【Hadoop框架深度剖析】:优缺点详解与适用场景分析
发布时间: 2024-10-27 22:27:23 阅读量: 46 订阅数: 49 

白色大气风格的旅游酒店企业网站模板.zip

# 1. Hadoop框架概述与核心组件
## 1.1 Hadoop框架简介
Hadoop是一个由Apache基金会开发的开源分布式系统基础架构。它提供了处理大规模数据的平台,支持在商业硬件集群上运行的应用程序。Hadoop框架以其高容错性、高效性和高扩展性的特点,在处理非结构化和半结构化数据方面表现出色。它允许用户利用简单的编程模型来处理大规模数据集。
## 1.2 Hadoop核心组件
Hadoop的核心组件包括Hadoop分布式文件系统(HDFS)和MapReduce。HDFS负责数据存储,MapReduce则负责数据处理。这两个组件结合在一起,使得Hadoop能够分布式地存储和处理大数据。随着Hadoop生态系统的发展,它已经集成了多种辅助组件,如YARN(Yet Another Resource Negotiator)、Zookeeper等,以增强其资源管理和集群协调的能力。
## 1.3 Hadoop的分布式处理能力
Hadoop的分布式处理能力来源于其对大数据的切片和分布存储。通过将数据切分成较小的块(block)分散存储在多个节点上,Hadoop能够并行处理存储在不同节点上的数据块。这种分布式处理方式大幅度提高了数据处理的效率,尤其在处理PB级别的数据时表现出色。
通过下一章节,我们将深入了解HDFS的工作原理和架构,以获得更全面的Hadoop知识。
# 2. Hadoop的分布式文件系统(HDFS)
### 2.1 HDFS的工作原理和架构
Hadoop的分布式文件系统(HDFS)是Hadoop项目的核心组件之一。它是专为存储和处理大规模数据集而设计的,能够运行在廉价的硬件之上。通过多台计算机的集群实现高可靠性,容错性和伸缩性。
#### 2.1.1 HDFS的设计理念和核心组件
HDFS的设计理念是将大型数据集分割成块(block),然后分布式存储在多个节点上。HDFS提供了高吞吐量的数据访问,非常适合于大规模数据集的应用。其核心组件包括:
- NameNode:管理文件系统的命名空间。记录文件中各个块所在的DataNode节点信息。
- DataNode:在本地文件系统中存储各个块,处理来自文件系统的客户端读写请求。
- Secondary NameNode:辅助NameNode管理文件系统的元数据。
#### 2.1.2 HDFS的数据存储与复制机制
HDFS通过数据的多副本机制确保数据的高可用性和容错性。在HDFS中,默认情况下每个数据块会复制成3份,分别存储在不同的DataNode上。当某个DataNode发生故障时,HDFS可以自动从其他副本恢复数据,保证系统可靠性。
### 2.2 HDFS的命令行操作和管理
HDFS提供了丰富的命令行工具,允许用户和系统管理员对文件系统进行操作和管理。掌握了这些基本命令,可以高效地管理Hadoop集群中的数据。
#### 2.2.1 HDFS的常用命令及其用法
HDFS命令行工具是操作HDFS的基本手段。一些常用的命令包括但不限于:
- `hadoop fs -ls`:列出文件系统目录信息。
- `hadoop fs -put`:上传文件到HDFS。
- `hadoop fs -get`:从HDFS下载文件到本地。
- `hadoop fs -rm`:删除HDFS上的文件。
例如,使用 `hadoop fs -ls /` 可以查看HDFS根目录下的文件列表。每个命令后面都可以接多个参数,以便进行更复杂的操作。
#### 2.2.2 HDFS的权限和安全机制
为了确保数据的安全性,HDFS提供了文件系统的权限机制。主要通过POSIX的权限模型来控制用户对文件和目录的访问权限。除了基本的读、写和执行权限之外,HDFS还支持文件的访问控制列表(ACLs)和继承权限。
### 2.3 HDFS的性能调优与故障排除
尽管HDFS是非常强大的存储系统,但在实际应用中,可能会遇到性能瓶颈和故障问题。适当的调优和故障排除策略对于维持集群稳定运行至关重要。
#### 2.3.1 HDFS性能调优的策略和技巧
- **数据块大小调整**:根据应用场景调整数据块的大小可以显著影响读写性能。
- **合理分配副本数量**:针对不同的业务场景,调整副本数以平衡性能和数据安全。
- **压缩和编码**:通过启用数据压缩减少存储空间,同时提高I/O效率。
#### 2.3.2 HDFS常见故障诊断与处理
HDFS集群可能会遇到各种问题,例如节点故障、网络问题和硬件故障。故障诊断通常涉及以下步骤:
- **日志分析**:检查Hadoop的日志文件,确定错误发生的时间和类型。
- **节点健康检查**:使用Hadoop提供的工具检查DataNode和NameNode的状态。
- **备份和恢复**:及时备份关键数据,利用备份数据恢复系统状态。
下面是一个故障诊断的简单示例,用于检查DataNode的状态:
```bash
hdfs dfsadmin -report
```
执行该命令后,会输出所有DataNode的信息和状态,帮助管理员快速了解集群健康状况。
在下一章中,我们将继续深入了解Hadoop的分布式计算框架MapReduce,分析其工作流程、优化策略以及与大数据处理场景的结合应用。
# 3. Hadoop的分布式计算框架(MapReduce)
## 3.1 MapReduce编程模型详解
### 3.1.1 MapReduce的工作流程和编程范式
MapReduce是Hadoop的核心计算框架,它采用了一种“分而治之”的编程范式,将计算任务分解为两个阶段:Map阶段和Reduce阶段。首先,Map阶段读取输入数据,并将其分割成独立的块进行处理,每个块由一个Map任务处理,生成一系列的中间键值对。然后,这些键值对被Shuffle过程分发到对应的Reduce任务,每个Reduce任务负责处理一个或多个键的所有值。最后,Reduce任务将所有值汇总起来,得到最终结果。
这个过程可以有效地在大规模分布式集群上运行,处理TB甚至PB级别的数据。MapReduce编程模型通过这种方式,允许开发者仅需关注自己的业务逻辑,而不需要关心底层的并行处理和容错机制。
### 3.1.2 MapReduce的编程实践和案例分析
MapReduce编程模型的具体实践涉及到编写Map和Reduce函数,这些函数定义了数据处理的具体逻辑。Map函数处理输入数据,并生成中间键值对,而Reduce函数则处理具有相同键的值集合,输出最终结果。
在实践MapReduce时,一个经典的案例是处理大规模日志文件,提取访问频率最高的URL。Map阶段解析日志文件,输出每个URL及其访问次数,而Reduce阶段则将相同的URL的访问次数合并,最终得到每个URL的总访问次数。
具体代码示例如下:
```java
public static class MapClass extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
String[] words = line.split("\\s+"); // 假设每个单词之间由空格分隔
for (String str : words) {
word.set(str);
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
```
### 3.2 MapReduce的优化与扩展
#### 3.2.1 MapReduce任务调度和性能优化
MapReduce任务的性能优化可以从多个方面入手。首先是任务调度优化,合理安排Map和Reduce任务的执行顺序和数量,可以充分利用集群资源,避免资源浪费或任务执行的瓶颈。
其次是代码优化,减少Map和Reduce操作的次数,利用Combiner减少Shuffle过程中传输的数据量。Combiner的作用类似于本地的Reduce操作,它在Map任务完成之后、数据传输之前,对中间数据进行局部归约,从而减少了网络传输的数据量,提升了性能。
#### 3.2.2 MapReduce与其他技术的集成应用
MapReduce作为一种通用的分布式计算框架,可以与其他技术集成,提供更强大的数据处理能力。例如,它可以与HBase结合,进行大规模的实时数据分析,或者与Spark集成,利用Spark的内存计算优势,提升处理速度。
### 3.3 MapReduce在大数据处理中的应用
#### 3.3.1 大数据处理场景的MapReduce实现
在大数据处理中,MapReduce可以应用于多种场景,比如搜索引擎的索引构建、社交网络的用户行为分析、金融领域的风险模型计算等。
例如,在构建搜索引擎索引时,MapReduce可以处理大规模网页数据,生成倒排索引。Map阶段解析网页内容,并提取出单词和URL,生成中间键值对;Reduce阶段则对所有相同单词的URL进行合并,形成最终的倒排索引。
#### 3.3.2 MapReduce与其他大数据技术的比较
与Hadoop的其他大数据技术相比,MapReduce更加成熟稳定,适合批处理型的计算任务。然而,由于其处理速度相对较慢,并不适合需要快速响应的实时计算场景。Spark的出现,以其内存计算优势,为大数据实时处理提供了一种新的选择。而Flink则进一步在低延迟流处理领域展示了其强大的能力。
在选择使用MapReduce还是其他技术时,需要根据实际业务需求和数据特性来定。对于需要大量历史数据处理,且可以接受较长处理时间的场景,MapReduce仍然是一个很好的选择。而对于需要快速处理响应的应用,Spark或Flink可能会更加合适。
# 4. Hadoop生态系统中的其他组件
## 4.1 数据仓库工具Hive和Pig
### 4.1.1 Hive的架构和SQL-like查询语言
Apache Hive 是一个数据仓库基础架构,建立在 Hadoop 之上,提供了类 SQL 查询语言(HiveQL)和表存储,使得熟悉 SQL 的开发者能够使用 Hadoop 进行大数据分析。它将结构化的数据文件映射为一张数据库表,并提供简单的 SQL 查询功能,能够将 SQL 语句转换为 MapReduce 任务进行运行。HiveQL 解析器将 HiveQL 语句转换成一个 DAG(有向无环图),这个 DAG 对应一个执行计划,并进一步转换成一系列的 MapReduce 任务来执行。
#### Hive架构概览
Hive 架构主要由以下几个组件构成:
- **用户接口**:主要的用户接口是 Hive CLI(命令行接口),但也可以通过 JDBC 和 ODBC 进行连接。
- **元数据存储**:存储表结构定义、HiveQL 语句等元数据信息。默认使用内嵌的 Derby 数据库,也可以配置为使用 MySQL 或 Oracle 等数据库系统。
- **驱动程序**:负责处理输入的 HiveQL 语句,生成一个优化后的查询计划,并进行执行。
- **编译器**:将 HiveQL 语句转换成一个执行计划,该计划将被进一步转换成一系列的 MapReduce 任务。
- **执行器**:负责将编译器生成的执行计划交由 Hadoop 集群进行实际的执行。
#### HiveQL 与 SQL 的异同
尽管 HiveQL 在语法上类似于 SQL,但 HiveQL 针对大数据场景做了一些特别的优化和扩展。下面是一些关键的区别:
- HiveQL 不支持事务处理。
- HiveQL 的操作大多数是面向批处理的,不如传统的 SQL 数据库的响应时间快。
- HiveQL 增加了一些对大数据分析有用的函数和操作符,例如 UDF(用户定义函数)。
- HiveQL 支持 MapReduce,但还支持 Tez 和 Spark 等执行引擎,提供更高的性能。
#### HiveQL 示例
以下是一个简单的 HiveQL 示例,演示如何创建表和查询:
```sql
-- 创建表
CREATE TABLE IF NOT EXISTS example (
id int,
name string,
data double
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
-- 插入数据
LOAD DATA LOCAL INPATH 'path/to/data.txt' INTO TABLE example;
-- 查询数据
SELECT * FROM example;
```
在这个例子中,我们定义了一个名为 `example` 的表,它包含三个字段:`id`、`name` 和 `data`。表使用逗号分隔字段的文本文件格式存储。然后,我们使用 `LOAD DATA` 命令将本地数据文件加载到表中,并通过 `SELECT` 查询来检索所有记录。
### 4.1.2 Pig的数据处理和脚本语言
Apache Pig 是另一个 Hadoop 生态系统中的重要组件,它提供了一种名为 Pig Latin 的高级脚本语言,用于对大数据集进行转换和分析。Pig Latin 脚本被编译成一系列的 MapReduce 任务,通过 Pig 执行引擎运行在 Hadoop 集群上。Pig 的核心概念包括关系和转换操作,这些操作可以链式组合,形成复杂的数据处理流程。
#### Pig架构概览
Pig 的架构主要包括以下几个部分:
- **Pig Latin**:用户编写的高级脚本语言,易于理解并能够处理复杂的转换。
- **Pig 解释器**:负责解析 Pig Latin 语句,并生成逻辑计划。
- **优化器**:对逻辑计划进行优化,生成更为高效的执行计划。
- **执行引擎**:将优化后的执行计划转化为实际的 MapReduce 任务,在 Hadoop 集群上执行。
#### Pig Latin 的关键概念
- **关系(Relation)**:代表一个数据集,可以看作是一个表或者文件。
- **模式(Schema)**:描述关系中包含的数据类型和字段名称。
- **转换操作(Transformation)**:对关系的行进行操作的函数,例如过滤、排序、合并、分组等。
- **加载(Load)和存储(Store)**:用于将数据加载到 Hadoop 文件系统和从系统中读取数据的操作。
#### Pig Latin 示例
下面是一个简单的 Pig Latin 示例,演示如何加载数据、过滤和存储数据:
```pig
-- 定义一个关系并加载数据
raw_data = LOAD '/data/input.txt' USING PigStorage(',') AS (id: int, name: chararray, score: double);
-- 过滤数据,选择 score 大于 80 的记录
filtered_data = FILTER raw_data BY score > 80;
-- 将结果存储到 HDFS
STORE filtered_data INTO '/data/output_filtered.txt' USING PigStorage(',');
```
在这个例子中,我们首先加载了一个使用逗号分隔的文本文件到一个名为 `raw_data` 的关系中,然后通过 `FILTER` 语句过滤出分数大于 80 的记录,并将结果存储到指定的 HDFS 路径。
通过使用 Pig,数据科学家和工程师能够编写出既简洁又强大的数据处理程序,而无需深入 Java 编程。Pig Latin 的抽象层为大数据处理提供了灵活性和高效性。
# 5. Hadoop的部署与集群管理
## 5.1 Hadoop集群的搭建与配置
### 5.1.1 环境准备和集群安装步骤
搭建Hadoop集群是一项涉及多个步骤的任务,这需要系统管理员根据实际硬件和网络环境做出合适的规划。以下是在标准Linux环境下搭建Hadoop集群的基本步骤。
1. **硬件需求确认**
- 确保所有机器拥有足够的内存、CPU和磁盘空间。
- 网络带宽应满足节点间数据传输的需要。
2. **操作系统配置**
- 安装基于Debian或RedHat的Linux发行版,如Ubuntu或CentOS。
- 设置主机名和静态IP地址,确保每台机器的主机名是唯一的。
- 更新系统软件包,安装Java环境,因为Hadoop需要Java运行时环境。
3. **SSH无密码登录配置**
- 在集群中创建一个用户(比如hadoop),用于操作集群。
- 生成SSH密钥并分发到所有节点,实现无密码SSH登录。
4. **安装Hadoop**
- 从Apache官方网站下载Hadoop。
- 解压到所有节点的相同目录下。
5. **配置Hadoop环境变量**
- 编辑用户的`.bashrc`或`.bash_profile`文件,设置`JAVA_HOME`和`HADOOP_HOME`环境变量。
- 将Hadoop的`bin`目录添加到`PATH`变量中。
6. **配置Hadoop集群**
- 复制一份Hadoop配置文件模板到`$HADOOP_HOME/etc/hadoop`目录。
- 修改`core-site.xml`、`hdfs-site.xml`、`mapred-site.xml`和`yarn-site.xml`四个主要配置文件,设置HDFS和YARN的参数。
7. **格式化HDFS**
- 在NameNode主机上格式化文件系统,使用`hdfs namenode -format`命令。
8. **启动集群**
- 使用`start-dfs.sh`和`start-yarn.sh`脚本启动HDFS和YARN服务。
- 验证集群状态,使用`jps`命令查看JVM进程。
9. **测试集群功能**
- 上传一些文件到HDFS,运行一个MapReduce示例程序,确保集群正常工作。
### 5.1.2 Hadoop集群的配置详解
Hadoop集群配置涉及到多个层面,每个配置文件的作用和关键参数如下所示:
#### core-site.xml
```xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode_host:port/</value>
</property>
<property>
<name>io.file.buffersize</name>
<value>4096</value>
</property>
</configuration>
```
- `fs.defaultFS`: 指定NameNode的主机名和端口。
- `io.file.buffersize`: 设置Hadoop使用的缓冲区大小,影响IO性能。
#### hdfs-site.xml
```xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/path/to/dfs/name</value>
</property>
</configuration>
```
- `dfs.replication`: 设置HDFS文件的副本数量,默认为3。
- `dfs.namenode.name.dir`: 指定NameNode存储元数据的本地路径。
#### mapred-site.xml
```xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>jobhistory_host:10020</value>
</property>
</configuration>
```
- `mapreduce.framework.name`: 设置MapReduce运行在YARN之上。
- `mapreduce.jobhistory.address`: 指定MapReduce作业历史服务器地址。
#### yarn-site.xml
```xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>resourcemanager_host:8032</value>
</property>
</configuration>
```
- `yarn.nodemanager.aux-services`: 设置NodeManager的辅助服务,为MapReduce提供shuffle功能。
- `yarn.resourcemanager.address`: 指定ResourceManager的地址。
了解这些配置参数对于一个成功搭建和高效管理Hadoop集群至关重要。接下来,我们将探讨如何监控和维护Hadoop集群。
# 6. Hadoop的优缺点与适用场景分析
在大数据处理领域,Hadoop凭借其独特的设计理念和架构成为了一个广泛采用的解决方案。尽管其在大数据生态系统中占据着重要地位,但Hadoop并非万能,它同样存在着一些限制。本章将探讨Hadoop的优势与限制,并分析它适用的业务场景,最后通过案例和趋势展望Hadoop的未来。
## 6.1 Hadoop框架的优势与限制
### 6.1.1 Hadoop在大数据领域的应用优势
Hadoop的优势在于其可扩展性、高容错性和成本效益。以下是其具体的应用优势:
- **可扩展性:** Hadoop的设计支持通过简单增加节点来水平扩展存储和计算资源。这使得Hadoop能够应对从TB到PB级别的数据存储和处理需求。
- **高容错性:** Hadoop通过数据的复制机制确保了高度的容错能力。即使部分节点失败,系统也能继续运行,并在节点恢复后自动修复数据。
- **成本效益:** Hadoop能在廉价的商用硬件上运行,不需要昂贵的专业硬件,大幅度降低了大数据处理的总体成本。
### 6.1.2 Hadoop面临的技术挑战和局限性
Hadoop虽然强大,但在实际应用中也面临诸多挑战:
- **处理速度:** Hadoop基于硬盘的存储方式相比内存计算速度较慢。尽管有如Spark这样的解决方案来弥补这一点,但在需要低延迟处理的场景下Hadoop仍然存在局限性。
- **复杂性:** 对于没有足够技术背景的开发者而言,Hadoop的学习曲线较为陡峭。整个生态系统包含多种工具,需要时间去掌握和整合。
- **扩展性限制:** 尽管Hadoop可扩展,但随着集群规模的增大,管理难度和成本也相应增加。
## 6.2 Hadoop适用的业务场景与案例分析
### 6.2.1 Hadoop在不同行业的应用案例
Hadoop在许多行业都找到了它的应用,以下是几个典型案例:
- **互联网公司:** 例如Facebook和Yahoo使用Hadoop来处理海量的日志数据,用于用户行为分析、个性化推荐等。
- **金融行业:** 银行和保险公司利用Hadoop进行风险分析、欺诈检测以及客户数据整合。
- **医疗行业:** 利用Hadoop处理和分析大量的医疗数据,以提高疾病诊断和治疗的效率。
### 6.2.2 Hadoop的未来发展趋势和展望
在技术日新月异的大数据时代,Hadoop也在不断地发展进化。它的未来发展趋势可能包括:
- **集成更多实时处理能力:** 通过集成如Apache Spark这样的实时处理框架,Hadoop将能够更好地处理需要即时数据分析的应用场景。
- **更智能的资源管理:** 随着机器学习和人工智能技术的结合,Hadoop的资源调度将变得更加智能化和高效。
- **向混合云架构演进:** Hadoop将更好地支持混合云架构,使其能更灵活地满足不同业务场景的需求。
通过对Hadoop优缺点和适用场景的分析,我们可以看到它在大数据处理领域的核心地位。然而,随着技术的进步和业务需求的变化,Hadoop也需要不断地进行优化和升级,以保持其竞争力和应用价值。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入剖析了 Hadoop 框架的优缺点,并探讨了其在不同场景下的适用性。文章涵盖了 Hadoop 的局限性、集群性能优化、与 Spark 的比较以及在医疗大数据、物联网和机器学习等领域的应用。此外,还提供了 Hadoop 数据备份和恢复策略、MapReduce 编程指南、数据倾斜问题解决方案、集群升级和迁移策略等实用指南。通过深入分析和案例研究,本专栏旨在帮助读者全面了解 Hadoop 的优势和挑战,并为在大数据项目中有效利用 Hadoop 提供指导。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
BP1048B2接口分析:3大步骤高效对接系统资源,专家教你做整合

# 摘要
本文对BP1048B2接口进行了全面的概述,从理论基础到实践应用,再到高级特性和未来展望进行了系统性分析。首先介绍了BP1048B2接口的技术标准和硬件组成,然后详细探讨了接口与系统资源对接的实践步骤,包括硬件和软件层面的集成策略,以及系统资源的高效利用。在高级应用分析部分,本文着重研究了多接口并发处理、安全性与权限管理以及接口的可扩展性和维护性。最后,通过整合案例分析,本文讨论了BP1048B2接口
【Dev-C++ 5.11性能优化】:高级技巧与编译器特性解析
# 摘要
本文旨在深入探讨Dev-C++ 5.11的性能优化方法,涵盖了编译器优化技术、调试技巧、性能分析、高级优化策略以及优化案例与实践。文章首先概览了Dev-C++ 5.11的基础性能优化,接着详细介绍了编译器的优化选项、代码内联、循环展开以及链接控制的原理和实践。第三章深入讲解了调试工具的高级应用和性能分析工具的运用,并探讨了跨平台调试和优化的
【面积分真知】:理论到实践,5个案例揭示面积分的深度应用
# 摘要
面积分作为一种数学工具,在多个科学与工程领域中具有广泛的应用。本文首先概述了面积分的基础理论,随后详细探讨了它在物理学、工程学以及计算机科学中的具体应用,包括电磁学、流体力学、统计物理学、电路分析、结构工程、热力学、图像处理、机器学习和数据可视化等。通过对面积分应用的深入分析,本文揭示了面积分在跨学科案例中的实践价值和新趋势,并对未来的理论发展进行了展
加速度计与陀螺仪融合:IMU姿态解算的终极互补策略
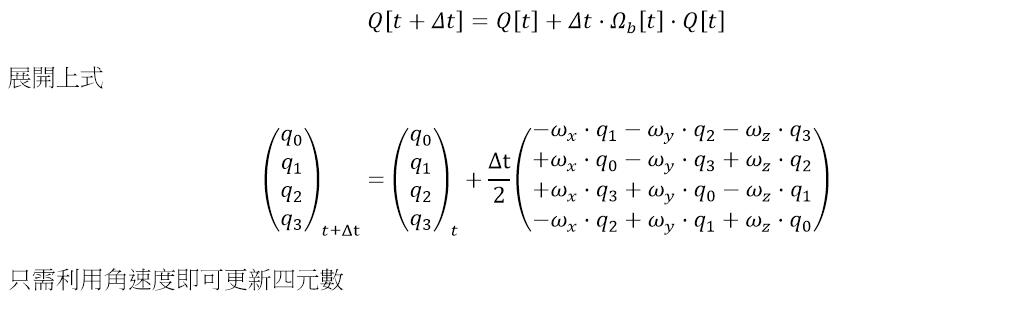
# 摘要
惯性测量单元(IMU)传感器在姿态解算领域中发挥着至关重要的作用,本文首先介绍了IMU的基础知识和姿态解算的基本原理。随后,文章深入探讨了IMU传感器理论基础,包括加速度计和陀螺仪的工作原理及数据模型,以及传感器融合的理论基础。在实践技巧方面,本文提供了加速度计和陀螺仪数据处理的技巧,并介绍了IMU数据融合的实践方法,特别是卡尔曼滤波器的应用。进一步地,本文讨论了高级IMU姿态解算技术,涉及多
【蓝凌KMSV15.0:权限管理的终极安全指南】:配置高效权限的技巧
# 摘要
蓝凌KMSV15.0权限管理系统旨在提供一套全面、高效、安全的权限管理解决方案。本文从权限管理的基础理论出发,详细介绍了用户、角色与权限的定义及权限管理的核心原则,并探讨了基于角色的访问控制(RBAC)与最小权限原则的实施方法。随后,通过配置实战章节,本文向读者展示了如何在蓝凌KMSV15.0中进行用户与角色的配置和权限的精细管理。此外,文章还探讨了自动化权限管理和高
揭秘华为硬件测试流程:全面的质量保证策略

# 摘要
本文全面介绍了华为硬件测试流程,从理论基础到实践操作,再到先进方法的应用以及面临的挑战和未来展望。文章首先概述了硬件测试的目的、重要性以及测试类型,随后深入探讨了测试生命周期的各个阶段,并强调了测试管理与质量控制在硬件测试中的核心作用。在实践操作方面,文章详细阐述了测试工具与环境的配置、功能性测试与性能评估的流程和指标,以及故障诊断与可靠性测试的方法。针对测试方法的创新,文中介绍了自动化测试、模拟测试和仿真技术,以及大数据与智能分析在
MIKE_flood高效模拟技巧:提升模型性能的5大策略

# 摘要
本文系统地介绍了MIKE_flood模拟软件的基础、性能提升技巧、高级性能优化策略和实践应用。首先概述了MIKE_flood的理论基础,包括水文模型原理、数据准备和模型校准过程。随后,详细探讨了硬件与软件优化、动态负载平衡、多模型集成等提升模型性能的方法。通过分析具体的模拟案例,展示了MI
Mamba SSM 1.2.0新纪元:架构革新与性能优化全解读
# 摘要
本文介绍了Mamba SSM 1.2.0的概况、新架构、性能优化策略、实践案例分析、生态系统整合以及对未来的展望。Mamba SSM 1.2.0采纳了新的架构设计理念以应对传统架构的挑战,强调了其核心组件与数据流和控制流的优化。文章详细探讨了性能优化的原则、关键点和实战
【ROSTCM系统架构解析】:揭秘内容挖掘背后的计算模型,专家带你深入了解

# 摘要
本文全面介绍了ROSTCM系统,阐述了其设计理念、核心技术和系统架构。ROSTCM作为一种先进的内容挖掘系统,将算法与数据结构、机器学习方法以及分布式计算框架紧密结合,有效提升了内容挖掘的效率和准确性。文章深入分析了系统的关键组件,如数据采集、内容分析引擎以及数据存储管理策略,并探讨了系统在不同领域的实践应用和性能评估。同时,本文对ROSTCM面临的技术挑战和发展前景进行了展望,并从
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )