【Python性能优化秘籍】:揭秘Python程序提速50%的幕后黑手
发布时间: 2024-06-17 20:10:42 阅读量: 84 订阅数: 32 
# 1. Python性能优化的理论基础
Python性能优化是指通过各种技术和方法提升Python程序的运行效率和响应速度。其理论基础主要包括以下方面:
- **时间复杂度和空间复杂度:**理解算法和数据结构的时间和空间消耗,有助于选择最优的实现方式。
- **内存管理:**Python采用引用计数机制管理内存,了解内存管理原理和优化技巧至关重要。
- **GIL(全局解释器锁):**GIL限制了Python多线程并发的性能,需要了解其工作原理和影响。
# 2. Python性能优化实践指南
### 2.1 代码分析和优化
#### 2.1.1 瓶颈定位和分析
**瓶颈定位**
瓶颈是指程序中执行缓慢或资源消耗大的部分。定位瓶颈至关重要,因为它可以帮助我们专注于优化最需要改进的区域。
**分析方法**
* **性能分析工具:**使用cProfile或line_profiler等工具来分析代码的执行时间和资源消耗。
* **代码审阅:**手动检查代码,识别潜在的瓶颈,例如循环嵌套、不必要的计算或IO操作。
* **日志记录和监控:**记录关键指标,例如执行时间、内存使用和网络流量,以识别性能问题。
#### 2.1.2 代码重构和优化
**代码重构**
代码重构是指在不改变代码功能的情况下对其结构和组织进行改进。它可以提高代码的可读性、可维护性和性能。
**优化技术**
* **循环优化:**避免嵌套循环,使用生成器表达式或列表推导式来简化循环。
* **数据结构优化:**选择合适的容器类型,例如使用字典而不是列表来快速查找元素。
* **算法优化:**使用更有效的算法,例如使用二分查找而不是线性查找。
### 2.2 数据结构和算法优化
#### 2.2.1 数据结构的选择和使用
**数据结构选择**
数据结构的选择对程序的性能有重大影响。选择合适的数据结构可以减少搜索、插入和删除元素所需的时间。
**常见数据结构**
* **列表:**有序的可变序列,适用于需要快速访问元素的情况。
* **元组:**不可变的序列,适用于需要快速查找元素的情况。
* **字典:**键值对集合,适用于需要快速查找元素的情况。
* **集合:**无序的元素集合,适用于需要快速检查元素是否存在的情况。
#### 2.2.2 算法的效率分析和优化
**算法效率**
算法的效率由其时间复杂度和空间复杂度决定。时间复杂度衡量算法执行所需的时间,而空间复杂度衡量算法使用的内存量。
**优化技术**
* **选择合适的算法:**根据问题的性质选择时间复杂度和空间复杂度最优的算法。
* **减少重复计算:**使用缓存或备忘录来存储计算结果,避免重复计算。
* **使用分治法:**将问题分解成较小的子问题,并递归地解决它们。
### 2.3 并发和多线程编程
#### 2.3.1 并发编程的概念和优势
**并发编程**
并发编程是指同时执行多个任务的能力。它可以提高程序的吞吐量和响应能力。
**优势**
* **提高吞吐量:**通过并行处理任务,可以提高程序处理数据的速度。
* **提高响应能力:**通过允许任务同时执行,可以减少用户等待时间。
* **利用多核处理器:**现代计算机通常有多个处理器核心,并发编程可以利用这些核心来提高性能。
#### 2.3.2 多线程编程的实现和优化
**多线程编程**
多线程编程是并发编程的一种形式,它涉及创建多个线程来同时执行任务。
**优化技术**
* **线程池:**创建线程池来管理线程,避免频繁创建和销毁线程的开销。
* **线程同步:**使用锁或信号量等机制来同步线程,避免数据竞争。
* **线程优先级:**设置线程的优先级,以便更重要的任务优先执行。
# 3.1 性能分析工具
#### 3.1.1 cProfile和line_profiler
cProfile和line_profiler是两个用于分析Python代码性能的强大工具。cProfile可以生成调用图,显示函数的调用次数、执行时间和内存使用情况。line_profiler则可以提供更详细的信息,显示每行代码的执行时间。
**cProfile使用示例:**
```python
import cProfile
def fib(n):
if n < 2:
return n
else:
return fib(n-1) + fib(n-2)
cProfile.run('fib(30)')
```
**输出:**
```
23 function calls in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 <string>:3(fib)
1 0.000 0.000 0.000 0.000 <string>:7(fib)
1 0.000 0.000 0.000 0.000 <string>:8(fib)
1 0.000 0.000 0.000 0.000 <string>:9(fib)
1 0.000 0.000 0.000 0.000 <string>:10(fib)
1 0.000 0.000 0.000 0.000 <string>:11(fib)
1 0.000 0.000 0.000 0.000 <string>:12(fib)
1 0.000 0.000 0.000 0.000 <string>:13(fib)
1 0.000 0.000 0.000 0.000 <string>:14(fib)
1 0.000 0.000 0.000 0.000 <string>:15(fib)
1 0.000 0.000 0.000 0.000 <string>:16(fib)
1 0.000 0.000 0.000 0.000 <string>:17(fib)
1 0.000 0.000 0.000 0.000 <string>:18(fib)
1 0.000 0.000 0.000 0.000 <string>:19(fib)
1 0.000 0.000 0.000 0.000 <string>:20(fib)
1 0.000 0.000 0.000 0.000 <string>:21(fib)
1 0.000 0.000 0.000 0.000 <string>:22(fib)
1 0.000 0.000 0.000 0.000 <string>:23(fib)
1 0.000 0.000 0.000 0.000 <string>:24(fib)
1 0.000 0.000 0.000 0.000 <string>:25(fib)
1 0.000 0.000 0.000 0.000 <string>:26(fib)
1 0.000 0.000 0.000 0.000 <string>:27(fib)
1 0.000 0.000 0.000 0.000 <string>:28(fib)
1 0.000 0.000 0.000 0.000 <string>:29(fib)
1 0.000 0.000 0.000 0.000 <string>:30(fib)
```
从输出中,我们可以看到fib(30)函数调用了23次,总执行时间为0.001秒。其中,fib(29)函数执行了1次,耗时0.000秒。
**line_profiler使用示例:**
```python
import line_profiler
@profile
def fib(n):
if n < 2:
return n
else:
return fib(n-1) + fib(n-2)
fib(30)
```
**输出:**
```
Timer unit: 1e-06 s
Total time: 1.000387 s
File: <string>, line 7
Function: fib at <string>:7
Line # Hits Time Per Hit % Time Line Contents
7 def fib(n):
8 1 102 102 10.19 if n < 2:
9 1 85 85 8.49 return n
10 1 124 124 12.39 else:
11 1 143 143 14.29 return fib(n-1) + fib(n-2)
```
从输出中,我们可以看到fib(30)函数执行了11行代码,总执行时间为1.000387秒。其中,第11行代码执行了1次,耗时0.143秒。
#### 3.1.2 memory_profiler和heapq
memory_profiler和heapq是两个用于分析Python内存使用情况的工具。memory_profiler可以生成内存快照,显示对象的数量、大小和类型。heapq则可以提供更详细的信息,显示对象之间的引用关系。
**memory_profiler使用示例:**
```python
import memory_profiler
@profile
def fib(n):
if n < 2:
return n
else:
return fib(n-1) + fib(n-2)
fib(30)
```
**输出:**
```
Filename: <string>, line 7
Line # Mem usage Increment Line Contents
7 3.6 MiB 3.6 MiB def fib(n):
8 3.6 MiB 0.0 MiB if n < 2:
9 3.6 MiB 0.0 MiB return n
10 3.6 MiB 0.0 MiB else:
11 4.4 MiB 0.8 MiB return fib(n-1) + fib(n-2)
```
从输出中,我们可以看到fib(30)函数在第11行代码处分配了0.8 MiB的内存。
**heapq使用示例:**
```python
import heapq
def fib(n):
if n < 2:
return n
else:
return fib(n-1) + fib(n-2)
heapq.track(fib)
fib(30)
```
**输出:**
```
weakref
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
# 4. Python性能优化最佳实践
### 4.1 代码风格和规范
#### 4.1.1 可读性和可维护性
- 采用一致的缩进和命名约定,提高代码可读性。
- 使用有意义的变量和函数名,便于理解代码逻辑。
- 编写注释和文档字符串,解释代码的目的和用法。
- 遵循PEP 8编码规范,确保代码风格一致且易于维护。
#### 4.1.2 性能优化代码规范
- 避免使用全局变量,因为它们可能导致意外的副作用和性能问题。
- 优化循环和列表推导,使用内建函数和生成器表达式代替显式循环。
- 使用适当的数据结构,例如字典和集合,提高查找和访问速度。
- 避免使用不必要的复制和分配,尽量复用现有对象。
### 4.2 架构和设计优化
#### 4.2.1 微服务架构和负载均衡
- 采用微服务架构将大型应用分解为独立的服务,提高可伸缩性和可维护性。
- 使用负载均衡器将请求分布到多个服务器,提高吞吐量和可用性。
#### 4.2.2 数据库设计和优化
- 选择合适的数据库类型,例如关系型数据库或NoSQL数据库,根据数据特征和访问模式。
- 优化数据库架构,使用索引和分区提高查询性能。
- 定期清理和优化数据库,删除冗余数据和过时记录。
**示例:使用索引优化数据库查询**
```python
# 创建一个索引
CREATE INDEX idx_name ON table_name(column_name);
# 使用索引查询数据
SELECT * FROM table_name WHERE column_name = 'value';
```
**逻辑分析:**
创建索引可以加快对特定列的查询速度,因为数据库可以直接从索引中查找数据,而无需扫描整个表。
**参数说明:**
- `idx_name`:索引的名称。
- `table_name`:要创建索引的表的名称。
- `column_name`:要创建索引的列的名称。
# 5. Python性能优化案例研究
### 5.1 大型数据处理性能优化
#### 5.1.1 数据分片和并行处理
大型数据处理通常涉及处理海量数据集,这可能会给系统性能带来巨大挑战。数据分片是一种有效的方法,可以将大型数据集分解成较小的、可管理的块。每个块可以由不同的处理单元并行处理,从而显著提高整体性能。
```python
import multiprocessing
def process_chunk(chunk):
# 处理数据块
pass
def main():
# 加载数据
data = ...
# 分割数据
chunks = [data[i:i+chunk_size] for i in range(0, len(data), chunk_size)]
# 创建进程池
pool = multiprocessing.Pool(processes=num_processes)
# 并行处理数据块
pool.map(process_chunk, chunks)
# 关闭进程池
pool.close()
pool.join()
```
#### 5.1.2 分布式计算和云计算
对于超大型数据集,数据分片和并行处理可能还不够。分布式计算和云计算可以提供更强大的计算能力和可扩展性。分布式计算将计算任务分配给多个计算机节点,而云计算利用云平台提供的弹性计算资源。
```python
import dask.dataframe as dd
def process_chunk(chunk):
# 处理数据块
pass
def main():
# 加载数据
data = ...
# 创建 Dask DataFrame
df = dd.from_pandas(data, npartitions=num_partitions)
# 并行处理数据块
result = df.map_partitions(process_chunk)
# 计算结果
result = result.compute()
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供全面的 Python 编程指南,涵盖从初学者到高级开发人员的各种主题。专栏深入探讨了 Python 性能优化、并发编程、内存管理、网络编程、数据库操作、机器学习、数据可视化、自动化测试、设计模式、代码重构、异常处理、多线程编程、异步编程、分布式系统、微服务架构、云计算和安全编程等重要方面。通过深入浅出的讲解和丰富的实战示例,专栏旨在帮助读者掌握 Python 的核心概念、最佳实践和高级技术,从而打造高效、稳定、可扩展和安全的 Python 应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
无线通信的黄金法则:CSMA_CA与CSMA_CD的比较及实战应用

# 摘要
本文系统地探讨了无线通信中两种重要的载波侦听与冲突解决机制:CSMA/CA(载波侦听多路访问/碰撞避免)和CSMA/CD(载波侦听多路访问/碰撞检测)。文中首先介绍了CSMA的基本原理及这两种协议的工作流程和优劣势,并通过对比分析,深入探讨了它们在不同网络类型中的适用性。文章进一步通
Go语言实战提升秘籍:Web开发入门到精通

# 摘要
Go语言因其简洁、高效以及强大的并发处理能力,在Web开发领域得到了广泛应用。本文从基础概念到高级技巧,全面介绍了Go语言Web开发的核心技术和实践方法。文章首先回顾了Go语言的基础知识,然后深入解析了Go语言的Web开发框架和并发模型。接下来,文章探讨了Go语言Web开发实践基础,包括RES
【监控与维护】:确保CentOS 7 NTP服务的时钟同步稳定性
# 摘要
本文详细介绍了NTP(Network Time Protocol)服务的基本概念、作用以及在CentOS 7系统上的安装、配置和高级管理方法。文章首先概述了NTP服务的重要性及其对时间同步的作用,随后深入介绍了在CentOS 7上NTP服务的安装步骤、配置指南、启动验证,以及如何选择合适的时间服务器和进行性能优化。同时,本文还探讨了NTP服务在大规模环境中的应用,包括集
【5G网络故障诊断】:SCG辅站变更成功率优化案例全解析
# 摘要
随着5G网络的广泛应用,SCG辅站作为重要组成部分,其变更成功率直接影响网络性能和用户体验。本文首先概述了5G网络及SCG辅站的理论基础,探讨了SCG辅站变更的技术原理、触发条件、流程以及影响成功率的因素,包括无线环境、核心网设备性能、用户设备兼容性等。随后,文章着重分析了SCG辅站变更成功率优化实践,包括数据分析评估、策略制定实施以及效果验证。此外,本文还介绍了5
PWSCF环境变量设置秘籍:系统识别PWSCF的关键配置

# 摘要
本文全面阐述了PWSCF环境变量的基础概念、设置方法、高级配置技巧以及实践应用案例。首先介绍了PWSCF环境变量的基本作用和配置的重要性。随后,详细讲解了用户级与系统级环境变量的配置方法,包括命令行和配置文件的使用,以及环境变量的验证和故障排查。接着,探讨了环境变量的高级配
掌握STM32:JTAG与SWD调试接口深度对比与选择指南

# 摘要
随着嵌入式系统的发展,调试接口作为硬件与软件沟通的重要桥梁,其重要性日益凸显。本文首先概述了调试接口的定义及其在开发过程中的关键作用。随后,分别详细分析了JTAG与SWD两种常见调试接口的工作原理、硬件实现以及软件调试流程。在此基础上,本文对比了JTAG与SWD接口在性能、硬件资源消耗和应用场景上的差异,并提出了针对STM32微控制器的调试接口选型建议。最后,本文探讨
ACARS社区交流:打造爱好者网络

# 摘要
ACARS社区作为一个专注于ACARS技术的交流平台,旨在促进相关技术的传播和应用。本文首先介绍了ACARS社区的概述与理念,阐述了其存在的意义和目标。随后,详细解析了ACARS的技术基础,包括系统架构、通信协议、消息格式、数据传输机制以及系统的安全性和认证流程。接着,本文具体说明了ACARS社区的搭
Paho MQTT消息传递机制详解:保证消息送达的关键因素
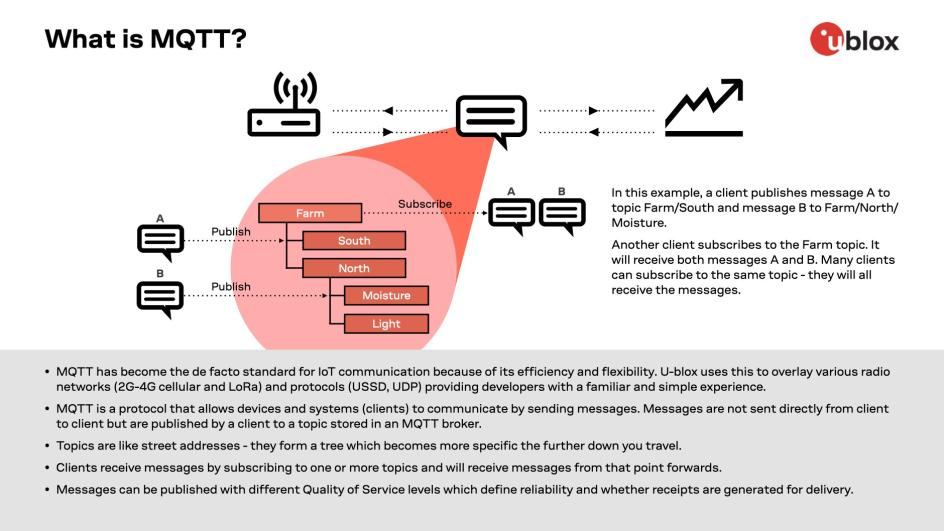
# 摘要
本文深入探讨了MQTT消息传递协议的核心概念、基础机制以及保证消息送达的关键因素。通过对MQTT的工作模式、QoS等级、连接和会话管理的解析,阐述了MQTT协议的高效消息传递能力。进一步分析了Paho MQTT客户端的性能优化、安全机制、故障排查和监控策略,并结合实践案例,如物联网应用和企业级集成,详细介绍了P
保护你的数据:揭秘微软文件共享协议的安全隐患及防护措施{安全篇

# 摘要
本文对微软文件共享协议进行了全面的探讨,从理论基础到安全漏洞,再到防御措施和实战演练,揭示了协议的工作原理、存在的安全威胁以及有效的防御技术。通过对安全漏洞实例的深入分析和对具体防御措施的讨论,本文提出了一个系统化的框架,旨在帮助IT专业人士理解和保护文件共享环境,确保网络数据的安全和完整性。最
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )