【Python编程秘籍】:精通urlparse模块的12种实战技巧
发布时间: 2024-10-08 16:37:36 阅读量: 41 订阅数: 32 
# 1. urlparse模块简介与安装
在当今数字时代,网络地址已成为我们日常交互不可或缺的一部分。Python的`urlparse`模块提供了一种方便的方法来解析和构建URL,它将URL分解成多个组件,使开发者能够轻松地访问和修改这些组件。本文将带你走进`urlparse`的世界,从其基本概念讲起,深入到实际应用,并展望其未来发展。
## 1.1 urlparse模块的简介
`urlparse`是Python标准库中的一个模块,它允许我们对统一资源定位符(Uniform Resource Locator,URL)进行解析。通过使用这个模块,我们能够将URL分解成几个组件,如协议(scheme)、网络位置(netloc)、路径(path)等,这对于进行网络编程和网络数据处理时非常有用。
## 1.2 安装与使用
在Python 3中,`urlparse`模块已经包含在标准库中,因此不需要额外安装。如果你使用的是Python 2,可能需要安装`urlparse34`这个第三方库。你可以通过运行以下pip命令来安装:
```bash
pip install urlparse34
```
一旦安装完成,你就可以在Python代码中直接导入`urlparse`模块,并开始使用它提供的功能了。下面是一个简单的例子,展示了如何解析一个URL字符串:
```python
from urlparse import urlparse
url = '***'
parsed_url = urlparse(url)
print(parsed_url.scheme) # 输出: http
print(parsed_***loc) # 输出: ***
print(parsed_url.path) # 输出: /path/to/page
print(parsed_url.query) # 输出: name=alice&age=18
```
通过本章的学习,我们将掌握`urlparse`模块的基础知识,为深入解析和使用它奠定基础。接下来的章节将带领大家逐步深入了解`urlparse`模块的内部结构和高级功能。
# 2. 深入解析urlparse模块的结构
## 2.1 urlparse模块的组件构成
### 2.1.1 网址的基本结构和组件
网址(Uniform Resource Locator, URL)是互联网中资源定位的基本方式,其标准格式由几个核心组件构成,通常包含协议(scheme)、网络位置(netloc)、路径(path)、查询参数(query)等。例如,在URL `***` 中,`http` 是协议,`***` 是网络位置,`/path/to/resource` 是路径,`query=string` 是查询参数。
解析一个URL,通常意味着将这些组件分离出来,以便于程序能够独立地对这些组件进行访问和处理。Python标准库中的urlparse模块正是为了这一目的而设计的,它可以对URL进行结构化分解,并提取出各个组件。
### 2.1.2 解析网址的各个组件
urlparse模块能够解析出以下组件:
- `scheme`:协议部分,如`http`, `https`, `ftp`等。
- `netloc`:网络位置部分,包括域名和端口号,例如`***:80`。
- `path`:资源的路径,如`/path/to/resource`。
- `query`:查询字符串,以`?`开头,如`?query=string`。
- `fragment`:URL中的片段标识符,以`#`开头,例如`#section1`。
使用urlparse模块中的`urlparse()`函数,可以将URL分解为这些组件。例如:
```python
from urllib.parse import urlparse
url = '***'
parsed_url = urlparse(url)
print(parsed_url)
```
执行上述代码后,我们得到一个`ParseResult`对象,包含了各个组件的属性。
## 2.2 urlparse方法详解
### 2.2.1 urlsplit()与urlunsplit()
虽然`urlparse()`是解析URL的常用函数,但`urlsplit()`和`urlunsplit()`方法在处理URL时也十分有用。`urlsplit()`方法与`urlparse()`功能类似,但它不处理查询参数和片段标识符,适用于只需要网络位置和路径信息的场景。
`urlunsplit()`方法则正好相反,它将一个URL组件的序列重新组合成一个完整的URL字符串。这在需要对URL进行修改时尤其有用。例如,可以用来改变URL的协议部分或添加新的查询参数。
```python
from urllib.parse import urlsplit, urlunsplit
split_url = urlsplit(url)
print(split_url)
# 修改URL的协议部分,并重新组合
new_url = urlunsplit(split_url._replace(scheme='https'))
print(new_url)
```
### 2.2.2 urljoin()与urldefrag()
`urljoin()`方法用于合并基础URL和相对URL,确保生成的URL是绝对且有效的。这对于网络爬虫或任何需要构建大量URL的应用程序来说非常实用。
`urldefrag()`方法用于去除URL的片段标识符部分,如果URL中存在片段标识符,它会返回一个`Result`对象,包含去除片段的URL和片段标识符。
```python
from urllib.parse import urljoin, urldefrag
base_url = '***'
relative_url = 'path/to/resource'
full_url = urljoin(base_url, relative_url)
print(full_url)
# 分离URL的片段标识符
defragged_url = urldefrag(full_url)
print(defragged_url)
```
## 2.3 urlparse的高级参数使用
### 2.3.1 分隔符的自定义和限制
在某些情况下,标准的URL分隔符(如`?`用于查询参数,`#`用于片段标识符)可能需要被自定义或移除。使用`urlparse()`和`urlsplit()`函数时,可以通过`delimiter`参数来指定查询参数和片段标识符的分隔符。
```python
# 自定义分隔符
custom_url = '***'
parsed_custom_url = urlparse(custom_url, delimiter=';', allow_fragments=False)
print(parsed_custom_url)
```
### 2.3.2 解析策略的控制和调整
通过`urlparse()`函数的`scheme`和`allow_fragments`参数,我们可以控制解析策略。`scheme`参数允许开发者指定哪些协议是允许的,而`allow_fragments`参数可以控制是否允许片段标识符。
```python
# 控制是否允许片段标识符
no_fragment_url = '***'
parsed_no_fragment_url = urlparse(no_fragment_url, allow_fragments=False)
print(parsed_no_fragment_url)
```
通过上述代码,`parsed_no_fragment_url`将不会包含片段标识符的信息。
通过这些高级参数的使用,开发者可以更精确地控制URL的解析过程,以适应各种特定场景的需求。
# 3. 利用urlparse进行网址分析
在这个章节中,我们将深入探讨如何使用urlparse模块进行网址的详细分析。这将包括提取网络资源类型、分析主机和端口信息、以及路径与查询参数的提取。我们将通过实际的代码例子和解释来展示urlparse模块在这些方面的应用。
## 3.1 提取网络资源类型
### 3.1.1 理解scheme的作用与应用
在互联网的URL结构中,scheme是指定访问资源协议的那部分,例如http、https、ftp等。Scheme是URL的第一部分,并由冒号(:)结束。在解析一个URL时,正确地识别和处理scheme是至关重要的,因为它决定了我们如何与该资源交互。
在Python中,使用urlparse模块可以很轻易地提取URL中的scheme部分。以下是一个如何实现的例子:
```python
from urllib.parse import urlparse
url = "***"
parsed_url = urlparse(url)
scheme = parsed_url.scheme
print("Scheme:", scheme)
```
代码逻辑解读:
- 首先,从`urllib.parse`模块中导入`urlparse`函数。
- 创建一个URL字符串,并将其作为参数传递给`urlparse`函数。
- `urlparse`函数返回一个`ParseResult`对象,包含了解析后的URL的不同组件。
- 通过访问`ParseResult`对象的`scheme`属性来获取scheme。
### 3.1.2 处理不同类型的网络协议
网络协议(scheme)的多样性意味着我们需要一种通用的方法来处理它们。urlparse模块支持识别绝大多数标准协议,但也提供了对自定义协议的支持。例如,我们可能需要解析一个自定义的`myprotocol://`协议。
让我们以一个例子来看看如何处理这种情况:
```python
from urllib.parse import urlparse, ProtocolError
urls = [
"***",
"myprotocol://***/page?name=value"
]
for url in urls:
try:
parsed_url = urlparse(url)
scheme = parsed_url.scheme
print(f"URL: {url}, Scheme: {scheme}")
except ProtocolError:
print(f"URL: {url}, is not a valid URL.")
```
代码逻辑解读:
- 创建一个包含两种不同scheme的URL列表。
- 对每个URL使用`urlparse`函数进行解析。
- 在尝试访问`scheme`属性之前,捕获可能的`ProtocolError`异常,这是因为非标准协议可能不被urlparse支持,从而触发异常。
- 如果URL有效,打印出URL和对应的scheme。
## 3.2 分析主机和端口
### 3.2.1 获取和验证主机名
对于网络请求来说,主机名是用来确定我们想要访问的服务器地址。在解析URL时,获取主机名是基础操作之一。urlparse模块可以帮助我们从任何合法的URL中提取出主机名。
以下是示例代码:
```python
from urllib.parse import urlparse
url = "***"
parsed_url = urlparse(url)
hostname = parsed_url.hostname
print("Hostname:", hostname)
```
代码逻辑解读:
- 使用`urlparse`函数解析URL。
- 通过访问`ParseResult`对象的`hostname`属性来获取主机名。
- 打印主机名信息。
### 3.2.2 提取和使用端口号
端口号是网络服务的通信端口,它用来标识特定的服务或应用。大多数服务有默认端口号(如HTTP的80端口,HTTPS的443端口),但也可能使用非默认端口。
下面的代码展示了如何提取端口号:
```python
from urllib.parse import urlparse
url = "***"
parsed_url = urlparse(url)
port = parsed_url.port
print("Port:", port)
```
代码逻辑解读:
- 使用`urlparse`解析URL。
- 访问`ParseResult`对象的`port`属性来获取端口号。
- 打印端口号信息。
## 3.3 路径与查询参数的提取
### 3.3.1 分析路径信息
路径信息通常指向服务器上的特定资源或页面。我们可以使用urlparse模块来解析这个部分,并且进一步处理路径字符串。
以下是提取路径信息的代码示例:
```python
from urllib.parse import urlparse
url = "***"
parsed_url = urlparse(url)
path = parsed_url.path
print("Path:", path)
```
代码逻辑解读:
- 使用`urlparse`函数解析URL。
- 通过访问`ParseResult`对象的`path`属性来获取路径信息。
- 打印路径信息。
### 3.3.2 解析和构建查询字符串
查询字符串通常位于URL的末尾,以问号(?)开始,并包含一系列的键值对。在处理Web请求时,解析这些参数是一项常见的任务。
使用urlparse模块进行查询字符串解析的例子:
```python
from urllib.parse import urlparse, parse_qs
url = "***"
parsed_url = urlparse(url)
query_params = parse_qs(parsed_url.query)
print("Query Parameters:", query_params)
```
代码逻辑解读:
- 使用`urlparse`函数解析URL。
- 通过访问`ParseResult`对象的`query`属性来获取查询字符串部分。
- 使用`parse_qs`函数解析查询字符串,并将其转换为字典形式,便于操作。
- 打印查询参数字典。
以上,我们通过实例介绍了使用urlparse模块进行网址分析的各个方面。通过本章节的介绍,我们已经能够利用Python中的urlparse模块对URL的各个组件进行细致的分析和处理,为后续章节中更复杂的应用打下了坚实的基础。
# 4. urlparse模块的实战技巧
## 4.1 构建复杂的URL结构
在开发过程中,经常需要动态构建URL以满足应用程序的需求。使用Python的urlparse模块,我们可以轻松实现这一目标。首先,让我们探索如何使用urlparse构建复杂的URL结构。
### 4.1.1 使用urlparse生成URL
Python的`urlparse`模块提供了一系列工具来构建和解析URL。为了构建URL,我们可以使用`urlunparse`函数,它接受一个特定顺序的字符串序列,并将其组合成一个完整的URL。这个序列包括协议(scheme)、网络位置(netloc)、路径(path)、参数(params)、查询(query)和片段(fragment)。
下面是一个示例代码块,演示如何使用`urlunparse`来构建一个标准的HTTP URL。
```python
from urllib.parse import urlunparse
# 定义URL的各个部分
scheme = 'http'
netloc = '***'
path = 'path/to/resource'
params = ''
query = 'key1=value1&key2=value2'
fragment = 'section1'
# 将各部分组合为一个完整的URL
url = urlunparse((scheme, netloc, path, params, query, fragment))
print(url)
```
在这个例子中,我们创建了一个包含查询参数的URL。`urlunparse`函数接受一个六元素的元组,每个元素对应URL的一个部分。这种方式非常适合动态构建复杂的URL。
### 4.1.2 通过编程调整URL组件
一旦我们构建了一个URL,可能还需要根据应用的逻辑调整它的某些部分。通过`urlparse`解析URL后,我们可以操作返回对象的属性来修改URL的不同组件,然后使用`urlunparse`重新生成URL。
让我们来看一个简单的例子,演示如何修改URL的路径部分:
```python
from urllib.parse import urlparse, urlunparse
# 原始URL
url = '***'
# 解析原始URL
parsed_url = urlparse(url)
# 修改路径部分
parsed_url = parsed_url._replace(path='/new/path/to/resource')
# 重新生成URL
modified_url = urlunparse(parsed_url)
print(modified_url)
```
通过修改`urlparse`返回的`ParseResult`对象的属性,我们可以灵活地调整URL的各个组件。例如,我们还可以改变协议、添加或修改查询参数、更改片段标识符等。
## 4.2 验证和清理URL
在网络编程中,确保URL的有效性至关重要。接下来,我们将探讨如何使用urlparse来验证URL的有效性以及清理和规范化URL格式。
### 4.2.1 检查URL的有效性
尽管Python标准库没有直接提供验证URL是否真实存在的工具,但我们可以结合`urlparse`和其他库,如`requests`,来进行URL的有效性检查。
```python
import requests
from urllib.parse import urlparse
def is_valid_url(url):
parsed_url = urlparse(url)
if parsed_url.scheme in ('http', 'https') and parsed_***loc:
try:
# 尝试对URL发起一个HEAD请求
response = requests.head(url, allow_redirects=True, timeout=5)
return response.status_code == 200
except requests.RequestException:
return False
return False
# 测试URL的有效性
print(is_valid_url('***'))
```
此代码段定义了一个函数,它接受一个URL作为输入,并检查该URL是否有效。这涉及到解析URL以确保它具有有效的协议和网络位置,然后使用`requests`库发起一个简单的HTTP HEAD请求。如果响应状态码为200,则认为URL有效。
### 4.2.2 清理和规范URL格式
URL规范化是确保URL在不同的上下文中一致性的过程。例如,我们可能希望去除URL中不必要的部分,或解决相对路径和绝对路径之间的差异。`urllib.parse`模块的`urldefrag`和`urljoin`函数可以帮助我们实现这一点。
```python
from urllib.parse import urldefrag, urljoin
# 示例URL
url = '***'
# 去除片段标识符
clean_url = urldefrag(url).url
print(clean_url)
# 规范化路径
normalized_url = urljoin('***', clean_url)
print(normalized_url)
```
在第一个示例中,`urldefrag`用于去除URL的片段部分。在第二个示例中,`urljoin`结合基础路径来规范化相对路径。这样的处理能确保URL在应用中保持一致和标准化。
## 4.3 错误处理与异常管理
在解析URL时,难免会遇到格式不正确或其他问题,这时候就需要正确的错误处理与异常管理机制。
### 4.3.1 处理解析过程中常见的错误
解析URL时可能遇到的问题包括格式错误、不支持的协议或缺失组件等。通过捕获`ValueError`异常,我们可以处理解析过程中发生的错误。
```python
from urllib.parse import urlparse
try:
# 尝试解析一个无效的URL
result = urlparse('***')
except ValueError as e:
print(f'解析错误:{e}')
# 输出错误信息
```
这个例子演示了如何捕获和处理解析无效URL时的`ValueError`。
### 4.3.2 设计健壮的异常处理机制
为了设计健壮的异常处理机制,我们需要考虑可能出现的所有异常类型,并为每种异常提供适当的处理逻辑。这不仅可以帮助识别问题所在,还可以允许程序在遇到错误时优雅地恢复或终止。
```python
from urllib.parse import urlparse, ParseResult
def safe_parse_url(url):
try:
# 尝试解析URL
result = urlparse(url)
# 可以添加进一步的条件检查,例如验证协议
if result.scheme not in ['http', 'https']:
raise ValueError('不支持的协议。')
return result
except ValueError as e:
print(f'解析URL时出错: {e}')
# 根据错误类型采取进一步行动
except Exception as e:
print(f'解析URL时遇到未知错误: {e}')
# 提供一种方式来记录错误或通知管理员
# 测试函数
print(safe_parse_url('***'))
print(safe_parse_url('invalid://url'))
```
在这段代码中,我们定义了一个`safe_parse_url`函数,它尝试解析一个URL并处理所有可能发生的异常。使用条件语句检查每个可能的错误情况,并给出适当的反馈。
通过以上实战技巧,我们可以更好地利用Python的urlparse模块进行URL的构建、验证和错误处理,从而增强程序的健壮性和用户体验。
# 5. urlparse在项目中的应用案例
## 5.1 网络爬虫中的URL处理
### 5.1.1 分析爬虫抓取的URL结构
在网络爬虫中,合理地解析和处理URL是至关重要的。通过对爬虫抓取到的URL进行结构化分析,可以有效地识别和提取网络资源的类型、协议、主机名、端口号、路径和查询参数等关键信息。这不仅可以帮助开发者理解数据来源的结构,还可以为后续的数据处理和存储提供便利。
在使用urlparse模块进行URL结构分析时,首先需要导入urlparse库,然后使用`urlparse()`函数将URL分解为组件。以一个典型的爬虫抓取到的URL为例:
```python
from urllib.parse import urlparse
url = '***'
parsed_url = urlparse(url)
```
### 5.1.2 优化爬虫的链接解析效率
为了提高爬虫抓取链接的效率,可以对解析出的URL组件进行分析,然后根据需要提取特定部分,如路径部分,以便进一步构造子页面或相关页面的URL。这一步骤可以帮助爬虫更有针对性地爬取网页,而不是盲目地遍历所有链接。
下面是一个简单的代码示例,展示了如何从解析结果中提取路径部分,并拼接子页面的URL:
```python
# 提取基础URL和路径
base_url = f"{parsed_url.scheme}://{parsed_***loc}"
path = parsed_url.path
# 假设我们需要抓取当前路径下的所有子页面
subpage_base_url = f"{base_url}{path}/"
# 创建子页面URL列表
subpage_urls = [f"{subpage_base_url}{subpath}" for subpath in ['subpage1', 'subpage2', 'subpage3']]
```
通过这种方式,我们可以快速地构造出一系列需要爬取的链接,而不需要对每个链接单独解析。这样不仅提高了代码的复用性,也优化了爬虫的工作效率。
## 5.2 构建API接口的URL处理器
### 5.2.1 为RESTful API设计URL
在开发RESTful API时,合理设计URL是至关重要的。一个良好的URL设计不仅反映了资源的结构,还可以使得API易于理解和使用。使用urlparse模块可以帮助开发者检查API请求的URL是否遵循既定的模式,并确保正确地提取请求参数。
假设我们有一个API,其基本路径是`/api/resource/`,后端需要根据客户端请求的URL来处理数据。可以通过以下方式解析并验证请求的URL:
```python
from urllib.parse import urlparse
api_base_path = '/api/resource/'
api_url = '/api/resource/items/12345'
# 解析URL并检查是否符合API路径
parsed_url = urlparse(api_url)
if parsed_url.path.startswith(api_base_path):
# 提取资源ID
resource_id = parsed_url.path[len(api_base_path):]
# 处理资源请求
print(f"Processing resource with ID: {resource_id}")
else:
# 路径不符合预期,返回错误
print("Invalid URL for API request.")
```
### 5.2.2 实现URL参数和请求的映射
在处理HTTP请求时,通常需要从URL中提取查询参数,并将其映射到相应的处理函数或方法中。urlparse模块提供的`parse_qs()`函数可以将查询字符串解析成字典,这样可以方便地通过键值对方式获取参数。
这里展示了一个例子,演示了如何解析查询字符串并将其映射到处理逻辑:
```python
from urllib.parse import urlparse, parse_qs
# 假设这是从客户端接收到的请求URL
request_url = "/search?q=example&limit=10"
# 解析URL并获取查询参数
parsed_url = urlparse(request_url)
query_params = parse_qs(parsed_url.query)
# 从查询参数中提取数据
search_query = query_params.get('q', [''])[0]
limit = query_params.get('limit', ['10'])[0]
# 根据提取的参数执行搜索操作
search_results = perform_search(search_query, limit)
# 显示搜索结果
for result in search_results:
print(result)
```
通过这种映射机制,可以轻松地将URL参数转换为函数的输入参数,大大简化了Web开发的流程,并使得代码结构更加清晰。
## 5.3 数据分析中的URL处理
### 5.3.1 分析网络日志中的URL
在进行数据分析时,网络日志是一个宝贵的数据源。它记录了用户在网站上的活动,包括访问的页面、时间戳、客户端信息等。通过分析网络日志中的URL,可以提取出用户行为的模式,从而为产品优化和运营决策提供依据。
假设我们有一段网络日志数据,记录了用户的访问行为,我们可以使用urlparse模块来分析这些行为:
```python
from urllib.parse import urlparse
# 示例网络日志数据
log_entry = '***.*.*.* - - [01/Feb/2023:20:45:43 +0000] "GET /product/view?id=123 HTTP/1.1" ***'
# 解析日志中的URL
parsed_url = urlparse(log_entry.split('"')[1])
# 提取相关组件
method = log_entry.split()[5] # "GET"
path = parsed_url.path # "/product/view"
query = parsed_url.query # "id=123"
```
### 5.3.2 从URL中提取关键信息进行数据分析
网络日志中的URL通常包含了大量有价值的信息,例如访问的页面、请求的资源类型、查询参数等。通过对这些信息的提取和分析,可以了解用户的访问路径、流量分布、产品使用情况等,对于网站优化和营销策略制定有着重要的意义。
以下是一个使用Python从日志中提取特定信息并进行简单统计的示例:
```python
import re
from collections import Counter
# 假设我们有一段网络日志数据
log_data = """
***.*.*.* - - [01/Feb/2023:20:45:43 +0000] "GET /product/view?id=123 HTTP/1.1" ***
***.0.0.1 - - [01/Feb/2023:20:46:54 +0000] "GET /product/list HTTP/1.1" ***
***.0.0.1 - - [01/Feb/2023:20:47:03 +0000] "GET /search?q=example&limit=10 HTTP/1.1" ***
# 定义一个正则表达式来匹配URL中的路径
url_path_pattern = r'"GET (\/[^\s"]+)'
# 使用正则表达式查找所有匹配的URL路径
url_paths = re.findall(url_path_pattern, log_data)
# 统计不同路径的访问次数
url_path_counts = Counter(url_paths)
for path, count in url_path_counts.items():
print(f"Path: {path} - Count: {count}")
```
以上代码片段通过正则表达式提取了日志中的URL路径,并利用`collections.Counter`进行了简单的频率统计。这样可以快速地得到每个页面或资源的访问次数,为后续的数据分析提供了基础。
在实际应用中,通常会将这些分析结果与数据库或其他数据分析工具结合,以进行更深入的数据挖掘和可视化展示。
通过上述案例,我们可以看到urlparse模块在不同的项目应用中的灵活性和实用性。无论是网络爬虫、API接口还是数据分析,合理的URL处理都是确保项目成功的关键因素之一。
# 6. urlparse模块的扩展与未来展望
## 6.1 urlparse模块的局限性与替代方案
urlparse模块是Python标准库的一部分,它为URL的解析和构造提供了基础的支持。然而,在实际应用中,我们可能会遇到urlparse无法解决的问题,尤其是在处理复杂的URL或者需要进行国际化域名解析时。
### 6.1.1 分析urlparse模块的局限性
虽然urlparse模块功能强大,但仍有其局限性:
- **国际化域名支持不足**:urlparse默认不支持国际化域名(IDN)。
- **URL编码和解码**:虽然提供了基本的编码和解码方法,但在处理特殊字符时可能会遇到问题。
- **参数解析深度**:对于查询字符串中的嵌套参数或复杂数据类型(如JSON),urlparse无法提供深层次的解析。
### 6.1.2 探讨替代方案及应用场景
针对urlparse的局限性,可以考虑以下几个替代方案:
- **idna**:支持国际化域名的编码和解码。
- **urllib.parse**:Python 3中,urllib模块提供了更全面的URL处理功能。
- **第三方库**:如`rfc3986`,它严格遵循RFC 3986标准,可以处理更复杂的URL格式。
## 6.2 预见urlparse模块的发展趋势
随着时间的推移和技术的发展,urlparse模块也在不断地进行改进和升级。了解这些潜在的发展方向,对于开发者来说是非常有益的。
### 6.2.1 模块升级与改进的预测
随着Python版本的迭代更新,urlparse模块可能会增加以下特性:
- **对Unicode字符集的全面支持**:在URL的各个组件中使用Unicode字符。
- **性能优化**:在处理大量URL解析请求时,提高效率。
- **更丰富的异常处理**:提供更详细的错误信息,便于调试和维护。
### 6.2.2 对未来URL处理技术的展望
在未来的URL处理技术方面,以下方向值得关注:
- **模块集成**:将URL处理功能更好地与其他Web框架集成,如Django或Flask。
- **自动化验证**:URL解析后可以自动验证其有效性,减少手动检查步骤。
- **安全性增强**:提供更为安全的URL处理方式,防止常见的网络攻击,如SSRF(服务器端请求伪造)。
总而言之,urlparse模块在Python开发中扮演着重要角色,尽管它存在一些局限性,但通过使用替代方案和关注其未来的发展,开发者可以更好地应对日益复杂的网络环境。随着Python生态系统的不断完善,我们有理由期待urlparse模块能够带来更为强大的URL处理能力。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python库文件学习之urlparse》专栏深入探究了urlparse模块,这是一个强大的Python库,用于解析和操作URL。专栏涵盖了广泛的主题,包括:
* 实战技巧,例如构建请求和处理网络数据
* 深度源码分析和性能优化
* RESTful API中的高级应用
* 算法原理和最佳实践
* 错误处理和异常管理
* 自定义URL解析器
* 提升性能的技巧
* Web框架中的集成
通过深入的分析和实用示例,本专栏旨在帮助Python开发者掌握urlparse模块,从而增强他们的网络编程技能,提高数据抓取和请求处理的效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实时系统空间效率】:确保即时响应的内存管理技巧

# 1. 实时系统的内存管理概念
在现代的计算技术中,实时系统凭借其对时间敏感性的要求和对确定性的追求,成为了不可或缺的一部分。实时系统在各个领域中发挥着巨大作用,比如航空航天、医疗设备、工业自动化等。实时系统要求事件的处理能够在确定的时间内完成,这就对系统的设计、实现和资源管理提出了独特的挑战,其中最为核心的是内存管理。
内存管理是操作系统的一个基本组成部
机器学习性能评估:时间复杂度在模型训练与预测中的重要性
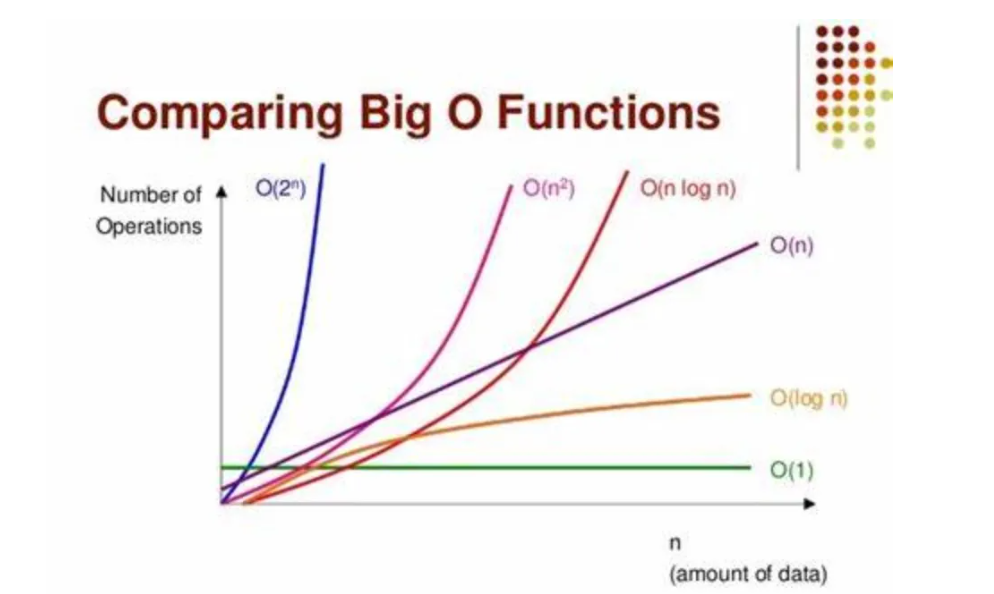
# 1. 机器学习性能评估概述
## 1.1 机器学习的性能评估重要性
机器学习的性能评估是验证模型效果的关键步骤。它不仅帮助我们了解模型在未知数据上的表现,而且对于模型的优化和改进也至关重要。准确的评估可以确保模型的泛化能力,避免过拟合或欠拟合的问题。
## 1.2 性能评估指标的选择
选择正确的性能评估指标对于不同类型的机器学习任务至关重要。例如,在分类任务中常用的指标有
贝叶斯优化:智能搜索技术让超参数调优不再是难题
# 1. 贝叶斯优化简介
贝叶斯优化是一种用于黑盒函数优化的高效方法,近年来在机器学习领域得到广泛应用。不同于传统的网格搜索或随机搜索,贝叶斯优化采用概率模型来预测最优超参数,然后选择最有可能改进模型性能的参数进行测试。这种方法特别适用于优化那些计算成本高、评估函数复杂或不透明的情况。在机器学习中,贝叶斯优化能够有效地辅助模型调优,加快算法收敛速度,提升最终性能。
接下来,我们将深入探讨贝叶斯优化的理论基础,包括它的工作原理以及如何在实际应用中进行操作。我们将首先介绍超参数调优的相关概念,并探讨传统方法的局限性。然后,我们将深入分析贝叶斯优化的数学原理,以及如何在实践中应用这些原理。通过对
【空间复杂度详解】:揭秘存储成本与算法优化的黄金法则
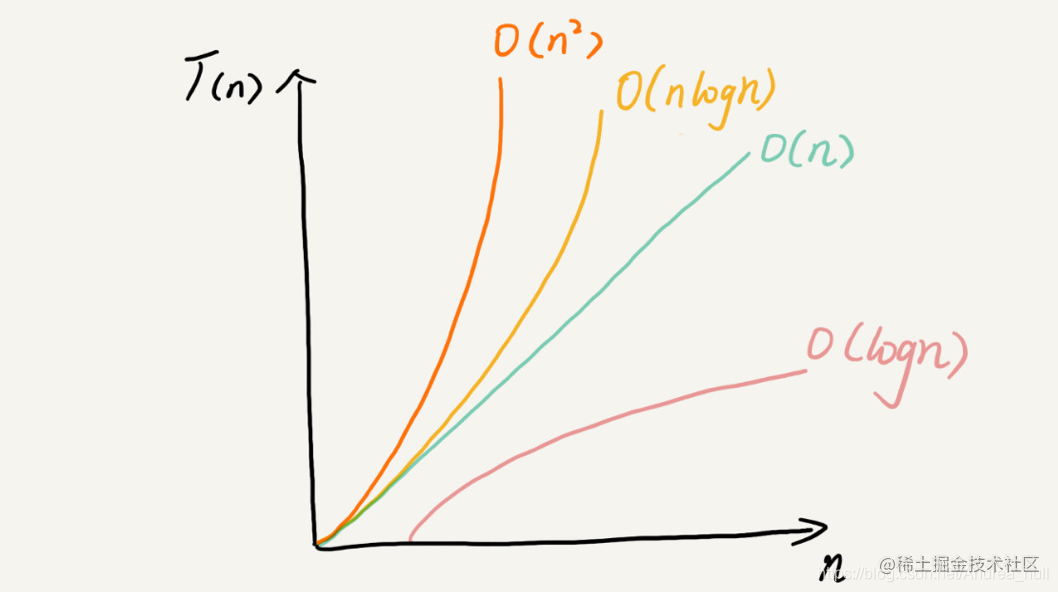
# 1. 空间复杂度的理论基础
在探讨高效算法时,时间复杂度和空间复杂度是衡量算法性能的两个重要指标。空间复杂度,尤其是,反映了算法执行过程中所需的最大内存空间。理解空间复杂度的基础理论对于任何从事IT行业,尤其是软件开发、系统架构、数据分析的专业人士至关重要。
## 1.1 空间复杂度的定义
空间复杂度(Space Complexity)通常被定义为算法在运行过程中临时占
时间序列分析的置信度应用:预测未来的秘密武器
# 1. 时间序列分析的理论基础
在数据科学和统计学中,时间序列分析是研究按照时间顺序排列的数据点集合的过程。通过对时间序列数据的分析,我们可以提取出有价值的信息,揭示数据随时间变化的规律,从而为预测未来趋势和做出决策提供依据。
## 时间序列的定义
时间序列(Time Series)是一个按照时间顺序排列的观测值序列。这些观测值通常是一个变量在连续时间点的测量结果,可以是每秒的温度记录,每日的股票价
模型参数泛化能力:交叉验证与测试集分析实战指南

# 1. 交叉验证与测试集的基础概念
在机器学习和统计学中,交叉验证(Cross-Validation)和测试集(Test Set)是衡量模型性能和泛化能力的关键技术。本章将探讨这两个概念的基本定义及其在数据分析中的重要性。
## 1.1 交叉验证与测试集的定义
交叉验证是一种统计方法,通过将原始数据集划分成若干小的子集,然后将模型在这些子集上进行训练和验证,以
探索与利用平衡:强化学习在超参数优化中的应用
# 1. 强化学习与超参数优化的交叉领域
## 引言
随着人工智能的快速发展,强化学习作为机器学习的一个重要分支,在处理决策过程中的复杂问题上显示出了巨大的潜力。与此同时,超参数优化在提高机器学习模型性能方面扮演着关键角色。将强化学习应用于超参数优化,不仅可实现自动化,还能够通过智能策略提升优化效率,对当前AI领域的发展产生了深远影响。
## 强化学习与超参数优化的关系
强化学习能够通过与环境的交互来学
极端事件预测:如何构建有效的预测区间
# 1. 极端事件预测概述
极端事件预测是风险管理、城市规划、保险业、金融市场等领域不可或缺的技术。这些事件通常具有突发性和破坏性,例如自然灾害、金融市场崩盘或恐怖袭击等。准确预测这类事件不仅可挽救生命、保护财产,而且对于制定应对策略和减少损失至关重要。因此,研究人员和专业人士持
【Python预测模型构建全记录】:最佳实践与技巧详解
# 1. Python预测模型基础
Python作为一门多功能的编程语言,在数据科学和机器学习领域表现得尤为出色。预测模型是机器学习的核心应用之一,它通过分析历史数据来预测未来的趋势或事件。本章将简要介绍预测模型的概念,并强调Python在这一领域中的作用。
## 1.1 预测模型概念
预测模型是一种统计模型,它利用历史数据来预测未来事件的可能性。这些模型在金融、市场营销、医疗保健和其
【目标变量优化】:机器学习中因变量调整的高级技巧
# 1. 目标变量优化概述
在数据科学和机器学习领域,目标变量优化是提升模型预测性能的核心步骤之一。目标变量,又称作因变量,是预测模型中希望预测或解释的变量。通过优化目标变量,可以显著提高模型的精确度和泛化能力,进而对业务决策产生重大影响。
## 目标变量的重要性
目标变量的选择与优化直接关系到模型性能的好坏。正确的目标变量可以帮助模
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )