揭秘贝叶斯推断的强大力量:从机器学习到自然语言处理
发布时间: 2024-07-14 12:54:21 阅读量: 60 订阅数: 41 

AI Paper阅读记录与收藏:机器学习/深度学习/自然语言处理/计算机视觉/智能语音/推荐系统/知识图谱
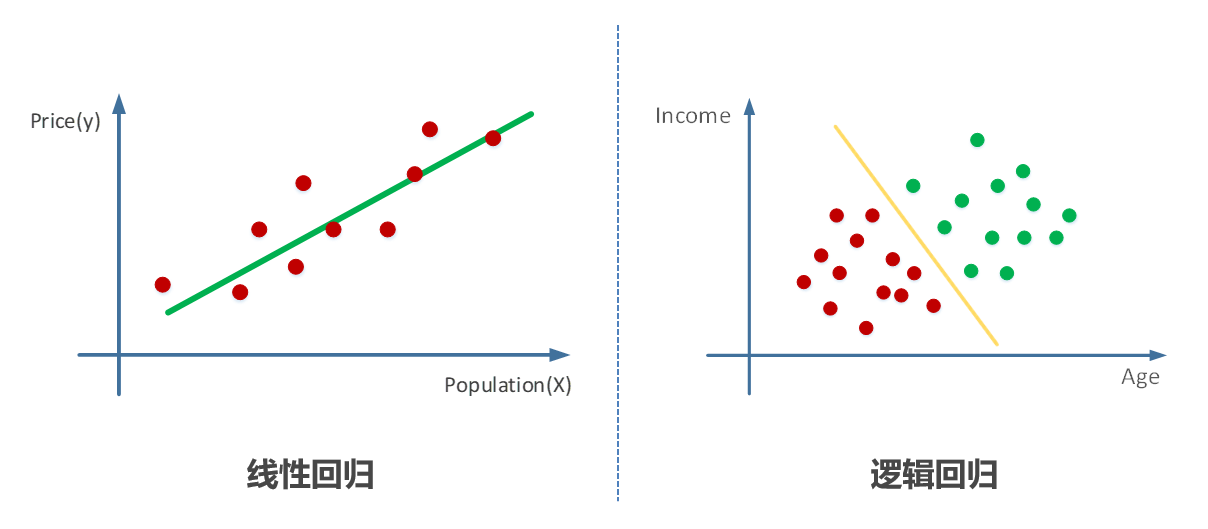
# 1. 贝叶斯推断基础
贝叶斯推断是一种概率推理方法,它利用贝叶斯定理来更新事件的概率分布。与传统的频率派推理不同,贝叶斯推断将先验知识纳入考虑范围,从而得出更准确的结论。
贝叶斯定理的公式为:
```
P(A|B) = (P(B|A) * P(A)) / P(B)
```
其中:
* P(A|B) 是在事件 B 发生的情况下事件 A 发生的概率(后验概率)
* P(B|A) 是在事件 A 发生的情况下事件 B 发生的概率(似然度)
* P(A) 是事件 A 的先验概率
* P(B) 是事件 B 的概率(证据)
# 2. 贝叶斯推断在机器学习中的应用
贝叶斯推断在机器学习领域有着广泛的应用,特别是在分类和时序建模方面。本章节将介绍两种经典的贝叶斯机器学习模型:朴素贝叶斯分类器和隐马尔可夫模型。
### 2.1 朴素贝叶斯分类器
#### 2.1.1 原理和算法
朴素贝叶斯分类器是一种基于贝叶斯定理的简单而有效的分类算法。其核心假设是给定类标签,特征之间相互独立。虽然这一假设在实际应用中并不总是成立,但朴素贝叶斯分类器在许多情况下仍然表现出色。
朴素贝叶斯分类器的算法如下:
1. **训练阶段:**
- 计算每个特征在每个类标签下的先验概率。
- 计算每个特征在每个类标签下的条件概率。
2. **预测阶段:**
- 对于一个新的数据点,计算其在每个类标签下的后验概率。
- 将数据点分配给后验概率最高的类标签。
#### 2.1.2 优势和劣势
朴素贝叶斯分类器具有以下优势:
- **简单易懂:**算法简单明了,易于实现和解释。
- **计算效率高:**训练和预测过程都非常高效,即使对于大型数据集。
- **对缺失值鲁棒:**即使数据集中存在缺失值,朴素贝叶斯分类器也能正常工作。
然而,朴素贝叶斯分类器也有一些劣势:
- **特征独立性假设:**特征独立性假设可能不适用于所有数据集,这可能会影响分类器的准确性。
- **对噪声敏感:**朴素贝叶斯分类器对噪声数据敏感,这可能会导致分类错误。
- **容易过拟合:**当训练数据集中存在大量特征时,朴素贝叶斯分类器容易过拟合。
### 2.2 隐马尔可夫模型
#### 2.2.1 原理和算法
隐马尔可夫模型 (HMM) 是一种时序建模算法,用于处理具有隐藏状态的序列数据。HMM 假设观测到的数据是由一个隐藏的马尔可夫链生成的。
HMM 的算法如下:
1. **训练阶段:**
- 确定隐藏状态的数量和观测符号的集合。
- 估计隐藏状态之间的转移概率和观测符号的生成概率。
2. **预测阶段:**
- 给定一个观测序列,使用维特比算法或前向-后向算法来计算隐藏状态序列。
#### 2.2.2 应用场景
HMM 在自然语言处理、语音识别和生物信息学等领域有着广泛的应用。例如:
- **语音识别:**HMM 用于对语音信号进行建模,识别不同的语音单元。
- **自然语言处理:**HMM 用于对文本进行分词和词性标注。
- **生物信息学:**HMM 用于对基因序列进行建模和分析。
# 3. 贝叶斯推断在自然语言处理中的应用
### 3.1 文本分类
#### 3.1.1 朴素贝叶斯分类器在文本分类中的应用
朴素贝叶斯分类器是一种基于贝叶斯定理的文本分类算法。它假设文本中的特征是相互独立的,这虽然在现实中并不完全成立,但朴素贝叶斯分类器在实践中仍然表现出良好的分类效果。
**原理和算法:**
朴素贝叶斯分类器的工作原理如下:
1. **特征提取:**从文本中提取特征,如词频、词干、词性等。
2. **概率计算:**计算每个特征在不同类别下的概率。
3. **贝叶斯定理:**根据贝叶斯定理,计算每个文本属于不同类别的概率。
4. **分类:**将文本分配给概率最高的类别。
**代码示例:**
```python
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer
# 训练数据
X_train = ["This is a good movie.", "This is a bad movie."]
y_train = [1, 0]
# 特征提取
vectorizer = CountVectorizer()
X_train_counts = vectorizer.fit_transform(X_train)
# 训练朴素贝叶斯分类器
clf = MultinomialNB()
clf.fit(X_train_counts, y_train)
# 测试数据
X_test = ["This is a great movie."]
# 特征提取
X_test_counts = vectorizer.transform(X_test)
# 预测
y_pred = clf.predict(X_test_counts)
```
**逻辑分析:**
* `CountVectorizer` 将文本转换为特征向量,其中每个元素表示一个单词的出现次数。
* `MultinomialNB` 使用多项式分布来估计特征的概率。
* `fit()` 方法训练分类器,学习特征和类别之间的关系。
* `predict()` 方法使用训练好的模型对新文本进行分类。
#### 3.1.2 隐马尔可夫模型在文本分类中的应用
隐马尔可夫模型(HMM)是一种基于概率论的文本分类算法,它假设文本中的单词序列是由一个隐藏的马尔可夫链产生的。
**原理和算法:**
HMM 的工作原理如下:
1. **状态定义:**定义文本分类的可能状态,如正面、负面、中立等。
2. **状态转移概率:**计算从一个状态转移到另一个状态的概率。
3. **发射概率:**计算在每个状态下观察到特定单词的概率。
4. **维特比算法:**使用维特比算法找到最可能的单词序列和对应的状态序列。
5. **分类:**将文本分配给最可能的隐藏状态。
**代码示例:**
```python
import hmmlearn.hmm
import nltk
# 训练数据
sentences = ["This is a good movie.", "This is a bad movie."]
labels = ["positive", "negative"]
# 特征提取
tokenizer = nltk.word_tokenize
X_train = [tokenizer(sentence) for sentence in sentences]
y_train = labels
# 训练 HMM
hmm = hmmlearn.hmm.MultinomialHMM()
hmm.fit(X_train, y_train)
# 测试数据
X_test = ["This is a great movie."]
# 预测
y_pred = hmm.predict(X_test)
```
**逻辑分析:**
* `MultinomialHMM` 使用多项式分布来估计发射概率。
* `fit()` 方法训练 HMM,学习状态转移概率和发射概率。
* `predict()` 方法使用训练好的模型对新文本进行分类。
### 3.2 语言模型
#### 3.2.1 贝叶斯推断在语言模型中的应用
贝叶斯推断可以用于构建语言模型,预测文本中下一个单词的概率。
**原理和算法:**
基于贝叶斯推断的语言模型的工作原理如下:
1. **先验概率:**估计每个单词的先验概率。
2. **条件概率:**估计给定前面单词的情况下每个单词的条件概率。
3. **贝叶斯定理:**根据贝叶斯定理,计算给定前面单词序列的情况下每个单词的后验概率。
**代码示例:**
```python
import nltk
import numpy as np
# 训练数据
sentences = ["This is a good movie.", "This is a bad movie."]
# 特征提取
tokenizer = nltk.word_tokenize
X_train = [tokenizer(sentence) for sentence in sentences]
# 计算先验概率
word_counts = nltk.FreqDist(np.concatenate(X_train))
total_words = sum(word_counts.values())
prior_probs = {word: count / total_words for word, count in word_counts.items()}
# 计算条件概率
transition_counts = nltk.ConditionalFreqDist(X_train)
conditional_probs = {
(prev_word, word): count / transition_counts[prev_word].N()
for prev_word, word, count in transition_counts.items()
}
# 预测下一个单词
prev_words = ["This", "is"]
next_word_probs = {
word: prior_probs[word] * conditional_probs.get((prev_words[-1], word), 0)
for word in word_counts
}
```
**逻辑分析:**
* `FreqDist` 计算每个单词的出现次数。
* `ConditionalFreqDist` 计算给定前面单词的情况下每个单词的出现次数。
* `prior_probs` 和 `conditional_probs` 分别存储先验概率和条件概率。
* `next_word_probs` 计算给定前面单词序列的情况下每个单词的后验概率。
# 4.1 贝叶斯推断在医学诊断中的应用
### 4.1.1 贝叶斯推断在医学诊断中的原理
贝叶斯推断在医学诊断中的应用遵循贝叶斯定理的原理,该定理将先验概率(基于现有知识的概率)与似然函数(基于观察结果的概率)相结合,以计算后验概率(更新后的概率)。
**贝叶斯定理:**
```
P(A|B) = (P(B|A) * P(A)) / P(B)
```
其中:
* P(A|B) 是在已知 B 的情况下 A 发生的概率(后验概率)
* P(B|A) 是在已知 A 的情况下 B 发生的概率(似然函数)
* P(A) 是 A 发生的先验概率
* P(B) 是 B 发生的概率(边缘概率)
### 4.1.2 贝叶斯推断在医学诊断中的优势
贝叶斯推断在医学诊断中具有以下优势:
* **处理不确定性:**它允许医生在诊断过程中考虑不确定性,并根据新证据不断更新概率。
* **个性化诊断:**它可以将患者的个人病史和症状纳入考虑,从而提供个性化的诊断。
* **诊断复杂疾病:**它可以处理具有多个症状和潜在原因的复杂疾病,从而提高诊断准确性。
### 4.1.3 贝叶斯推断在医学诊断中的应用场景
贝叶斯推断在医学诊断中有着广泛的应用,包括:
* **疾病诊断:**诊断特定疾病,例如癌症、心脏病和感染。
* **风险评估:**评估患者患特定疾病的风险,例如心脏病发作或中风。
* **治疗决策:**确定最佳治疗方案,并根据患者的反应进行调整。
* **预后预测:**预测患者的预后,例如生存率或康复时间。
### 4.1.4 贝叶斯推断在医学诊断中的案例分析
**案例:诊断癌症**
考虑一个患者出现肿块的案例。医生可以通过以下步骤使用贝叶斯推断来诊断癌症:
1. **定义先验概率:**基于患者的年龄、性别和家族史等因素,确定患者患癌症的先验概率。
2. **收集似然函数:**进行检查(例如活检或成像)以收集有关肿块的证据。这些证据将用于计算似然函数。
3. **计算后验概率:**使用贝叶斯定理将先验概率与似然函数相结合,计算患者患癌症的后验概率。
4. **做出诊断:**根据后验概率,医生可以做出诊断,例如癌症或良性肿块。
### 4.1.5 贝叶斯推断在医学诊断中的局限性
尽管贝叶斯推断在医学诊断中具有优势,但它也存在一些局限性:
* **数据依赖性:**贝叶斯推断的结果高度依赖于先验概率和似然函数的准确性。
* **计算复杂度:**对于复杂模型,贝叶斯推断的计算可能非常耗时。
* **解释性:**贝叶斯推断的结果有时可能难以解释,这可能会影响其在临床实践中的采用。
# 5.1 计算复杂度
### 5.1.1 贝叶斯推断的计算复杂度问题
贝叶斯推断的计算复杂度主要体现在以下两个方面:
- **模型训练:**贝叶斯推断模型的训练通常需要迭代计算后验概率,这可能涉及到大量的参数和数据,导致计算量巨大。
- **推理:**在对新数据进行预测或分类时,贝叶斯推断需要计算后验概率,这同样可能涉及到大量的计算。
### 5.1.2 解决方法
为了解决贝叶斯推断的计算复杂度问题,研究人员提出了多种方法:
- **近似方法:**使用近似方法,如变分推断或蒙特卡罗采样,来近似后验概率的计算,从而降低计算复杂度。
- **并行计算:**利用并行计算技术,将计算任务分配到多个处理器或计算机上,以提高计算效率。
- **预先计算:**对于一些需要频繁推理的模型,可以预先计算后验概率并存储起来,以减少推理时的计算量。
- **模型简化:**通过简化模型结构或减少参数数量,可以降低模型的计算复杂度。
**代码块:**
```python
import numpy as np
from scipy.stats import norm
# 朴素贝叶斯分类器
class NaiveBayes:
def __init__(self, num_features):
self.num_features = num_features
self.priors = np.zeros(num_features)
self.means = np.zeros(num_features)
self.variances = np.zeros(num_features)
def fit(self, X, y):
for i in range(self.num_features):
# 计算先验概率
self.priors[i] = np.mean(y == i)
# 计算均值
self.means[i] = np.mean(X[y == i, i])
# 计算方差
self.variances[i] = np.var(X[y == i, i])
def predict(self, X):
# 计算后验概率
posteriors = np.zeros((X.shape[0], self.num_features))
for i in range(self.num_features):
posteriors[:, i] = norm.pdf(X[:, i], self.means[i], self.variances[i]) * self.priors[i]
# 预测类别
return np.argmax(posteriors, axis=1)
```
**代码逻辑分析:**
该代码实现了朴素贝叶斯分类器,它通过计算数据中每个特征的先验概率、均值和方差来训练模型。在预测时,它计算每个特征的后验概率,并预测具有最高后验概率的类别。
**参数说明:**
- `num_features`:特征数量
- `X`:训练数据
- `y`:训练标签
# 6. 贝叶斯推断的未来展望
### 6.1 新算法和方法
#### 6.1.1 贝叶斯推断新算法和方法的开发
贝叶斯推断领域正在不断发展,涌现出许多新的算法和方法,以克服传统方法的局限性并提高推理效率。这些新方法包括:
- **变分推断 (VI):**一种近似推断方法,通过优化变分分布来近似后验分布。VI 在处理大规模和复杂模型时特别有效。
- **采样算法:**如马尔可夫链蒙特卡罗 (MCMC) 和顺序蒙特卡罗 (SMC),这些算法通过生成后验分布的样本来近似推理。采样算法适用于无法解析计算后验分布的情况。
- **深度学习贝叶斯方法:**将深度学习模型与贝叶斯推断相结合,利用深度学习的表征能力和贝叶斯推断的概率建模优势。
### 6.1.2 应用场景和影响
这些新算法和方法的开发将对贝叶斯推断的应用产生重大影响:
- **更复杂模型的推理:**新算法允许推理更复杂和高维的模型,从而提高预测和决策的准确性。
- **大规模数据集处理:**变分推断和采样算法能够处理大规模数据集,使贝叶斯推断在处理现实世界问题时更加实用。
- **实时推理:**某些新算法,如在线变分推断,能够进行实时推理,使贝叶斯推断在动态环境中具有应用价值。
### 6.2 跨学科应用
#### 6.2.1 贝叶斯推断在跨学科领域的应用
贝叶斯推断的跨学科应用正在不断扩大,其概率建模和推理能力在以下领域具有巨大潜力:
- **生物信息学:**用于基因表达分析、疾病诊断和药物发现。
- **社会科学:**用于社会网络分析、舆情监测和行为预测。
- **物理学:**用于数据建模、参数估计和不确定性量化。
#### 6.2.2 潜在的突破和创新
贝叶斯推断在跨学科领域的应用将带来潜在的突破和创新:
- **个性化医疗:**通过结合患者数据和贝叶斯推断,实现个性化治疗计划和药物剂量优化。
- **社会网络分析:**利用贝叶斯推断识别社交网络中的影响者和社区结构,从而优化营销策略和公共政策。
- **物理建模:**通过贝叶斯推断处理不确定性,提高物理模型的精度和预测能力。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到贝叶斯推断的全面指南!本专栏深入探讨了贝叶斯推断的原理和应用,从机器学习到自然语言处理、计算机视觉、生物信息学、金融、医疗保健、工程、环境科学、教育、商业、制造业、交通和能源等领域。通过一系列深入的文章,您将了解贝叶斯网络、贝叶斯优化、贝叶斯模型选择以及贝叶斯推断在各个行业中的具体应用。无论您是刚接触贝叶斯推断的新手,还是希望深入了解其强大功能的经验丰富的专业人士,本专栏都将为您提供所需的知识和见解,让您掌握贝叶斯推断并将其应用于您的领域。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
紧急揭秘!防止Canvas转换中透明区域变色的5大技巧

# 摘要
Canvas作为Web图形API,广泛应用于现代网页设计与交互中。本文从Canvas转换技术的基本概念入手,深入探讨了在渲染过程中透明区域变色的理论基础和实践解决方案。文章详细解析了透明度和颜色模型,渲染流程以及浏览器渲染差异,并针对性地提供了预防透明区域变色的技巧。通过对Canvas上下文优化
超越MFCC:BFCC在声学特征提取中的崛起

# 摘要
声学特征提取是语音和音频处理领域的核心,对于提升识别准确率和系统的鲁棒性至关重要。本文首先介绍了声学特征提取的原理及应用,着重探讨
Flutter自定义验证码输入框实战:提升用户体验的开发与优化

# 摘要
本文详细介绍了在Flutter框架中实现验证码输入框的设计与开发流程。首先,文章探讨了验证码输入框在移动应用中的基本实现,随后深入到前端设计理论,强调了用户体验的重
光盘刻录软件大PK:10个最佳工具,找到你的专属刻录伙伴
# 摘要
本文全面介绍了光盘刻录技术,从技术概述到具体软件选择标准,再到实战对比和进阶优化技巧,最终探讨了在不同应用场景下的应用以及未来发展趋势。在选择光盘刻录软件时,本文强调了功能性、用户体验、性能与稳定性的重要性。此外,本文还提供了光盘刻录的速度优化、数据安全保护及刻录后验证的方法,并探讨了在音频光盘制作、数据备份归档以及多媒体项目中的应用实例。最后,文章展望了光盘刻录技术的创
【FANUC机器人接线实战教程】:一步步教你完成Process IO接线的全过程
# 摘要
本文系统地介绍了FANUC机器人接线的基础知识、操作指南以及故障诊断与解决策略。首先,章节一和章节二深入讲解了Process IO接线原理,包括其优势、硬件组成、电气接线基础和信号类型。随后,在第三章中,提供了详细的接线操作指南,从准备工作到实际操作步骤,再到安全操作规程与测试,内容全面而细致。第四章则聚焦于故障诊断与解决,提供了一系列常见问题的分析、故障排查步骤与技巧,以及维护和预防措施
ENVI高光谱分析入门:3步掌握波谱识别的关键技巧

# 摘要
本文全面介绍了ENVI高光谱分析软件的基础操作和高级功能应用。第一章对ENVI软件进行了简介,第二章详细讲解了ENVI用户界面、数据导入预处理、图像显示与分析基础。第三章讨论了波谱识别的关键步骤,包括波谱特征提取、监督与非监督分类以及分类结果的评估与优化。第四章探讨了高级波谱分析技术、大数据环境下的高光谱处理以及ENVI脚本
ISA88.01批量控制核心指南:掌握制造业自动化控制的7大关键点

# 摘要
本文详细介绍了ISA88.01批量控制标准的理论基础和实际应用。首先,概述了ISA88.01标准的结构与组件,包括基本架构、核心组件如过程模块(PM)、单元模块(UM)
【均匀线阵方向图优化手册】:提升天线性能的15个实战技巧
# 摘要
本文系统地介绍了均匀线阵天线的基础知识、方向图优化理论基础、优化实践技巧、系统集成与测试流程,以及创新应用。文章首先概述了均匀线阵天线的基本概念和方向图的重要性,然后
STM32F407 USB通信全解:USB设备开发与调试的捷径

# 摘要
本论文深入探讨了STM32F407微控制器在USB通信领域的应用,涵盖了从基础理论到高级应用的全方位知识体系。文章首先对USB通信协议进行了详细解析,并针对STM32F407的USB硬件接口特性进行了介绍。随后,详细阐述了USB设备固件开发流程和数据流管理,以及USB通信接口编程的具体实现。进一步地,针对USB调试技术和故障诊断、性能优化进行了系统性分析。在高级应用部分,重点介绍了USB主
车载网络诊断新趋势:SAE-J1939-73在现代汽车中的应用
# 摘要
随着汽车电子技术的发展,车载网络诊断技术变得日益重要。本文首先概述了车载网络技术的演进和SAE-J1939标准及其子标准SAE-J1939-73的角色。接着深入探讨了SAE-J1939-73标准的理论基础,包括数据链路层扩展、数据结构、传输机制及诊断功能。文章分析了SAE-J1939-73在现代汽车诊断中的实际应用,车载网络诊断工具和设备,以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )