【10大MATLAB数组秘籍】:从创建到优化,提升代码效率
发布时间: 2024-06-08 11:52:28 阅读量: 117 订阅数: 44 

# 1. MATLAB数组的基础和创建
MATLAB数组是MATLAB中存储和处理数据的基本数据结构。它们是一组具有相同数据类型和维度的元素。
### 1.1 创建数组
创建MATLAB数组有以下几种方法:
- **使用方括号 ([]):**`array_name = [element1, element2, ..., elementN]`
- **使用内置函数:**
- `zeros(m, n)`:创建大小为 m x n 的全零数组
- `ones(m, n)`:创建大小为 m x n 的全一数组
- `rand(m, n)`:创建大小为 m x n 的随机数组
- **从其他数据源导入:**
- `load('filename.mat')`:从 MAT 文件导入数组
- `importdata('filename.txt')`:从文本文件导入数组
# 2. MATLAB数组的属性和操作
### 2.1 数组的维度、大小和类型
**2.1.1 获取数组的维度和大小**
MATLAB中数组的维度表示其元素的排列方式。一维数组是向量,二维数组是矩阵,三维数组是张量。
```matlab
% 创建一个二维数组
A = [1 2 3; 4 5 6; 7 8 9];
% 获取数组的维度
ndims(A) % 2
% 获取数组的大小(每个维度中的元素数)
size(A) % [3 3]
```
**2.1.2 转换数组的类型**
MATLAB提供多种数据类型,包括整数、浮点数、字符串和逻辑值。可以使用`cast`函数转换数组的类型。
```matlab
% 将一个浮点数数组转换为整数数组
B = cast(A, 'int32');
% 检查转换后的数组类型
class(B) % 'int32'
```
### 2.2 数组的索引和切片
**2.2.1 线性索引**
线性索引将多维数组中的元素视为一维向量中的元素。可以使用`(:)`运算符获取线性索引。
```matlab
% 获取数组A的线性索引
linear_index = A(:);
% 使用线性索引访问数组元素
A(linear_index(5)) % 5
```
**2.2.2 逻辑索引**
逻辑索引使用布尔值数组来选择数组中的元素。
```matlab
% 创建一个逻辑索引数组
index = A > 5;
% 使用逻辑索引访问数组元素
A(index) % [7 8 9]
```
**2.2.3 切片操作**
切片操作允许使用冒号(`:`)从数组中提取子数组。
```matlab
% 从数组A中提取第二行
A(2, :) % [4 5 6]
% 从数组A中提取第二列
A(:, 2) % [2 5 8]
% 从数组A中提取从第二行到第三行,第二列到第三列的子数组
A(2:3, 2:3) % [5 6; 8 9]
```
### 2.3 数组的数学和逻辑运算
**2.3.1 基本的数学运算**
MATLAB支持各种数学运算,包括加法、减法、乘法、除法和幂运算。
```matlab
% 加法
A + B % [2 4 6; 6 8 10; 8 10 12]
% 减法
A - B % [0 0 0; 0 0 0; 0 0 0]
% 乘法
A .* B % [1 4 9; 16 25 36; 49 64 81]
% 除法
A ./ B % [1 2 3; 2 2.5 3; 3.5 4 4.5]
% 幂运算
A.^2 % [1 4 9; 16 25 36; 49 64 81]
```
**2.3.2 逻辑运算**
MATLAB支持逻辑运算,包括`and`、`or`和`not`。
```matlab
% 逻辑与
A & B % [0 0 0; 0 1 0; 0 0 0]
% 逻辑或
A | B % [1 2 3; 4 5 6; 7 8 9]
% 逻辑非
~A % [0 0 0; 0 0 0; 0 0 0]
```
# 3.1 数组的重塑和拼接
#### 3.1.1 数组的重塑
数组重塑是指改变数组的维度和大小,而不改变其元素的值。MATLAB 提供了 `reshape()` 函数来实现数组的重塑。`reshape()` 函数的语法如下:
```
B = reshape(A, new_size)
```
其中:
* `A` 是要重塑的数组。
* `new_size` 是重塑后的数组的新尺寸,是一个整数向量。
`new_size` 向量的元素指定了重塑后数组的每个维度的长度。如果 `new_size` 向量的元素乘积与 `A` 数组的元素个数相等,则重塑操作成功。否则,`reshape()` 函数将返回一个错误。
**示例:**
```
A = [1 2 3 4 5 6 7 8 9];
B = reshape(A, [3, 3]);
disp(B)
```
输出:
```
1 2 3
4 5 6
7 8 9
```
在该示例中,`A` 数组是一个 1x9 的行向量。`reshape()` 函数将 `A` 数组重塑为一个 3x3 的矩阵。
#### 3.1.2 数组的拼接
数组拼接是指将两个或多个数组连接在一起形成一个新的数组。MATLAB 提供了 `cat()` 函数来实现数组的拼接。`cat()` 函数的语法如下:
```
C = cat(dim, A1, A2, ..., An)
```
其中:
* `dim` 指定了拼接的维度。可以是 1(按行拼接)、2(按列拼接)或更高维度。
* `A1`, `A2`, ..., `An` 是要拼接的数组。
**示例:**
```
A = [1 2 3];
B = [4 5 6];
C = cat(2, A, B);
disp(C)
```
输出:
```
1 2 3 4 5 6
```
在该示例中,`A` 和 `B` 都是 1x3 的行向量。`cat()` 函数将 `A` 和 `B` 按列拼接,形成一个 1x6 的行向量。
# 4. MATLAB数组的进阶应用
### 4.1 稀疏数组和结构化数组
#### 4.1.1 稀疏数组
稀疏数组是一种特殊类型的数组,其中大多数元素为零。它适用于数据集中非零元素数量远少于零元素数量的情况。稀疏数组使用特殊的数据结构来存储非零元素,从而节省内存并提高计算效率。
在 MATLAB 中,可以使用 `sparse` 函数创建稀疏数组:
```matlab
% 创建一个稀疏数组
A = sparse([1, 3, 5], [2, 4, 6], [10, 20, 30], 5, 6);
% 查看稀疏数组
spy(A) % 以可视化方式显示非零元素
```
`sparse` 函数的参数包括:
- `row_indices`:非零元素的行索引
- `col_indices`:非零元素的列索引
- `values`:非零元素的值
- `m`:稀疏数组的行数
- `n`:稀疏数组的列数
稀疏数组支持与普通数组类似的操作,例如数学运算、索引和切片。但是,由于其特殊的数据结构,某些操作可能会比普通数组慢。
#### 4.1.2 结构化数组
结构化数组是一种数组,其中每个元素都是一个结构体。结构体是一种复合数据类型,可以包含不同类型的数据字段。
在 MATLAB 中,可以使用 `struct` 函数创建结构化数组:
```matlab
% 创建一个结构化数组
student_data = struct('name', {'John', 'Mary', 'Bob'}, ...
'age', [20, 22, 25], ...
'gpa', [3.5, 3.8, 4.0]);
% 访问结构化数组中的字段
student_data.name(1) % 输出:'John'
```
结构化数组中的每个元素都是一个结构体,可以像普通结构体一样访问其字段。结构化数组支持与普通数组类似的操作,例如索引、切片和数学运算。
### 4.2 元胞数组和表
#### 4.2.1 元胞数组
元胞数组是一种数组,其中每个元素都可以包含任何类型的数据,包括其他数组、结构体或函数句柄。元胞数组类似于 Python 中的列表或 JavaScript 中的数组。
在 MATLAB 中,可以使用 `cell` 函数创建元胞数组:
```matlab
% 创建一个元胞数组
cell_array = {'John', 20, 3.5; 'Mary', 22, 3.8; 'Bob', 25, 4.0};
% 访问元胞数组中的元素
cell_array{1, 1} % 输出:'John'
```
元胞数组中的每个元素都是一个元胞,可以包含任何类型的数据。元胞数组支持与普通数组类似的操作,例如索引、切片和连接。
#### 4.2.2 表
表是一种类似于结构化数组的数据类型,但它提供了更灵活和易于使用的界面。表中的每一行都表示一个记录,每一列都表示一个字段。
在 MATLAB 中,可以使用 `table` 函数创建表:
```matlab
% 创建一个表
student_table = table({'John', 'Mary', 'Bob'}, [20, 22, 25], [3.5, 3.8, 4.0], ...
'VariableNames', {'name', 'age', 'gpa'});
% 访问表中的数据
student_table.name(1) % 输出:'John'
```
表支持与结构化数组类似的操作,例如索引、切片和数学运算。此外,表还提供了专门用于处理表格数据的函数,例如 `sortrows` 和 `filterrows`。
### 4.3 自定义数据类型
#### 4.3.1 创建自定义数据类型
MATLAB 允许用户创建自己的自定义数据类型,称为类。类可以包含数据字段、方法和属性。
要创建自定义数据类型,可以使用 `classdef` 语句:
```matlab
% 创建一个名为 'Student' 的自定义数据类型
classdef Student
properties
name
age
gpa
end
methods
function obj = Student(name, age, gpa)
obj.name = name;
obj.age = age;
obj.gpa = gpa;
end
function display(obj)
fprintf('Name: %s, Age: %d, GPA: %.2f\n', obj.name, obj.age, obj.gpa);
end
end
end
```
`classdef` 语句定义了类的名称、属性和方法。属性是类的数据字段,方法是类可以执行的操作。
#### 4.3.2 使用自定义数据类型
一旦创建了自定义数据类型,就可以像使用其他 MATLAB 数据类型一样使用它:
```matlab
% 创建一个 'Student' 类的对象
student1 = Student('John', 20, 3.5);
% 访问对象属性
student1.name % 输出:'John'
% 调用对象方法
student1.display() % 输出:'Name: John, Age: 20, GPA: 3.50'
```
自定义数据类型提供了封装和代码重用,使代码更易于维护和扩展。
# 5. MATLAB数组的函数和工具箱
MATLAB 提供了丰富的内置函数和工具箱,用于处理和分析数组。这些函数和工具箱可以帮助您高效地执行各种任务,从基本数学运算到复杂的数据分析。
### 5.1 内置函数和工具箱
#### 5.1.1 常用的数组函数
MATLAB 提供了许多内置函数,用于执行常见的数组操作,例如:
- **size():**获取数组的维度和大小。
- **reshape():**重塑数组的维度。
- **cat():**连接多个数组。
- **sort():**对数组进行排序。
- **find():**查找数组中满足特定条件的元素。
**代码块:**
```matlab
% 创建一个数组
A = [1, 2, 3; 4, 5, 6; 7, 8, 9];
% 获取数组的维度和大小
size_A = size(A);
% 重塑数组
B = reshape(A, [1, 9]);
% 连接两个数组
C = cat(1, A, B);
% 对数组进行排序
sorted_A = sort(A);
% 查找数组中大于 5 的元素
indices = find(A > 5);
```
**逻辑分析:**
* `size()` 函数返回一个包含数组维度和大小的向量。
* `reshape()` 函数将数组重塑为指定维度。
* `cat()` 函数将多个数组连接在一起,可以按行或按列连接。
* `sort()` 函数对数组进行升序或降序排序。
* `find()` 函数返回一个包含满足特定条件的元素索引的向量。
#### 5.1.2 数据分析工具箱
MATLAB 数据分析工具箱提供了一系列函数,用于执行复杂的数据分析任务,例如:
- **stats:**用于统计分析。
- **curvefit:**用于曲线拟合。
- **signal:**用于信号处理。
- **optim:**用于优化。
**代码块:**
```matlab
% 使用 stats 工具箱计算数组的均值
mean_A = mean(A);
% 使用 curvefit 工具箱拟合一条线性曲线
[fitresult, gof] = fit(x, y, 'poly1');
% 使用 signal 工具箱滤波数组
filtered_A = filtfilt(b, a, A);
% 使用 optim 工具箱优化一个函数
x0 = [0, 0]; % 初始猜测
options = optimset('Display', 'iter'); % 设置优化选项
[x, fval] = fminunc(@(x) myfun(x), x0, options);
```
**逻辑分析:**
* `mean()` 函数计算数组的均值。
* `fit()` 函数拟合一条指定类型的曲线到数据。
* `filtfilt()` 函数使用数字滤波器滤波数组。
* `fminunc()` 函数使用无约束优化算法优化一个函数。
### 5.2 第三方工具箱
除了内置函数和工具箱外,MATLAB 还支持许多第三方工具箱,用于特定领域的专业任务。
#### 5.2.1 图像处理工具箱
图像处理工具箱提供了一系列函数,用于处理和分析图像,例如:
- **imread():**读取图像文件。
- **imshow():**显示图像。
- **imresize():**调整图像大小。
- **edge():**检测图像中的边缘。
**代码块:**
```matlab
% 使用图像处理工具箱读取图像
image = imread('image.jpg');
% 显示图像
imshow(image);
% 调整图像大小
resized_image = imresize(image, 0.5);
% 检测图像中的边缘
edges = edge(image, 'canny');
```
**逻辑分析:**
* `imread()` 函数从文件读取图像。
* `imshow()` 函数显示图像。
* `imresize()` 函数调整图像的大小。
* `edge()` 函数使用 Canny 算法检测图像中的边缘。
#### 5.2.2 机器学习工具箱
机器学习工具箱提供了一系列函数,用于构建和训练机器学习模型,例如:
- **fitcsvm():**训练支持向量机模型。
- **fitctree():**训练决策树模型。
- **fitglm():**训练广义线性模型。
- **predict():**使用训练好的模型进行预测。
**代码块:**
```matlab
% 使用机器学习工具箱训练一个支持向量机模型
model = fitcsvm(X, y);
% 使用训练好的模型进行预测
predictions = predict(model, X_test);
% 评估模型的性能
accuracy = mean(predictions == y_test);
```
**逻辑分析:**
* `fitcsvm()` 函数训练一个支持向量机模型。
* `predict()` 函数使用训练好的模型对新数据进行预测。
* `mean()` 函数计算预测的准确性。
# 6. MATLAB数组的最佳实践和故障排除
### 6.1 数组最佳实践
#### 6.1.1 选择合适的数组类型
根据数据的性质和预期操作选择合适的数组类型。例如:
- **数值数组:**用于存储数字数据,如 `double`、`single`、`int32`。
- **字符数组:**用于存储文本数据,如 `char`。
- **逻辑数组:**用于存储布尔值,如 `logical`。
- **元胞数组:**用于存储不同类型数据的集合,如 `cell`。
#### 6.1.2 优化数组的内存使用
MATLAB中数组的内存占用取决于其元素类型和大小。以下技巧可以优化内存使用:
- **使用紧凑的数据类型:**选择占用的内存最小的数据类型,如 `single` 代替 `double`。
- **避免不必要的复制:**使用 `view` 函数创建数组的视图,而不是复制。
- **预分配数组:**在填充数组之前预先分配其大小,以避免内存碎片化。
### 6.2 数组故障排除
#### 6.2.1 常见的数组错误
MATLAB中常见的数组错误包括:
- **索引超出范围:**尝试访问不存在的数组元素。
- **数据类型不匹配:**尝试对不同数据类型的数组执行操作。
- **维度不匹配:**尝试对具有不同维度的数组执行操作。
#### 6.2.2 调试数组问题
调试数组问题可以使用以下技巧:
- **使用 `whos` 命令:**查看数组的名称、类型、大小和内存占用。
- **使用 `disp` 命令:**显示数组的内容。
- **使用 `size` 和 `ndims` 函数:**获取数组的维度和大小。
- **使用 `find` 和 `isnan` 函数:**查找数组中的特定值或 NaN 值。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“10大MATLAB数组秘籍”深入探究了MATLAB数组的创建、优化和操作技巧。从基础的数组类型和维度到高级的索引、切片和转置技术,该专栏提供了全面的指南,帮助读者提升MATLAB代码的效率和可读性。通过掌握这些秘籍,读者可以高效地提取数据、重排数据、组织数据,从而优化代码性能并简化数据处理任务。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Unity C# Mathf.Abs() 函数性能成本深度剖析

# 摘要
本论文全面介绍 Mathf.Abs() 函数的定义、应用及内部实现机制,并重点分析了其性能特性。通过探讨 Mathf.Abs() 在不同场景下的性能成本,我们提供了量化的性能分析,揭示了在高频调用情况下可能出现的性能瓶颈。接着,本文探讨了多种避免性能损耗的策略,包括代码优化技巧和寻找替代方案。最后,结合复杂系统的应用实例,本文展示了 Mathf.Abs() 的实际应用效果,并对未来函数的改进与优化方向提供了展望。本研究旨在帮助开发者更深入理解
深度剖析LGO:高级用户如何优化作业流程与数据管理

# 摘要
本文全面介绍LGO系统及其在作业流程优化中的应用。首先概述了LGO的基本概念和作业流程基础,然后深入分析了LGO在作业流程优化中的理论和实践应用,包括自动化、监控及日志记录。文中还探讨了LGO在数据管理方面的能力,阐述了高级数据挖掘、数据安全与备份,以及数据库集成与优化的策略。在跨部门协作方面,讨论了LGO如何提
MTK工程模式下的代码优化:提升系统响应速度的高效方法

# 摘要
本文针对MTK工程模式下的代码优化进行了全面的研究和实践探讨。首先概述了代码优化的基本理论基础,接着详细分析了系统响应速度优化的必要性和实施方法,包括性能评估、资源消耗最小化、系统架构调整、编译器优化技术等。随后,本文深入到具体的代码优化策略,探讨了数据处理、内存管理和多线程并发优化的实践方法。文章进一步研究了MTK工程模式下的代码调试与性能分析技巧,包括调试工具的使用、性能分
个性化DEWESoftV7.0界面

# 摘要
DEWESoft V7.0作为一款先进的数据采集与分析软件,其界面定制功能极大地提升了用户体验和工作效率。本文首先概述了DEWESoft V7.0的基本界面和定制基础,随后详细介绍了界面元素的类型、功能、布局定制以及主题与样式的自定义。文章进一步探讨了高级定制技术,包括脚本编程的应用、插件开发与界面扩展、以及界面的维护与管理策略。通过实践案例分析,本文展现了定制界面在实际工作中的应用,并分享了成功案例
【DELL PowerEdge T30 硬盘故障应对大揭秘】:数据安全与恢复技巧

# 摘要
本文全面分析了DELL PowerEdge T30服务器硬件及其硬盘基础知识,深入探讨了硬盘故障的理论、诊断方法、数据安全与备份技术,以及高级技术应对策略。通过对硬盘结构、故障
KeeLoq算法漏洞与防护:安全专家的实战分析(专业性、权威性)

# 摘要
KeeLoq算法是用于无线遥控加密的常见加密技术,本文详细概述了KeeLoq算法及其漏洞,深入分析了其工作原理、安全性评估、漏洞发现与分析,以及修复策略和防护措施。通过对KeeLoq算法的数学模型、密钥管理机制以及理论与实际应用中的安全挑战的探讨,揭示了导致漏洞的关键因素。同时,本文提出了相应的修复方案和防护措施,包括系统升级、密钥管理强化,以及安全最佳实践的建议,并展望了算法未来改进的方向和在新兴技术中的应用。通过案
【OS单站性能调优】:从客户反馈到系统优化的全过程攻略

# 摘要
性能调优是确保系统稳定运行和提升用户体验的关键环节。本文首先概述了性能调优的重要性和基础概念,强调了性能监控和数据分析对于识别和解决系统瓶颈的作用。随后,深入探讨了系统级优化策略,包括操作系统内核参数、网络性能以及系统服务和进程的调整。在应用性能调优实践中,本文介绍了性能测试方法和代码级性能优化的技巧,同时分析了数据库性能调优的重要性。最后,
【Unix gcc编译器全攻略】:最佳实践+常见问题一网打尽

# 摘要
本文深入介绍Unix环境下的gcc编译器,覆盖基础使用、核心功能、项目最佳实践、高级特性、常见问题解决以及未来展望等多方面内容。首先,介绍了gcc编译器的基本概念、安装与配置,并详解了其编译流程和优化技术。随后,探讨了在多文件项目中的编译管理、跨平台编译策略以及调试工具的使用技巧。文章进一步分析gcc对现代C++标准的支持、内建函数以及警告和诊断机制。最后,本文讨论了
【如何预防潜在故障】:深入解析系统故障模式与影响分析(FMEA)
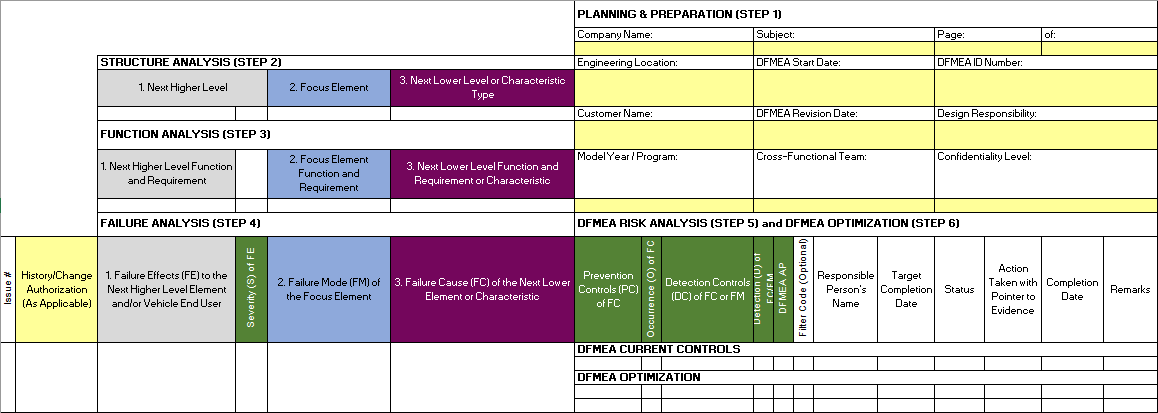
# 摘要
故障模式与影响分析(FMEA)是一种系统性、预防性的质量和可靠性工具,用于识别产品或过程中可能出现的故障模式、原因和影响,并评估其严重性。本文系统介绍了FMEA的理论基础、应用流程以及其在实践操作和预防性维护中的应用。通过分析FMEA的种类和方法论,包括设计FMEA(DFMEA)和过程FMEA(PFMEA),文章深入阐述了建立FMEA团队、进行故障树分析(FTA)和案例研究的实
架构设计与性能优化:字节跳动的QUIC协议应用案例

# 摘要
QUIC协议作为下一代互联网传输协议,旨在解决现有TCP协议中存在的问题,特别是在延迟敏感型应用中的性能瓶颈。本文首先概述了QUIC协议及其网络性能理论基础,深入分析了网络延迟、吞吐量、多路复用与连接迁移等关键性能指标,并探讨了QUIC协议的安全特性。接着,通过字节跳动的QUIC协议实践应用案例,本文讨论了部署与集成过程中的技术挑战和性能优化实例。进一步,从架
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )