Python网络编程实战:深入理解网络编程原理,构建网络应用
发布时间: 2024-06-17 17:27:06 阅读量: 59 订阅数: 28 

Python网络编程实战.zip

# 1. Python网络编程基础**
Python网络编程是利用Python语言开发与网络相关的应用。本章将介绍网络编程的基础知识,包括:
- **网络模型:**了解客户端-服务器模型、TCP/IP协议栈和HTTP协议。
- **Socket编程:**掌握Socket编程的基本概念,包括套接字类型、地址和端口。
- **网络安全:**了解网络安全威胁,如中间人攻击和SQL注入,以及如何使用加密和身份验证来保护数据。
# 2. 网络编程理论与实践
### 2.1 网络协议和数据传输
#### 2.1.1 TCP/IP协议栈
TCP/IP(传输控制协议/网际协议)协议栈是一组分层网络协议,用于在互联网上进行数据传输。它定义了数据在不同网络设备和计算机之间传输的方式。
**TCP/IP协议栈结构:**
| 层次 | 协议 | 功能 |
|---|---|---|
| 应用层 | HTTP、FTP、SMTP | 提供应用程序之间的通信 |
| 传输层 | TCP、UDP | 提供可靠或不可靠的数据传输 |
| 网络层 | IP、ICMP | 提供寻址和路由功能 |
| 数据链路层 | 以太网、Wi-Fi | 提供物理层连接 |
**TCP和UDP协议:**
* **TCP(传输控制协议):**面向连接、可靠的传输层协议,保证数据按序、无差错地传输。
* **UDP(用户数据报协议):**无连接、不可靠的传输层协议,提供低延迟、高吞吐量的数据传输。
#### 2.1.2 HTTP/HTTPS协议
HTTP(超文本传输协议)是用于在Web浏览器和Web服务器之间传输数据的应用层协议。
**HTTP请求与响应:**
* **HTTP请求:**客户端向服务器发送请求,指定要访问的资源和相关信息。
* **HTTP响应:**服务器处理请求并向客户端发送响应,包括状态代码、响应头和响应体。
**HTTPS协议:**
HTTPS(安全超文本传输协议)是HTTP协议的加密版本,使用SSL/TLS加密技术来保护数据传输。
### 2.2 网络编程技术
#### 2.2.1 Socket编程
Socket编程是网络编程的基础,允许应用程序通过网络进行通信。
**Socket概念:**
* **Socket:**一个网络端点,用于发送和接收数据。
* **Socket对:**两个连接的Socket,用于双向通信。
**Socket编程流程:**
1. 创建一个Socket。
2. 绑定Socket到一个地址和端口。
3. 监听Socket以接收连接。
4. 接受连接请求并创建新的Socket。
5. 发送和接收数据。
6. 关闭Socket。
#### 2.2.2 HTTP请求与响应
HTTP请求和响应可以通过Socket编程实现。
**HTTP请求代码示例:**
```python
import socket
# 创建Socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 绑定Socket
sock.bind(('127.0.0.1', 8080))
# 监听Socket
sock.listen(5)
# 接受连接
conn, addr = sock.accept()
# 发送HTTP请求
request = 'GET / HTTP/1.1\r\nHost: www.example.com\r\n\r\n'
conn.send(request.encode())
# 接收HTTP响应
response = conn.recv(1024)
print(response.decode())
# 关闭连接
conn.close()
```
**HTTP响应代码示例:**
```python
# 构建HTTP响应
response = 'HTTP/1.1 200 OK\r\nContent-Type: text/html\r\n\r\n<h1>Hello, world!</h1>'
# 发送HTTP响应
conn.send(response.encode())
```
### 2.3 网络安全与加密
#### 2.3.1 SSL/TLS加密
SSL(安全套接字层)和TLS(传输层安全)是加密协议,用于在网络传输中保护数据。
**SSL/TLS加密流程:**
1. 客户端和服务器协商加密算法和密钥。
2. 客户端使用协商的密钥加密数据。
3. 服务器使用相同的密钥解密数据。
#### 2.3.2 防火墙和入侵检测
防火墙和入侵检测系统(IDS)是网络安全措施,用于防止未经授权的访问和检测恶意活动。
**防火墙:**
* 监视传入和传出流量。
* 根据预定义规则阻止或允许流量。
**入侵检测系统:**
* 分析网络流量以识别恶意活动。
* 触发警报或采取措施阻止攻击。
# 3. Python网络编程实战**
**3.1 Web开发**
**3.1.1 Flask框架简介**
Flask是一个轻量级、易于使用的Python Web框架,它提供了一组简洁的API,用于构建Web应用程序。Flask基于Werkzeug WSGI工具包和Jinja2模板引擎,它强调灵活性、可扩展性和可测试性。
**3.1.2 RESTful API设计**
RESTful API(Representational State Transferful Application Programming Interface)是一种遵循REST(表述性状态转移)架构风格的API。RESTful API使用HTTP方法(如GET、POST、PUT、DELETE)来操作资源,并返回资源的表述(通常是JSON或XML)。
**3.2 网络爬虫**
**3.2.1 Scrapy框架使用**
Scrapy是一个用于网络爬取的强大Python框架。它提供了一组全面的工具,用于提取网页中的数据,包括HTTP请求、网页解析和数据持久化。
**3.2.2 网页解析和数据提取**
网页解析涉及从HTML或XML文档中提取有意义的数据。Scrapy使用XPath或CSS选择器等技术来定位和提取特定信息。
**3.3 网络监控与管理**
**3.3.1 网络流量分析**
网络流量分析涉及收集和分析网络流量数据,以识别模式、趋势和异常情况。这对于网络性能优化、故障排除和安全监控至关重要。
**3.3.2 系统和网络性能监控**
系统和网络性能监控涉及跟踪和分析系统和网络指标,例如CPU利用率、内存使用情况、网络延迟和吞吐量。这有助于识别性能瓶颈和确保系统的正常运行。
**代码示例:**
```python
# Flask Web应用程序示例
from flask import Flask, render_template
app = Flask(__name__)
@app.route('/')
def home():
return render_template('home.html')
if __name__ == '__main__':
app.run()
```
**代码逻辑分析:**
这段代码使用Flask创建了一个简单的Web应用程序。它定义了一个路由'/',当用户访问该路由时,它将渲染'home.html'模板。
**参数说明:**
* app.route('/'): 将URL路径'/'与home()函数关联。
* render_template('home.html'): 渲染'home.html'模板,该模板可以包含HTML和Jinja2模板语法。
**Mermaid流程图:**
```mermaid
sequenceDiagram
participant User
participant Flask App
User->Flask App: HTTP GET /
Flask App->User: HTTP 200 OK
Flask App->User: HTML response
```
**流程图分析:**
此流程图描述了用户访问Flask应用程序时发生的交互。用户向Flask应用程序发送HTTP GET请求,Flask应用程序响应HTTP 200 OK并返回HTML响应。
# 4. Python网络编程进阶
### 4.1 并发编程与协程
#### 4.1.1 多线程和多进程
**多线程**
* **原理:**在单个进程内创建多个线程,每个线程共享相同的内存空间,但拥有独立的执行栈。
* **优点:**
* 充分利用CPU资源,提高程序并发性。
* 线程间切换开销较小。
* **缺点:**
* 共享内存可能导致数据竞争和死锁。
* 调试和维护难度较大。
**多进程**
* **原理:**创建多个独立的进程,每个进程拥有自己的内存空间和执行栈。
* **优点:**
* 进程间隔离性强,避免数据竞争和死锁。
* 调试和维护相对容易。
* **缺点:**
* 进程间切换开销较大。
* 资源占用较多。
#### 4.1.2 协程和异步编程
**协程**
* **原理:**一种轻量级的线程,可以暂停和恢复执行,而无需切换到其他线程。
* **优点:**
* 避免多线程切换开销。
* 提高程序并发性。
* **缺点:**
* 调试和维护难度较大。
**异步编程**
* **原理:**一种非阻塞的编程模型,当等待I/O操作完成时,程序不会阻塞,而是继续执行其他任务。
* **优点:**
* 充分利用CPU资源,提高程序响应速度。
* 减少线程或进程数量,降低资源占用。
* **缺点:**
* 编程模型复杂,需要使用回调函数或事件循环。
### 4.2 分布式系统与微服务
#### 4.2.1 分布式架构设计
**分布式架构**
* **原理:**将一个系统拆分为多个独立的组件,这些组件分布在不同的物理服务器或云平台上。
* **优点:**
* 提高系统可扩展性和可用性。
* 便于维护和升级。
* **缺点:**
* 增加系统复杂性和通信开销。
* 需要考虑分布式事务和一致性问题。
**分布式架构模式**
* **微服务架构:**将系统拆分为多个小而独立的服务,每个服务专注于特定的功能。
* **消息队列架构:**使用消息队列作为组件之间的通信机制,提高系统解耦性和并发性。
* **分布式数据库架构:**将数据存储在多个数据库节点上,提高数据可扩展性和容错性。
#### 4.2.2 微服务架构实践
**微服务架构**
* **原理:**将系统拆分为多个小而独立的服务,每个服务通过API进行通信。
* **优点:**
* 提高系统可扩展性、可用性和可维护性。
* 便于团队协作和敏捷开发。
* **缺点:**
* 增加系统复杂性和通信开销。
* 需要考虑服务发现、负载均衡和容错机制。
**微服务架构实践**
* **服务发现:**使用注册中心或服务网格发现和管理微服务。
* **负载均衡:**使用负载均衡器将请求分发到多个微服务实例。
* **容错机制:**使用熔断器、重试和超时机制提高微服务的容错性。
### 4.3 云计算与网络编程
#### 4.3.1 云平台网络服务
**云平台网络服务**
* **虚拟私有云(VPC):**提供一个隔离的虚拟网络,用于部署和管理云资源。
* **负载均衡器:**将流量分发到多个云资源,提高可用性和可扩展性。
* **防火墙:**控制进出云资源的流量,提高安全性。
* **内容分发网络(CDN):**将静态内容缓存到全球多个边缘节点,提高网站访问速度。
#### 4.3.2 云原生网络应用开发
**云原生网络应用开发**
* **无服务器架构:**使用云平台提供的无服务器函数,无需管理基础设施即可构建和部署网络应用。
* **容器化:**使用Docker或Kubernetes等容器技术,将网络应用打包为可移植的容器镜像。
* **微服务化:**将网络应用拆分为多个微服务,提高可扩展性和可维护性。
# 5. Python网络编程项目实战**
**5.1 构建一个简单的Web服务器**
构建一个简单的Web服务器是网络编程中的一个基础项目,它可以帮助你理解HTTP协议和服务器端的开发。以下是如何使用Python构建一个简单的Web服务器:
```python
import socket
# 创建一个TCP套接字
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 绑定套接字到一个地址和端口
server_socket.bind(('localhost', 8000))
# 监听传入连接
server_socket.listen(5)
while True:
# 接受一个传入连接
client_socket, client_address = server_socket.accept()
# 接收客户端请求
request = client_socket.recv(1024).decode('utf-8')
# 解析请求并生成响应
response = 'HTTP/1.1 200 OK\nContent-Type: text/html\n\n<h1>Hello, world!</h1>'
# 发送响应给客户端
client_socket.send(response.encode('utf-8'))
# 关闭客户端套接字
client_socket.close()
```
**5.2 开发一个网络爬虫爬取指定网站**
网络爬虫是一个自动化的程序,用于从网站上抓取和提取数据。以下是如何使用Python开发一个网络爬虫来爬取指定网站:
```python
import requests
from bs4 import BeautifulSoup
# 指定要爬取的网站URL
url = 'https://www.example.com'
# 发送HTTP GET请求并获取响应
response = requests.get(url)
# 解析HTML响应
soup = BeautifulSoup(response.text, 'html.parser')
# 提取数据
title = soup.find('title').text
links = [link['href'] for link in soup.find_all('a')]
# 打印结果
print(f'

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以 Python 语言为核心,涵盖自动化测试、数据处理、机器学习、Web 开发、网络编程、并发编程、大数据处理、人工智能、云计算、爬虫、图像处理、自然语言处理、数据可视化、设计模式、性能优化、安全编程、版本管理和异常处理等领域。通过一系列实战教程,旨在帮助读者掌握 Python 的自动化测试秘诀,提升测试效率;解锁 Python 自动化测试框架,节省测试时间;掌握 Python 数据处理利器,提升数据分析效率;从零开始构建机器学习模型,探索数据奥秘;打造动态交互网站,体验 Web 开发乐趣;深入理解网络编程原理,构建网络应用;解锁多线程和多进程,提升代码性能;掌握大数据处理技术,应对海量数据挑战;揭秘人工智能算法,探索智能世界;深入理解云计算概念,构建云上应用;掌握网络爬取技术,获取海量信息;探索图像处理算法,解锁图像奥秘;深入理解 NLP 技术,探索语言世界;掌握数据可视化利器,呈现数据洞察;深入理解设计模式,提升代码质量;揭秘 Python 性能瓶颈,提升代码效率;掌握安全编程技术,保障代码安全;深入理解版本控制,提升团队协作;掌握异常处理技巧,提升代码鲁棒性。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【高级应用技巧】:MPU-9250数据读取与处理优化秘籍
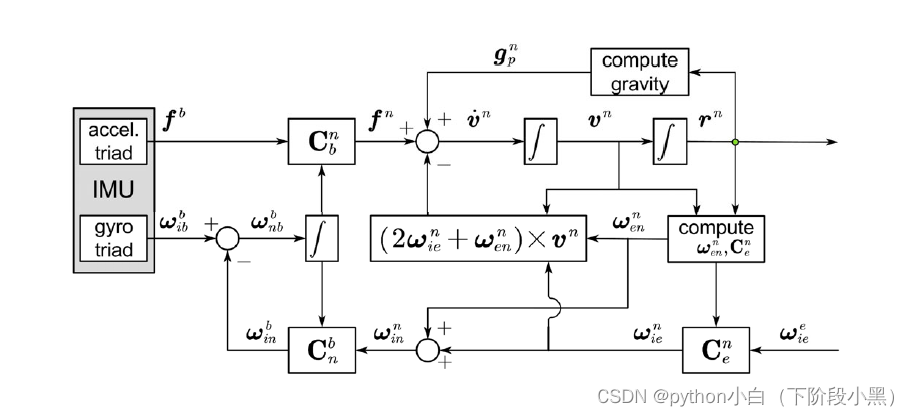
# 摘要
本文针对MPU-9250传感器的应用和数据处理进行了深入研究。首先概述了MPU-9250的特点及其在多个场景下的应用。其次,详细探讨了MPU-9250的数据读取原理、初始化流程、数据采集以及读取速度优化技巧。第三章重点介绍了数据处理技术,包括数字信号处理的基础知识、预处理技术和使用卡尔曼滤波器、离散傅里叶变换等高级滤波算法。接着,文章研究了MPU-9250在嵌入式系统集成时的选择标准、驱动
VW-80000-CN-2021-01中文文档回顾:技术革新下的行业影响与应对策略

# 摘要
随着技术革新,行业正经历前所未有的变革,新兴技术如人工智能、大数据分析以及物联网的融合为行业带来了显著的进步和创新。这些技术不仅在生产流程、决策支持、供应链优化等方面展现出巨大潜力,同时也引发了安全、人力资源和技术升级方面的挑战。未来技术趋势表明,云计算和边缘计算的融合
GDC2.4性能调优宝典:专家教你如何调整参数

# 摘要
本文全面探讨了GDC2.4性能调优的策略和实施过程,涵盖了理论基础、参数调整技巧、内存管理优化以及CPU与I/O性能优化。首先,文章对GDC2.4架构及其性能瓶颈进行了深入分析,并介绍了性能调优的基本原则和计划制定。随后,聚焦于参数调整,详细介绍了调优的准备、技巧以及性
数据词典设计原则:确保数据一致性和可追踪性的5大要点

# 摘要
数据词典在信息系统中扮演着至关重要的角色,它是定义数据元素属性及其关系的参考手册,对保障数据一致性、完整性和可追踪性具有核心作用。本文系统介绍了数据词典的基本概念及其在实践中的重要性,探讨了数据一致性的设计原则和实施要点,包括数据类型选择、数据完整性约束和元数据管理。此外,本文还深入分析了数据可追踪性的关键要素,如变更记录、数据流映射和数据质量控制。通过案例分析,本文展示了数据词典在数据模型构建、数据治理、数据安全和合规性方面的应用
Ansys命令流参数化设计:打造高效模拟的5个关键技巧

# 摘要
本文全面概述了Ansys命令流参数化设计,旨在为工程设计和仿真提供更高效、灵活的解决方案。首先介绍了参数化设计的概念、重要性以及与传统设计的比较,阐述了在工程模拟
变压器模型在ADS中的电磁兼容性考量

# 摘要
本文全面探讨了变压器电磁兼容性设计的核心问题,从变压器模型的构建到优化,再到仿真技术的应用以及未来发展趋势。首先介绍了ADS软件在变压器设计中的应用及其搭建模型的方法,强调了参数设置的精确性与模型仿真中电磁兼容性分析的重要性。其次,文章讨论了变压器设计的优化方法,强调了电磁兼容性测试和验证的实践意义,并通过案例研究
揭秘5G神经系统:RRC协议详解及其在无线通信中的关键作用

# 摘要
随着5G技术的商业化推广,无线资源控制(RRC)协议作为关键的无线通信协议,在资源管理、连接控制及信号传递方面扮演着至关重要的角色。本文首先对5G通信技术及RRC协议的基础知识进行了概述,详细介绍了RRC的角色、功能、状态模型以及消息类型和结构。随后,文章深入探讨了RR
高创伺服驱动器安装与维护:8个步骤确保系统稳定运行
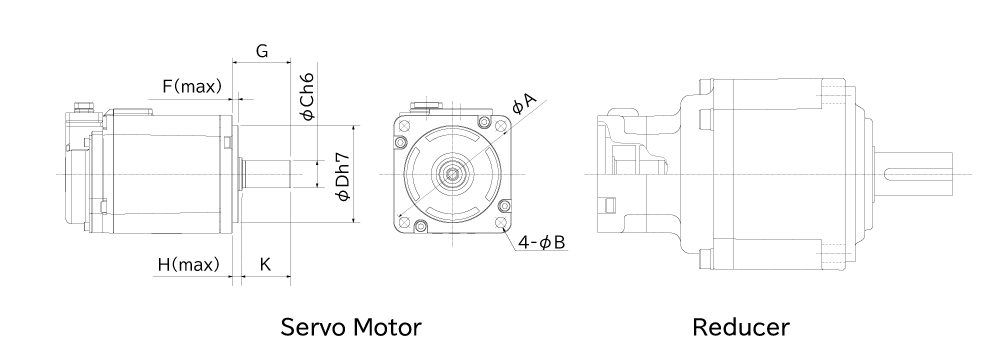
# 摘要
本文全面介绍了高创伺服驱动器的基础知识、安装、配置、调试、日常维护及故障预防。首先,概述了伺服驱动器选型和安装前的准备工作,包括硬件连接和安装环境要求。接着,深入探讨了伺服驱动器的配置参数、调试工具使用及故障诊断方法。然后,文中提出了日常维护要点、预防性维护措施和故障预防最佳实践。最后,通过具体应用案例,展示了伺服驱动器在不同场景下的性能优化和节能特性。本文为工程师和技术人员提供了一个系统性的指导,旨在提高伺服
微信小程序用户信息更新机制:保持数据时效性的核心技巧

# 摘要
微信小程序作为一种新型的移动应用形式,在用户信息管理上具备实时更新的需求,以保证用户体验和服务质量。本文全面探讨了微信小程序用户信息更新的各个方面,从理论基础到实践应用,从基本更新策略到性能优化
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )