【机器翻译】:技术原理与挑战——R085深度剖析
发布时间: 2024-12-14 09:39:58 阅读量: 8 订阅数: 18 

毕业设计:数据库原理课程设计——毕业设计管理系统.zip
参考资源链接:[【R085】自然语言处理导论【张奇&桂韬&黄萱菁】.pdf](https://wenku.csdn.net/doc/6o0isosga3?spm=1055.2635.3001.10343)
# 1. 机器翻译的技术背景与演变
## 1.1 翻译技术的起源
机器翻译的概念可追溯至20世纪40年代末期,当时提出了利用计算机进行语言自动翻译的想法。1954年,IBM成功地使用计算机进行了俄语到英语的翻译,尽管翻译结果并不理想,但这标志着机器翻译技术正式诞生。
## 1.2 从规则翻译到统计方法
早期的机器翻译依赖于规则和字典。随着计算能力的提高,20世纪90年代引入了基于统计的翻译方法,这些方法通过对大量双语语料库的统计分析,来提高翻译的准确性和流畅性。
## 1.3 神经机器翻译的崛起
近年来,神经网络技术的突破性进展,特别是Transformer模型的出现,开启了机器翻译的新篇章。神经机器翻译(NMT)通过一个端到端的模型架构,实现了对自然语言语义的更好理解,从而极大提升了翻译的质量。这种自回归模型不仅提高了翻译的准确度,还加快了翻译速度,使得实时翻译成为可能。
机器翻译技术的演变体现了人工智能领域计算能力、算法理论以及大数据处理能力的不断提升,目前它已成为多语言交流和全球化沟通的重要工具。在下一章,我们将深入探讨机器翻译的理论基础,从数学模型到深度学习方法,进一步理解这一技术的演进路径。
# 2. 机器翻译的理论基础
## 2.1 翻译模型的数学基础
### 2.1.1 统计机器翻译模型
统计机器翻译(Statistical Machine Translation, SMT)是机器翻译领域的开创性工作之一,其基于概率论和统计学原理,通过统计大量的双语文本(平行语料库)来建立翻译模型。SMT的核心思想是寻找目标语言中的句子,使它与源语言句子的翻译概率最大化。翻译概率通常用翻译模型和语言模型的乘积来表示。
传统统计机器翻译主要涉及三个模型:
- **语言模型**:估计目标语言文本的自然度,即一个句子在目标语言中出现的概率。
- **翻译模型**:估算从源语言到目标语言的翻译对齐概率。
- **解码器**:负责找到最佳的翻译输出。
参数包括词汇对齐概率、短语翻译概率、以及语言模型的概率。这些参数通过训练数据集估计得到,这个过程中主要采用期望最大化(EM)算法来迭代地改进模型参数。
代码块展示一个简单的统计机器翻译模型实现的框架:
```python
import nltk
from nltk.translate import AlignmentModel, IBMModel1, IBMModel2
# 训练语料库准备
source_sentences = [...] # 源语言句子列表
target_sentences = [...] # 目标语言句子列表
parallel_corpus = list(zip(source_sentences, target_sentences))
# 训练IBM Model 1翻译模型
model1 = IBMModel1(parallel_corpus)
print(model1)
# 训练IBM Model 2翻译模型
model2 = IBMModel2(parallel_corpus)
print(model2)
# 评估模型的翻译质量(这里假设我们有一些参考译文)
references = [...] # 参考译文句子列表
hypotheses = [...] # 翻译模型生成的译文句子列表
# 使用BLEU评分进行评估
score = nltk.translate.bleu_score.sentence_bleu(references, hypotheses)
print('BLEU score:', score)
```
逻辑分析和参数说明:
- `source_sentences` 和 `target_sentences` 分别包含源语言和目标语言的句子。
- `parallel_corpus` 是通过`zip`函数组合的平行语料库。
- `IBMModel1` 和 `IBMModel2` 分别表示基于IBM模型1和IBM模型2的翻译模型。
- `references` 和 `hypotheses` 分别是参考译文和假设译文的句子列表。
- `bleu_score.sentence_bleu` 函数用于计算单个句子的BLEU分数,反映翻译质量。
### 2.1.2 神经机器翻译模型
神经机器翻译(Neural Machine Translation, NMT)利用深度神经网络来学习源语言和目标语言之间的映射关系。与SMT相比,NMT在处理长距离依赖、词汇歧义和语序调整等问题上有更好的表现。NMT模型通常基于序列到序列(seq2seq)的架构,使用循环神经网络(RNN)或者最近的Transformer架构。
seq2seq模型包含两个主要部分:编码器(Encoder)和解码器(Decoder)。编码器将源语言句子编码成一个上下文向量,解码器则根据这个上下文向量生成目标语言的翻译。
一个基本的NMT模型实现可能包含以下几个步骤:
1. 预处理数据,包括分词、构建词汇表、生成输入输出的索引。
2. 构建编码器和解码器网络结构。
3. 使用训练数据训练模型,通常采用梯度下降优化算法。
4. 使用测试数据评估模型性能,采用BLEU等评价标准。
代码块演示一个基于TensorFlow的简单NMT模型结构:
```python
import tensorflow as tf
from tensorflow.keras.layers import Input, LSTM, Embedding, Dense, Concatenate
from tensorflow.keras.models import Model
# 定义编码器
encoder_inputs = Input(shape=(None,))
enc_emb = Embedding(input_dim=source_vocab_size, output_dim=embedding_dim)(encoder_inputs)
encoder_lstm = LSTM(units=hidden_units)
encoder_outputs, state_h, state_c = encoder_lstm(enc_emb)
# 定义解码器
decoder_inputs = Input(shape=(None,))
dec_emb = Embedding(input_dim=target_vocab_size, output_dim=embedding_dim)
dec_lstm = LSTM(units=hidden_units)
decoder_embedding = dec_emb(decoder_inputs)
decoder_outputs, _, _ = dec_lstm(decoder_embedding, initial_state=[state_h, state_c])
# 使用一个全连接层实现输出层
decoder_dense = Dense(target_vocab_size, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
# 构建模型
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
# 准备训练数据...
# 训练模型...
```
参数说明:
- `source_vocab_size` 是源语言词汇表的大小。
- `target_vocab_size` 是目标语言词汇表的大小。
- `embedding_dim` 是嵌入向量的维度。
- `hidden_units` 是编码器和解码器中LSTM层的隐藏单元数。
- `encoder_inputs` 和 `decoder_inputs` 分别代表编码器和解码器的输入。
- `encoder_lstm` 和 `dec_lstm` 分别代表编码器和解码器使用的LSTM层。
## 2.2 理解语言的机器学习方法
### 2.2.1 语言模型和序列建模
语言模型是评估给定词语序列合理性的概率模型。在机器翻译中,语言模型用于估计生成的目标语言句子的自然性。序列建模,如循环神经网络(RNN)、长短期记忆网络(LSTM)和门控循环单元(GRU),被广泛用于处理文本数据,因为它们能够考虑词序列的前后文关系。
语言模型训练时需要输入大量的目标语言单语语料库。训练目标是最大化正确词序列的概率,常见的方法有n-gram模型、隐马尔可夫模型(HMM)和神经网络语言模型。
代码块展示一个简单的n-gram语言模型:
```python
from nltk.lm.preprocessing import padded_everygram_pipeline
from nltk.lm.Models import MLE
from nltk.tokenize import word_tokenize
# 准备数据
text = "your training text goes here"
tokens = word_tokenize(text)
n = 2 # n-gram order
train_data, padded_sents = padded_everygram_pipeline(n, tokens)
# 训练语言模型
lm = MLE(n)
lm.fit(train_data, vocabulary(tokens))
# 生成下文
context = "How are".split()
print(lm.generate(3, context))
```
参数说明:
- `n` 表示n-gram模型的阶数。
- `tokens` 是词序列的列表。
- `train_data` 是根据输入数据生成的n-gram模型训练数据。
- `lm` 是训练得到的语言模型实例。
### 2.2.2 表示学习与嵌入技术
单词嵌入(Word Embeddings)是将单词转换为稠密向量的技术,向量位于多维空间中,其中语义或语境相似的单词在空间中的距离较近。嵌入向量可以有效地表示单词或短语,为机器翻译模型提供了丰富的语义信息。
常见的词嵌入模型包括Word2Vec、GloVe和FastText。这些模型通过学习大量的文本数据,能够捕获词汇之间的复杂关系。比如Word2Vec模型利用上下文窗口来预测词与词之间的关系,而GloVe模型则是在整个语料库上进行词共现的统计学习。
表格呈现三种词嵌入模型的比较:
| 特征 | Word2Vec | GloVe | FastText |
| --- | --- | --- | --- |
| 底层技术 |

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“【R085】自然语言处理导论”是一份全面的自然语言处理(NLP)入门指南,由张奇、桂韬和黄萱菁共同撰写。专栏深入探讨了 NLP 的基础知识,包括词汇语义相似度、对话系统、知识图谱构建和问答系统构建。它还展示了 NLP 在金融服务、法律文档分析和自然语言生成等行业的实际应用。通过深入浅出的讲解和丰富的案例,该专栏旨在帮助 NLP 新手快速掌握这项技术,并将其应用于各种现实世界场景中。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
理解SN29500-2010:IT专业人员的标准入门手册

# 摘要
SN29500-2010标准作为行业规范,对其核心内容和历史背景进行了概述,同时解析了关键条款,如术语定义、管理体系要求及信息安全技术要求等。本文还探讨了如何在实际工作中应用该标准,包括推广策略、员工培训、监督合规性检查,以及应对标准变化和更新的策略。文章进一步分析了SN29500-2010带来的机遇和挑战,如竞争优势、技术与资源
红外遥控编码:20年经验大佬揭秘家电控制秘籍
# 摘要
红外遥控技术作为无线通信的重要组成部分,在家电控制领域占有重要地位。本文从红外遥控技术概述开始,详细探讨了红外编码的基础理论,包括红外通信的原理、信号编码方式、信号捕获与解码。接着,本文深入分析了红外编码器与解码器的硬件实现,以及在实际编程实践中的应用。最后,本文针对红外遥控在家电控制中的应用进行了案例研究,并展望了红外遥控技术的未来趋势与创新方向,特别是在智能家居集成和技术创新方面。文章旨在为读者提
【信号完整性必备】:7系列FPGA SelectIO资源实战与故障排除
# 摘要
随着数字电路设计复杂度的提升,FPGA(现场可编程门阵列)已成为实现高速信号处理和接口扩展的重要平台。本文对7系列FPGA的SelectIO资源进行了深入探讨,涵盖了其架构、特性、配置方法以及在实际应用中的表现。通过对SelectIO资源的硬件组成、电气标准和参数配置的分析,本文揭示了其在高速信号传输和接口扩展中的关键作用。同时,本文还讨论了信号完整性
C# AES加密:向量化优化与性能提升指南
# 摘要
本文深入探讨了C#中的AES加密技术,从基础概念到实现细节,再到性能挑战及优化技术。首先,概述了AES加密的原理和数学基础,包括其工作模式和关键的加密步骤。接着,分析了性能评估的标准、工具,以及常见的性能瓶颈,着重讨论了向量化优化技术及其在AES加密中的应用。此外,本文提供了一份实践指南,包括选择合适的加密库、性能优化案例以及在安全性与性能之间寻找平衡点的策略。最后,展望了AES加密技术的未来趋势,包括新兴加密算法的演进和性能优化的新思路。本研究为C#开发者在实现高效且安全的AES加密提供了理论基础和实践指导。
# 关键字
C#;AES加密;对称加密;性能优化;向量化;SIMD指令
RESTful API设计深度解析:Web后台开发的最佳实践

# 摘要
本文全面探讨了RESTful API的设计原则、实践方法、安全机制以及测试与监控策略。首先,介绍了RESTful API设计的基础知识,阐述了核心原则、资源表述、无状态通信和媒体类型的选择。其次,通过资源路径设计、HTTP方法映射到CRUD操作以及状态码的应用,分析了RESTful API设计的具体实践。
【Buck电路布局绝招】:PCB设计的黄金法则
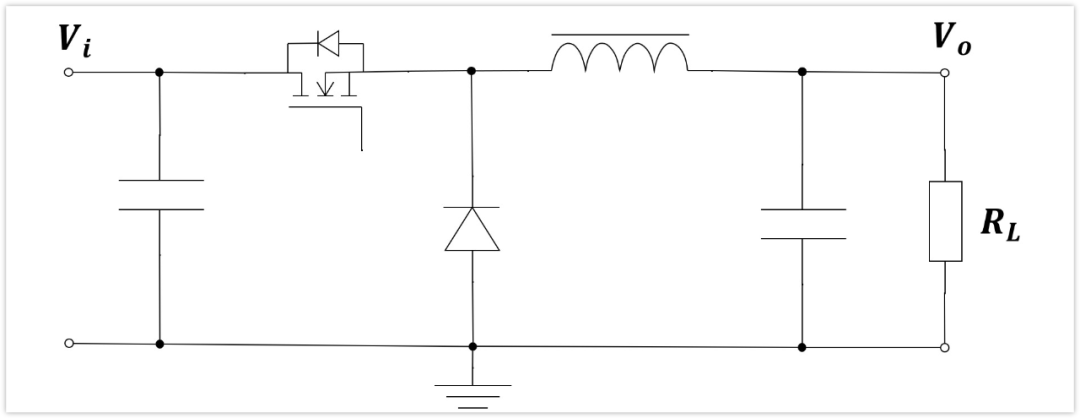
# 摘要
Buck转换器是一种广泛应用于电源管理领域的直流-直流转换器,它以高效和低成本著称。本文首先阐述了Buck转换器的工作原理和优势,然后详细分析了Buck电路布局的理论基础,包括关键参数、性能指标、元件选择、电源平面设计等。在实践技巧方面,本文提供了一系列提高电路布局效率和准确性的方法,并通过案例分析展示了低噪声、高效率以及小体积高功率密度设计的实现。最后,本文展望了Buck电
揭秘苹果iap2协议:高效集成与应用的终极指南
# 摘要
本文系统介绍了IAP2协议的基础知识、集成流程以及在iOS平台上的具体实现。首先,阐述了IAP2协议的核心概念和环境配置要点,包括安装、配置以及与iOS系统的兼容性问题。然后,详细解读了IAP2协议的核心功能,如数据交换模式和认证授权机制,并通过实例演示了其在iOS应用开发和数据分析中的应用技巧。此外,文章还探讨了IAP2协议在安全、云计算等高级领域的应用原理和案例,以及性能优化的方法和未来发展的方向。最后,通过大
ATP仿真案例分析:故障相电压波形A的调试、优化与实战应用
# 摘要
本文对ATP仿真软件及其在故障相电压波形A模拟中的应用进行了全面介绍。首先概述了ATP仿真软件的发展背景与故障相电压波形A的理论基础。接着,详细解析了模拟流程,包括参数设定、步骤解析及结果分析方法。本文还深入探讨了调试技巧,包括ATP仿真环境配置和常见问题的解决策略。在此基础上,提出了优化策略,强调参数优化方法和提升模拟结果精确性的重要性。最后,通过电力系统的实战应用案例,本文展示了故障分析、预防与控制策略的实际效果,并通过案例研究提炼出有价值的经验与建议。
# 关键字
ATP仿真软件;故障相电压波形;模拟流程;参数优化;故障预防;案例研究
参考资源链接:[ATP-EMTP电磁暂
【流式架构全面解析】:掌握Kafka从原理到实践的15个关键点

# 摘要
流式架构作为处理大数据的关键技术之一,近年来受到了广泛关注。本文首先介绍了流式架构的概念,并深入解析了Apache Kafka作为流式架构核心组件的引入背景和基础知识。文章深入探讨了Kafka的架构原理、消息模型、集群管理和高级特性,以及其在实践中的应用案例,包括高可用集群的实现和与大数据生态以及微
【SIM卡故障速查速修秘籍】:10分钟内解决无法识别问题

# 摘要
本文旨在为读者提供一份全面的SIM卡故障速查速修指导。首先介绍了SIM卡的工作原理及其故障类型,然后详细阐述了故障诊断的基本步骤和实践技巧,包括使用软件工具和硬件检查方法。本文还探讨了常规和高级修复策略,以及预防措施和维护建议,以减少SIM卡故障的发生。通过案例分析,文章详细说明了典型故障的解决过程。最后,展望了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )