MATLAB条件语句的常见陷阱:避免逻辑错误和性能问题的完整指南
发布时间: 2024-06-15 21:25:11 阅读量: 84 订阅数: 27 

MATLAB中利用条件语句自定义图形样式的详细指南

# 1. MATLAB条件语句概述
MATLAB条件语句是控制程序流的关键工具,允许根据特定条件执行不同的代码块。MATLAB提供了一系列条件语句,包括`if-else`、`switch-case`和`while`循环。
这些语句允许程序根据特定条件做出决策,例如:
- 检查变量是否大于或等于某个值
- 比较两个字符串是否相等
- 确定是否满足某个逻辑表达式
# 2. 条件语句的常见陷阱
### 2.1 逻辑运算符误用
逻辑运算符用于组合布尔表达式,它们可以对多个条件进行 AND、OR 和 NOT 操作。在 MATLAB 中,常用的逻辑运算符有:
- `&`:AND 运算符,当所有条件都为真时返回真。
- `|`:OR 运算符,当任何一个条件为真时返回真。
- `~`:NOT 运算符,将真值取反。
#### 2.1.1 与运算符 (&) 和或运算符 (|) 的区别
与运算符 (&) 和或运算符 (|) 的主要区别在于它们的求值顺序。与运算符 (&) 采用短路求值,这意味着如果第一个条件为假,则不会求值后续条件。而或运算符 (|) 采用非短路求值,这意味着即使第一个条件为真,也会求值所有条件。
```matlab
% 与运算符 (&)
if (x > 0) & (y < 0)
disp('条件为真')
else
disp('条件为假')
end
% 或运算符 (|)
if (x > 0) | (y < 0)
disp('条件为真')
else
disp('条件为假')
end
```
在上面的示例中,如果 `x` 为负数,与运算符 (&) 将不会求值 `y < 0`,因为第一个条件 `x > 0` 为假。而或运算符 (|) 将求值所有条件,即使 `x > 0` 为真。
#### 2.1.2 非运算符 (~) 的用法
非运算符 (~) 用于取反布尔表达式。它将真值变为假,反之亦然。非运算符的优先级高于逻辑运算符,因此在使用时需要特别注意。
```matlab
% 非运算符 (~)
if ~(x > 0)
disp('条件为真')
else
disp('条件为假')
end
```
在上面的示例中,非运算符 (~) 将 `x > 0` 取反,因此如果 `x` 为负数,则条件为真。
### 2.2 比较运算符错误
比较运算符用于比较两个值的大小或相等性。在 MATLAB 中,常用的比较运算符有:
- `==`:等于
- `~=`:不等于
- `>`:大于
- `<`:小于
- `>=`:大于等于
- `<=`:小于等于
#### 2.2.1 等号 (==) 和赋值运算符 (=) 的混淆
等号 (==) 用于比较两个值是否相等,而赋值运算符 (=) 用于将一个值分配给另一个变量。混淆这两种运算符会导致逻辑错误。
```matlab
% 等号 (==)
if x == 0
disp('x 为 0')
end
% 赋值运算符 (=)
if x = 0
disp('x 为 0')
end
```
在上面的示例中,第一个 if 语句使用等号 (==) 正确地比较 `x` 是否等于 0。而第二个 if 语句使用赋值运算符 (=) 将 0 赋值给 `x`,而不是比较 `x` 是否等于 0。
#### 2.2.2 比较运算符 (>, <, >=, <=) 的优先级
比较运算符的优先级低于逻辑运算符。因此,在使用比较运算符和逻辑运算符组合时,需要特别注意优先级。
```matlab
% 比较运算符优先级低于逻辑运算符
if x > 0 && y < 0
disp('条件为真')
end
```
在上面的示例中,由于逻辑运算符 && 的优先级高于比较运算符 >,因此条件首先求值 `x > 0`,然后求值 `y < 0`。
### 2.3 条件语句结构不当
条件语句结构不当会导致代码难以理解和维护。常见的结构不当包括:
#### 2.3.1 if-else 语句的嵌套过多
嵌套过多的 if-else 语句会使代码难以阅读和理解。应尽可能避免嵌套,并考虑使用 switch-case 语句或其他结构来简化代码。
```matlab
% 嵌套过多的 if-else 语句
if x > 0
if y > 0
disp('x 和 y 都为正')
else
disp('x 为正,y 为负')
end
else
if y > 0
disp('x 为负,y 为正')
else
disp('x 和 y 都为负')
end
end
```
#### 2.3.2 switch-case 语句的滥用
switch-case 语句用于处理多个条件,但滥用 switch-case 语句会导致代码难以维护和扩展。应仅在需要处理大量条件时使用 switch-case 语句,并考虑使用 if-elseif-else 语句或其他结构来简化代码。
```matlab
% switch-case 语句的滥用
switch x
case 1
disp('x 为 1')
case 2
disp('x 为 2')
case 3
disp('x 为 3')
otherwise
disp('x 不是 1、2 或 3')
end
```
# 3.1 使用清晰的逻辑表达式
避免逻辑错误的关键在于使用清晰且易于理解的逻辑表达式。以下是一些最佳实践:
- **避免使用复杂的嵌套和冗余条件:**复杂的嵌套和冗余条件会使代码难以阅读和理解。尽量将条件分解成更小的、更易管理的部分,并使用括号来提高可读性。
```
% 复杂且难以理解的条件表达式
if (x > 0) && (y < 0) || (z == 0) && (w ~= 1)
% 执行代码
end
% 更清晰且易于理解的条件表达式
if (x > 0) && (y < 0)
% 执行代码
elseif (z == 0) && (w ~= 1)
% 执行代码
end
```
- **采用可读性高的变量名和注释:**变量名和注释可以帮助解释条件表达式的意图。使用描述性变量名,并添加注释以解释复杂的逻辑。
```
% 使用描述性变量名和注释
x_is_positive = x > 0;
y_is_negative = y < 0;
z_is_zero = z == 0;
w_is_not_one = w ~= 1;
if x_is_positive && y_is_negative
% 执行代码
elseif z_is_zero && w_is_not_one
% 执行代码
end
```
### 3.2 测试所有可能的输入
确保条件语句处理所有可能的输入至关重要。以下是一些最佳实践:
- **考虑边界条件和特殊情况:**边界条件和特殊情况可能会导致意外的行为。测试这些情况以确保代码在所有情况下都能正常运行。
```
% 测试边界条件
x = 0;
y = 0;
if x > 0
% 执行代码
end
% 测试特殊情况
x = NaN;
y = Inf;
if x > 0
% 执行代码
end
```
- **使用断言和单元测试来验证逻辑:**断言和单元测试可以帮助验证条件语句的逻辑是否正确。断言在运行时检查条件,单元测试提供了一种自动化方式来测试代码的各种输入。
```
% 使用断言来验证逻辑
assert(x > 0, 'x must be greater than 0');
% 使用单元测试来测试代码
function test_condition
x = 1;
y = -1;
expected_result = true;
actual_result = (x > 0) && (y < 0);
assertEqual(expected_result, actual_result);
end
```
# 4. 提高条件语句性能的技巧
### 4.1 避免不必要的条件检查
在条件语句中,不必要的条件检查会浪费计算资源并降低代码性能。有两种主要技术可以避免不必要的条件检查:
#### 4.1.1 使用短路求值 (&& 和 ||) 来优化条件语句
短路求值是一种运算符,当第一个操作数为 false 时,它会停止评估后续操作数。这对于优化条件语句非常有用,因为如果第一个条件为 false,则没有必要评估后续条件。
```
% 使用短路求值优化 if 语句
if (x > 0) && (y < 0)
% 执行代码块
end
```
在上面的示例中,如果 `x` 为 false,则 `y < 0` 不会被评估,从而避免了不必要的计算。
#### 4.1.2 缓存条件结果以减少重复计算
在某些情况下,条件语句可能会多次评估相同的条件。为了避免这种不必要的重复计算,可以使用缓存来存储条件结果。
```
% 使用缓存优化条件语句
cached_condition = (x > 0);
if cached_condition
% 执行代码块
end
```
在上面的示例中,`x > 0` 的结果被缓存到 `cached_condition` 中。如果条件语句多次执行,则可以从缓存中检索结果,而不是每次都重新计算。
### 4.2 使用高效的条件语句结构
选择合适的条件语句结构可以显著提高代码性能。以下是一些建议:
#### 4.2.1 优先使用 if-elseif-else 语句而不是嵌套的 if 语句
嵌套的 if 语句可能会导致代码难以阅读和维护。相反,建议使用 if-elseif-else 语句来处理多个条件。
```
% 使用 if-elseif-else 语句代替嵌套的 if 语句
if (x > 0)
% 执行代码块
elseif (x < 0)
% 执行代码块
else
% 执行代码块
end
```
#### 4.2.2 考虑使用 switch-case 语句来处理多个条件
switch-case 语句可以更有效地处理多个条件,尤其是当条件涉及枚举值或常量时。
```
% 使用 switch-case 语句处理多个条件
switch (x)
case 1
% 执行代码块
case 2
% 执行代码块
otherwise
% 执行代码块
end
```
通过遵循这些技巧,可以显著提高条件语句的性能,从而改善 MATLAB 程序的整体效率。
# 5. 条件语句的进阶应用
条件语句在 MATLAB 中不仅用于控制程序流程,还可以在数值计算和数据分析中发挥重要作用。
### 5.1 条件语句在数值计算中的应用
#### 5.1.1 使用条件语句实现分段函数
分段函数是指在不同输入范围内具有不同数学表达式的函数。MATLAB 中可以使用条件语句轻松实现分段函数。例如,以下代码实现了分段函数 f(x):
```
function y = f(x)
if x < 0
y = -x;
elseif x >= 0 && x < 1
y = x^2;
else
y = 2*x;
end
end
```
#### 5.1.2 在优化算法中使用条件语句
条件语句在优化算法中也扮演着重要角色。例如,在梯度下降算法中,需要判断当前梯度的方向,并根据判断结果更新参数。以下代码展示了梯度下降算法中使用条件语句:
```
function [x, iter] = gradient_descent(f, x0, alpha, max_iter)
iter = 0;
while iter < max_iter
grad = gradient(f, x0);
if norm(grad) < 1e-6
break;
end
x0 = x0 - alpha * grad;
iter = iter + 1;
end
end
```
### 5.2 条件语句在数据分析中的应用
#### 5.2.1 使用条件语句过滤和分类数据
条件语句可以用来过滤和分类数据。例如,以下代码过滤出大于 100 的数据:
```
data = [10, 20, 30, 40, 50, 110, 120, 130];
filtered_data = data(data > 100);
```
#### 5.2.2 在机器学习模型中使用条件语句
条件语句在机器学习模型中也广泛应用。例如,在决策树中,条件语句用于根据特征值将数据划分到不同的分支。以下代码展示了决策树中使用条件语句:
```
function [tree, y_pred] = decision_tree(data, labels, max_depth)
if max_depth == 0 || all(labels == labels(1))
tree = labels(1);
y_pred = labels(1) * ones(size(data, 1), 1);
return;
end
[best_feature, best_threshold] = find_best_split(data, labels);
left_data = data(data(:, best_feature) <= best_threshold, :);
left_labels = labels(data(:, best_feature) <= best_threshold);
right_data = data(data(:, best_feature) > best_threshold, :);
right_labels = labels(data(:, best_feature) > best_threshold);
tree = struct('feature', best_feature, 'threshold', best_threshold);
left_tree = decision_tree(left_data, left_labels, max_depth - 1);
right_tree = decision_tree(right_data, right_labels, max_depth - 1);
tree.left = left_tree;
tree.right = right_tree;
y_pred = predict(tree, data);
end
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
MATLAB条件语句专栏深入探讨了MATLAB条件语句的广泛应用场景,涵盖了从图像处理到机器学习、从数据分析到控制系统等各个领域。专栏文章提供了10个具体应用场景,并针对性能优化、常见陷阱、单元测试和调试技巧等方面提供了详细的指导。此外,专栏还探讨了条件语句在面向对象编程、并行计算、云计算、物联网、金融建模、生物信息学和医学影像等领域的应用。通过这些深入的分析和实用指南,专栏旨在帮助读者充分掌握MATLAB条件语句,提升代码效率、可靠性和可维护性,从而在各种应用场景中发挥其强大功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Odroid XU4与Raspberry Pi比较分析
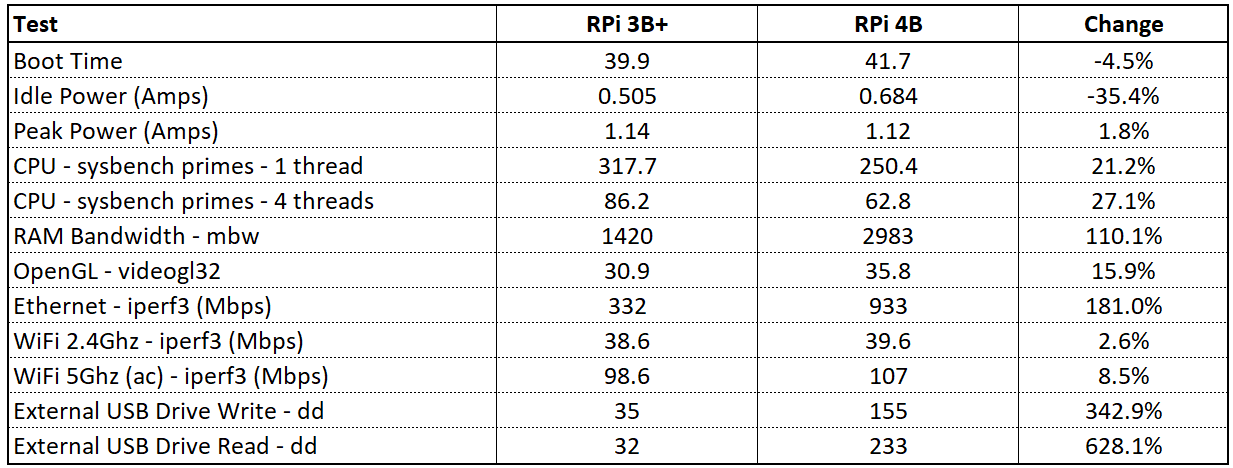
# 摘要
本文详细比较了Odroid XU4与Raspberry Pi的硬件规格、操作系统兼容性、性能测试与应用场景分析,并进行了成本效益分析。通过对比处理器性能、内存存储能力、扩展性和连接性等多个维度,揭示了两款单板计算机的优劣。文章还探讨了它们在图形处理、视频播放、科学计算和IoT应用等方面的实际表现,并对初次购买成本与长期运营维护成本进行了
WinRAR CVE-2023-38831漏洞全生命周期管理:从漏洞到补丁

# 摘要
WinRAR CVE-2023-38831漏洞的发现引起了广泛关注,本文对这一漏洞进行了全面概述和分析。我们深入探讨了漏洞的技术细节、成因、利用途径以及受影响的系统和应用版本,评估了漏洞的潜在风险和影响等级。文章还提供了详尽的漏洞应急响应策略,包括初步的临时缓解措施、长期修复
【数据可视化个性定制】:用Origin打造属于你的独特图表风格

# 摘要
随着数据科学的发展,数据可视化已成为传达复杂信息的关键手段。本文详细介绍了Origin软件在数据可视化领域的应用,从基础图表定制到高级技巧,再到与其他工具的整合,最后探讨了最佳实践和未来趋势。通过Origin丰富的图表类型、强大的数据处理工具和定制化脚本功能,用户能够深入分析数据并创建直观的图表。此外,本文还探讨了如何利用Origin的自动化和网络功能实现高效的数据可视化协作和分享。通
【初学者到专家】:LAPD与LAPDm帧结构的学习路径与进阶策略
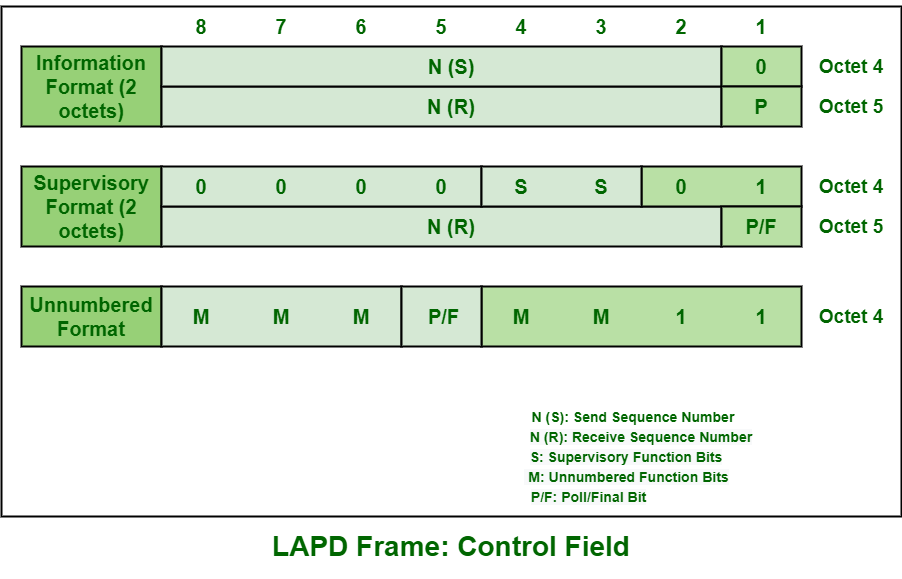
# 摘要
本文全面阐述了LAPD(Link Access Procedure on the D-channel)和LAPDm(LAPD modified)协议的帧结构及其相关理论,并深入探讨了这两种协议在现代通信网络中的应用和重要性。首先,对LAPD和LAPDm的帧结构进行概述,重点分析其组成部分与控制字段。接着,深入解析这两种协议的基础理论,包括历史发展、主要功能与特点
医学成像革新:IT技术如何重塑诊断流程

# 摘要
本文系统探讨了医学成像技术的历史演进、IT技术在其中的应用以及对诊断流程带来的革新。文章首先回顾了医学成像的历史与发展,随后深入分析了IT技术如何改进成像设备和数据管理,特别是数字化技术与PACS的应用。第三章着重讨论了IT技术如何提升诊断的精确性和效率,并阐述了远程医疗和增强现实技术在医学教育和手术规划中的应用。接着,文章探讨了数据安全与隐私保护的挑战,以及加密
TriCore工具链集成:构建跨平台应用的链接策略与兼容性解决

# 摘要
本文对TriCore工具链在跨平台应用构建中的集成进行了深入探讨。文章首先概述了跨平台开发的理论基础,包括架构差异、链接策略和兼容性问题的分析。随后,详细介绍了TriCore工具链的配置、优化以及链接策略的实践应用,并对链接过程中的兼容性
【ARM调试技巧大公开】:在ARMCompiler-506中快速定位问题

# 摘要
本文详述了ARM架构的调试基础,包括ARM Compiler-506的安装配置、程序的编译与优化、调试技术精进、异常处理与排错,以及调试案例分析与实战。文中不仅提供安装和配置ARM编译器的具体步骤,还深入探讨了代码优化、工具链使用、静态和动态调试、性能分析等技术细节。同时,本文还对ARM异常机制进行了解
【远程桌面工具稳定安全之路】:源码控制与版本管理策略
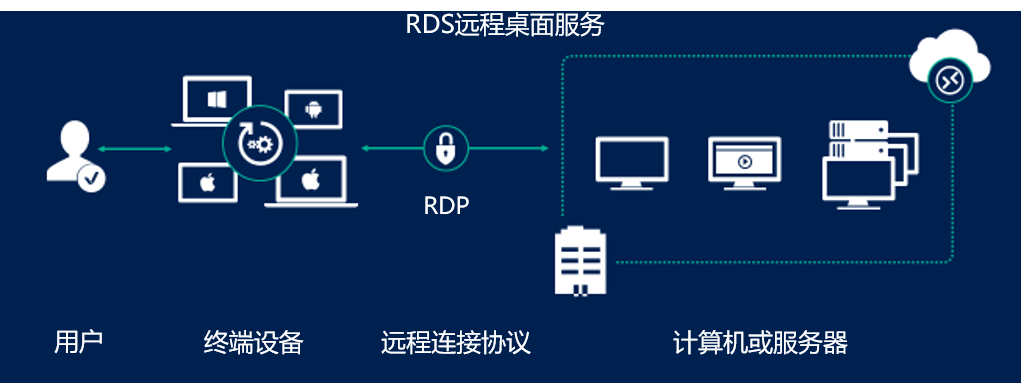
# 摘要
本文系统地介绍了远程桌面工具与源码控制系统的概念、基础和实战策略。文章首先概述了远程桌面工具的重要性,并详细介绍了源码控制系统的理论基础和工具分类,包括集中式与分布式源码控制工具以及它们的工作流程。接着,深入讨论了版本管理策略,包括版本号规范、分支模型选择和最佳实践。本文还探讨了远程桌面工具源码控制策略中的安全、权限管理、协作流程及持续集成。最后,文章展望了版本管理工具与
【网络连接优化】:用AT指令提升MC20芯片连接性能,效率翻倍(权威性、稀缺性、数字型)

# 摘要
随着物联网设备的日益普及,MC20芯片在移动网络通信中的作用愈发重要。本文首先概述了网络连接优化的重要性,接着深入探讨了AT指令与MC20芯片的通信原理,包括AT指令集的发展历史、结构和功能,以及MC20芯片的网络协议栈。基于理论分析,本文阐述了AT指令优化网络连接的理论基础,着重于网络延迟、吞吐量和连接质量的评估。实
【系统稳定性揭秘】:液态金属如何提高计算机物理稳定性
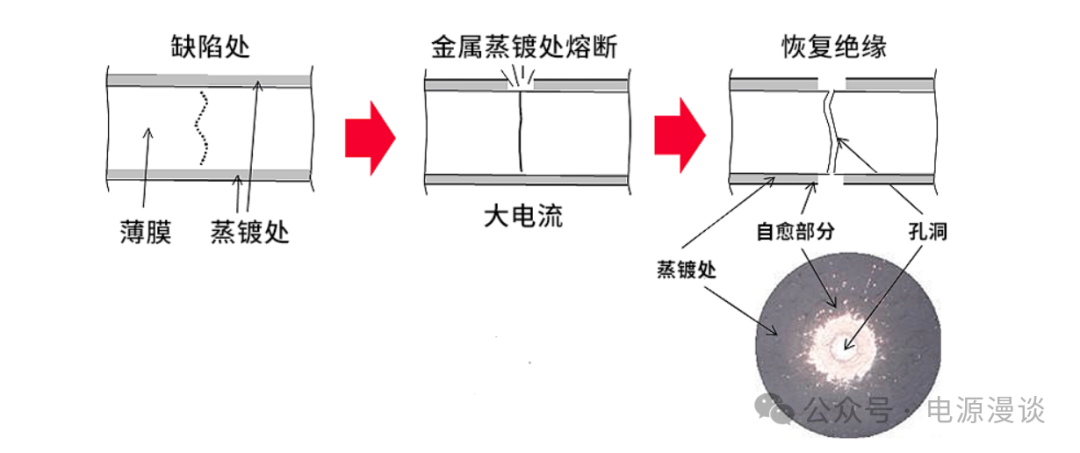
# 摘要
随着计算机硬件性能的不断提升,计算机物理稳定性面临着前所未有的挑战。本文综述了液态金属在增强计算机稳定性方面的潜力和应用。首先,文章介绍了液态金属的理论基础,包括其性质及其在计算机硬件中的应用。其次,通过案例分析,探讨了液态金属散热和连接技术的实践,以及液态金属在提升系统稳定性方面的实际效果。随后,对液态金属技术与传统散热材
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )