




【高级排序技巧】:在实际项目中优雅地排序,提升开发效率


AEDII:数据结构范围内开发的项目的存储库
1. 排序算法概述与应用场景
排序算法是计算机科学中不可或缺的基础组成部分,它负责对数据按照特定的顺序进行排列。从简单的个人通讯录到复杂的数据库系统,排序算法几乎渗透到每一款软件的最深处。了解排序算法的原理、性能特点,以及它们在不同应用场景下的表现,对于一名IT专业人员来说至关重要。
1.1 排序算法的重要性
排序算法的重要性不仅体现在它的频繁使用上,还体现在对于理解计算机科学其他概念的基础性作用上。例如,掌握排序可以更好地理解数据结构如堆、二叉树等,以及它们是如何在算法中起到优化作用的。
1.2 常见的应用场景
排序算法在多个方面得到应用,例如:
- 数据库系统中对查询结果进行排序;
- 文件系统中按照文件名或大小排列文件;
- 网页搜索引擎对搜索结果进行排序。
在接下来的章节中,我们将深入探讨各种排序算法的机制、复杂度以及在不同环境中的应用。
2. 经典排序算法深入解析
2.1 时间复杂度与空间复杂度
2.1.1 时间复杂度的定义与计算
时间复杂度是用来衡量算法执行时间的一个抽象概念,通常与算法执行所涉及的基本操作数成正比。它描述了算法的运行时间随着输入数据量的增加而增长的趋势。时间复杂度用大O符号表示,例如O(n),O(n^2)等。
基本操作是指算法中最常见、执行次数最多的操作。例如,在冒泡排序中,比较和交换是其基本操作。计算时间复杂度时,我们关注的是算法在最坏情况下的表现,因为这通常能够提供算法性能的保证。
例如,冒泡排序的时间复杂度为O(n^2),因为它包含两层嵌套循环,每层循环都依赖于数据集的大小n。相比之下,快速排序在平均情况下的时间复杂度为O(n log n),这使其在大数据集上更为高效。
2.1.2 空间复杂度的概念及其重要性
空间复杂度是指算法在运行过程中临时占用存储空间的大小,与算法所处理的数据量相关。它是一个关于输入数据大小的函数,用于描述随着输入数据的增加,算法所占用的空间如何变化。
在排序算法中,空间复杂度尤为重要,因为有些算法是原地排序(in-place),即不需要额外的存储空间;而另一些则需要额外的空间来辅助排序。例如,归并排序的空间复杂度为O(n),因为它需要与输入数组大小相当的临时数组来合并排序后的子数组。
在设计排序算法时,需要在时间效率和空间效率之间做出权衡。有时候牺牲一定的空间复杂度可以换取更快的处理速度,反之亦然。
2.2 常见的排序算法
2.2.1 冒泡排序与选择排序
冒泡排序是最简单的排序算法之一,它通过重复遍历要排序的数列,一次比较两个元素,如果顺序错误就把它们交换过来。遍历数列的工作是重复进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
- def bubble_sort(arr):
- n = len(arr)
- for i in range(n):
- for j in range(0, n-i-1):
- if arr[j] > arr[j+1]:
- arr[j], arr[j+1] = arr[j+1], arr[j]
- return arr
- # 示例数组
- arr = [64, 34, 25, 12, 22, 11, 90]
- bubble_sort(arr)
选择排序是一种原地排序算法,它的工作原理是每次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
- def selection_sort(arr):
- n = len(arr)
- for i in range(n):
- min_idx = i
- for j in range(i+1, n):
- if arr[min_idx] > arr[j]:
- min_idx = j
- arr[i], arr[min_idx] = arr[min_idx], arr[i]
- return arr
- # 示例数组
- arr = [64, 25, 12, 22, 11]
- selection_sort(arr)
2.2.2 插入排序与快速排序
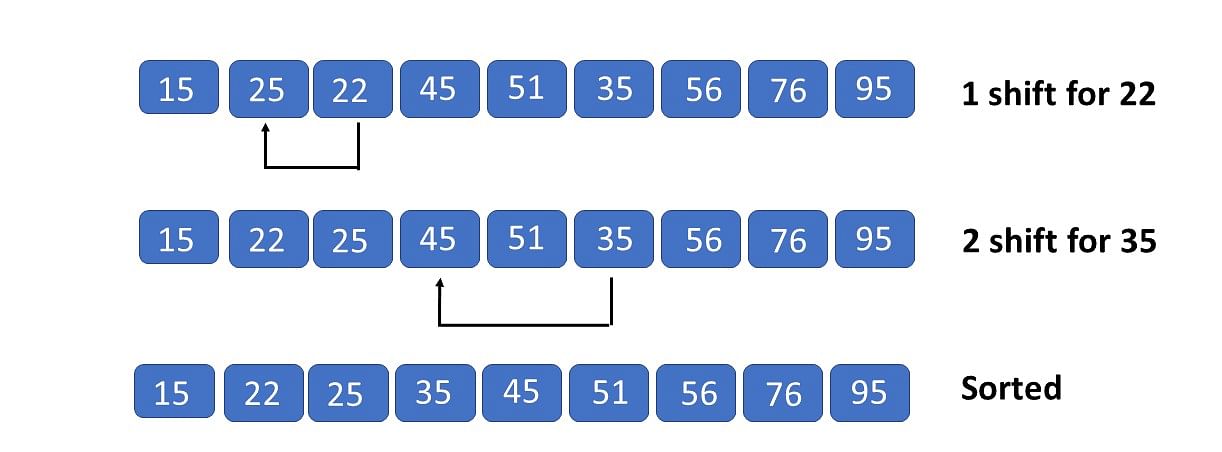
插入排序的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
- def insertion_sort(arr):
- for i in range(1, len(arr)):
- key = arr[i]
- j = i-1
- while j >=0 and key < arr[j]:
- arr[j + 1] = arr[j]
- j -= 1
- arr[j + 1] = key
- return arr
- # 示例数组
- arr = [12, 11, 13, 5, 6]
- insertion_sort(arr)
快速排序使用分治策略来把一个序列分为较小和较大的两个子序列,然后递归地排序两个子序列。快速排序的过程中,选择一个元素作为"基准"(pivot),重新排列数组中的元素,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- def quick_sort(arr):
- if len(arr) <= 1:
- return arr
- pivot = arr[len(arr) // 2]
- left = [x for x in arr if x < pivot]
- middle = [x for x in arr if x == pivot]
- right = [x for x in arr if x > pivot]
- return quick_sort(left) + middle + quick_sort(right)
- # 示例数组
- arr = [3, 6, 8, 10, 1, 2, 1]
- quick_sort(arr)
2.2.3 归并排序与堆排序
归并排序是一种分治算法。其思想是将原始数组切分成更小的数组,直到每个小数组只有一个位置,然后将小数组归并成更大的数组,直到最后只有一个排序完毕的大数组。因为是排序两个有序数组,所以归并排序每次合并操作的复杂度为O(n),且归并排序是稳定的排序方法。

堆排序是一种选择排序,它的最坏、最好和平均时间复杂度均为O(n log n)。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子节点的键值或索引总是小于(或者大于)它的父节点。堆排序的过程主要包括两个步骤:创建堆和逐步将每个元素从堆中取出。堆的创建可以通过将给定无序序列调整为堆来完成,逐步取出则是将堆顶元素与堆的最后一个元素交换,并减少堆的大小,然后重新调整堆。
2.3 算法稳定性分析
2.3.1 稳定性在排序中的作用
在排序算法中,稳定性是一个重要概念。如果一个排序算法可以保证相等的元素之间的相对顺序不变,则称该算法是稳定的。稳定性在实际应用中非常有用,尤其是在处理包含多个字段的数据时。举个例子,如果按照姓名排序后,想要再次按照年龄排序,稳定性的算法可以保持姓名排序的顺序。
2.3.2 各排序算法稳定性的对比
冒泡排序、插入排序和归并排序是稳定的排序算法。例如,在冒泡排序中,相等的元素不会因为排序而交换位置,而归并排序在合并过程中也会注意保持相同的元素顺序。
快速排序和堆排序不是稳定的算法。在快速排序中,相等的元素可能会被交换到数组的另一侧。堆排序中,由于数据是通过构建二叉堆来实现排序的,相同的元素可能在构建堆的过程中改变位置。
| 算法 | 时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|
| 冒泡排序 | O(n^2) | O(1) | 稳定 |
| 选择排序 | O(n^2) | O(1) | 不稳定 |
| 插入排序 | O(n^2) | O(1) | 稳定 |
| 快速排序 | O(n log n) | O(log n) | 不稳定 |
| 归并排序 | O(n log n) | O(n) | 稳定 |
| 堆排序 | O(n log n) | O(1) | 不稳定 |
在选择排序算法时,需要根据实际需求考虑是否需要稳定性,以及是否可以接受算法的空间复杂度,从而决定使用哪种排序方法。
3. 高级排序技术与实践应用
在这一章中,我们将深入探讨排序技术的高级主题,以及如何将这些技术应用于实际问题解决。我们会讨论递归与迭代的排序算法优化,多线程排序与并行计算的优势,以及大数据环境下排序技术的重要性。
3.1 递归与迭代的排序算法优化
3.1.1 递归算法的优化策略
递归算法在排序过程中提供了简洁的代码实现,但同时也存在性能上的挑战,尤其是在调用栈的深度方面。针对递归排序算法的优化策略主要包括减少递归深度和优化递归的函数效率。
一个常见的方法是将递归算法改写为迭代算法。例如,对于快速排序算法,可以通过使用一个栈来模拟递归过程,从而避免递归调用的开销。
下面是一个将快速排序改写为迭代形式的伪代码示例:
- function iterativeQuickSort(array):
- let stack = empty stack
- stack.push((0, len(array) - 1))
- while not stack.isEmpty():
- low, high = stack.pop()
- if low < high:
- pivotIndex = partition(array, low, high)
- stack

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【工业测量案例分析】:FLUKE_8845A_8846A在生产中的高效应用
天线设计基础:无线通信系统中的10大关键要素
EPLAN图纸自动更新与变更管理:【设计维护的自动化】:专家的实操技巧
【可扩展性设计】:打造可扩展BSW模块的5大设计原则
【用户体验至上的消费管理系统UI设计】:打造直观易用的操作界面
稳定性分析:快速排序何时【适用】与何时【避免】的科学指南
【性能调优大师】:高德地图API响应速度提升策略全解析
【网络架构师的挑战】:eNSP与VirtualBox在云网络设计中的应用
【案例研究】:专家分享:如何无障碍量产成功三启动U盘
优化算法实战:用R语言解决线性和非线性规划问题


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















