R语言提供了一系列强大的工具,用于创建直观且吸引人的图表。
##### 3.1.1 基础图表的绘制
R语言中最常用的图表绘制包是ggplot2。ggplot2提供了一种层次化的绘图方法,允许用户通过添加图层(如几何对象、统计变换和位置调整)来自定义图表。下面是一个基础条形图的示例代码:
```r
library(ggplot2)
data(mtcars)
ggplot(mtcars, aes(x = factor(cyl))) +
geom_bar(fill = "steelblue") +
labs(x = "Number of Cylinders", y = "Count", title = "Bar Chart of Car Cylinders")
```
该代码首先加载了ggplot2包,并使用mtcars数据集。通过aes函数,我们将气缸数(cyl)映射为x轴,然后使用geom_bar函数来绘制条形图,其中填充颜色设置为"steelblue"。最后,我们添加了x轴和y轴的标签,并给图表一个标题。
##### 3.1.2 高级图形的设计
除了基础图表,R语言还能够创建更复杂、更精细的图表,如分面图、并排条形图或带有交互性的图形。使用ggplot2的分面功能,可以轻松地创建分组的图表,为每个变量的每个水平生成单独的图形。以下是一个分组散点图的示例:
```r
ggplot(mtcars, aes(x = wt, y = mpg, color = factor(gear))) +
geom_point() +
facet_wrap(~gear) +
labs(x = "Weight", y = "Miles Per Gallon", color = "Gear")
```
该代码生成了一个散点图,其中展示的是汽车重量(wt)与油耗(mpg)之间的关系,并根据变速器的档位(gear)对数据进行了分面。每个档位的数据显示在不同的子图中,通过颜色来区分不同的档位。
#### 3.2 探索性数据分析
探索性数据分析(Exploratory Data Analysis,简称EDA)是数据分析过程中不可或缺的部分。EDA包括各种技术和实践,旨在理解数据的分布、找出异常值、识别变量间的关系以及生成假设。
##### 3.2.1 描述性统计分析
描述性统计分析是对数据集的基本特征进行总结,包括中心趋势(均值、中位数)、分散程度(方差、标准差)和分布特征(偏度、峰度)等的度量。以下是如何在R中进行描述性统计分析的示例:
```r
summary(mtcars)
```
这个简单的summary函数将提供mtcars数据集中每个变量的描述性统计,包括最小值、第一四分位数、中位数、均值、第三四分位数和最大值。
##### 3.2.2 相关性分析与检验
在数据集中,我们经常需要了解变量间的相关性。R语言提供了多种方法来计算相关系数。例如,可以使用cor函数来计算两变量间的皮尔逊相关系数:
```r
cor(mtcars$mpg, mtcars$wt)
```
这将给出mtcars数据集中油耗(mpg)与重量(wt)之间的相关性。
#### 3.3 数据报告与交互式图形
随着R Markdown和Shiny的应用,R语言在数据报告和交互式图形方面也展现出了强大的能力。
##### 3.3.1 动态报告生成
R Markdown是一个强大的工具,它结合了R代码和Markdown标记语言,可以生成格式化的文档、报告、甚至是幻灯片。以下是一个简单的R Markdown报告示例:
```markdown
title: "Data Report"
output: html_document
# Introduction
This is an introductory paragraph of the report.
## Analysis
```{r}
# R code chunk for analysis
summary(mtcars)
```
The above R code has summarized the mtcars dataset.
```
该文档在渲染时会执行R代码块,并将结果嵌入最终生成的HTML报告中。
##### 3.3.2 交互式图形的实现
Shiny是R的一个包,用来创建交互式的web应用程序。Shiny应用程序由两个主要组件构成:ui(用户界面)和server(服务器逻辑)。以下是Shiny应用的基础框架:
```r
library(shiny)
ui <- fluidPage(
titlePanel("Basic Shiny Application"),
sidebarLayout(
sidebarPanel(
sliderInput("bins",
"Number of bins:",
min = 1,
max = 50,
value = 30)
),
mainPanel(
plotOutput("distPlot")
)
)
)
server <- function(input, output) {
output$distPlot <- renderPlot({
# generate bins based on input$bins from ui.R
x <- faithful$waiting
bins <- seq(min(x), max(x), length.out = input$bins + 1)
hist(x, breaks = bins, col = 'darkgray', border = 'white')
})
}
shinyApp(ui, server)
```
这段代码定义了一个简单的Shiny应用程序,其中包含一个滑动条输入控件,允许用户改变直方图的箱数。服务器函数根据用户输入生成并返回直方图。最终,shinyApp函数将用户界面和服务器逻辑结合在一起,创建了一个完整的Shiny应用。
### 表格展示
| 概念 | 描述 |
|----------------------|--------------------------------------------------------------|
| 数据可视化 | 使用图形或图片的方式展示数据,以便快速理解数据特征 |
| 探索性数据分析 | 一种数据分析方法,旨在发现数据中的模式、趋势和关联 |
| 描述性统计分析 | 对数据集进行概要性统计描述,包括中心趋势和分散程度的度量 |
| 相关性分析与检验 | 探究两个或多个变量之间的统计关系,如线性相关程度 |
| 交互式图形 | 用户可以与之交互的图形,可以改变视觉呈现,以获取更多信息 |
### 交互式图表示例 - 代码块
```mermaid
graph LR
A[开始分析] --> B[数据导入]
B --> C[数据清洗]
C --> D[数据可视化]
D --> E[探索性数据分析]
E --> F[生成报告]
```
此流程图用mermaid语言定义了一个数据处理的流程,通过流程图可以清晰地理解整个数据分析的步骤和顺序。
在这一章节中,我们了解了R语言如何用图形化的方式展现数据,以及如何利用探索性数据分析来深入理解数据集。此外,我们也展示了如何通过R Markdown和Shiny创建交互式的报告和应用。这些技能对于任何数据分析师来说都是必备的,它们可以帮助我们更好地呈现数据洞察,以及构建可以互动的、动态的报告系统。
# 4. 统计模型与机器学习
## 4.1 常用统计模型
### 4.1.1 回归分析
回归分析是统计学中一个强有力的工具,它通过研究变量间的依赖关系来预测或控制某变量。在R语言中,可以使用`lm()`函数来执行简单的线性回归,而`glm()`函数则可以进行广义线性回归分析。
```r
# 简单线性回归示例
data(mtcars)
lm_model <- lm(mpg ~ wt, data=mtcars)
summary(lm_model)
```
在上述代码中,我们使用了mtcars数据集,并以车的重量(wt)作为解释变量来预测每加仑汽油的英里数(mpg)。`summary()`函数将输出模型的详细统计结果。
### 4.1.2 方差分析(ANOVA)
方差分析(ANOVA)是一种检验多个组间均值是否存在显著差异的统计方法。在R中,我们利用`aov()`函数来进行单因素或双因素ANOVA分析。
```r
# 单因素ANOVA示例
model <- aov(mpg ~ factor(cyl), data=mtcars)
summary(model)
```
这里,我们对mtcars数据集中的汽车的气缸数量(cyl)是否影响燃油效率(mpg)进行检验。输出结果包括F统计量和p值,用以判断组间差异的显著性。
### 4.1.3 多元回归
多元回归模型是线性回归的扩展,它允许我们同时使用多个预测变量。
```r
# 多元线性回归示例
lm_model <- lm(mpg ~ wt + hp + drat, data=mtcars)
summary(lm_model)
```
这里加入了马力(hp)和传动比(drat)作为预测变量,`summary()`函数输出将显示每个变量对模型的贡献度。
## 4.2 机器学习方法
### 4.2.1 预测建模
预测建模是机器学习中的重要部分,它涉及到数据集的划分、模型的构建和预测结果的评估。
```r
# 用mtcars数据集进行训练测试分割
set.seed(123) # 设置随机种子以获得可重复结果
training_indices <- sample(1:nrow(mtcars), round(0.8 * nrow(mtcars)))
mtcars_train <- mtcars[training_indices, ]
mtcars_test <- mtcars[-training_indices, ]
# 使用训练数据构建模型
lm_model <- lm(mpg ~ ., data=mtcars_train)
# 使用测试数据评估模型
predictions <- predict(lm_model, newdata=mtcars_test)
```
在该代码块中,我们首先划分了数据集为训练集和测试集,然后构建了线性回归模型,并用测试集进行了模型预测。
### 4.2.2 聚类分析
聚类分析旨在将数据集划分为多个类别,R语言中的`kmeans()`函数和`hclust()`函数分别实现了K均值聚类和层次聚类。
```r
# K均值聚类示例
set.seed(123)
kmeans_result <- kmeans(mtcars[, -1], centers=3)
# 层次聚类示例
distance_matrix <- dist(mtcars[, -1])
hclust_result <- hclust(distance_matrix, method="complete")
```
在上述代码中,我们使用了mtcars数据集(除去第一列的气缸数),通过K均值聚类得到了三个聚类中心,并通过层次聚类得到了完整的聚类树。
### 4.2.3 分类与回归树(CART)
分类与回归树(CART)是一种常用于预测建模的算法,它创建在数据中寻找划分点的规则,以最小化残差。
```r
library(rpart)
rpart_model <- rpart(mpg ~ ., data=mtcars_train, method="anova")
summary(rpart_model)
```
上述代码中,使用mtcars数据集的训练子集构建了一个CART模型,并用`summary()`函数查看了模型的详细信息。
## 4.3 模型评估与优化
### 4.3.1 模型评估指标
模型评估指标可以衡量模型的性能。常见的指标包括均方误差(MSE)、均方根误差(RMSE)和决定系数($R^2$)。
```r
# 均方误差计算示例
mse <- mean((mtcars_test$mpg - predictions)^2)
# 均方根误差计算示例
rmse <- sqrt(mse)
# 决定系数示例
r_squared <- 1 - (sum((mtcars_test$mpg - predictions)^2) / sum((mtcars_test$mpg - mean(mtcars_test$mpg))^2))
```
在上面的代码中,我们用均方误差、均方根误差和决定系数评估了线性回归模型在测试集上的表现。
### 4.3.2 参数调优方法
参数调优是优化模型性能的关键步骤。在R中,可以使用网格搜索(grid search)和随机搜索(random search)来寻找最佳参数。
```r
library(caret)
# 网格搜索示例
train_control <- trainControl(method="repeatedcv", number=10, repeats=3)
lm_fit <- train(mpg ~ ., data=mtcars_train, method="lm", trControl=train_control, tuneLength=5)
```
这里我们使用`caret`包来执行线性模型的参数调优,通过交叉验证的方式寻找最优参数。
### 4.3.3 模型的交叉验证与泛化能力
交叉验证是一种评估模型泛化能力的技术,它通过将数据集分成多个子集,循环使用其中一部分作为验证集,其余作为训练集。
```r
# K折交叉验证示例
set.seed(123)
kfold_control <- trainControl(method="cv", number=10)
lm_kfold <- train(mpg ~ ., data=mtcars, method="lm", trControl=kfold_control)
```
在此代码中,我们设置了10折交叉验证,利用`caret`包的`trainControl()`函数来控制交叉验证的流程。
通过本章节的介绍,我们理解了R语言在统计模型和机器学习方面的丰富功能和应用。我们可以看到,无论是传统的统计模型还是现代的机器学习技术,R语言都提供了一系列易于使用且功能强大的工具,满足各种数据分析和预测的需求。
# 5. R语言实战项目技巧
## 5.1 项目管理与协作
在R语言的项目开发中,管理和协作是不可或缺的环节。良好的项目管理能够确保项目进度,提升代码质量和团队协作效率。而GitHub作为版本控制系统,为R语言项目提供了强大的支持。
### 5.1.1 版本控制与GitHub
版本控制允许开发者追踪和管理代码的变更历史,GitHub更是扩展了版本控制的功能,它不仅支持代码托管,还提供了丰富的社交协作功能。
- 初始化本地仓库:在项目根目录下使用`git init`命令初始化本地仓库。
- 链接GitHub远程仓库:使用`git remote add origin [repository_url]`命令将本地仓库与GitHub上的远程仓库关联。
- 提交更改:通过`git add .`添加文件更改到暂存区,然后用`git commit -m "commit message"`提交更改到本地仓库。
- 推送到GitHub:使用`git push -u origin master`将本地更改推送到GitHub上的master分支。
### 5.1.2 包管理与维护
R语言中使用包(Package)来扩展其功能。包管理是R语言项目中的重要组成部分,它关系到项目依赖的完整性和代码的复用性。
- 安装包:使用`install.packages("package_name")`从CRAN或其他仓库安装包。
- 载入包:使用`library(package_name)`或`require(package_name)`在R会话中载入包。
- 更新包:使用`update.packages(ask = FALSE)`命令批量更新已安装的包。
## 5.2 从案例学习分析方法
通过具体案例来展示如何运用R语言进行数据分析。每个案例都可能涉及到不同的分析方法和技巧。
### 5.2.1 金融数据分析实例
在金融数据分析中,R语言可以用于风险评估、资产定价、市场分析等领域。
- 使用`quantmod`包获取和分析金融数据。
- 利用时间序列分析模型如ARIMA进行市场预测。
- 通过`PerformanceAnalytics`包来评估投资组合性能。
### 5.2.2 生物信息学数据处理实例
生物信息学的数据通常是高维度的,R语言的生物统计包可以帮助科学家进行基因表达分析、生物标记物筛选等。
- 使用`Bioconductor`项目中的包如`DESeq2`进行差异表达分析。
- 利用`limma`包进行微阵列数据分析。
- 使用`ggplot2`和`pheatmap`包进行结果的可视化展示。
### 5.2.3 社会科学数据研究实例
在社会科学领域,R语言可以用来处理调查数据,进行统计建模和社交网络分析等。
- 使用`survey`包处理抽样调查数据。
- 运用`lme4`包构建混合效应模型。
- 应用`igraph`包进行社交网络的结构和关系分析。
## 5.3 性能优化与调试技巧
性能优化和调试是项目开发中的关键环节,直接关系到程序的执行效率和稳定性。
### 5.3.1 代码性能分析
R语言提供了性能分析的工具,如`profvis`包,它可以帮助开发者识别代码中的性能瓶颈。
- 使用`profvis`对代码块进行性能分析。
- 识别运行缓慢的函数和循环。
- 优化关键代码段,例如通过向量化操作替代循环。
### 5.3.2 内存管理和优化
内存管理是优化R语言性能的另一个重要方面。合理地管理内存可以避免程序在处理大数据集时出现崩溃。
- 使用`gc()`函数清理无用的对象。
- 采用`rm()`函数删除不再需要的大对象。
- 运用`data.table`包以高效方式处理大型数据集。
### 5.3.3 调试工具的使用和技巧
R语言的调试工具可以帮助开发者快速定位和解决问题。
- 使用`browser()`函数在代码中设置断点。
- 利用`traceback()`函数查看错误发生的调用堆栈。
- 应用`debug()`和`undebug()`函数对特定函数进行调试。
通过这些实战技巧,R语言开发者可以更好地管理项目、分析数据和优化性能,从而提升整体工作效率和项目质量。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供了一系列深入且实用的教程,指导读者使用 R 语言数据包 ismev 进行数据分析。从基础入门到高级应用,涵盖了数据清洗、预处理、极值统计、统计模型构建、贝叶斯分析、金融风险分析、环境搭建、项目实战、Excel 数据交互、高级功能和时间序列分析等广泛主题。专栏内容由专家撰写,旨在帮助读者掌握 ismev 包的强大功能,提升他们的数据分析技能。无论是初学者还是经验丰富的从业者,都能从本专栏中找到有价值的见解和实用技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Multisim实战演练:构建高效数据选择器电路的策略

# 摘要
本文对Multisim软件中数据选择器电路的设计与应用进行了全面的探讨。首先介绍了数据选择器电路的基础知识和理论基础,包括其工作原理、关键参数
网络工程师必修课:华为交换机端口优先级调整的5个技巧
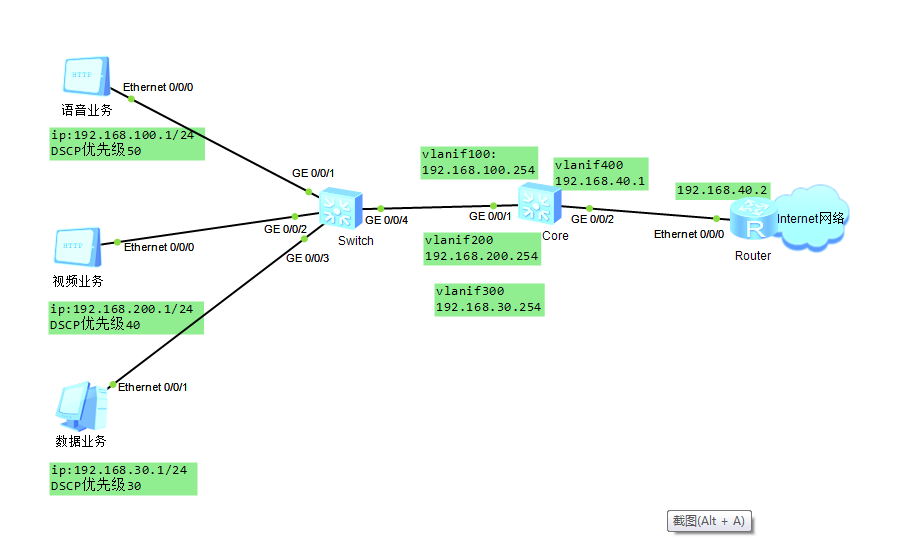
# 摘要
随着网络技术的快速发展,网络性能和数据流管理变得日益重要。本文旨在探讨华为交换机端口优先级调整的重要性和实际操作技巧。通过了解端口优先级的基础知识,包括其与网络性能的关系以及配置基础,技术人员可以更有效地管理和控制网络流量。本文还介绍了一些高级应用和故障排除方法,以提高网络效率和可靠性。最后,文章展望了自动化技术在网络优先级管理中的未来趋势,以及网络工程师
微信小程序安全指南:如何防范常见的安全威胁

# 摘要
微信小程序作为移动互联网的重要组成部分,其安全性问题日益凸显,成为业界关注的焦点。本文从微信小程序安全基础出发,深入分析其安全架构与机制,包括微信小程序的安全组件及其在实践中的应用案例。针对代码注入、CSRF、XSS等常见的安全威胁,本文提出了输入验证、安全API使用等防范策略,并对安全编码原则和技术实现进行了探讨。最后,文章概述了微信小程序安全审核流程和合规性要求,旨在为开发者提供一套全面的微信小程序安全指南,以提升小程序整
【数据预处理与增强】:提升神经网络模型性能的关键步骤
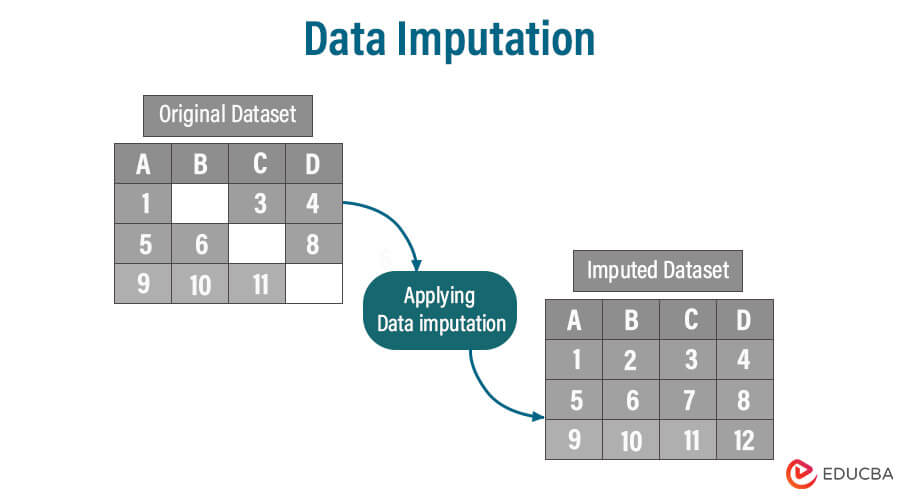
# 摘要
数据预处理与增强是机器学习和深度学习任务中至关重要的步骤,直接影响着模型的性能。本文系统地讨论了数据预处理的目的、理论基础以及各种数据清洗、标准化和特征提取技术。随后,针对图像、文本和时序数据,详细介绍了相应的数据增强技术,并通过案例分析展示了数据增强对神经网络性能的积极影响,同时探讨了数据增强的局限性和未来趋势。本文还介绍了一些先进的数据预处理与增强工具和框架,强调
微积分的终极揭秘:深入剖析位置补偿条件指令

# 摘要
本文全面阐述了微积分基础知识,并深入探讨了位置补偿条件指令理论及其在实践中的应用。文章首先回顾了微积分的基础概念,包括微分、积分、导数和极限的理论基础,随后详细介绍了位置补偿的数学模型和实际应用案例。在实践应用章节中,本文探讨了编程实现和实验验证的方法,并结合工程案例分析了位置补偿策略的实施和效果。文章进一步讨论了位置补偿条件指令的进阶应用,包括高级算法、
【ArcGIS进阶操作】:批量点转面技巧揭秘,让你的数据管理更高效

# 摘要
本文详细探讨了ArcGIS软件在地理信息系统(GIS)中的数据管理与处理技巧,特别是点数据和面数据的创建、编辑、空间分析以及批量处理。重点介绍了点转面操作的理论基础与实践方法,并通过案例分析展示了批量点转面操作的步骤和关键技巧。此外,本文还展望了ArcGIS进阶操作的未来趋势,包括大数据和人工智能的应用,以及面临的挑战,如数据安全和软件可持续发展问题。通过
高校校车订座系统权限管理:打造安全用户权限策略的5个步骤

# 摘要
随着信息技术的发展,高校校车订座系统的安全性和功能性需求日益增长,其中权限管理作为系统安全的关键组成部分,其重要性不言而喻。本文首先对高校校车订座系统的权限管理需求进行了深入分析,阐述了权限管理的概念、意义及其与系统安全的紧密关系。接着,介绍了权限管理的基础理论,包括常见的管理模型、策略设计原则及用户身份验证与授
【Spring Boot实战秘籍】:快速开发健身俱乐部会员系统

# 摘要
本文介绍了一个基于Spring Boot框架的会员系统的开发和维护过程,涵盖了从基础配置到高级特性的应用以及部署与维护策略。首先,我们介绍了系统核心功能的开发,包括用户模型的构建、会员注册与认证流程,以及会员信息管理界面的设计。随后,
Mapbox地图设计艺术:视觉层次与色彩搭配

# 摘要
本文从艺术和实用性角度综合探讨了Mapbox地图设计的各个方面。第一章对Mapbox地图设计艺术进行了总体介绍,揭示了设计艺术在地图呈现中的重要性。第二章深入探讨了地图的视觉层次理论,包括视觉层次的基础、创建有效视觉层次的策略以及实例分析,旨在通过视觉元素组织提升地图的信息传达效果。第三章专注于地图色彩搭配技巧,从色彩理论基础到实际应用,以及
MTK Camera HAL3更新维护策略:系统稳定与先进性的保持之道
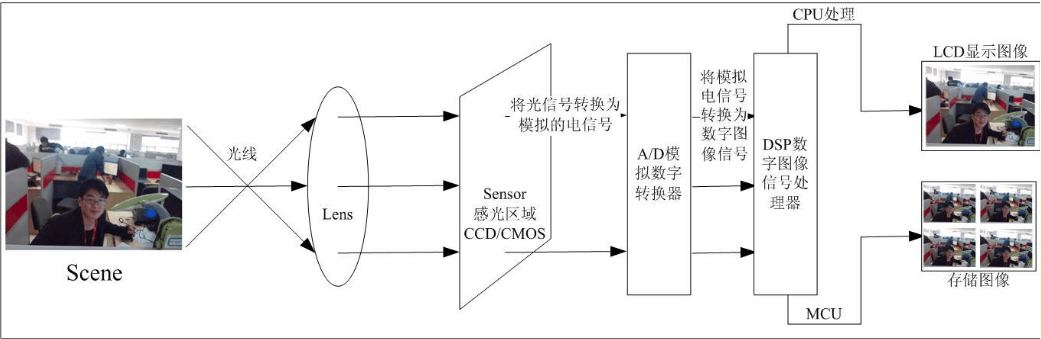
# 摘要
本文全面介绍了MTK Camera HAL3的技术架构,探讨了提高系统稳定性和先进性的重要性,以及实现这些目标的关键策略。通过分析硬件抽象层(HAL)的作用和优化,系统架构稳定性考虑,以及持续集成与自动化测试的实施方法,本文揭示了MTK Camera HAL3的性能提升路径。此外,文章也强调了技术更新、高级功能集成和用户体验改善对于保持产品竞争力的重要
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )