Fluentd的可扩展架构设计
发布时间: 2024-12-13 17:58:18 阅读量: 7 订阅数: 17 

架构设计思路样例.zip
参考资源链接:[Fluent入门指南:理解和应用shadow面及初始化策略](https://wenku.csdn.net/doc/63yh5d3q83?spm=1055.2635.3001.10343)
# 1. Fluentd简介与基础架构
## 1.1 Fluentd简介
Fluentd是一个开源的数据收集器,用于统一日志层。它能够将分散在多台服务器上的数据统一收集、处理、输出到各种存储系统中。Fluentd的设计目标是实现数据的一致性和可扩展性,这对于运维管理和数据分析来说至关重要。其设计灵感来源于Ruby语言的简洁和灵活性,以及现代Web应用数据流的复杂性。
## 1.2 基础架构
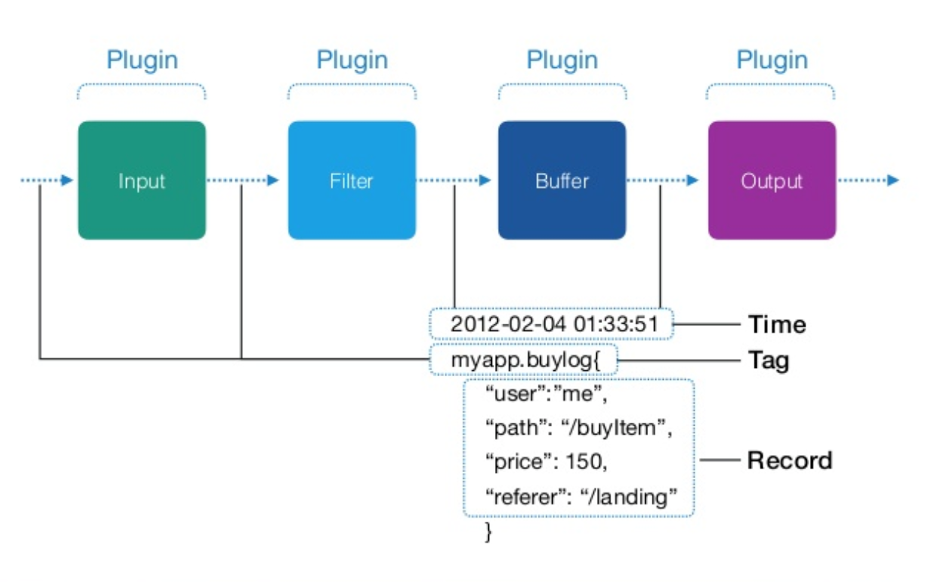
Fluentd的基础架构包含三个主要组件:输入(input)、解析器(parser)、输出(output)。输入插件负责收集数据,解析器负责解析数据格式,输出插件则将处理后的数据发送到指定的目的地,如文件、数据库或者消息队列系统。Fluentd支持丰富的插件,可以实现多种数据源和存储系统之间的无缝对接。架构设计上,Fluentd具备自我诊断、日志记录和缓冲机制,保证了数据传输的可靠性和稳定性。
## 1.3 核心优势
Fluentd的核心优势在于它的灵活性和扩展性。开发者可以轻易地通过插件系统来扩展Fluentd的功能,以适应不断变化的数据源和数据处理需求。此外,Fluentd采用集中式配置管理,使得系统管理更加方便。其内存中JSON对象处理方式提供了高效的数据处理能力。整体而言,Fluentd为日志收集提供了一个统一、可扩展且高性能的解决方案。
# 2. Fluentd核心组件深入解析
## 2.1 Fluentd的数据模型
### 2.1.1 记录结构与消息格式
Fluentd的数据模型是其核心特性之一,允许用户以统一的方式处理日志数据。Fluentd采用的是JSON格式作为其记录结构的基础,这对于任何熟悉JSON的开发者来说都是一个好消息,因为它提供了灵活性和可扩展性。
在Fluentd中,每条记录被称作事件(event),它由两个主要部分组成:
- **标签(Tag)**:标识事件来源的唯一字符串,通常遵循“领域.来源.级别”的结构,例如 `app.retail.error`。它告诉Fluentd如何处理该事件。
- **消息(Message)**:包含数据的JSON对象。例如:
```json
{
"level": "error",
"message": "Failed to connect to the database",
"timestamp": "2023-03-15T15:44:27.000Z"
}
```
在Fluentd内部,所有的数据都以记录形式处理,使得插件之间可以无缝地传递数据,而无需关心数据的格式细节。这种设计使得Fluentd非常适合处理多样化的日志数据,这些数据可以来自各种不同的来源,比如应用程序、操作系统和网络服务等。
### 2.1.2 标签和插件系统
标签系统是Fluentd最为核心的部分之一。每个数据流都有一个标签,Fluentd通过这个标签来决定如何处理数据。标签不仅可以用来过滤,还能指定数据的流向。标签使得Fluentd能够以非常灵活的方式路由数据。
Fluentd的插件系统与其标签系统紧密结合。Fluentd插件大致可以分为三类:
- **输入插件(Input Plugins)**:负责收集数据并生成事件。
- **输出插件(Output Plugins)**:负责处理并发送事件到目的地。
- **过滤插件(Filter Plugins)**:用于处理和修改数据,常在输入和输出插件之间使用。
Fluentd的插件生态系统非常丰富,几乎可以满足所有日志处理场景的需求。此外,Fluentd的插件是独立的,可以根据需要单独加载或卸载,这为Fluentd带来了强大的可扩展性。
## 2.2 Fluentd的输入与输出机制
### 2.2.1 输入插件的工作原理
Fluentd的输入插件工作在数据采集阶段,它们负责从各种数据源(如文件、网络服务或应用程序)收集数据,并将其封装成事件。每个输入插件通常会监听一个或多个端口,以接收外部事件,或者定期扫描文件以获取新的日志条目。
对于输入插件来说,关键在于能够高效地从其源获取数据,并准确地将其转换为Fluentd期望的JSON格式。例如,假设我们有一个日志文件,我们希望Fluentd监控该文件并将新行作为事件发送。使用 `tail` 输入插件,配置可能如下所示:
```xml
<source>
@type tail
path /var/log/myapp.log
pos_file /var/log/myapp.log.pos
format json
tag app.myapp
</source>
```
这里,我们告诉 `tail` 插件监听 `/var/log/myapp.log` 文件。每当新行被添加到文件时,`tail` 插件就会读取该行,并将其作为JSON格式的数据事件发出,`app.myapp` 标签会指示这条事件的来源和上下文。
### 2.2.2 输出插件的策略与优化
输出插件位于数据处理流程的末端,它们的职责是将事件传输到最终目的地。这可能是一个数据库、另一个日志聚合系统或任何其他类型的数据存储。
Fluentd输出插件的工作策略依赖于它所连接的系统。例如,当我们使用 `forward` 输出插件将数据发送到其他Fluentd实例时,Fluentd会将数据封装成二进制格式,并通过TCP连接发送,以确保高效传输。
在性能优化方面,输出插件提供了多种配置选项。例如,Fluentd的缓冲机制允许输出插件在遇到暂时性的网络问题时,不会丢失事件。此外,输出插件通常支持缓冲区配置,如内存缓冲和磁盘缓冲,并且可以根据需要选择合适的策略。
```xml
<match app.myapp>
@type forward
send_timeout 60s
buffer_type file
buffer_path /var/log/fluentd-buffers/app.myapp.buffer
flush_interval 10s # 默认情况下,每个缓冲区都会在10秒后刷新。
</match>
```
在上述配置中,我们配置了 `forward` 输出插件,它通过网络将 `app.myapp` 标签的事件发送到其他节点,并且具有缓冲区配置,允许事件在达到目的地之前暂时存储在磁盘上。
## 2.3 Fluentd的缓冲与重试机制
### 2.3.1 缓冲区配置与管理
Fluentd的缓冲机制是确保数据可靠传输的关键。当输出插件无法将数据直接发送到目的地时(比如因为网络问题),缓冲机制就会介入,数据会被暂存起来,直到可以发送。
缓冲机制主要通过两种类型的缓冲区来实现:内存缓冲和磁盘缓冲。内存缓冲速度快,但容量有限,并且在系统崩溃时会丢失数据;磁盘缓冲慢一些,但提供了数据持久性,即使在Fluentd重启的情况下也能保证数据不丢失。
```xml
<buffer tag>
@type file
path /var/log/fluentd/buffer/tag
chunk_limit_size 2M
flush_at_shutdown true
</buffer>
```
在该配置中,我们为特定标签配置了一个文件缓冲区,设置了缓冲大小限制和在关闭时刷新缓冲区的选项。
### 2.3.2 重试逻辑和故障转移
Fluentd的重试逻辑确保了当数据传输失败时,数据不会轻易丢失。Fluentd的输出插件有内置的重试机制,可以根据配置的重试次数和重试间隔,自动尝试重新发送失败的数据。
在处理连续的重试失败后,Fluentd还支持故障转移机制,即当一个输出目标失败时,Fluentd可以尝试将数据发送到另一个预设的输出目标。这

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**Fluent 帮助文档**专栏提供全面的指南和深入分析,涵盖 Fluent 框架的各个方面。它深入探讨了 Fluent 与传统日志系统的性能差异,并提供了从头开始构建企业级日志系统的分步指南。专栏还涵盖了 Fluentd 的高级配置技巧、与 ELK 的比较以及最佳实践。此外,它还探讨了微服务架构中的 Fluentd 应用、大数据扩展性分析和数据处理流程。专栏还深入研究了 Fluentd 与消息队列的集成、插件生态系统、日志备份和恢复,以及在容器化环境和云服务提供商中的部署策略。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ECOTALK案例研究:揭秘企业数字化转型的5个关键成功因素
# 摘要
企业数字化转型已成为推动现代商业发展的核心战略,本文全面概述了数字化转型的理论基础与实践应用。通过对转型定义、理论模型和成功关键因素的深入分析,探讨了ECOTALK公司在数字化转型过程中的背景、目标、策略和成效。文章强调了组织文化、技术创新、人才培养在转型中的重要性,并通过案例分析,展示了如何将理论与实践相结合,有效推进企业数字化进程。总结与展望部分提供了经验教训,并对数字化
事务管理关键点:确保银企直连数据完整性的核心技术

# 摘要
本文深入探讨了事务管理的基本概念、银企直连数据完整性的挑战以及核心技术在事务管理中的应用,同时分析了确保数据完整性的策略,并对事务管理技术的发展趋势进行了展望。文章详细阐述了事务管理的重要性,特别是理解ACID原则在银企直连中的作用,以及分布式事务处理和数据库事务隔离级别等核心技术的应用。此外,本文还讨论了事务日志与数据备份、并发控制与锁定机制,以及测试与性能调优
从零开始构建BMP图像编辑器:框架搭建与核心功能实现

# 摘要
本论文首先介绍了BMP图像格式的基础知识,随后详细阐述了一个图像编辑器软件框架的设计,包括软件架构、用户界面(GUI)和核心功能模块的划分。接着,论文重点介绍了BMP图像处理算法的实现,涵盖基本图像处理概念、核心功能编码以及高级图像处理效果如灰度化、反色和滤镜等。之后,本文讨论了文件操作与数据管理,特别是BMP文件格式的解析处理和高级文件操作的技术实现。在测试
【Linux内核优化】:提升Ubuntu系统性能的最佳实践
# 摘要
随着技术的发展,Linux操作系统内核优化成为提升系统性能和稳定性的关键。本文首先概述了Linux内核优化的基本概念和重要性。随后深入探讨了Linux内核的各个组成部分,包括进程管理、内存管理以及文件系统等,并介绍了内核模块的管理方法。为了进一步提升系统性能,文章分析了性能监控和诊断工具的使用,阐述了系统瓶颈诊断的策略,以及系统日志的分析方法。接着,文章着重讲解了内核参数的调整和优化,包
【设备校准与维护】:保障光辐射测量设备精确度与可靠性的秘诀

# 摘要
光辐射测量设备在科研及工业领域扮演着至关重要的角色,其准确性和稳定性直接关系到研究和生产的结果质量。本文首先概述了光辐射测量设备的重要性,随后深入探讨了设备校准的理论基础,包括校准的概念、目的、方法以及校准流程与标准。在设备校准的实践操作章节中,文章详细描述了校准前的准备工作、实际操作
谢菲尔德遗传工具箱全面入门指南:0基础也能快速上手

# 摘要
谢菲尔德遗传工具箱是一个综合性的遗传学分析软件,旨在为遗传学家和生物信息学家提供强大的数据分析和处理能力。本文首先介绍该工具箱的理论基础,包括遗传学的基本原理和基因组的结构。随后,本文阐述了谢菲尔德遗传工具箱的构建理念、核心算法和数据结构,以及其在遗传数据分析和生物信息学研究中的应用。接着,文章详细说明了工具箱的安装与配置过程,包括系统要求、安装步骤和验证方法。核心功能部分
【TDD提升代码质量】:智能编码中的测试驱动开发(TDD)策略

# 摘要
测试驱动开发(TDD)是一种软件开发方法,强调编写测试用例后再编写满足测试的代码,并不断重构以提升代码质量和可维护性。本文全面概述了TDD,阐述了其理论基础、实践指南及在项目中的应用案例,并分析了TDD带来的团队协作和沟通改进。文章还探讨了TDD面临的挑战,如测试用例的质量控制和开发者接受度,并展望了TDD在持续集成、敏捷开发和DevOps中的未来趋势及
《符号计算与人工智能的交汇》:Mathematica在AI领域的无限潜力
# 摘要
本论文旨在探讨符号计算与人工智能的融合,特别是Mathematica平台在AI领域的应用和潜力。首先介绍了符号计算与人工智能的基本概念,随后深入分析了Mathematica的功能、符号计算的原理及其优势。接着,本文着重讨论了Mathematica在人工智能中的应用,包括数据处理、机器学习、模式识别和自然语言处理等方面。此外,论文还阐述了Mathematica在解决高级数学问题、AI算法符号化实现以及知识表达与推理方
openTCS 5.9 与其他自动化设备的集成指南:无缝对接,提升效率

# 摘要
本文全面概述了openTCS 5.9在自动化设备集成中的应用,着重介绍了其在工业机器人和仓库管理系统中的实践应用。通过理论基础分析,深入探讨了自
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )