【R语言速成课】:零基础到精通R语言的五大秘诀
发布时间: 2024-11-10 03:35:23 阅读量: 53 订阅数: 23 
# 1. R语言简介及安装配置
## 1.1 R语言起源与应用领域
R语言起源于1993年,由统计学家Ross Ihaka和Robert Gentleman共同开发。它是一款开源编程语言,广泛用于数据挖掘、统计分析、图形表示和报告制作。其强大的社区支持和丰富的包资源使得R语言成为数据科学领域的翘楚,尤其在学术研究和生物信息学中占有重要地位。
## 1.2 R语言环境安装配置
要在个人计算机上配置R语言环境,首先需访问R语言官方网站下载对应操作系统的最新版本安装包。安装完成后,推荐使用RStudio作为集成开发环境(IDE),它提供了更加友好的界面和便捷的功能,助你快速开始编程和数据分析工作。
## 1.3 初识R语言
打开R或RStudio,输入如下代码,执行后将得到R语言的版本信息,标志着安装配置成功:
```r
version
```
此外,可以通过简单的算术运算来测试R语言的基本功能,例如:
```r
1 + 1 # 结果为2
```
接下来,读者可以进一步探索R语言的内置函数,进行更复杂的数据操作和分析。
通过以上步骤,你已经迈出了使用R语言进行数据分析的第一步。在接下来的章节中,你将逐步深入了解R语言的基础语法、数据处理技巧以及高级分析方法,最终能够运用R语言解决实际问题。
# 2. R语言的基础语法
### 2.1 R语言的基本数据结构
#### 2.1.1 向量的创建与操作
在R语言中,向量是用于存储相同类型数据的基础数据结构。它可以包含数值、字符或逻辑值等。向量的创建可以通过 `c()` 函数完成,它是向量的合并操作符。
```r
# 创建一个数值型向量
numeric_vector <- c(1, 2, 3, 4, 5)
# 创建一个字符型向量
character_vector <- c("Apple", "Banana", "Cherry")
# 创建一个逻辑型向量
logical_vector <- c(TRUE, FALSE, TRUE, FALSE)
```
向量的操作包括访问、索引、排序等。例如,使用方括号 `[ ]` 可以对向量进行索引操作。
```r
# 访问向量的第三个元素
third_element <- numeric_vector[3]
# 索引字符型向量的前两个元素
first_two_fruits <- character_vector[1:2]
```
#### 2.1.2 矩阵和数组的应用
矩阵(Matrix)是一个二维数据结构,可以看作是向量的扩展,用于存储数值型数据。创建矩阵可以使用 `matrix()` 函数。
```r
# 创建一个3x3的矩阵
matrix_example <- matrix(1:9, nrow = 3, ncol = 3)
```
数组(Array)可以看作是矩阵的多维版本。它可以存储多维数据,创建数组使用 `array()` 函数。
```r
# 创建一个3x3x2的数组
array_example <- array(1:18, dim = c(3, 3, 2))
```
矩阵和数组可以使用索引、转置(通过 `t()` 函数)等操作进行操作。
#### 2.1.3 数据框(DataFrame)的使用
数据框(DataFrame)是R中最重要也是最常用的数据结构,用于存储表格型数据,可以包含不同类型的列。创建数据框可以通过 `data.frame()` 函数。
```r
# 创建一个数据框
df <- data.frame(
Name = c("Alice", "Bob", "Charlie"),
Age = c(25, 30, 35),
Height = c(165, 175, 180),
stringsAsFactors = FALSE # 防止字符串自动转换为因子类型
)
```
数据框的操作包括添加/删除列、合并数据框等。
### 2.2 R语言的控制结构
#### 2.2.1 条件控制语句:if-else
在R语言中,条件控制语句包括 `if` 和 `else`。这些语句用于基于条件判断执行不同的代码块。
```r
# 简单的if-else语句
x <- 10
if(x > 5) {
print("x is greater than 5")
} else {
print("x is not greater than 5")
}
```
嵌套 `if-else` 和条件表达式也可以用来处理更复杂的逻辑。
#### 2.2.2 循环控制语句:for, while, repeat
R语言提供了多种循环控制结构,包括 `for` 循环,`while` 循环和 `repeat` 循环。
```r
# for循环
for(i in 1:5) {
print(i)
}
# while循环
j <- 1
while(j <= 5) {
print(j)
j <- j + 1
}
# repeat循环
k <- 1
repeat {
print(k)
k <- k + 1
if(k > 5) {
break
}
}
```
循环控制结构使得在R中执行重复任务变得简单。
#### 2.2.3 函数的定义和应用
函数在R中是通过 `function()` 关键字创建的,用于封装代码块,并可以接受输入参数,返回值。
```r
# 定义一个函数,计算两个数的和
add_two_numbers <- function(num1, num2) {
sum <- num1 + num2
return(sum)
}
# 调用函数
result <- add_two_numbers(10, 15)
print(result)
```
函数可以提高代码的复用性和可读性。
### 2.3 R语言的图形系统基础
#### 2.3.1 基础图形绘制
R语言提供了基础的图形系统,用于创建简单的统计图表,如条形图、折线图、散点图等。
```r
# 创建一个基础的条形图
barplot(c(10, 20, 30, 40), names.arg = c("A", "B", "C", "D"))
# 创建一个基础的折线图
x <- 1:10
y <- rnorm(10)
plot(x, y, type = "l")
```
#### 2.3.2 高级图形功能介绍
除了基础图形之外,R还提供了高级的图形功能,如 `ggplot2` 包,它可以创建更为复杂和美观的图形。
```r
# 安装并加载ggplot2包
install.packages("ggplot2")
library(ggplot2)
# 使用ggplot2绘制一个散点图
ggplot(df, aes(x = Age, y = Height)) +
geom_point()
```
### 总结
在本章节中,我们详细探讨了R语言的基础语法,包括其基本数据结构如向量、矩阵和数据框的创建和操作。同时,我们也学习了R语言的控制结构,例如条件控制语句和循环控制语句,它们是编写复杂程序逻辑的关键。此外,本章节还介绍了R语言图形系统的基础知识,从基础图形到高级图形系统的应用,为后续的高级分析和数据可视化奠定了基础。通过这些基础语法的学习,读者将能够在R环境中更有效地进行数据处理和分析。
# 3. R语言的数据处理技巧
## 3.1 数据清洗和预处理
### 3.1.1 缺失值处理方法
在真实世界的R语言数据集中,缺失值处理是数据分析中非常关键的一步。R语言提供了多种工具和方法来处理缺失值,从而提高数据质量。例如,`is.na()`函数可以检测数据中的缺失值,`na.omit()`函数可以删除含有缺失值的行,`complete.cases()`函数可以找出完整数据的行。
```r
# 示例数据集
data <- data.frame(
A = c(1, 2, NA, 4, 5),
B = c(NA, 2, 3, 4, NA),
C = c(1, 2, 3, 4, 5)
)
# 检测缺失值
missing_values <- is.na(data)
print(missing_values)
# 删除含有缺失值的行
data_complete <- na.omit(data)
print(data_complete)
# 找出完整数据的行
complete_cases <- complete.cases(data)
print(complete_cases)
```
### 3.1.2 异常值检测与处理
异常值可能会对数据分析和模型预测产生不利影响。在R语言中,可以使用箱型图、Z分数或者IQR(四分位距)方法来识别和处理异常值。
```r
# 箱型图
boxplot(data$A)
# 使用Z分数检测异常值
z_scores <- scale(data$A)
abs_z_scores <- abs(z_scores)
threshold <- 3 # Z分数阈值
outliers <- data$A[abs_z_scores > threshold]
print(outliers)
# 使用IQR方法
iqr_value <- IQR(data$A)
upper_bound <- quantile(data$A, 0.75) + (iqr_value * 1.5)
lower_bound <- quantile(data$A, 0.25) - (iqr_value * 1.5)
outliers_iqr <- data$A[data$A > upper_bound | data$A < lower_bound]
print(outliers_iqr)
```
### 3.1.3 数据变换技巧
数据变换是提高数据质量的一个重要步骤,R语言提供了多种变换函数,如对数变换、幂次变换、标准化和归一化等。
```r
# 对数变换
log_data <- log(data$A + 1)
# 幂次变换
power_data <- data$A^2
# 标准化(z-score标准化)
standardized_data <- scale(data$A)
# 归一化(最小-最大标准化)
normalized_data <- (data$A - min(data$A)) / (max(data$A) - min(data$A))
```
## 3.2 数据整合与重塑
### 3.2.1 数据合并技术
R语言中的`merge()`函数可以实现数据库风格的数据合并操作,而`dplyr`包中的`join`系列函数也提供了更为直观的合并方法。
```r
# 创建第二个数据集
data2 <- data.frame(
A = c(1, 2, 3, 4, 5),
D = c('X', 'Y', 'Z', 'W', 'V')
)
# 使用merge函数合并数据集
merged_data <- merge(data, data2, by = "A")
# 使用dplyr包的join函数合并数据集
library(dplyr)
joined_data <- inner_join(data, data2, by = "A")
```
### 3.2.2 数据重塑和分组操作
R语言提供了`reshape()`函数和`tidyr`包的`gather`和`spread`函数用于数据的重塑。分组操作常使用`dplyr`包的`group_by`和`summarise`函数实现。
```r
library(tidyr)
# 数据重塑
reshaped_data <- gather(data, key = "variable", value = "value", -A)
# 分组操作
grouped_data <- data %>%
group_by(variable) %>%
summarise(mean_value = mean(value))
```
### 3.2.3 数据透视表的应用
在R语言中,虽然没有像Excel那样内置的数据透视表功能,但`reshape2`包的`dcast`函数或`data.table`包都可以创建类似的数据透视表。
```r
library(reshape2)
# 使用dcast函数创建数据透视表
pivot_table <- dcast(reshaped_data, A ~ variable, value.var = "value")
# 或者使用data.table包
library(data.table)
setDT(reshaped_data)
pivot_table_dt <- dcast(reshaped_data, A ~ variable, value.var = "value")
```
## 3.3 数据可视化进阶
### 3.3.1 ggplot2图形高级定制
`ggplot2`是R中非常流行的绘图系统,它使用了图形语法进行数据可视化。ggplot2通过叠加层的方式定制图形,每个层都可以通过加号`+`添加。
```r
library(ggplot2)
# 绘制散点图
ggplot(data, aes(x = A, y = B)) +
geom_point() +
theme_minimal() +
labs(title = "散点图示例")
```
### 3.3.2 分面绘图和交互式图形
分面绘图可以帮助我们观察数据在不同子集的表现,而交互式图形则可以提供更多的探索性分析。`ggplot2`支持分面绘图,而`plotly`包可以生成交互式图形。
```r
# 分面绘图
ggplot(data, aes(x = A, y = B)) +
geom_point() +
facet_wrap(~C)
# 使用plotly生成交互式图形
library(plotly)
plotly::ggplotly(ggplot(data, aes(x = A, y = B)) + geom_point())
```
### 3.3.3 地理空间数据的可视化技巧
R语言提供了`ggmap`包和`sf`包用于绘制地理空间数据。`ggmap`包允许用户轻松集成Google Maps等地图服务,`sf`包提供了简单特性(Simple Features)的支持。
```r
library(ggmap)
# 使用ggmap绘制地图
map <- get_map(location = "New York City")
ggmap(map)
library(sf)
# 创建简单特性的点数据集
points <- st_as_sf(data.frame(data), coords = c("A", "B"), crs = 4326)
# 绘制点数据
ggplot() + geom_sf(data = points) + theme_minimal()
```
通过以上详尽的章节内容展示,我们对R语言的数据处理技巧有了全面的了解,从数据清洗和预处理,到数据整合与重塑,再到数据可视化的进阶应用,每一步都深入浅出,力求为IT行业和相关行业的专业人员提供实用且高效的操作指南。
# 4. ```
# 第四章:R语言的高级分析方法
## 4.1 统计建模基础
### 4.1.1 描述性统计分析
在R语言中,描述性统计分析是分析数据集的初步方法,用以总结和描述数据集的基本特征。R语言提供了丰富的函数进行描述性统计分析,如 `mean()`, `median()`, `sd()`, `var()` 分别用于计算均值、中位数、标准差和方差。此外,`summary()` 函数可以提供数据集的五数概括(最小值、第一四分位数、中位数、第三四分位数、最大值)以及均值,它是探索数据集的强大工具。
### 4.1.2 常用统计分布和假设检验
R语言支持各种统计分布,包括正态分布、二项分布、泊松分布等。使用 `dnorm()`, `pnorm()`, `qnorm()` 可以分别计算正态分布的概率密度、累积分布和分位数。进行假设检验时,R语言提供了一系列的检验函数,如 `t.test()` 用于t检验,`chisq.test()` 用于卡方检验,`wilcox.test()` 用于威尔科克森符号秩检验等。
### 4.1.3 线性回归模型的构建与解释
线性回归是统计建模中最基本也是最重要的方法之一。在R中,可以使用 `lm()` 函数来拟合线性回归模型。例如,`lm(y ~ x1 + x2, data = dataset)` 将创建一个以 `y` 为因变量,`x1` 和 `x2` 为自变量的线性回归模型。模型拟合后,可以使用 `summary()` 函数来获取模型的详细统计输出,解读系数估计、p值以及模型的其他统计指标。
## 4.2 机器学习初探
### 4.2.1 基于R的监督学习算法
R语言在机器学习方面拥有众多强大的包,如 `caret`, `e1071`, `randomForest` 等。使用这些包,可以轻松实现各种监督学习算法,包括逻辑回归、支持向量机(SVM)、决策树、随机森林等。以随机森林算法为例,`randomForest()` 函数可以帮助我们快速构建随机森林模型并进行预测。
```r
library(randomForest)
model <- randomForest(formula, data = dataset)
predictions <- predict(model, newdata = new_data)
```
### 4.2.2 非监督学习的R实现
非监督学习不依赖于预先标记的输出,而是试图发现数据的内在结构。在R中,可以利用 `kmeans()` 函数实现K-均值聚类算法,或者用 `hclust()` 函数来执行层次聚类。这些函数允许我们根据数据点的相似度,将数据分为多个类别。
### 4.2.3 模型选择和评估方法
模型选择是机器学习流程中至关重要的一步。在R中,我们可以通过 `cv.glm()` 函数在交叉验证的框架下进行模型选择和评估。此外,`confusionMatrix()` 函数可以用来评估分类模型的性能,输出混淆矩阵,并提供了一系列性能指标,如准确率、召回率、F1分数等。
## 4.3 时间序列分析
### 4.3.1 时间序列数据的处理
在R语言中,时间序列分析是通过 `ts()` 函数来处理的,它能够将数据转换为时间序列对象。时间序列对象包含了频率、起始时间等信息,这对于后续的分析至关重要。例如:
```r
myts <- ts(data, start = c(2020, 1), frequency = 12)
```
### 4.3.2 ARIMA模型的构建和预测
自回归积分滑动平均模型(ARIMA)是时间序列分析中的一种经典模型。在R语言中,`forecast` 包提供了 `auto.arima()` 函数,它可以自动选择最佳的ARIMA模型参数,并进行时间序列的预测。
```r
library(forecast)
model <- auto.arima(myts)
forecast_result <- forecast(model, h = 12)
```
### 4.3.3 季节性分解与周期性分析
季节性分解技术如STL(Seasonal and Trend decomposition using Loess)可以在R中使用 `stl()` 函数来实现。这个方法可以将时间序列分解为趋势、季节性和不规则成分,从而帮助我们更好地理解数据的周期性和季节性模式。
```r
stl_decomposed <- stl(myts, s.window = "periodic")
plot(stl_decomposed)
```
以上章节内容介绍了R语言在统计建模、机器学习和时间序列分析方面的高级应用,展示了其在数据科学领域中的强大功能和应用灵活性。
```
# 5. R语言的实战案例分析
## 5.1 生物信息学中的应用
R语言不仅在统计分析领域有着深远的影响,其在生物信息学领域同样扮演着重要的角色。在生物信息学中,R语言的应用可以涉及到基因表达数据的分析、生物网络的构建以及进化树的绘制等多个方面。
### 5.1.1 基因表达数据分析
基因表达数据分析是生物信息学的核心研究之一。使用R语言进行基因表达数据分析,通常需要依赖特定的生物信息学包,比如`limma`、`DESeq2`和`edgeR`等,这些包专门针对微阵列或RNA测序数据分析进行了优化。
```R
# 安装并加载limma包
install.packages("limma")
library(limma)
# 假设已经获取了基因表达矩阵和设计矩阵
# 设计矩阵指定实验设计,基因表达矩阵包含表达数据
design_matrix <- ... # 设计矩阵的构建代码
expression_matrix <- ... # 基因表达矩阵的构建代码
# 使用limma进行差异表达分析
fit <- lmFit(expression_matrix, design_matrix)
fit <- eBayes(fit)
# 查找差异表达的基因
topTable(fit, coef=2)
```
上述代码演示了如何使用`limma`包进行差异表达基因的分析。通过设计矩阵的构建和利用线性模型拟合,最终可以识别在不同实验条件下表达水平发生变化的基因。
### 5.1.2 基于R的生物网络分析
在生物网络分析中,我们可以利用R语言来识别基因之间的相互作用,并以此来构建基因调控网络或蛋白质相互作用网络。常用的生物网络分析包包括`igraph`和`BioNet`等。
```R
# 安装并加载igraph包
install.packages("igraph")
library(igraph)
# 假设我们有一个基因的邻接矩阵,用来构建网络
adjacency_matrix <- ... # 邻接矩阵构建代码
# 创建网络
network <- graph.adjacency(adjacency_matrix, mode="undirected")
# 绘制网络图
plot(network)
```
以上代码简单演示了如何使用`igraph`包创建和可视化一个基因相互作用网络。通过邻接矩阵,我们可以构建一个无向图,并进行可视化展示。
### 5.1.3 进化树的绘制与分析
进化树是一种用来表示物种进化关系的树状结构图。在生物信息学中,使用R语言绘制进化树可以通过专门的包,如`ape`,来实现。
```R
# 安装并加载ape包
install.packages("ape")
library(ape)
# 假设我们有一个物种的序列数据
# 通常需要对序列数据进行比对,构建多序列比对结果
# 导入序列比对结果,示例代码省略比对过程
aligned_sequences <- ... # 序列比对结果导入代码
# 构建进化树
tree <- NJ(aligned_sequences)
# 绘制进化树
plot(tree)
```
在这个例子中,通过`ape`包中的`NJ`函数构建了一个基于序列比对结果的进化树,并利用`plot`函数进行了可视化展示。这可以帮助研究人员理解物种间的进化关系。
## 5.2 金融分析的实际运用
在金融领域,R语言同样有着广泛的应用,它能够应用于风险管理和投资组合分析、金融时间序列分析以及高频交易数据挖掘等场景。
### 5.2.1 风险管理和投资组合分析
在风险管理领域,R语言可以用来构建风险模型、计算投资组合的期望收益和风险。`PerformanceAnalytics`和`portfolio`是两个在投资领域常用的R包。
```R
# 安装并加载PerformanceAnalytics包
install.packages("PerformanceAnalytics")
library(PerformanceAnalytics)
# 假设有一个包含股票收益的历史数据
# 通常数据来源于金融市场的历史交易记录
# 导入历史收益数据,示例代码省略数据导入细节
stock_returns <- ... # 股票收益数据导入代码
# 计算投资组合的收益和风险
chart.RiskReturnScatter(stock_returns)
```
在此例中,使用`PerformanceAnalytics`包来计算和可视化投资组合的风险和收益。`chart.RiskReturnScatter`函数绘制了一个风险-收益散点图,帮助投资者直观理解不同资产组合的风险和预期回报。
## 5.3 R语言在大数据中的角色
R语言也逐渐在大数据分析领域发挥作用,它能够与大数据处理平台如Hadoop集成,并处理流数据,同时R Shiny能够开发交互式Web应用。
### 5.3.1 R与Hadoop的集成
由于R语言自身在内存处理能力上的局限性,直接处理大规模数据集往往困难。通过与Hadoop的集成,可以有效地分析大规模数据。
```R
# 安装并加载RHadoop的相关组件
# 注意:RHadoop的安装较为复杂,通常需要Hadoop环境的预设
# 这里提供大致安装代码,具体安装步骤较为繁琐
# 安装并加载rmr2包
install.packages("rmr2")
library(rmr2)
# 示例代码,简单的MapReduce任务
map <- function(k, v) cbind(v, 1)
reduce <- function(k, vs) keyval(k, sum(unlist(vs)))
result <- rmr2::mapreduce(input = "输入数据路径",
input.format = "text",
map = map,
reduce = reduce)
```
此处演示了如何使用RHadoop的`rmr2`包来执行MapReduce任务。尽管示例简化了实际操作过程,但它展示了在Hadoop环境中使用R语言进行数据处理的可能性。
## 5.3.2 R语言在流数据处理中的应用
在流数据处理方面,R语言通过`RevoScaleR`包提供了处理大规模数据流的能力,这在金融和物联网数据流分析中特别有用。
```R
# 安装并加载RevoScaleR包
install.packages("RevoScaleR")
library(RevoScaleR)
# 示例代码,进行数据流处理
rxDataStep(inData="输入数据源",
varsToDrop=c("不需要的列"),
rowsPerRead=5000,
reportProgress=100,
overwrite=TRUE)
```
上述代码展示了如何使用`RevoScaleR`包中的`rxDataStep`函数来处理大规模数据流。通过设置合适的参数,如`rowsPerRead`,可以控制每次读取的数据行数,从而有效管理内存使用。
在本章的案例分析中,我们看到了R语言在多个领域的强大应用,从生物信息学到金融分析,再到大数据处理。这些案例不仅展示了R语言作为统计和数据科学工具的能力,也证明了它在实际工作中的灵活和多样性。接下来的章节将继续探索R语言在其他实战领域中的应用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏汇集了 R 语言学习和应用的丰富教程,涵盖从基础到高级的各个方面。从零基础到精通 R 语言的五大秘诀,到掌握数据包管理的终极指南,再到数据处理、图形绘制、机器学习、图论分析、时间序列分析、文本挖掘、并行计算、包管理、数据安全、大数据处理、深度学习、统计建模、性能突破和空间数据分析等主题,本专栏提供了全面的知识和实践指导。通过这些详细的教程,读者可以快速提升 R 语言技能,解决数据分析和处理中的各种问题,并探索 R 语言在各个领域的应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
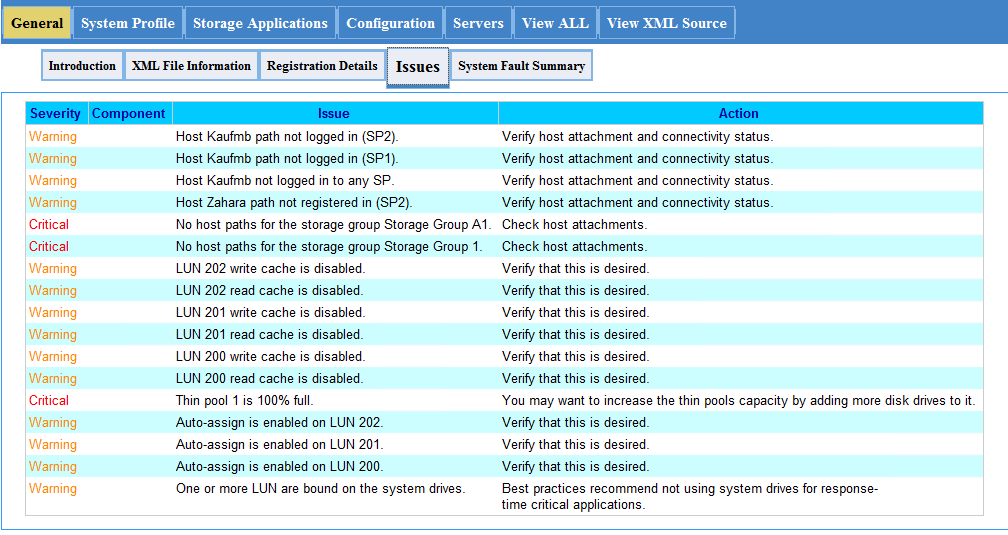
从停机到上线,EMC VNX5100控制器SP更换的实战演练
# 摘要
本文详细介绍了EMC VNX5100控制器的更换流程、故障诊断、停机保护、系统恢复以及长期监控与预防性维护策略。通过细致的准备工作、详尽的风险评估以及备份策略的制定,确保控制器更换过程的安全性与数据的完整性。文中还阐述了硬件故障诊断方法、系统停机计划的制定以及数据保护步骤。更换操作指南和系统重启初始化配置得到了详尽说明,以确保系统功能的正常恢复与性能优化。最后,文章强调了性能测试
【科大讯飞官方指南】:语音识别集成与优化的终极解决方案

# 摘要
本文综述了语音识别技术的当前发展概况,深入探讨了科大讯飞语音识别API的架构、功能及高级集成技术。文章详细分析了不同应用场景下语音识别的应用实践,包括智能家居、移动应用和企业级
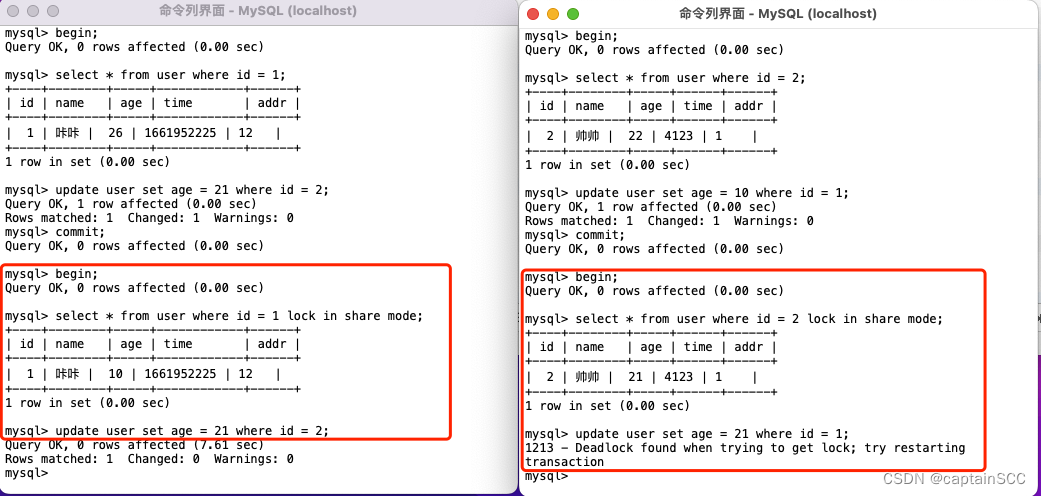
彻底解决MySQL表锁问题:专家教你如何应对表锁困扰
# 摘要
本文深入探讨了MySQL数据库中表锁的原理、问题及其影响。文章从基础知识开始,详细分析了表锁的定义、类型及其与行锁的区别。理论分析章节深入挖掘了表锁产生的原因,包括SQL编程习惯、数据库设计和事务处理,以及系统资源和并发控制问题。性能影响部分讨论了表锁对查询速度和事务处理的潜在负面效果。诊断与排查章节提供了表锁监控和分析工具的使用方法,以及实际监控和调试技巧。随后,本文介绍了避免和解决表锁问题
【双色球数据清洗】:掌握这3个步骤,数据准备不再是障碍
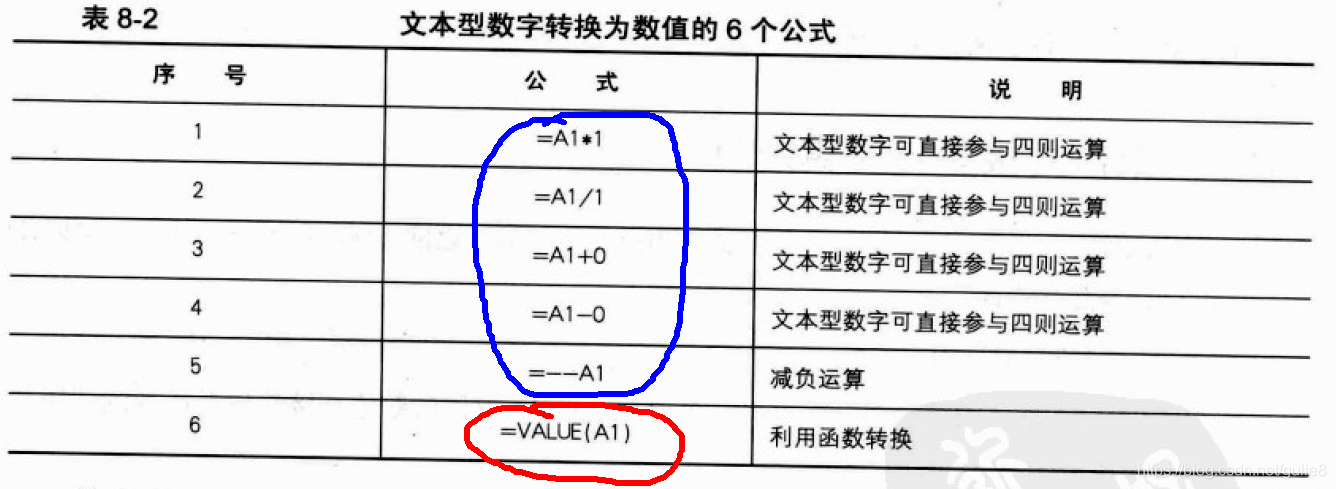
# 摘要
双色球数据清洗作为保证数据分析准确性的关键环节,涉及数据收集、预处理、实践应用及进阶技术等多方面内容。本文首先概述了双色球数据清洗的重要性,并详细解析
【SketchUp脚本编写】

# 摘要
随着三维建模需求的增长,SketchUp脚本编程因其自动化和高效性受到设计师的青睐。本文首先概述了SketchUp脚本编写的基础知识,包括脚本语言的基本概念、SketchUp API与命令操作、控制流与函数的使用。随后,深入探讨了脚本在建模自动化、材质与纹理处理、插件与扩展开发中的实际应用。文章还介绍了高级技巧,如数据交换、错误处理、性能优化
硬盘故障分析:西数硬盘检测工具在故障诊断中的应用(故障诊断的艺术与实践)

# 摘要
本文从硬盘故障的分析概述入手,系统地探讨了西数硬盘检测工具的选择、安装与配置,并深入分析了硬盘的工作原理及故障类型。在此基础上,本文详细阐述了故障诊断的理论基础和实践应用,包括常规状态检测、故障模拟与实战演练。此外,本文还提供了数据恢复与备份策略,以及硬盘故障处理的最佳实践和预防措施,旨在帮助读者全面理解和
关键参数设置大揭秘:DEH调节最佳实践与调优策略
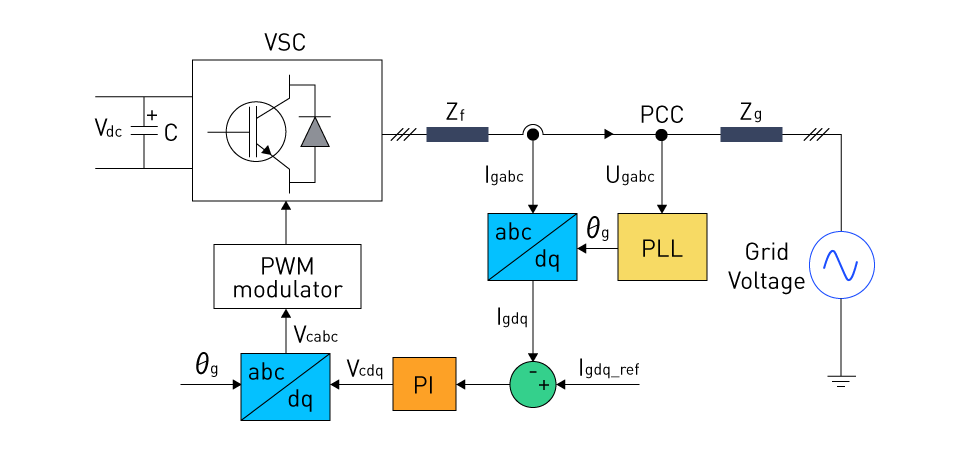
# 摘要
本文系统地介绍了DEH调节技术的基本概念、理论基础、关键参数设置、实践应用、监测与分析工具,以及未来趋势和挑战。首先概述了DEH调节技术的含义和发展背景。随后深入探讨了DEH调节的原理、数学模型和性能指标,详细说明了DEH系统的工作机制以及控制理论在其中的应用。重点分析了DEH调节关键参数的配置、优化策略和异
【面向对象设计在软件管理中的应用】:原则与实践详解
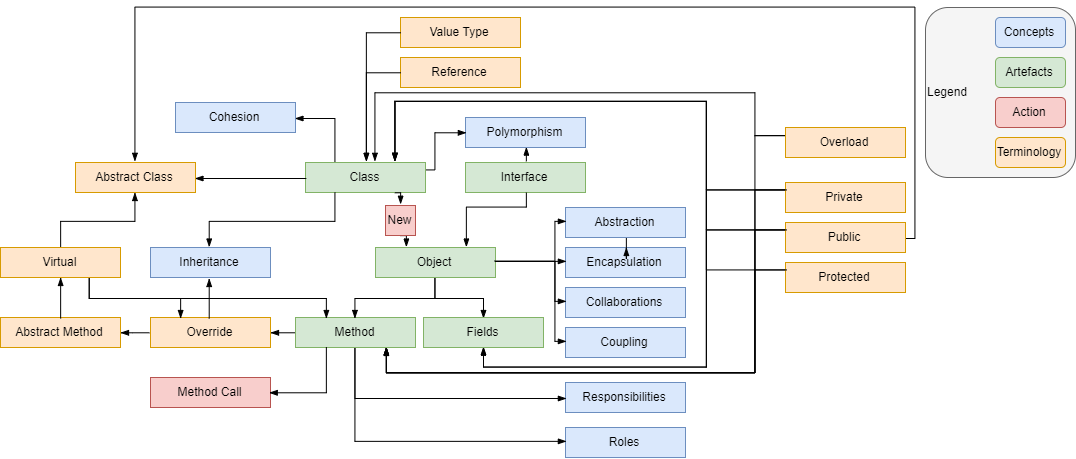
# 摘要
面向对象设计(OOD)是软件工程中的核心概念,它通过封装、继承和多态等特性,促进了代码的模块化和复用性,简化了系统维护,提高了软件质量。本文首先回顾了OOD的基本概念与原则,如单一职责原则(SRP)、开闭原则(OCP)、里氏替换原则(LSP)、依赖倒置原则(DIP)和接口隔离原则(ISP),并通过实际案例分析了这些原则的应用。接着,探讨了创建型、结构型和行为型设计模式在软件开发中的应用,以及面向对象设计
【AT32F435与AT32F437 GPIO应用】:深入理解与灵活运用

# 摘要
AT32F435/437微控制器作为一款广泛应用的高性能MCU,其GPIO(通用输入/输出端口)的功能对于嵌入式系统开发至关重要。本文旨在深入探讨GPIO的基础理论、配置方法、性能优化、实战技巧以及在特定功能中的应用,并提供故障诊断与排错的有效方法。通过详细的端口结构分析、寄存器操作指导和应用案例研究,
【sCMOS相机驱动电路信号同步处理技巧】:精确时间控制的高手方法
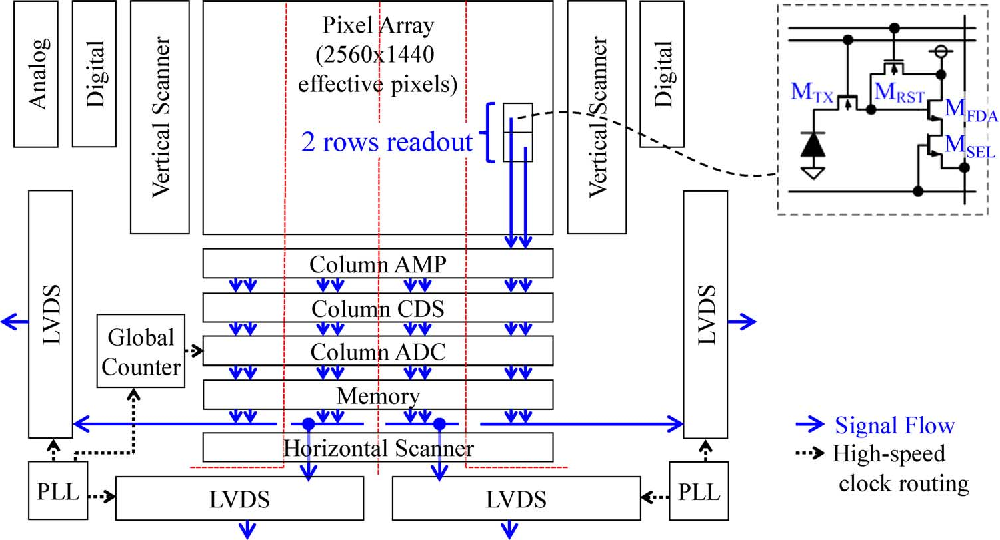
# 摘要
sCMOS相机作为高分辨率成像设备,在科学研究和工业领域中发挥着重要作用。本文首先概述了sCMOS相机驱动电路信号同步处理的基本概念与必要性,然后深入探讨了同步处理的理论基础,包括信号同步的定义、分类、精确时间控制理论以及时间延迟对信号完整性的影响。接着,文章进入技术实践部分,详细描述了驱动电路设计、同步信号生成控制以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )