个性化购物体验:Hadoop在零售行业的数据驱动策略
发布时间: 2024-10-25 16:06:45 阅读量: 52 订阅数: 38 

新零售行业大数据分析平台建设整体解决方案.pptx

# 1. Hadoop在零售业中的重要性与应用背景
## 1.1 零售业数据量的爆炸性增长
随着互联网技术的发展和电子商务的兴起,零售业产生了大量的用户行为数据、交易记录和市场动态信息。这些数据的体量大、种类多、增长快,构成了一个典型的大数据环境。传统数据库和数据处理工具难以应对这种规模的数据处理需求,这为Hadoop等大数据处理框架的应用提供了契机。
## 1.2 Hadoop在零售业的价值体现
Hadoop作为一个开源的分布式存储和计算框架,能够高效地处理大量非结构化数据,并提供弹性扩展、容错和低成本存储的能力。在零售业中,Hadoop被用于用户行为分析、库存管理优化、供应链调整、市场趋势预测等多个方面,极大地提升了零售商的决策效率和市场竞争力。
## 1.3 应用背景与市场需求
零售商通过Hadoop进行数据分析,可以更好地理解客户需求,优化存货水平,降低运营成本,并提供个性化的购物体验。例如,通过Hadoop分析历史销售数据,零售商能够精准预测未来销售趋势,及时调整商品库存,避免过剩或缺货。此外,Hadoop能够处理来自社交媒体、网页点击流等外部数据源的数据,从而为零售商提供更为全面的市场洞察。
# 2. Hadoop生态系统详解
### 2.1 Hadoop核心组件介绍
#### 2.1.1 HDFS的工作原理和架构
Hadoop分布式文件系统(HDFS)是Hadoop的核心组件之一,它在Hadoop生态系统中负责数据存储。HDFS采用了主从架构,包含一个NameNode和多个DataNodes。NameNode管理文件系统命名空间和客户端对文件的访问。DataNode则在集群的节点上存储实际数据。
为了保障数据的高可靠性,HDFS默认会复制数据三个副本,分别存储在不同的DataNode上。当一个DataNode发生故障,系统仍能通过其他副本确保数据的可用性。HDFS支持大文件存储,并且适用于流式数据访问模式,非常适合批量处理和分析。
```mermaid
graph LR
A[Client] -->|读/写请求| B[NameNode]
B -->|文件系统元数据| C[DataNodes]
C -->|数据块存储| D[磁盘]
```
上图展示了HDFS的核心组件及其交互关系。客户端通过与NameNode交互来了解数据块位置,然后直接与存储数据的DataNodes通信。
### 2.1.2 MapReduce编程模型和应用案例
MapReduce是一种编程模型和处理大数据的计算框架,用于并行处理大规模数据集。MapReduce作业首先把输入数据分割成独立的块,每个块由一个Map任务处理,生成键值对中间结果。然后这些中间结果通过Shuffle过程,分发给不同的Reduce任务进行汇总,最终得到处理后的输出。
MapReduce可以应用到各种场景中,例如日志分析、文件索引构建、机器学习算法的训练等。以单词计数为例,Map阶段将文本切分成单词并计数,Reduce阶段则汇总所有单词的计数结果。
```java
// Map函数示例
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
// Reduce函数示例
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
```
在上述代码中,map函数将文档分割成单词并记录每个单词的出现次数,reduce函数则对所有单词的计数结果进行汇总。
### 2.2 Hadoop的外围工具和项目
#### 2.2.1 Hive和Pig的高级数据处理能力
Hive和Pig是构建在Hadoop之上的高级工具,它们允许用户使用类SQL语言和脚本语言对数据进行处理,而不必深入学习Java或MapReduce。Hive使用HiveQL语言,提供了一个类似传统数据库的查询接口,适用于数据仓库环境。Pig使用PigLatin语言,它是一种用于数据流的高级脚本语言,对于复杂的数据转换和分析操作来说非常方便。
Hive和Pig都提供了对HDFS的接口,允许用户直接读写存储在HDFS中的数据,并且它们都支持Hadoop的MapReduce作业提交机制,因此可利用Hadoop集群的分布式计算能力。
```sql
-- HiveQL示例
SELECT category, COUNT(*)
FROM sales
GROUP BY category;
```
上述HiveQL语句用于计算不同类别产品的销售数量。
```pig
-- Pig Latin示例
sales = LOAD 'sales.txt' as (date, category, amount);
counted = GROUP sales BY category;
summed = FOREACH counted GENERATE group, SUM(sales.amount);
```
上述Pig Latin代码处理了一个销售数据集,将销售数据按类别分组,并计算每个类别的总销售额。
#### 2.2.2 HBase和Cassandra的非关系型数据库应用
HBase和Apache Cassandra是分布式NoSQL数据库,它们为Hadoop提供了快速的随机访问能力。HBase建立在HDFS之上,适合存储大量稀疏数据集。它以列族为单位存储数据,提供了高可用性、可伸缩性和高性能的特性。
Cassandra则特别擅长分布式环境下的数据读写操作,它是一个去中心化的数据库,适合于构建多数据中心的分布式环境。Cassandra可以处理大量的写入请求,支持数据分区和复制,并提供了强大的容错性。
```java
// HBase表创建示例
Configuration config = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin();
TableName tableName = TableName.valueOf("ExampleTable");
HTableDescriptor tableDescriptor = new HTableDescriptor(tableName);
HColumnDescriptor columnDescriptor = new HColumnDescriptor("data");
tableDescriptor.addFamily(columnDescriptor);
admin.createTable(tableDescriptor);
```
上述代码展示了如何使用Java API在HBase中创建一个新表。
#### 2.2.3 Spark与Hadoop的整合及优势分析
Apache Spark是一个快速、通用、可扩展的大数据处理框架,它可以通过Hadoop的YARN进行集群资源管理。Spark与Hadoop整合的主要优势在于其内存计算能力,相比Hadoop的MapReduce模型,Spark可以将数据加载到内存中进行反复的迭代计算,从而大大提高处理速度。
Spark提供了一套丰富的API,支持多种编程语言,使得数据处理更加便捷。Spark的弹性分布式数据集(RDD)和数据框(DataFrame)等抽象概念使得数据处理更加高效和灵活。
```python
# Spark Python 示例: 读取HDFS中的文本文件并计算单词出现次数
sc = SparkContext('yarn', 'Python Spark Count')
text_file = sc.textFile("hdfs://path/to/textfile")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://path/to/output")
```
上述代码使用了SparkContext从HDFS读取数据文件,通过一系列转换操作最终计算出单词出现次数,并将结果保存回HDFS。
### 2.3 数据存储与管理策略
#### 2.3.1 数据仓库的选择与设计
数据仓库是专门为了支持决策而设计的系统,它能够存储、管理和提供大量的历史数据。在Hadoop生态系统中,Hive和Impala是比较常用的两个数据仓库解决方案。它们都支持SQL查询语言,Hive更适合复杂的批处理分析,而Impala则提供了更快的即时查询能力。
数据仓库的设计通常涉及星型模型或雪花模型。星型模型由一个中心表(事实表)和多个维度表组成,而雪花模型是对星型模型的进一步规范化。设计数据仓库时需要考虑数据整合、数据质量和数据模型设计等要素。
#### 2.3.2 数据湖的概念及其在Hadoop中的实现
数据湖是一个存储原始企业数据的仓库,通常是未经加工和分类的。与传统数据仓库不同,数据湖主要关注数据的存储,而不强调对数据的结构化处理。Hadoop为数据湖提供了理想的存储解决方案,用户可以在Hadoop集群上存储大量原始数据,然后再根据需要进行加工和分析。
数据湖通常包括数据的存储、管理、分析等关键组件。数据在Hadoop中的存储一般使用HDF

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Hadoop 核心组件及其在构建大数据处理平台中的关键作用。从 HDFS 的数据存储机制到 YARN 的资源管理架构,再到 MapReduce 的处理加速器,文章全面解析了 Hadoop 的各个组件。此外,还深入研究了 ZooKeeper 在保障集群协调一致性中的作用,以及 Hadoop 生态系统中其他组件的互补性。专栏还提供了 Hadoop 集群搭建、优化、故障排查和安全机制的实用指南。通过深入剖析 Hadoop 的技术细节和实际应用,本专栏为读者提供了全面了解 Hadoop 核心组件及其在各种行业中的应用的宝贵资源。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【非线性材料的秘密】:10个案例揭示分析精度提升策略
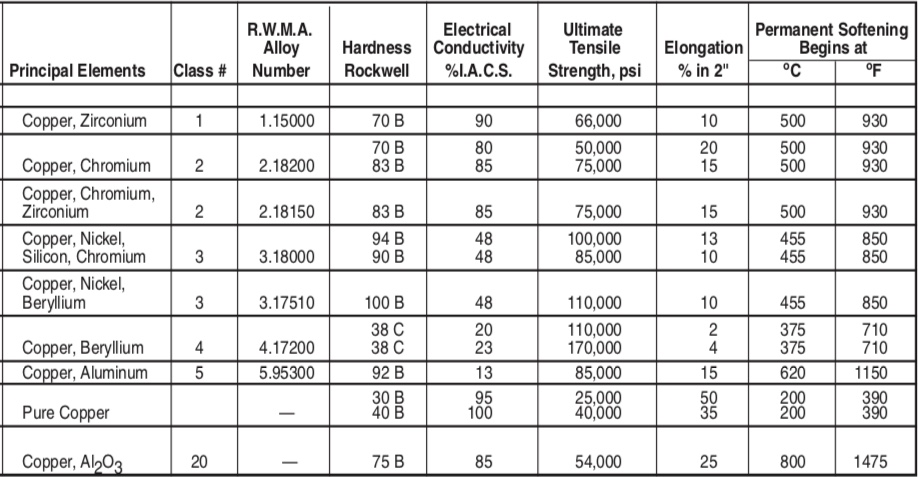
# 摘要
非线性材料的研究是现代材料科学领域的重要课题,它关系到光通信、压电应用和光学晶体等关键技术的发展。本文首先介绍了非线性材料的基础知识,探讨了其物理机制、非线性系数测量以及理论模型的发展。随后,文章转向实验技术与精度分析,讨论了实验测量技术的挑战、数据处理方法以及精度验证。通过案例研究,本文深入分析了不同领域中非线性材料分析精度提升的策略与效果。最后,文章展望了非线性材料分析的技术前沿和未来发展趋势,并讨论了实现进一步精度提升
【PCIe Gen3升级宝典】:Xilinx 7系列向PCIe Gen3迁移实用指南

# 摘要
PCIe技术作为高带宽计算机总线标准,在数据传输领域占据重要地位。随着应用需求的增长,PCIe Gen3标准的推
GT-power仿真秘籍:构建复杂模型的5个关键步骤
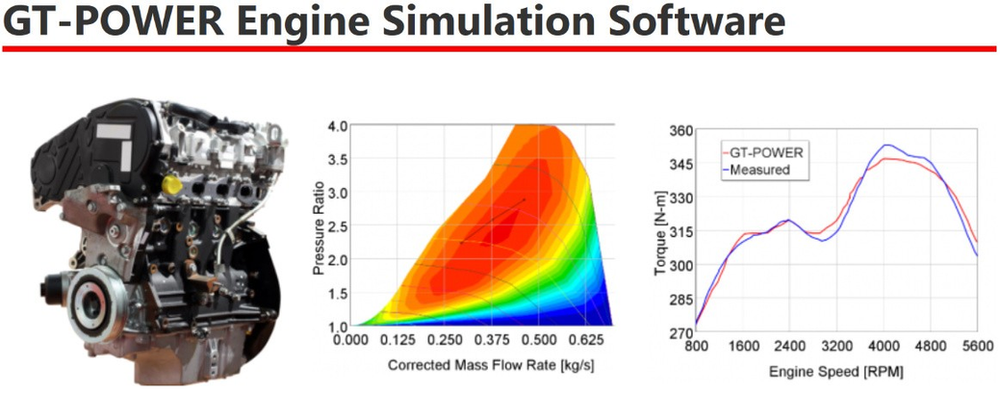
# 摘要
GT-power仿真技术作为一种高效的动力系统分析工具,在内燃机和其他动力设备的性能评估和设计优化中发挥着重要作用。本文首先概述了GT-power仿真的基本概念和应用范围,然后详细介绍了构建GT-power模型的理论基础,包括对软件工作原理的理解、模型构建的理论框架、关键参数的设置
【MySQL索引优化大师】:揭秘高效检索与最佳索引选择技巧
# 摘要
本文系统地探讨了MySQL数据库中索引的基础知识、类型、优化实践技巧以及选择策略,并展望了未来索引技术的发展趋势。首先介绍了索引的作用和基础概念,接着详述了不同索引类型如B-Tree、Hash、全文索引以及稀疏和密集索引,并分析了它们的工作原理及适用场景。随后,本文深入讨论了索引的创建、管理、监控以及诊断工具,结合实际案例分析了索引
【软件兼容性升级指南】:PCIe 5.0驱动程序影响及应对策略解析
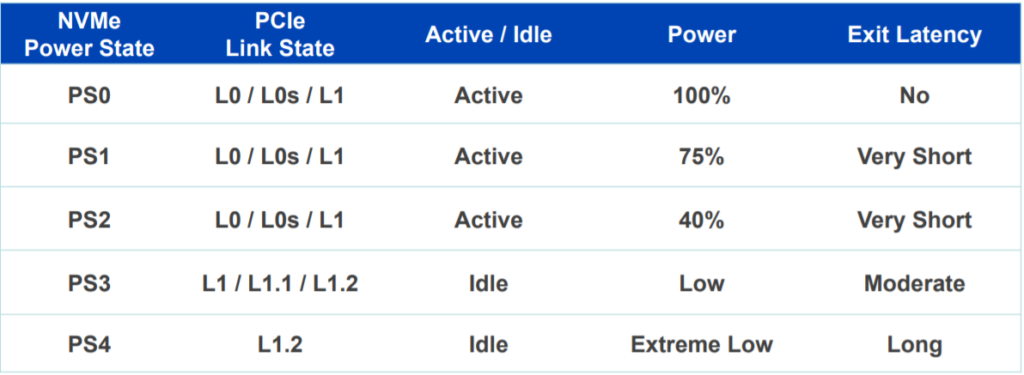
# 摘要
随着PCIe技术的持续发展,PCIe 5.0已经成为高速数据传输的新标准,对驱动程序的兼容性升级提出了新的要求。本文首先概述了PCIe 5.0技术及其驱动程序基础,强调了软件兼容性升级的重要性,并详细分析了在升级过程中所面临的挑战和影响。通过系统评估、测试与模拟,以及实际案例研究,本文深入讨论了兼容性升级的具体实施步骤,包括检查、安装、验证、优化、监控和维护。研究结果表明,经过周密的准备和测试,可以有效地实现PCIe 5.0驱动程序的
【Vue组件性能优化】:实现大型表格数据的高效渲染
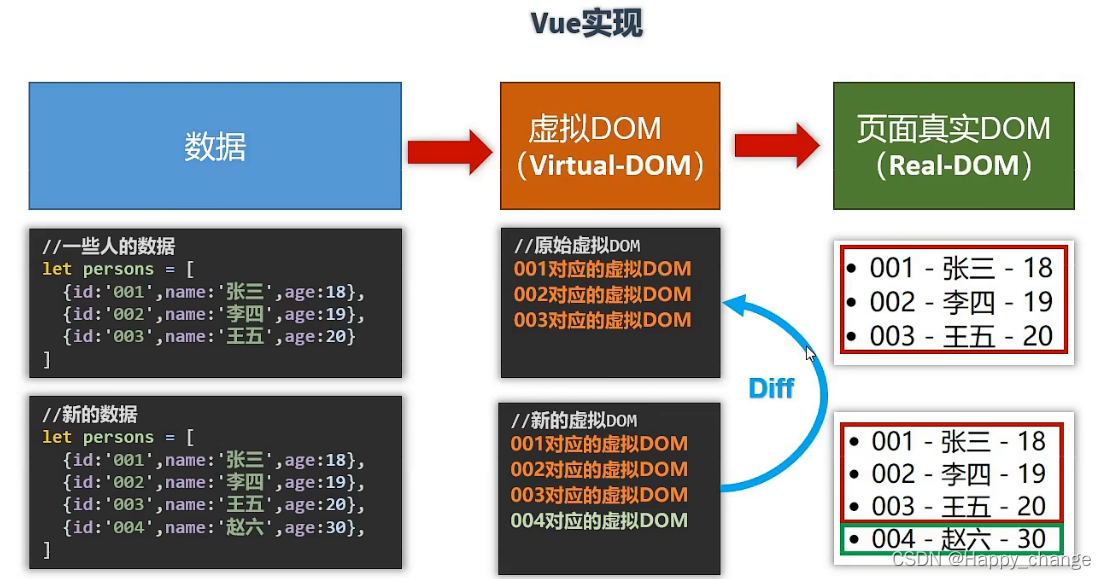
# 摘要
随着Web应用的日益复杂,Vue组件性能优化成为提升用户体验的关键。本文首先概述了Vue组件性能优化的重要性,然后深入探讨了性能优化的理论基础,包
【模拟与数字电路的混合设计】:探索16位加法器的新境界
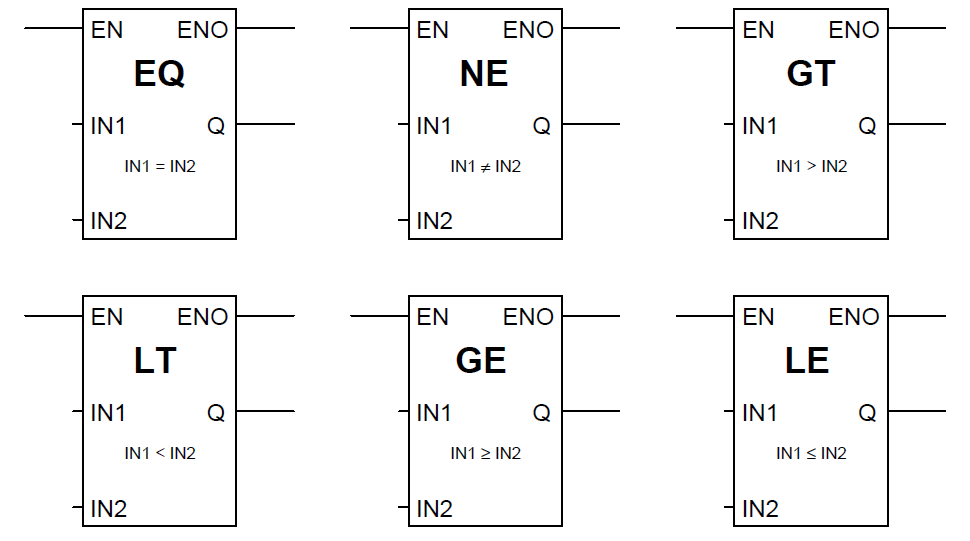
# 摘要
本文综合分析了数字电路与模拟电路融合的先进技术,重点研究了16位加法器的设计基础、电路实现与优化、混合信号环境下的应用、以及与微控制器的编程接口。通过对16位加法器的硬件设计原理和电路模拟仿真的探讨,本文详细阐述了加法器在不同领域的应用案例,并针对微控制器的交互提出了具体的编程策
Android UBOOT教程:如何优化开机logo动画效果,提升启动视觉冲击力

# 摘要
本文详细探讨了UBOOT在Android系统启动过程中的关键作用,以及如何通过优化开机logo动画来提升用户体验。首先,分析了UBOOT的初始化过程与Android启动序列的关系。随后,介绍了开机动画的类型、格式及其与用户交互的方式。实践部分详细阐述了开机动画素材的准备、设计、编码实现以及性能优化策略。进一步,本文探讨了通过自定义UB
内存映射I_O揭秘:微机接口技术深度解析

# 摘要
内存映射I/O是一种高效的数据传输技术,通过将设备寄存器映射到处理器的地址空间,实现快速的数据交换。本文首先介绍了内存映射I/O的基本概念和原理,然后详细探讨了其技术实现,包括硬件结构、软件模型以及编程接口。通过分析内存映射I/O在设备驱动开发、性能优化以及现代计算架构中的应用案例,本文阐述了其在提升系统性能和简化编程复杂性方面的优势。最后,针对内存映射I/O面临的安全挑战和技术发展趋势进
CMW100 WLAN故障快速诊断手册:立即解决网络难题
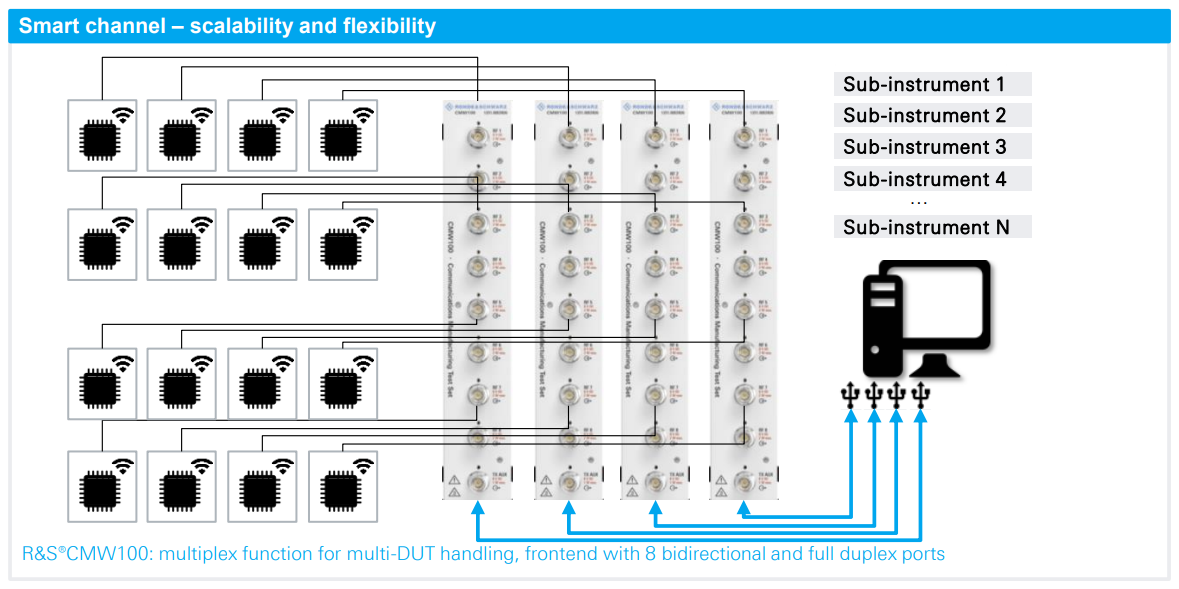
# 摘要
随着无线局域网(WLAN)技术的广泛应用,网络故障诊断成为确保网络稳定性和性能的关键环节。本文深入探讨了WLAN故障诊断的基础知识,网络故障的理论,以及使用CMW100这一先进的诊断工具进行故障排除的具体案例。通过理解不同类型的WLAN故障,如信号强度问题、接入限制和网络配置错误,并应用故障诊断的基本原则和工具,本文提供了对网络故障分析和解决过程的全面视角。文章详细介绍了CMW100的功能、特点及在实战中如何应对无线信号覆盖问题、客户端接入问题和网络安全漏
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )