程序员面试算法全攻略:从入门到精通(必读指南)
发布时间: 2024-12-28 10:11:59 阅读量: 4 订阅数: 7 

黑马程序员 linux从入门到精通配套笔记.docx

# 摘要
程序员面试中算法题目的表现是衡量技术能力和潜在价值的关键指标。本文首先强调了算法在面试中的重要性,并探讨了有效的准备方法。接着,文章深入介绍了数据结构的基础知识及其在算法实现中的应用,包括线性结构、树与图的算法应用,以及排序和搜索算法的原理和实现。在深入解析动态规划和贪心算法的基础上,文章讨论了这两种算法的原理、应用场景以及如何在面试中做出选择。此外,本文还提供了算法设计的思维模式、面试中的算法问题解决策略,以及如何应对面试中的非技术性问题。最后,探讨了高级算法的应用、编程语言选择对算法实现的影响以及终身学习对算法能力提升的重要性。本文旨在为程序员提供一个全面的面试算法准备和进阶学习指南。
# 关键字
算法面试;数据结构;动态规划;贪心算法;编程语言选择;终身学习
参考资源链接:[程序员面试必备:实用算法集锦](https://wenku.csdn.net/doc/2b9k9b8gkc?spm=1055.2635.3001.10343)
# 1. 程序员面试算法的重要性与准备
## 1.1 算法在面试中的地位
在IT行业的求职过程中,算法能力是考察一个程序员技术水平的重要指标。掌握扎实的算法知识不仅能够帮助你通过面试关卡,还能在工作中解决复杂问题,提升开发效率。
## 1.2 面试前的准备策略
准备面试时,首先要复习数据结构和算法基础,如数组、链表、栈、队列、树、图、排序和搜索算法等。其次,要通过实际编码练习来加深对这些概念的理解和应用。
## 1.3 通过实例加深理解
在复习过程中,建议通过编写具体的代码实例来验证算法的正确性和效率。例如,实现一个快速排序算法,并分析其时间复杂度,这样做可以加强记忆并理解算法的深层次原理。
## 1.4 面试中算法题目的应对
面对面试中的算法题目,一定要保持冷静,仔细审题,了解题目要求。在编码时,注意代码的整洁性和可读性,这通常会给面试官留下良好印象。如果遇到难题,可以尝试与面试官沟通,从不同角度思考问题,但切勿盲目编写不成熟的代码。
# 2. 数据结构基础与算法实践
在IT行业中,数据结构和算法的重要性不言而喻,它们是编程的基础,是构建高效软件的基石。数据结构决定了数据如何存储与组织,而算法则是解决问题的一系列定义良好的计算步骤。本章将带你深入理解数据结构的基本概念,并通过实践的方式加深对算法应用的理解。
## 2.1 线性结构的算法应用
### 2.1.1 数组和链表的操作
数组和链表是最基本的线性结构,它们各有优缺点,适用于不同的场景。
**数组**是一种线性数据结构,其中的元素通过连续的内存空间进行存储,且每个元素的类型相同。数组具有很好的随机访问性能,但插入和删除操作较为低效,因为它需要移动大量元素。
```java
// Java中数组的创建和初始化
int[] numbers = new int[5];
for (int i = 0; i < numbers.length; i++) {
numbers[i] = i;
}
```
而**链表**,作为一种链式结构,每个节点包含数据和指向下个节点的链接。链表的插入和删除操作比较高效,因为它仅需要修改相邻节点的链接,但它的随机访问性能较差。
```java
// Java中单向链表节点的定义
class ListNode {
int val;
ListNode next;
ListNode(int x) { val = x; }
}
// 链表的插入操作
ListNode head = new ListNode(1);
head.next = new ListNode(2);
head.next.next = new ListNode(3);
```
### 2.1.2 栈与队列的实现和运用
**栈**是一种后进先出(LIFO)的数据结构,最后一个进入的元素会是第一个被访问的元素。栈的操作包括压栈(push)和弹栈(pop),以及查看栈顶元素(peek)。
```java
// Java中栈的实现示例
Stack<Integer> stack = new Stack<>();
stack.push(1);
stack.push(2);
stack.pop();
```
**队列**则是一种先进先出(FIFO)的数据结构,元素的添加(enqueue)和移除(dequeue)操作分别发生在不同的端点。队列操作用于管理如打印任务等场景。
```java
// Java中队列的实现示例
Queue<Integer> queue = new LinkedList<>();
queue.offer(1);
queue.offer(2);
queue.poll();
```
## 2.2 树与图结构的算法应用
### 2.2.1 树的基本操作与遍历
树是一种分层的数据结构,由节点和连接它们的边组成。树的根节点没有入边,而叶子节点没有出边。
**二叉树**是一种特殊的树,其中每个节点最多有两个子节点。二叉树的遍历主要有三种方式:前序遍历、中序遍历和后序遍历。
```java
// 二叉树节点的定义
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) { val = x; }
}
// 前序遍历
void preorderTraversal(TreeNode node) {
if (node == null) return;
System.out.print(node.val); // 访问根节点
preorderTraversal(node.left); // 遍历左子树
preorderTraversal(node.right); // 遍历右子树
}
```
### 2.2.2 图的搜索与最短路径算法
图是由节点(顶点)和连接这些节点的边组成的复杂数据结构。图可以是有向的(边有方向)或无向的。
图的搜索算法中,**深度优先搜索(DFS)**是一种用于遍历或搜索树或图的算法。而**广度优先搜索(BFS)**则逐层进行,常用于在图中找到从起点到其他所有点的最短路径。
```java
// 图的节点和边的定义
class Graph {
int vertices;
LinkedList<Integer> [] adjList;
Graph(int vertices) {
this.vertices = vertices;
adjList = new LinkedList[vertices];
for (int i = 0; i < vertices; i++) {
adjList[i] = new LinkedList<>();
}
}
// 添加边
void addEdge(int src, int dest) {
adjList[src].add(dest);
}
}
// DFS算法实现
void DFS(Graph graph, int vertex, boolean[] visited) {
visited[vertex] = true;
System.out.print(vertex + " ");
for (Integer i : graph.adjList[vertex]) {
if (!visited[i]) {
DFS(graph, i, visited);
}
}
}
```
## 2.3 排序与搜索算法的实现
### 2.3.1 常见排序算法的原理与比较
排序算法用于将一组数据按照特定顺序进行排列。常见的排序算法包括冒泡排序、选择排序、插入排序、快速排序、归并排序和堆排序等。每种排序算法都有其适用的场景。
例如,**快速排序**是一种高效的排序算法,它使用分治法策略来把一个序列分为较小和较大的两个子序列,然后递归地排序两个子序列。
```java
// 快速排序的分区函数
int partition(int[] arr, int low, int high) {
int pivot = arr[high];
int i = (low - 1);
for (int j = low; j < high; j++) {
if (arr[j] <= pivot) {
i++;
swap(arr, i, j);
}
}
swap(arr, i + 1, high);
return (i + 1);
}
// 快速排序主函数
void quickSort(int[] arr, int low, int high) {
if (low < high) {
int pi = partition(arr, low, high);
quickSort(arr, low, pi - 1);
quickSort(arr, pi + 1, high);
}
}
```
### 2.3.2 二分搜索及其他搜索技术
二分搜索算法是一种在有序数组中查找特定元素的搜索算法。二分搜索每次将搜索区域减少一半,因此时间复杂度为 O(log n)。
```java
// 二分搜索实现
int binarySearch(int[] arr, int low, int high, int key) {
if (high >= low) {
int mid = low + (high - low) / 2;
if (arr[mid] == key) {
return mid;
}
if (arr[mid] > key) {
return binarySearch(arr, low, mid - 1, key);
} else {
return binarySearch(arr, mid + 1, high, key);
}
}
return -1;
}
```
除了二分搜索,还有其他高级搜索技术,例如**二叉搜索树(BST)搜索**、**跳表搜索**等,它们在不同类型的结构中寻找元素,各有其应用的场合和优势。这些算法的选择和应用取决于数据的组织形式和我们对搜索效率的需求。
通过本章节的介绍,我们已经对线性结构、树与图结构、排序与搜索算法有了一个全面的理解。下一章节中,我们将继续探索动态规划与贪心算法的深入解析。
# 3. 动态规划与贪心算法深入解析
在现代软件开发领域,算法问题的解决往往是优化性能的关键。动态规划(Dynamic Programming, DP)和贪心算法(Greedy Algorithm)是两种广泛用于求解优化问题的算法策略,尤其在需要进行决策和优化的场合中,这两种算法能够显著地提升效率和解决方案的性能。它们在面试中也是考官经常用以检验应聘者分析和解决复杂问题能力的工具。在本章中,我们将深入探讨这两种算法的工作原理,应用场景以及它们之间的对比和选择策略。
## 3.1 动态规划原理及应用场景
动态规划是一种将复杂问题分解为相对简单的子问题的策略,并且它利用了这些子问题之间的重叠特性,通过子问题的解来构建整个问题的解。理解动态规划的关键在于把握其状态转移方程,并且熟练地应用缓存机制来避免重复计算。
### 3.1.1 动态规划的基本思想
动态规划的基本思想是将待求解的问题分解为若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解。动态规划适用于具有最优子结构性质和重叠子问题特点的问题。
- **最优子结构**指的是一个问题的最优解包含了其子问题的最优解。
- **重叠子问题**意味着在递归求解过程中,同一个子问题会被多次计算。
动态规划的实现通常需要一个数组来存储已经计算过的子问题解,这个数组也被称为备忘录(Memoization)或者动态规划表。通过这种方式,动态规划避免了重复计算,从而极大地提升了算法效率。
### 3.1.2 实际问题中动态规划的应用案例
动态规划在许多实际问题中有着广泛的应用,如背包问题、最长公共子序列问题(LCS)、编辑距离问题等。
以背包问题为例,给定一组物品,每种物品都有自己的重量和价值,在限定的总重量内,我们应该如何选择装入背包的物品,使得背包中的总价值最大?背包问题是一个典型的组合优化问题。
动态规划解决背包问题的思路是,首先定义一个二维数组`dp[i][w]`表示在前`i`个物品中,对于容量为`w`的背包能够装下的最大价值。状态转移方程为:
```plaintext
dp[i][w] = max(dp[i-1][w], dp[i-1][w-weight[i]] + value[i]) if weight[i] <= w
dp[i][w] = dp[i-1][w] otherwise
```
其中,`weight[i]`和`value[i]`分别表示第`i`个物品的重量和价值。通过这个方程,我们可以从子问题的解推导出原问题的解。
## 3.2 贪心算法的策略与实践
贪心算法相对于动态规划而言,是一种更简单的优化策略。它在每一步选择中都采取在当前状态下最好或最优的选择,从而希望导致结果是最好或最优的算法。
### 3.2.1 贪心算法的基本概念
贪心算法的基本概念就是通过局部最优解的累积来达到全局最优解。在每个阶段,贪心算法都会做出一个看上去最优的选择,希望这个选择能导致最终结果的最优。
贪心算法并不保证总能获得最优解,但有些问题确实可以使用贪心算法求解。比如哈夫曼编码、最小生成树、最短路径等问题。
### 3.2.2 解决问题的贪心策略实例
以最小生成树问题为例,假设我们有一个加权连通图,我们希望找到一个子集的边,构成一棵包含所有顶点的树,并且使得树上边的权重之和最小。
使用普里姆算法(Prim's algorithm)或克鲁斯卡尔算法(Kruskal's algorithm)都可以得到最小生成树。普里姆算法从任意一个顶点开始,逐步增加边,而克鲁斯卡尔算法则从边的集合中选择权重最小的边。
以普里姆算法为例,算法的贪心策略是选择连接已选取顶点集合与未选取顶点集合的最小边,并且将该边加入到最小生成树中。
## 3.3 动态规划与贪心算法的对比分析
动态规划和贪心算法都属于优化算法,但它们在问题解决的策略和适用范围上存在差异。
### 3.3.1 两者的区别和适用范围
动态规划需要建立状态转移方程,并且解决子问题,同时保证全局最优。它适用于解决具有重叠子问题和最优子结构的问题,其特征是需要记录子问题的解,并通过这些记录来构建最终解。
贪心算法则是局部最优的,它没有像动态规划那样的子问题结构,也不需要记录子问题的解。贪心算法适用于那些子问题的选择不会影响到后续决策的问题。
### 3.3.2 如何在面试中选择算法技巧
在面试中,选择动态规划还是贪心算法作为解决方法,很大程度上取决于问题本身的特征。在面试前,应聘者应该熟悉这两种算法的适用情况,并且能够通过分析问题的特点,快速判断应该使用哪一种算法。
当问题具有明显的重叠子问题特征时,考虑使用动态规划;而当问题可以通过局部最优解来达到全局最优时,可以优先考虑贪心算法。此外,如果面试官没有特别指定算法要求,应聘者也可以在解题时先尝试贪心算法,因为它的实现通常更为简单直接。
在面试中,对于动态规划问题,能够清晰地写出状态转移方程,合理利用缓存机制,并解释算法的时间复杂度,将是一个很大的加分项。对于贪心算法问题,合理地解释贪心选择的性质以及局部最优解的正确性也是十分关键的。
# 4. 面试中的算法设计技巧与常见问题
## 4.1 算法设计的思维模式
### 4.1.1 问题分析与抽象建模
在面对复杂的算法问题时,第一步是将实际问题转化为数学模型,这一步骤被称为抽象建模。例如,在设计一个排序算法时,我们需要抽象出数组这一数据结构,然后根据算法的特性(时间复杂度、空间复杂度等)选择合适的排序方法。在面试中,这个过程需要快速而准确地完成,面试官通常会通过这个过程考察求职者的问题解决能力。
**代码逻辑分析:**
```python
def quicksort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quicksort(left) + middle + quicksort(right)
```
在这个快速排序的Python示例中,首先通过`if len(arr) <= 1`条件判断来终止递归,然后选择一个基准值(pivot),将数组分成小于基准值的左边部分(left)、等于基准值的中间部分(middle)和大于基准值的右边部分(right)。通过递归调用`quicksort`函数对左边和右边的数组进行排序,最后返回合并后的结果。
### 4.1.2 复杂问题的拆解与算法组合
在设计算法时,遇到复杂问题是很常见的。这时,将大问题拆解为小问题,分别用合适的小算法去解决,然后再将这些小算法组合起来形成一个完整的解决方案是常用的方法。例如,在设计一个最短路径算法时,我们可以先利用迪杰斯特拉算法找出从起点到其他所有点的最短路径,然后再利用贪心策略找出其中的最小值作为结果。
**代码逻辑分析:**
```python
import heapq
def dijkstra(graph, start):
distances = {vertex: float('infinity') for vertex in graph}
distances[start] = 0
priority_queue = [(0, start)]
while priority_queue:
current_distance, current_vertex = heapq.heappop(priority_queue)
for neighbor, weight in graph[current_vertex].items():
distance = current_distance + weight
if distance < distances[neighbor]:
distances[neighbor] = distance
heapq.heappush(priority_queue, (distance, neighbor))
return distances
```
上述代码实现了一个标准的迪杰斯特拉算法,用于计算图中所有点到起点的最短路径。首先,初始化一个包含所有顶点的距离字典`distances`,然后使用一个优先队列`priority_queue`来存储当前找到的最短路径候选。通过不断从队列中选取未访问的最小距离顶点,并更新其邻居顶点的距离来完成算法。
## 4.2 面试中可能遇到的算法问题
### 4.2.1 经典面试题的算法解决方案
面试官有时会给出一些经典算法问题,比如“八皇后问题”、“汉诺塔问题”或“背包问题”。针对这类问题,求职者需要掌握一种或多种解决方案,以及对这些解决方案的优化方法。
**代码逻辑分析:**
```python
def eight_queens(n):
def is_safe(board, row, col):
for i in range(col):
if board[row][i] == 1:
return False
for i, j in zip(range(row, -1, -1), range(col, -1, -1)):
if board[i][j] == 1:
return False
for i, j in zip(range(row, len(board), 1), range(col, -1, -1)):
if board[i][j] == 1:
return False
return True
def solve(board, col):
if col >= n:
return True
for i in range(n):
if is_safe(board, i, col):
board[i][col] = 1
if solve(board, col + 1):
return True
board[i][col] = 0
return False
board = [[0] * n for _ in range(n)]
if solve(board, 0) == False:
print("Solution does not exist")
return False
for row in board:
print(" ".join(["Q" if col == 1 else "." for col in row]))
return True
```
这个八皇后问题的Python解决方案使用了回溯法,通过递归搜索整个棋盘的列,检查当前行、左上到右下对角线、右上到左下对角线上的皇后位置是否冲突。如果找到冲突,则回溯到上一步重新尝试。当找到一个可行的放置方式时,就会输出棋盘的状态。
### 4.2.2 解题思路的快速转换技巧
在面试中快速转换解题思路是非常重要的。求职者需要展示出灵活转换解题策略的能力,这包括能从动态规划转到回溯法,或者从图论应用到递归和迭代等。例如,同样是解决图中的路径问题,如果给定的条件允许,可将问题从图的最短路径问题转换为贪心算法问题,以加快求解速度。
**代码逻辑分析:**
```python
def find_path(graph, start, end, path=[]):
path = path + [start]
if start == end:
return path
if start not in graph:
return None
for node in graph[start]:
if node not in path:
newpath = find_path(graph, node, end, path)
if newpath: return newpath
return None
```
这个递归函数用于找出图中两点之间的路径,通过递归遍历图的每一条边来查找路径。它展示了回溯法的基本原理,即在遇到死胡同时回退到上一个节点,尝试另一条路径直到找到解决方案或确认无解。
## 4.3 面试策略与心理准备
### 4.3.1 面试中的非技术性问题应对
面试不仅仅是技术能力的考察,还包括非技术性的部分,例如团队合作能力、沟通能力以及解决压力情境的能力。求职者需要准备一些例子来展示这些能力,如分享一个成功的团队项目经历,或描述如何处理过去的失败。
### 4.3.2 提升面试成功率的策略建议
为了提高面试成功率,求职者需要做好充分的准备。这包括对潜在问题的预测与模拟回答,了解公司的背景以及岗位要求,并准备一些针对性的问题来询问面试官。此外,良好的身体语言、自信的表达和清晰的思维逻辑也非常重要。
**小结:**
这一章节我们深入探讨了面试过程中算法设计的思维模式、可能遇到的算法问题以及面试策略和心理准备。面试不仅是技术能力的展现,更是心理素质、沟通能力和问题解决能力的全面考察。掌握了这些技巧,求职者在面试中就能更加从容不迫,展现出最佳状态。
# 5. 进阶算法的应用与持续学习
随着技术的不断进步,程序员面临的挑战也日益增多。进阶算法不仅是解决复杂问题的利器,也是个人能力提升的重要途径。本章节将探讨高级算法的理解与应用,如何在编程语言中实现算法的多样化选择,以及如何通过持续学习不断深化自己的算法知识。
## 高级算法的理解与应用
高级算法涉及到的领域非常广泛,其中包括但不限于字符串处理、数学问题的算法优化等。这些算法往往在面试中给面试官留下深刻的印象,并在实际工作中发挥重要作用。
### 字符串处理高级算法
字符串处理是编程中常见的任务,高级的字符串算法可以帮助程序员更高效地完成任务。比如,正则表达式是一种强大的字符串匹配工具,它能够用来进行复杂的文本处理。
```regex
# 一个简单的正则表达式示例
\d{3}-\d{2}-\d{4} # 匹配美式电话号码格式
```
另一个例子是 KMP (Knuth-Morris-Pratt) 算法,它用于在字符串中查找模式,但能够避免不必要的回溯,提高搜索效率。
### 数学问题与算法优化
解决数学问题时,算法可以发挥其优化作用。例如,在解决一个优化问题时,可以使用线性规划、整数规划等算法。在编程竞赛中,快速傅里叶变换(FFT)被用于多项式乘法和大整数乘法,极大地提高了运算速度。
```python
# 快速傅里叶变换示例代码(Python)
import numpy as np
def FFT(a):
N = len(a)
if N <= 1: return a
even = FFT(a[0::2])
odd = FFT(a[1::2])
T = [np.exp(-2j * np.pi * k / N) * odd[k] for k in range(N // 2)]
return [even[k] + T[k] for k in range(N // 2)] + [even[k] - T[k] for k in range(N // 2)]
a = [1, 2, 3, 4, 0, 0, 0, 0]
print(FFT(a))
```
## 编程语言在算法实现中的选择
不同的编程语言有其各自的特点,算法实现时要根据具体问题和环境来选择合适的语言。
### 各种编程语言的算法实现特点
- **Python**:它以其简洁的语法和丰富的库而著称。适用于快速原型开发和复杂的算法实现。例如,使用 NumPy 和 SciPy 库可以方便地实现复杂的数学计算。
- **C++**:性能要求高的场合经常使用 C++,尤其是在需要操作底层数据结构时。它提供更精细的内存管理,可以减少不必要的开销。
- **Java**:Java 在企业级应用中非常流行,它提供了良好的跨平台能力和成熟的生态系统。Java 的集合框架是处理数据结构和算法的强大工具。
### 选择编程语言的考量因素
选择编程语言来实现算法时,需要考虑以下因素:
1. 性能要求:对于需要高度优化的场景,可能需要选择编译型语言如 C++。
2. 开发效率:在需要快速开发的项目中,Python 或 JavaScript 可能是更好的选择。
3. 社区和资源:一个活跃的社区和丰富的库资源,可以让开发者更快地找到解决方案。
4. 硬件和平台限制:某些语言有特定的运行平台,比如 C# 主要运行在 .NET 环境。
## 终身学习与算法能力提升
在当今技术迭代飞速的环境下,终身学习是每个程序员应持续追求的目标。
### 持续学习的重要性和方法
持续学习能够保持个人技能的竞争力。推荐的学习方法包括:
- **在线课程和教程**:如 Coursera、edX 提供的计算机科学相关课程。
- **技术社区和论坛**:如 Stack Overflow、GitHub,可以及时获取新知识和解决问题。
- **参加编程挑战和竞赛**:如 LeetCode、Codeforces 等,可以提升算法和编程技巧。
### 构建个人算法知识体系
个人算法知识体系的构建是一个循序渐进的过程。首先,应当熟练掌握基本的数据结构和算法。其次,不断通过实际问题的解决来加深理解。最后,要注重算法的进阶学习和创新应用。
```mermaid
flowchart LR
A[基本数据结构和算法]
B[实际问题解决]
C[算法进阶学习和创新应用]
A --> B --> C
```
通过以上步骤,可以逐步构建起一套个人的算法知识体系,并在实际工作中不断丰富和完善。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《程序员面试算法指南》专栏是程序员面试算法的全面攻略,涵盖从入门到精通的各个方面。专栏文章深入解析算法复杂度、数组和字符串算法技巧、链表和树算法、图算法和动态规划、排序和搜索算法、数据结构、回溯算法和位运算技巧、算法时间空间复杂度、贪心算法、动态规划面试难题、经典算法案例分析、概率和数学基础、字符串匹配算法、系统设计面试攻略、复杂链表问题和数学逻辑推理等内容。专栏旨在帮助程序员掌握算法面试的核心策略和应用,提升算法思维,为面试做好充分准备。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Web设计实践】:从零开始构建花店网站布局
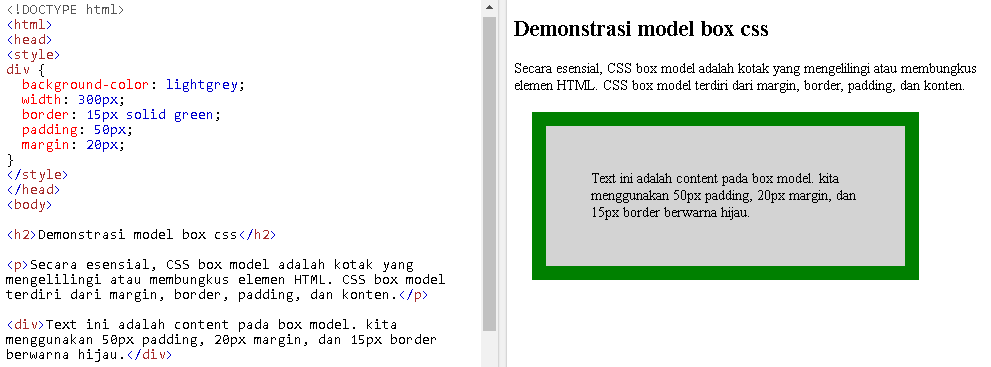
# 摘要
本文针对Web设计及开发的各个方面进行了系统性的阐述和实例演练,旨在指导开发者打造一个响应式、交互性强且视觉吸引人的花店网站。文章首先介绍了Web设计的基础知识和HTML5的关键特性,然后详细讨论了如何使用CSS3实现响应式设计、动画效果,以及如何通过JavaScript进行交互逻辑的构建。通过深入分析HTML结构、CSS样式和JavaScript脚本,本文展示了一个花店网站从界面设计到功能实现的完整开发流程。文章最后强调了网站实战开发中的用
【NHANES R 包编程技巧】:自定义函数与脚本优化的秘密武器

# 摘要
本文旨在为统计分析人员提供一个全面的NHANES R包使用指南,涵盖了从安装、基础知识回顾、数据分析、自定义函数编写到脚本优化的各个方面。首先,文章介绍了NHANES包的基本情况以及R语言的基础语法和数据处理方法。随后,重点放在了NHANES数据集的探索、描述性统计、可视化以及常用的数据探索技术上。接着,文章深入探讨了NHANES数据分析的实战应用,包括假
【水晶报表编程宝典】:自定义报表功能的深度解读
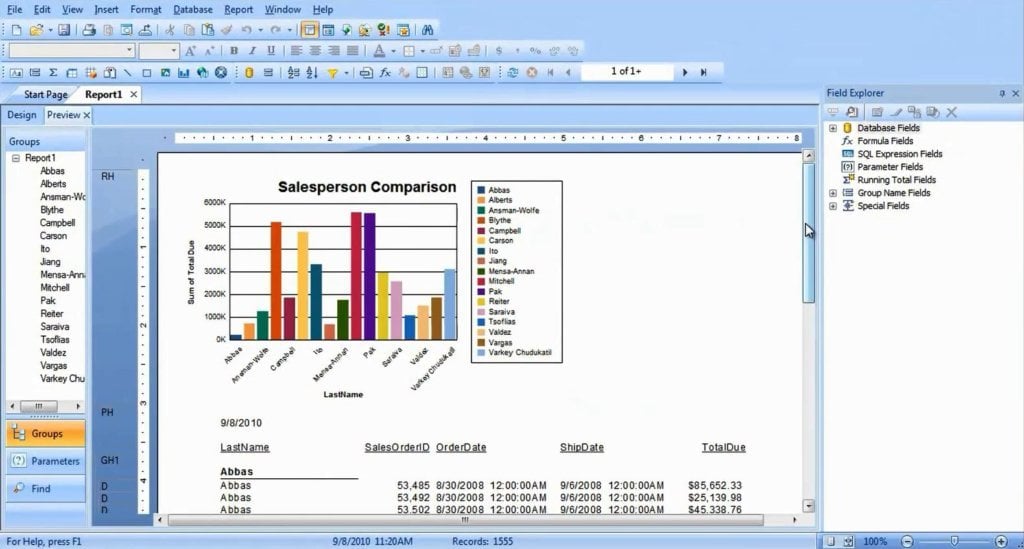
# 摘要
水晶报表作为一款功能强大的报表工具,广泛应用于企业数据展示和分析。本文首先介绍了水晶报表的基本概念和核心设计原理,随后深入探讨了其数据源管理、布局样式设计以及交互功能的开发。在编程技术章节,本文详细阐述了使用C#或VB.NET的编程接口、脚本控制结构以及动态数据处理的实现方式,进而讨论了高级报表功能如子报表管理和导出打印
【Synology File Station API监控与日志分析】:系统稳定运行的幕后英雄,有效监控与日志分析秘籍
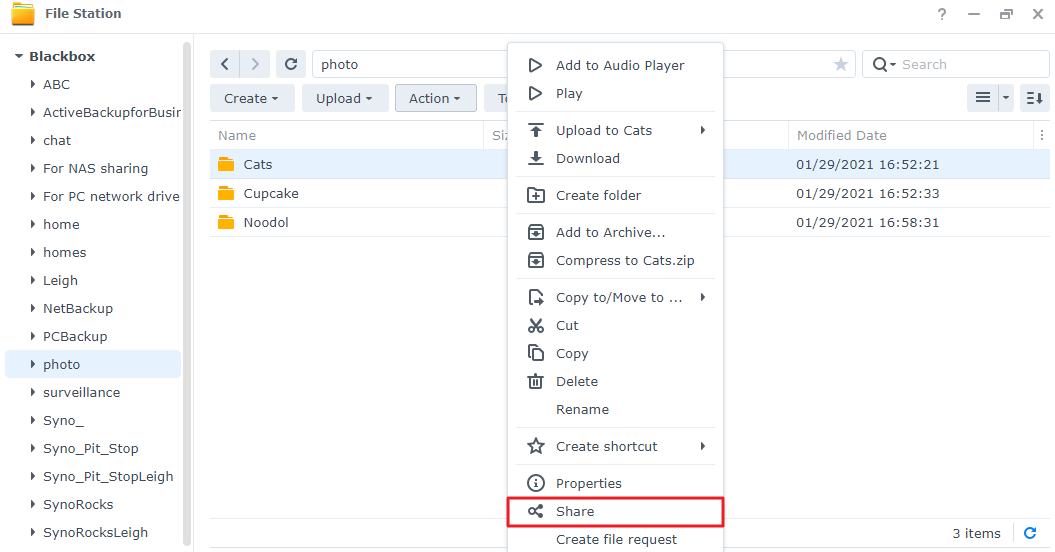
# 摘要
本文综合介绍了Synology File Station API在构建监控系统中的应用,以及日志分析的理论知识、工具选择和实际操作。首先概述了监控系统搭建的重要性和基于File Station API的监控组件架构。随后,探讨了监控系统实践应用中的数据收集、实时监控、告警机制和日
【单周期处理器流水线化】:理论与实现的完美结合

# 摘要
单周期处理器因其简单易实现而广泛应用于教学和基础系统中,然而它的性能存在局限性。本文首先介绍单周期处理器的基本概念和工作原理,随后探讨了单周期处理器向流水线化转型的理论基础,包括流水线技术原理、冲突解决策略、以及流水线化对性能的影响。文章进一步分析了流水线化在硬件实现和软件支持上的实践应用,以及性能评估方法。进阶应用部分着重于多级流水线、超流水线和超标量技术的设计与实现,并探讨了流水线的动态调度技术
【hwpt530.pdf实战操作手册】:如何将文档理论转化为项目成果(实战演练)
# 摘要
本文旨在提供hwpt530.pdf实战操作手册的全面概览,阐述理论基础,并指导项目规划与目标设定。通过对文档理论框架的解读,重点内容的详细剖析,以及从理论到实践目标的转化,本文帮助读者理解如何进行项目规划和管理。文章还详细介绍了实战演练的准备与实施步骤,以及如何进行问题诊断与成果评估。最后,本文强调了经验总结与知识转化的重要性,并探讨了将实践经验转化为组织知识的策略。通过这一系列的步骤,本文旨在帮助读者有效地掌握hwpt530.pdf的操作手册,并成功应用于实践项目中。
# 关键字
操作手册;理论框架;项目规划;实战演练;问题诊断;知识转化
参考资源链接:[华为PT530电力猫5
【ADS1256与STM32:终极数据采集系统指南】:专为初学者打造

# 摘要
本文旨在探讨数据采集系统的设计基础,重点分析STM32微控制器与ADS1256的集成使用,以及如何实现高精度的数据采集。文章首先介绍了ADS1256的特性及STM32微控制器的基础知识,包括硬件架构、软件开发环境和与ADS1256的接口通信。随后,文章深入探讨了ADS1256的初始化配置、数据采集方法及系统调试优化。在应用实践部分,文中展示了如何构建数据采集应用程序,并
揭秘IT策略:BOP2_BA20_022016_zh_zh-CHS.pdf深度剖析

# 摘要
本文对BOP2_BA20_022016进行了全面的概览和目标阐述,提出了研究的核心策略和实施路径。文章首先介绍了基础概念、理论框架和文档结构,随后深入分析了核心策略的思维框架,实施步骤,以及成功因素。通过案例研究,本文展示了策略在实际应用中的挑战、解决方案和经验教训,最后对策略的未来展望和持续改进方法进行了探讨。本文旨在
【VCS高效查询】:创建高效返回值查询的9个步骤与技巧

# 摘要
VCS(Version Control System)高效查询是版本控制系统优化性能和用户体验的关键技术。本文首先介绍了VCS高效查询的概念和其在软件开发过程中的重要性,随后深入探讨了VCS查询的理论基础,包括其基本原理、性能影响因素以及不同查询类型的选择方法。接着,本文详细阐述了实现VCS高效查询的设计、技术方法及调试优化实践,同时提供了实
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )