Python连接SQL Server数据库的底层原理:掌握核心技术
发布时间: 2024-06-24 21:53:48 阅读量: 77 订阅数: 34 
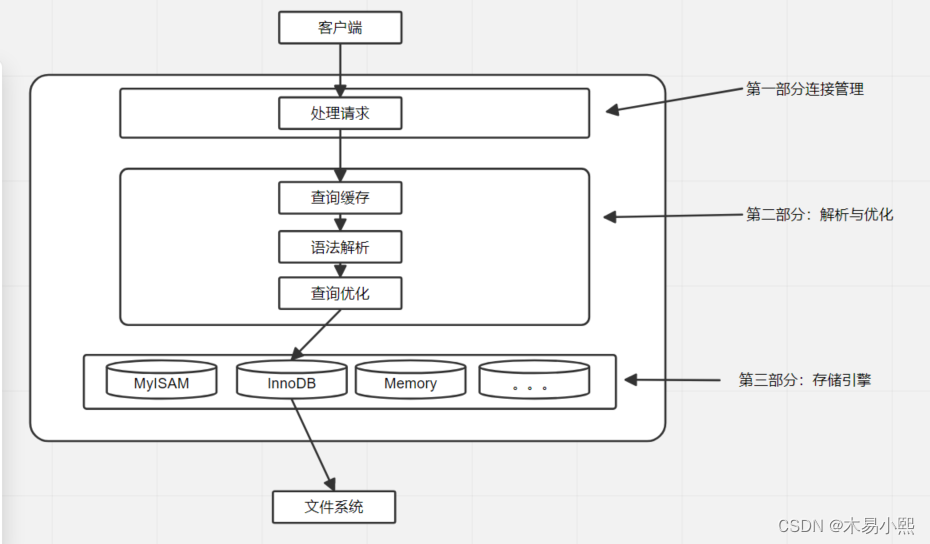
# 1. Python连接SQL Server数据库概述**
Python连接SQL Server数据库是一种常见且重要的任务,它使Python程序能够访问和操作SQL Server中的数据。Python提供了多种模块和库,用于连接和操作SQL Server数据库,例如pyodbc、sqlalchemy和psycopg2。这些模块提供了不同的功能和接口,以满足各种连接和查询需求。
在本章中,我们将介绍Python连接SQL Server数据库的基本概念和方法。我们将讨论Python与SQL Server之间的通信协议、数据库连接池机制以及Python数据库连接模块的实现。通过了解这些基础知识,您将能够在Python程序中有效地连接和操作SQL Server数据库。
# 2. Python连接SQL Server数据库的底层原理
### 2.1 Python与SQL Server的通信协议
Python与SQL Server数据库之间的通信是通过网络协议进行的。常用的协议包括:
- **TCP/IP**:最常用的协议,提供可靠的连接和数据传输。
- **Named Pipes**:仅适用于Windows系统,提供比TCP/IP更快的连接速度。
- **Shared Memory**:仅适用于Windows系统,提供最快的连接速度,但安全性较低。
### 2.2 SQL Server数据库连接池机制
为了提高数据库连接的效率,SQL Server提供了连接池机制。连接池是一个预先创建好的数据库连接集合,当应用程序需要连接数据库时,可以从连接池中获取一个可用连接,使用完毕后归还给连接池。
连接池机制的主要优点:
- **减少连接开销**:创建和销毁数据库连接是耗时的操作,连接池可以避免频繁创建和销毁连接,从而提高性能。
- **提高并发性**:连接池可以同时处理多个并发连接,从而提高应用程序的并发处理能力。
- **故障恢复**:如果连接池中的某个连接出现故障,连接池可以自动创建新的连接,保证应用程序的连续性。
### 2.3 Python数据库连接模块的实现
Python提供了多种数据库连接模块,可以用来连接SQL Server数据库,包括:
- **pyodbc**:一个使用Open Database Connectivity (ODBC)接口的模块,支持连接多种数据库,包括SQL Server。
- **sqlalchemy**:一个对象关系映射(ORM)工具,支持连接多种数据库,包括SQL Server。
- **psycopg2**:一个使用PostgreSQL接口的模块,也可以用来连接SQL Server。
这些模块提供了不同的连接方式和功能,开发者可以根据自己的需要选择合适的模块。
#### 代码块:使用pyodbc模块连接SQL Server数据库
```python
import pyodbc
# 连接参数
server = 'server_name'
database = 'database_name'
username = 'username'
password = 'password'
# 创建连接字符串
connection_string = f'DRIVER={{SQL Server}};SERVER={server};DATABASE={database};UID={username};PWD={password}'
# 创建连接
connection = pyodbc.connect(connection_string)
# 执行查询
cursor = connection.cursor()
cursor.execute('SELECT * FROM table_name')
# 获取查询结果
rows = cursor.fetchall()
# 关闭连接
cursor.close()
connection.close()
```
#### 代码逻辑分析
1. 导入pyodbc模块。
2. 定义连接参数,包括服务器名称、数据库名称、用户名和密码。
3. 使用连接参数创建连接字符串。
4. 使用连接字符串创建连接对象。
5. 创建游标对象,用于执行查询。
6. 使用游标对象执行查询,并将结果存储在rows变量中。
7. 关闭游标对象和连接对象。
# 3. Python连接SQL Server数据库的实践
### 3.1 使用pyodbc模块连接SQL Server数据库
pyodbc是Python中连接SQL Server数据库的常用模块,它通过ODBC(开放数据库连接)接口与数据库进行交互。使用pyodbc连接SQL Server数据库的步骤如下:
1. 安装pyodbc模块:`pip install pyodbc`
2. 导入pyodbc模块:`import pyodbc`
3. 创建连接字符串:连接字符串指定了数据库服务器、数据库名称、用户名和密码等信息。例如:
```
connection_string = 'DRIVER={SQL Server};SERVER=localhost;DATABASE=my_database;UID=my_username;PWD=my_password'
```
4. 创建连接对象:使用`pyodbc.connect()`函数创建连接对象。
```
connection = pyodbc.connect(connection_string)
```
5. 创建游标对象:游标对象用于执行SQL语句和获取查询结果。
```
cursor = connection.cursor()
```
6. 执行SQL语句:使用`cursor.execute()`方法执行SQL语句。
```
cursor.execute('SELECT * FROM my_table')
```
7. 获取查询结果:使用`cursor.fetchall()`方法获取查询结果。
```
results = cursor.fetchall()
```
8. 关闭游标和连接:执行完操作后,应关闭游标和连接对象。
```
cursor.close()
connection.close()
```
### 3.2 使用sqlalchemy模块连接SQL Server数据库
sqlalchemy是一个功能强大的Python ORM(对象关系映射)框架,它可以简化数据库操作。使用sqlalchemy连接SQL Server数据库的步骤如下:
1. 安装sqlalchemy模块:`pip install sqlalchemy`
2. 导入sqlalchemy模块:`import sqlalchemy`
3. 创建引擎对象:引擎对象是sqlalchemy与数据库交互的核心组件。
```
engine = sqlalchemy.create_engine('mssql+pytds://my_username:my_password@localhost/my_database')
```
4. 创建会话对象:会话对象用于管理数据库事务和操作。
```
session = engine.connect()
```
5. 执行SQL语句:使用`session.execute()`方法执行SQL语句。
```
results = session.execute('SELECT * FROM my_table')
```
6. 获取查询结果:使用`results.fetchall()`方法获取查询结果。
```
results = results.fetchall()
```
7. 关闭会话:执行完操作后,应关闭会话对象。
```
session.close()
```
### 3.3 使用psycopg2模块连接SQL Server数据库
psycopg2是Python中连接PostgreSQL数据库的常用模块,但它也可以通过安装psycopg2-sqlserver扩展来连接SQL Server数据库。使用psycopg2连接SQL Server数据库的步骤如下:
1. 安装psycopg2和psycopg2-sqlserver扩展:`pip install psycopg2 psycopg2-sqlserver`
2. 导入psycopg2模块:`import psycopg2`
3. 创建连接字符串:连接字符串指定了数据库服务器、数据库名称、用户名和密码等信息。例如:
```
connection_string = 'host=localhost dbname=my_database user=my_username password=my_password'
```
4. 创建连接对象:使用`psycopg2.connect()`函数创建连接对象。
```
connection = psycopg2.connect(connection_string)
```
5. 创建游标对象:游标对象用于执行SQL语句和获取查询结果。
```
cursor = connection.cursor()
```
6. 执行SQL语句:使用`cursor.execute()`方法执行SQL语句。
```
cursor.execute('SELECT * FROM my_table')
```
7. 获取查询结果:使用`cursor.fetchall()`方法获取查询结果。
```
results = cursor.fetchall()
```
8. 关闭游标和连接:执行完操作后,应关闭游标和连接对象。
```
cursor.close()
connection.close()
```
# 4. Python连接SQL Server数据库的高级应用
### 4.1 使用事务处理机制保证数据一致性
事务处理机制是数据库系统中保证数据一致性的重要机制。在Python中,可以通过使用`with`语句来管理事务。
```python
import pyodbc
# 建立数据库连接
conn = pyodbc.connect('Driver={SQL Server};Server=localhost;Database=test;Trusted_Connection=Yes;')
# 开始事务
with conn.cursor() as cursor:
# 执行SQL语句
cursor.execute("UPDATE users SET name='John' WHERE id=1")
cursor.execute("INSERT INTO orders (user_id, product_id, quantity) VALUES (1, 2, 3)")
# 提交事务
conn.commit()
```
在事务块中执行的所有操作要么全部成功,要么全部失败。如果事务中任何操作失败,整个事务将回滚,数据库状态将恢复到事务开始前的状态。
### 4.2 使用存储过程和函数提升性能
存储过程和函数是预编译的SQL代码块,可以存储在数据库中并被多次调用。使用存储过程和函数可以提升性能,因为它们避免了每次执行SQL语句时都需要重新编译。
**创建存储过程**
```sql
CREATE PROCEDURE GetUserInfo
(
@UserId int
)
AS
BEGIN
SELECT * FROM users WHERE id = @UserId
END
```
**调用存储过程**
```python
import pyodbc
# 建立数据库连接
conn = pyodbc.connect('Driver={SQL Server};Server=localhost;Database=test;Trusted_Connection=Yes;')
# 创建游标
cursor = conn.cursor()
# 执行存储过程
cursor.execute("{CALL GetUserInfo(?)}", 1)
# 提取结果
for row in cursor.fetchall():
print(row)
```
**创建函数**
```sql
CREATE FUNCTION GetUserName
(
@UserId int
)
RETURNS VARCHAR(50)
AS
BEGIN
DECLARE @Name VARCHAR(50)
SELECT @Name = name FROM users WHERE id = @UserId
RETURN @Name
END
```
**调用函数**
```python
import pyodbc
# 建立数据库连接
conn = pyodbc.connect('Driver={SQL Server};Server=localhost;Database=test;Trusted_Connection=Yes;')
# 创建游标
cursor = conn.cursor()
# 执行函数
result = cursor.execute("{? = CALL GetUserName(?)}", (pyodbc.SQL_VARBINARY(-1), 1))
# 提取结果
print(result.fetchone()[0])
```
### 4.3 使用游标处理大数据集
游标是数据库系统中用于遍历结果集的机制。在Python中,可以使用`cursor.execute()`方法返回一个游标对象。
```python
import pyodbc
# 建立数据库连接
conn = pyodbc.connect('Driver={SQL Server};Server=localhost;Database=test;Trusted_Connection=Yes;')
# 创建游标
cursor = conn.cursor()
# 执行SQL语句
cursor.execute("SELECT * FROM orders")
# 遍历结果集
for row in cursor.fetchall():
print(row)
```
游标还可以用于逐行处理大数据集,避免一次性加载所有数据到内存中。
```python
import pyodbc
# 建立数据库连接
conn = pyodbc.connect('Driver={SQL Server};Server=localhost;Database=test;Trusted_Connection=Yes;')
# 创建游标
cursor = conn.cursor()
# 执行SQL语句
cursor.execute("SELECT * FROM orders")
# 逐行处理结果集
while True:
row = cursor.fetchone()
if not row:
break
print(row)
```
# 5. Python连接SQL Server数据库的性能优化
### 5.1 优化数据库连接池配置
数据库连接池是一种管理数据库连接的机制,它可以提高数据库连接的效率和性能。Python中常用的数据库连接池有:
- pyodbc.pool
- sqlalchemy.pool
- psycopg2.pool
优化数据库连接池配置可以从以下几个方面入手:
- **连接池大小:**连接池的大小决定了可以同时建立的最大连接数。连接池大小应根据应用程序的并发量和数据库负载进行调整。
- **连接超时:**连接超时是指连接池中空闲连接的最长生存时间。连接超时应根据数据库的连接释放策略进行设置。
- **回收策略:**连接池的回收策略决定了连接池如何处理空闲连接。常见的回收策略有:
- **FIFO(先进先出):**回收最老的空闲连接。
- **LRU(最近最少使用):**回收最近最少使用的空闲连接。
- **定期回收:**定期回收所有空闲连接。
### 5.2 优化SQL语句执行效率
优化SQL语句执行效率可以从以下几个方面入手:
- **使用参数化查询:**参数化查询可以防止SQL注入攻击,并提高查询性能。
- **使用索引:**索引可以加快数据查询速度。应根据查询模式创建适当的索引。
- **避免使用SELECT *:**只查询需要的列,可以减少数据传输量和提高查询速度。
- **使用批处理:**将多个SQL语句合并成一个批处理,可以减少网络开销和提高性能。
### 5.3 优化数据传输方式
优化数据传输方式可以从以下几个方面入手:
- **使用二进制数据类型:**二进制数据类型可以减少数据传输量和提高传输速度。
- **使用压缩:**压缩数据可以减少数据传输量和提高传输速度。
- **使用异步传输:**异步传输可以提高数据传输的并发性,从而提高性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面介绍了 Python 连接 SQL Server 数据库的方方面面,从入门到精通,一应俱全。它深入探讨了连接过程中的常见陷阱和疑难杂症,揭示了底层原理,并提供了性能调优秘诀。此外,专栏还涵盖了事务处理、并发控制、高级查询、数据操作、数据迁移、安全管理、故障排除、最佳实践、连接池优化、异步编程、大数据处理、云端部署、跨平台集成、面向对象编程、数据可视化、机器学习和区块链应用等高级主题。通过阅读本专栏,读者可以掌握 Python 连接 SQL Server 数据库的全面知识和技能,提升数据操作效率,解锁数据价值,并探索新兴技术。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VR_AR技术学习与应用:学习曲线在虚拟现实领域的探索

# 1. 虚拟现实技术概览
虚拟现实(VR)技术,又称为虚拟环境(VE)技术,是一种使用计算机模拟生成的能与用户交互的三维虚拟环境。这种环境可以通过用户的视觉、听觉、触觉甚至嗅觉感受到,给人一种身临其境的感觉。VR技术是通过一系列的硬件和软件来实现的,包括头戴显示器、数据手套、跟踪系统、三维声音系统、高性能计算机等。
VR技术的应用
特征贡献的Shapley分析:深入理解模型复杂度的实用方法
# 1. 特征贡献的Shapley分析概述
在数据科学领域,模型解释性(Model Explainability)是确保人工智能(AI)应用负责任和可信赖的关键因素。机器学习模型,尤其是复杂的非线性模型如深度学习,往往被认为是“黑箱”,因为它们的内部工作机制并不透明。然而,随着机器学习越来越多地应用于关键决策领域,如金融风控、医疗诊断和交通管理,理解模型的决策过程变得至关重要
贝叶斯优化软件实战:最佳工具与框架对比分析
# 1. 贝叶斯优化的基础理论
贝叶斯优化是一种概率模型,用于寻找给定黑盒函数的全局最优解。它特别适用于需要进行昂贵计算的场景,例如机器学习模型的超参数调优。贝叶斯优化的核心在于构建一个代理模型(通常是高斯过程),用以估计目标函数的行为,并基于此代理模型智能地选择下一点进行评估。
## 2.1 贝叶斯优化的基本概念
### 2.1.1 优化问题的数学模型
贝叶斯优化的基础模型通常包括目标函数 \(f(x)\),目标函数的参数空间 \(X\) 以及一个采集函数(Acquisition Function),用于决定下一步的探索点。目标函数 \(f(x)\) 通常是在计算上非常昂贵的,因此需
激活函数在深度学习中的应用:欠拟合克星
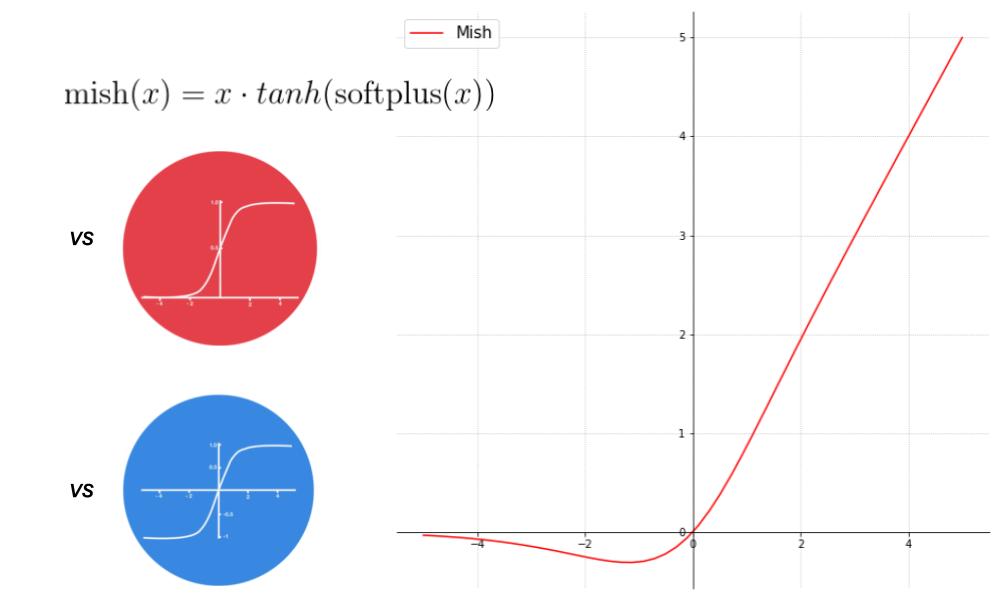
# 1. 深度学习中的激活函数基础
在深度学习领域,激活函数扮演着至关重要的角色。激活函数的主要作用是在神经网络中引入非线性,从而使网络有能力捕捉复杂的数据模式。它是连接层与层之间的关键,能够影响模型的性能和复杂度。深度学习模型的计算过程往往是一个线性操作,如果没有激活函数,无论网络有多少层,其表达能力都受限于一个线性模型,这无疑极大地限制了模型在现实问题中的应用潜力。
激活函数的基本
正则化技术详解:L1、L2与Elastic Net在过拟合防控中的应用

# 1. 正则化技术的理论基础
## 1.1 机器学习中的泛化问题
在机器学习中,泛化能力是指模型对未知数据的预测准确性。理想情况下,我们希望模型不仅在训练数据上表现良好,而且能够准确预测新样本。然而,在实践中经常遇到过拟合问题,即模型对训练数据过度适应,失去了良好的泛化能力。
## 1.2 过拟合与正则化的关系
过拟合是模型复杂度过高导致的泛化能力下降。正则化技术作为一种常见的解决
【统计学意义的验证集】:理解验证集在机器学习模型选择与评估中的重要性
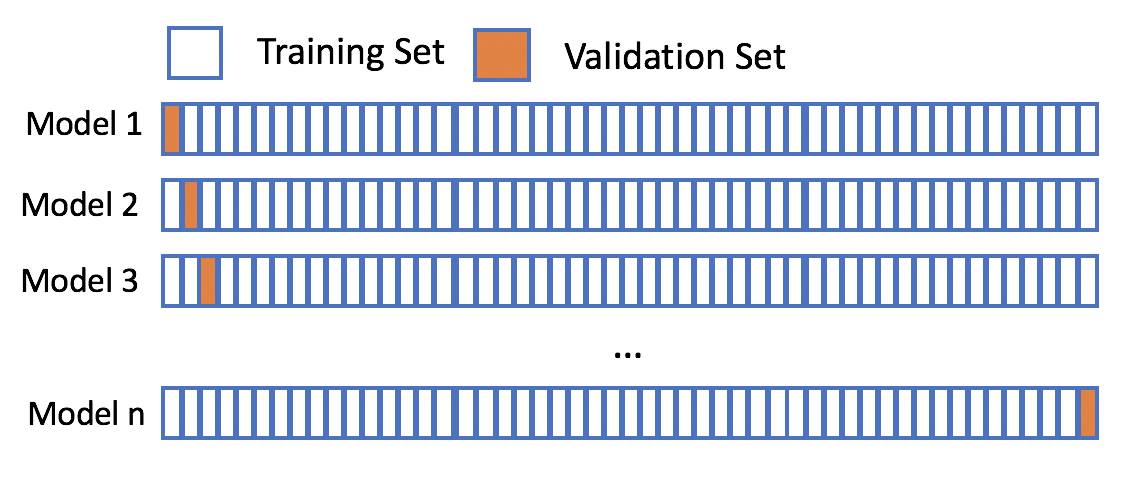
# 1. 验证集的概念与作用
在机器学习和统计学中,验证集是用来评估模型性能和选择超参数的重要工具。**验证集**是在训练集之外的一个独立数据集,通过对这个数据集的预测结果来估计模型在未见数据上的表现,从而避免了过拟合问题。验证集的作用不仅仅在于选择最佳模型,还能帮助我们理解模型在实际应用中的泛化能力,是开发高质量预测模型不可或缺的一部分。
```markdown
## 1.1 验证集与训练集、测试集的区
机器学习调试实战:分析并优化模型性能的偏差与方差
# 1. 机器学习调试的概念和重要性
## 什么是机器学习调试
机器学习调试是指在开发机器学习模型的过程中,通过识别和解决模型性能不佳的问题来改善模型预测准确性的过程。它是模型训练不可或缺的环节,涵盖了从数据预处理到最终模型部署的每一个步骤。
## 调试的重要性
有效的调试能够显著提高模型的泛化能力,即在未见过的数据上也能作出准确预测的能力。没有经过适当调试的模型可能无法应对实
网格搜索:多目标优化的实战技巧

# 1. 网格搜索技术概述
## 1.1 网格搜索的基本概念
网格搜索(Grid Search)是一种系统化、高效地遍历多维空间参数的优化方法。它通过在每个参数维度上定义一系列候选值,并
过拟合的统计检验:如何量化模型的泛化能力

# 1. 过拟合的概念与影响
## 1.1 过拟合的定义
过拟合(overfitting)是机器学习领域中一个关键问题,当模型对训练数据的拟合程度过高,以至于捕捉到了数据中的噪声和异常值,导致模型泛化能力下降,无法很好地预测新的、未见过的数据。这种情况下的模型性能在训练数据上表现优异,但在新的数据集上却表现不佳。
## 1.2 过拟合产生的原因
过拟合的产生通常与模
随机搜索在强化学习算法中的应用

# 1. 强化学习算法基础
强化学习是一种机器学习方法,侧重于如何基于环境做出决策以最大化某种累积奖励。本章节将为读者提供强化学习算法的基础知识,为后续章节中随机搜索与强化学习结合的深入探讨打下理论基础。
## 1.1 强化学习的概念和框架
强化学习涉及智能体(Agent)与环境(Environment)之间的交互。智能体通过执行动作(Action)影响环境,并根据环境的反馈获得奖
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )