揭秘OpenCV物体识别算法:原理、优势和局限性,掌握算法精髓,提升识别效率
发布时间: 2024-08-06 21:20:25 阅读量: 83 订阅数: 28 

三种强大的物体识别算法介绍
# 1. OpenCV物体识别算法概述
OpenCV(Open Source Computer Vision Library)是一个开源计算机视觉库,广泛用于图像处理、视频分析和物体识别等领域。OpenCV物体识别算法利用机器学习技术,通过分析图像或视频中的特征,识别和分类图像中的物体。
物体识别算法通常分为两类:目标检测算法和分类算法。目标检测算法负责定位图像中的物体,而分类算法则负责将检测到的物体分类为特定类别。OpenCV提供了多种物体识别算法,包括Haar级联分类器、HOG(直方图梯度)描述符和深度学习模型。这些算法在准确性和效率方面各具优势,可根据具体应用场景选择最合适的算法。
# 2. OpenCV物体识别算法原理
### 2.1 机器学习基础
#### 2.1.1 机器学习分类
机器学习是一种人工智能技术,它使计算机能够从数据中学习,而无需明确编程。机器学习算法可以分为三类:
- **监督学习:**算法从标记数据(即具有已知输入和输出的数据)中学习。
- **无监督学习:**算法从未标记数据中学习,识别数据中的模式和结构。
- **强化学习:**算法通过与环境互动并接收奖励或惩罚来学习。
#### 2.1.2 特征提取和表示
特征提取是将原始数据转换为更简洁、更具代表性的形式的过程。特征表示是提取特征的数学描述。特征提取和表示对于机器学习至关重要,因为它可以提高算法的性能和效率。
### 2.2 物体识别算法
物体识别算法是计算机视觉中的一类算法,用于识别图像或视频中的物体。这些算法通常基于机器学习技术,可以分为两类:
#### 2.2.1 目标检测算法
目标检测算法确定图像或视频中物体的存在和位置。它们通常使用滑动窗口或区域建议网络来生成候选区域,然后对这些区域进行分类。
**代码块:**
```python
import cv2
# 加载图像
image = cv2.imread('image.jpg')
# 创建目标检测器
detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 检测人脸
faces = detector.detectMultiScale(image, 1.1, 4)
# 绘制人脸边界框
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 显示图像
cv2.imshow('Faces', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
**逻辑分析:**
此代码使用 OpenCV 的级联分类器进行人脸检测。级联分类器使用一系列弱分类器来检测图像中的特定特征。代码首先加载图像,然后创建目标检测器。检测器使用滑动窗口在图像中搜索人脸。找到人脸后,代码在图像上绘制边界框。
#### 2.2.2 分类算法
分类算法将图像或视频中的物体分配给预定义的类别。它们通常使用卷积神经网络(CNN)来提取图像中的特征,然后使用这些特征对图像进行分类。
**代码块:**
```python
import tensorflow as tf
# 加载模型
model = tf.keras.models.load_model('model.h5')
# 加载图像
image = cv2.imread('image.jpg')
# 预处理图像
image = cv2.resize(image, (224, 224))
image = image / 255.0
# 预测类别
prediction = model.predict(np.expand_dims(image, axis=0))
# 打印预测结果
print(f'Predicted class: {np.argmax(prediction)}')
```
**逻辑分析:**
此代码使用 TensorFlow 加载预训练的 CNN 模型来对图像进行分类。模型使用预处理图像的特征来预测图像的类别。代码首先加载模型,然后加载图像并对其进行预处理。预处理包括调整图像大小和归一化像素值。然后,代码将预处理后的图像输入模型进行预测。预测结果是图像属于每个类别的概率分布。代码打印预测的类别,即概率最高的类别。
# 3. OpenCV物体识别算法优势
### 3.1 跨平台兼容性
OpenCV是一个跨平台的库,这意味着它可以在各种操作系统上运行,包括Windows、Linux、macOS和移动平台。这种跨平台兼容性使开发人员能够在不同的平台上部署和使用OpenCV,从而简化了开发过程并提高了可移植性。
### 3.2 丰富的算法库
OpenCV提供了一个丰富的算法库,涵盖了图像处理、计算机视觉和机器学习等领域。这些算法包括图像增强、特征提取、目标检测、分类和分割等。通过利用OpenCV的算法库,开发人员可以快速轻松地构建复杂的计算机视觉应用程序。
### 3.3 高效的图像处理能力
OpenCV以其高效的图像处理能力而闻名。它提供了优化的高性能函数,可以快速处理大图像和视频流。这使得OpenCV非常适合实时应用程序,例如目标跟踪和物体检测。
#### 3.3.1 图像增强
OpenCV提供了各种图像增强算法,包括直方图均衡化、伽马校正和锐化。这些算法可以改善图像的对比度、亮度和清晰度,从而提高后续处理任务的性能。
#### 3.3.2 特征提取
特征提取是计算机视觉中的一项关键任务,它涉及从图像中提取有意义的信息。OpenCV提供了各种特征提取算法,包括SIFT、SURF和ORB。这些算法可以从图像中提取关键点和描述符,用于目标检测和分类。
#### 3.3.3 目标检测
目标检测算法用于在图像中定位和识别特定对象。OpenCV提供了多种目标检测算法,包括Haar级联分类器、HOG检测器和YOLO。这些算法可以检测各种对象,例如人脸、车辆和行人。
#### 3.3.4 分类算法
分类算法用于将图像分类为预定义的类别。OpenCV提供了各种分类算法,包括支持向量机、随机森林和神经网络。这些算法可以训练在给定图像数据集中识别特定对象。
#### 3.3.5 分割算法
分割算法用于将图像分割成不同的区域或对象。OpenCV提供了各种分割算法,包括阈值分割、区域生长和基于边缘的分割。这些算法可以帮助提取图像中的感兴趣区域,并用于目标检测和图像分析。
# 4. OpenCV物体识别算法局限性
### 4.1 算法复杂度高
物体识别算法通常涉及复杂的计算,例如特征提取、分类和目标检测。这些计算可能需要大量的处理时间,尤其是在处理大型图像或视频流时。
**代码块:**
```python
import cv2
import numpy as np
# 加载图像
image = cv2.imread('image.jpg')
# 转换图像为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 使用 SIFT 特征检测器提取特征
sift = cv2.SIFT_create()
keypoints, descriptors = sift.detectAndCompute(gray, None)
# 训练 SVM 分类器
svm = cv2.ml.SVM_create()
svm.train(descriptors, np.ones((len(descriptors), 1), np.int32))
# 检测图像中的对象
objects = svm.predict(descriptors)
```
**逻辑分析:**
* 加载图像并将其转换为灰度图。
* 使用 SIFT 特征检测器提取图像中的特征。
* 训练 SVM 分类器以对特征进行分类。
* 使用分类器检测图像中的对象。
**参数说明:**
* `cv2.SIFT_create()`:创建 SIFT 特征检测器。
* `detectAndCompute()`:检测并计算图像中的特征。
* `cv2.ml.SVM_create()`:创建 SVM 分类器。
* `train()`:使用特征训练分类器。
* `predict()`:使用分类器检测图像中的对象。
### 4.2 训练数据依赖性
物体识别算法的性能很大程度上取决于训练数据的质量和数量。如果训练数据不足或质量低,算法可能无法准确识别对象。
**代码块:**
```python
# 加载训练数据
train_data = np.load('train_data.npy')
train_labels = np.load('train_labels.npy')
# 训练神经网络
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(train_data, train_labels, epochs=10)
```
**逻辑分析:**
* 加载训练数据(图像和标签)。
* 创建神经网络模型。
* 编译模型(指定优化器、损失函数和度量标准)。
* 训练模型(使用训练数据)。
**参数说明:**
* `np.load()`:加载训练数据。
* `tf.keras.models.Sequential()`:创建神经网络模型。
* `Dense()`:添加全连接层。
* `activation='relu'`:使用 ReLU 激活函数。
* `compile()`:编译模型。
* `fit()`:训练模型。
### 4.3 环境影响
物体识别算法的性能可能会受到环境因素的影响,例如照明条件、背景杂乱和对象遮挡。这些因素可能会导致算法错误识别或错过对象。
**代码块:**
```python
# 加载图像
image = cv2.imread('image.jpg')
# 使用 YOLOv3 目标检测器检测对象
net = cv2.dnn.readNet('yolov3.weights', 'yolov3.cfg')
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (416, 416), (0, 0, 0), swapRB=True, crop=False)
net.setInput(blob)
detections = net.forward()
# 处理检测结果
for detection in detections[0, 0]:
if detection[2] > 0.5:
x1, y1, x2, y2 = detection[3:7] * np.array([image.shape[1], image.shape[0], image.shape[1], image.shape[0]])
cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
```
**逻辑分析:**
* 加载图像。
* 使用 YOLOv3 目标检测器检测图像中的对象。
* 处理检测结果(过滤置信度较低的检测并绘制边界框)。
**参数说明:**
* `cv2.dnn.readNet()`:加载 YOLOv3 模型。
* `blobFromImage()`:将图像转换为 YOLOv3 输入格式。
* `setInput()`:将输入数据设置到模型中。
* `forward()`:执行前向传播。
* `cv2.rectangle()`:绘制边界框。
# 5. 提升OpenCV物体识别算法效率
提升OpenCV物体识别算法的效率至关重要,因为它可以缩短处理时间、提高准确性和降低资源消耗。以下介绍了三种有效的优化方法:
### 5.1 优化算法参数
算法参数对算法性能有显著影响。通过调整这些参数,可以优化算法在特定数据集上的表现。常见的可调参数包括:
- **学习率:**控制模型更新权重的速度。较高的学习率可能导致不稳定,而较低的学习率可能导致训练缓慢。
- **批量大小:**一次训练模型的样本数量。较大的批量大小可以提高稳定性,但可能需要更多的内存。
- **迭代次数:**模型训练的次数。更多的迭代次数可以提高准确性,但可能增加计算成本。
### 5.2 采用高效的数据结构
数据结构的选择会影响算法的性能。使用高效的数据结构可以减少内存使用并提高处理速度。以下是一些常见的优化:
- **哈希表:**用于快速查找和检索数据。
- **二叉树:**用于高效地存储和搜索有序数据。
- **稀疏矩阵:**用于存储大量零值的矩阵。
### 5.3 并行化处理
并行化处理可以利用多核CPU或GPU来提高算法效率。以下是一些常见的并行化技术:
- **多线程编程:**使用多个线程同时执行任务。
- **GPU加速:**利用GPU的并行计算能力来处理图像和数据。
- **分布式计算:**将任务分配给多个计算机或服务器同时执行。
通过实施这些优化方法,可以显著提升OpenCV物体识别算法的效率,从而提高其在实际应用中的性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 OpenCV 物体识别技术,涵盖其原理、优势和局限性。它提供了图像预处理技巧,以提高识别准确率,并介绍了性能优化技术,以加速识别速度。专栏还探讨了 OpenCV 物体识别在医疗、安防、零售、自动驾驶、机器人、教育、科研等领域的广泛应用。此外,它还介绍了性能评估指标、数据集、开源库以及与其他识别技术的比较,为读者提供了全面了解 OpenCV 物体识别技术的宝贵资源。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Swift报文安全秘籍:确保数据传输无懈可击的5大策略
# 摘要
本文旨在全面探讨Swift报文在传输过程中的安全性问题,涵盖加密技术、认证与授权机制、传输层安全策略、以及报文处理与存储的安全性实践。通过对加密算法的概述、Swift语言中的加密实践、认证机制、授权策略和SSL/TLS协议的深入解析,文章提供了一系列安全策略来增强Swift报文的安全性。同时,本文还探讨了安全报文的序列化与反序列化、存储安全性以及高级安全应用策略,包括安全审计与日志管理以及持
企业级部署宝典:Windows 7 SP1更新包的最佳实践与案例
# 摘要
本文全面概述了Windows 7 SP1更新包的准备工作、企业级部署实践以及自动化与优化的策略。文章首先介绍了更新包的系统需求分析、更新策略规划和获取管理过程,随后深入探讨了批量部署技术、更新过程监控与管理和更新包的验证与审核步骤。通过应用案例分析,作者分享了成功和失败的部署经验,并提出了应对策略。文章最后展望了更新部署的自动化工具和持续集成/持续部署(CI/CD)流程的应用,以及更新策略
【OpenWRT Portal认证速成课】:常见问题解决与性能优化
# 摘要
OpenWRT作为一款流行的开源路由器固件,其Portal认证功能在企业与家庭网络中得到广泛应用。本文首先介绍了OpenWRT Portal认证的基本原理和应用场景,随后详述了认证的配置与部署步骤,包括服务器安装、认证页面定制、流程控制参数设置及认证方式配置。为了应对实际应用中可
【Putty与SSH代理】:掌握身份验证问题的处理艺术
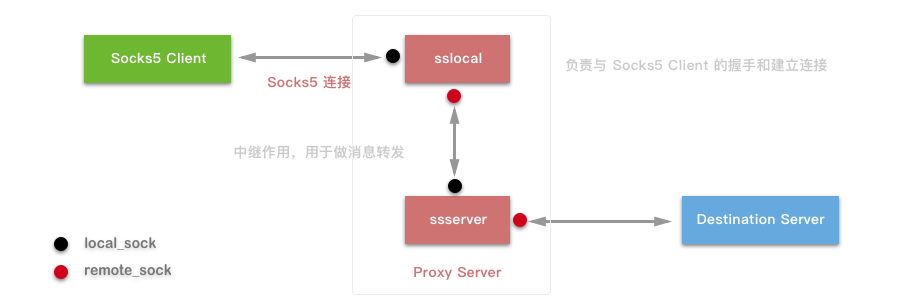
# 摘要
随着网络技术的发展,Putty与SSH代理已成为远程安全连接的重要工具。本文从Putty与SSH代理的简介开始,深入探讨了SSH代理的工作原理与配置,包括身份验证机制和高级配置技巧。文章还详细分析了身份验证问题的诊断与解决方法,讨论了密钥管理、安全强化措施以及无密码SSH登录的实现。在高级应用方面,探讨了代理转发、端口转发和自动化脚本中的应用。通过案例研究展示了这些技术在企业环境中的应
【环境适应性分析】:DROID-SLAM在室内外场景中的性能差异

# 摘要
随着机器人和自动驾驶技术的发展,DROID-SLAM技术作为一项关键的自主定位与地图构建解决方案,越来越受到学术界和产业界的关注。本文首先概述了DROID-SLAM技术的理论基础及其与传统SLAM技术的区别,然后详细解析了DROID-SLAM的核心
【系统性能分析】:如何利用迹线图诊断和改善计算性能
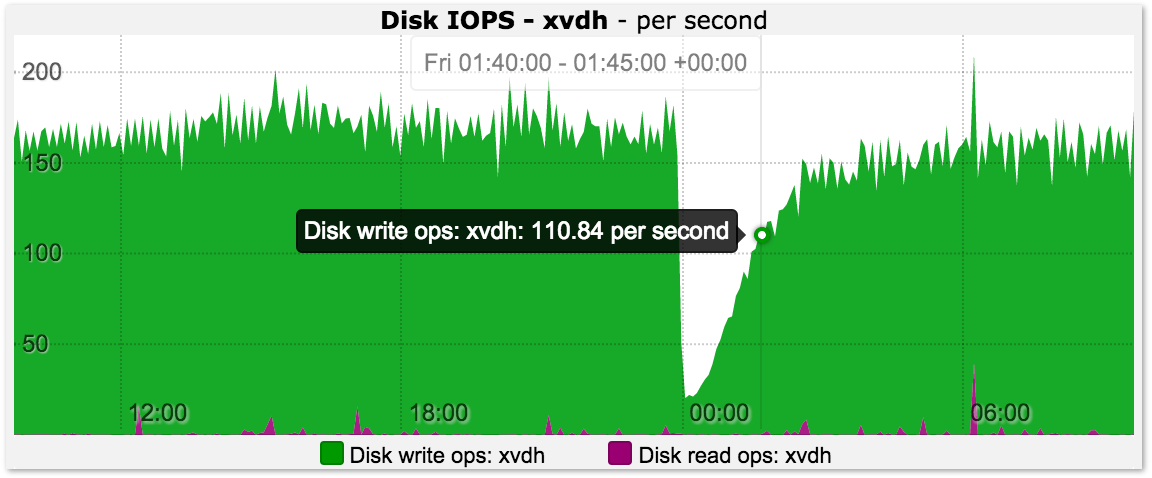
# 摘要
本文系统性地介绍了系统性能分析的概述,并详细阐述了迹线图的理论基础、类型特征、数学原理及其在系统诊断中的应用。文章首先界定了迹线图的概念及其在性能分析中的重要性,随后探讨了不同类型的迹线图以及如何识别其特征。接着,文章深入讲解了迹线图分析工具的使用方法,包括常见软件的对比和功能选择、数据采集及生成步骤,以及数据解读的技巧。在应用方面,文章讨论了迹线图在识别性能瓶颈、优化指导以及与
【国赛C题算法精进秘籍】:专家教你如何选择与调整算法

# 摘要
随着计算机科学的发展,算法已成为解决问题的核心工具,对算法的理解和选择对提升计算效率和解决问题至关重要。本文首先对算法基础知识进行概览,然后深入探讨算法选择的理论基础,包括算法复杂度分析和数据结构对算法选择的影响,以及算法在不同场景下的适用性。接着,本文介绍了算法调整与优化技巧,强调了基本原理与实用策略。在实践层面,通过案例分析展示算
S32K SPI开发实战指南:DMA传输与多设备通信策略
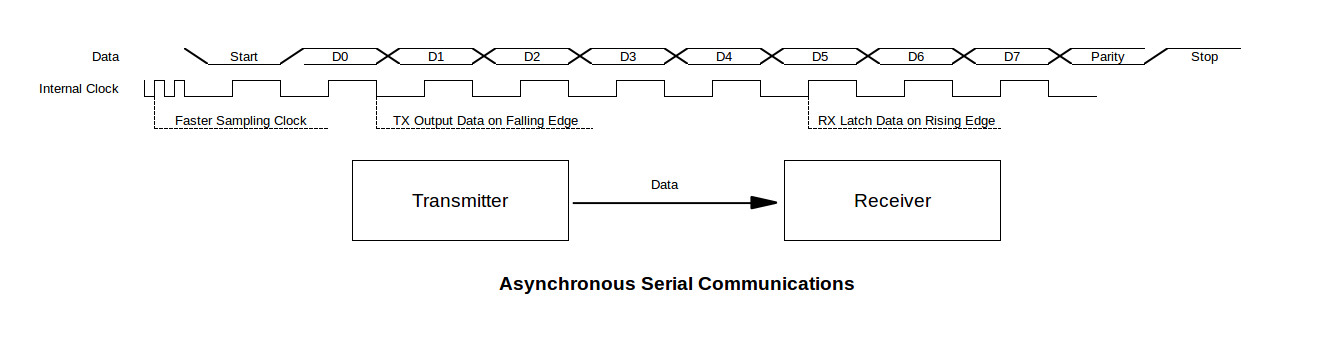
# 摘要
本文系统地介绍了S32K微控制器的SPI接口及其DMA传输机制,探讨了多SPI设备通信的技术需求、挑战与实现策略,并提供了高级配置技巧和面向对象编程范式的应用。文中详细分析了S32K SPI的基础知识,解释了DMA传输的基本原理及其在数据传输中的优势,并深入探讨了SPI与DMA的配置方法,以及在多设备通信中如何处理同步与控制问题。此外,本文还探讨了在物联网应用中S32K SPI
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )