【R语言速成课程】:掌握数据包运用与基础图形绘制的7个技巧
发布时间: 2024-11-10 05:56:45 阅读量: 16 订阅数: 34 

# 1. R语言简介及环境搭建
R语言是一种用于统计分析、图形表示和报告的编程语言和软件环境。它在数据分析、机器学习和生物信息学领域享有盛誉。本章节将从基础入手,逐步指导读者完成R语言的环境搭建和初步探索。
## 1.1 R语言起源和特点
R语言最早由Ross Ihaka和Robert Gentleman在1990年代初期开发,其灵感来源于S语言。R的特点包括:
- **开源软件**:自由使用并进行改进。
- **社区支持**:全球有庞大的用户社区和丰富的资源库。
- **多种统计和图形技术**:提供广泛的统计模型和高质量的图形绘制工具。
## 1.2 R语言环境搭建
为了开始使用R语言,您需要搭建一个开发环境。以下是搭建R语言环境的基本步骤:
1. **下载R语言**:访问R语言官方网站 [CRAN](*** 下载适用于您操作系统的R语言版本。
2. **安装R语言**:运行下载的安装程序,并按照提示完成安装过程。
3. **安装RStudio**(可选但推荐):RStudio是一个流行的R语言集成开发环境(IDE),提供了许多便捷功能来增强R语言的开发体验。访问[RStudio官网](*** 下载并安装RStudio IDE。
完成上述步骤后,您就可以打开R或RStudio开始您的R语言之旅了。在接下来的章节中,我们将深入探讨R语言的基础知识,帮助您构建坚实的数据分析基础。
# 2. R语言基础知识
## 2.1 R语言的语法结构
### 2.1.1 数据类型和结构
R语言提供了多种数据类型,基本类型包括数值型(numeric)、整数型(integer)、复数型(complex)、字符型(character)和逻辑型(logical)。在R中,数据结构是组织数据的关键方式,常见的有向量、矩阵、数组、列表和数据框(DataFrame)。
- 向量是R中最基本的数据结构,可以存储数值、字符或其他数据类型的元素,但所有元素的数据类型必须一致。
- 矩阵(matrix)是二维的数值型数据结构,所有元素的数据类型必须相同。
- 数组(array)是多维的数据结构,可视为矩阵的推广。
- 列表(list)是R语言中唯一可以包含不同数据类型的数据结构。
- 数据框(DataFrame)是R中最常用来存储数据的结构,其可以看作是不同长度向量的集合,这些向量通常对应于不同的属性,类似数据库中的表格。
在进行数据分析时,不同数据类型和结构的选用会直接影响分析的效率和结果。例如,在进行统计分析时,数据框结构是处理表格化数据的最佳选择。
### 2.1.2 基本的运算符和函数
R语言提供了丰富的内置函数和运算符,运算符包括算术运算符、关系运算符、逻辑运算符等。基本的算术运算符有加(+)、减(-)、乘(*)、除(/)、整除(%/%)、余数(%%)等。关系运算符有等于(==)、不等于(!=)、小于(<)、大于(>)、小于等于(<=)、大于等于(>=)。逻辑运算符则有逻辑与(&&、&)、逻辑或(||、|)、逻辑非(!)。
除了这些基本的运算符之外,R语言提供大量的内建函数,例如sum()、mean()、median()、var()、cor()等用于执行统计计算,以及length()、nrow()、ncol()等用于获取数据对象的属性。利用这些函数,可以高效地对数据进行处理和分析。
```r
# 简单的算术运算示例
result <- 3 + 5 * 2 # 结果为13
print(result)
# 使用逻辑运算符
logical_result <- (5 > 3) && (3 < 5) # 结果为TRUE
print(logical_result)
```
在上述代码中,我们进行了简单的算术运算并使用了逻辑运算符进行逻辑判断。这些基本的运算符和函数是R语言进行数据分析的基础。
## 2.2 R语言数据管理
### 2.2.1 向量和矩阵操作
在R语言中,向量和矩阵是处理数值数据的关键结构。向量可以通过c()函数创建,而矩阵则可以通过matrix()函数创建,并且可以通过指定行列数来构造。
```r
# 创建向量
vector_example <- c(1, 2, 3, 4, 5)
print(vector_example)
# 创建矩阵
matrix_example <- matrix(1:9, nrow = 3, ncol = 3)
print(matrix_example)
```
在上面的代码块中,我们创建了一个简单的数值向量和一个3x3的矩阵。矩阵操作通常包括转置(t())、矩阵加法(+)、矩阵乘法(%*%)等。向量和矩阵的操作是进行数值计算不可或缺的一部分。
### 2.2.2 数据框(DataFrame)的操作
数据框(DataFrame)是R语言中用于存储表格数据的核心数据结构,可以包含多个不同类型的列。创建数据框可以使用data.frame()函数。
```r
# 创建数据框
data_frame_example <- data.frame(
Name = c("Alice", "Bob", "Charlie"),
Age = c(25, 30, 35),
Salary = c(50000, 55000, 60000)
)
print(data_frame_example)
```
数据框的操作包括添加列、删除列、过滤行、合并数据框等。例如,我们可以通过$符号来访问特定的列:
```r
# 访问数据框中的列
age_column <- data_frame_example$Age
print(age_column)
```
### 2.2.3 因子(Factors)和列表(List)的使用
因子(Factors)在R中用于表示分类数据。因子可以具有特定的水平(levels),是处理分类变量的重要结构。列表(List)是R中最灵活的数据结构,可以包含不同类型的元素。
```r
# 创建因子
factor_example <- factor(c("Male", "Female", "Male"))
print(factor_example)
# 创建列表
list_example <- list(
vector = vector_example,
matrix = matrix_example,
data_frame = data_frame_example
)
print(list_example)
```
在上述代码中,我们创建了一个因子和一个列表。因子对于统计建模特别重要,因为模型通常需要知道变量的类别。而列表则用于存储不同类型的数据结构,是向量和数据框等的延伸。
## 2.3 R语言控制流程
### 2.3.1 条件语句
在R语言中,条件语句通过if、else和switch函数实现。if语句用来进行条件判断,而else可以用来处理条件不满足时的情况。
```r
# 条件语句示例
x <- 10
if (x > 0) {
print("x is positive")
} else {
print("x is non-positive")
}
```
在上述代码中,我们判断了变量x是否大于0,并输出相应的结果。if语句是数据分析和编程中不可或缺的控制结构。
### 2.3.2 循环结构
R语言支持多种循环结构,包括for循环和while循环。for循环可以遍历向量或列表中的每一个元素,while循环则会根据条件反复执行代码块直到条件不再满足。
```r
# for循环示例
for (i in 1:5) {
print(i^2)
}
# while循环示例
counter <- 1
while (counter <= 5) {
print(counter^2)
counter <- counter + 1
}
```
在以上代码块中,我们分别展示了for循环和while循环的使用。循环结构是自动化重复任务和处理数据序列的关键。
### 2.3.3 函数的定义和应用
函数是R语言中将代码模块化的基础。用户可以定义自己的函数,以便重用代码和简化任务。
```r
# 定义函数示例
add_numbers <- function(a, b) {
result <- a + b
return(result)
}
# 使用函数
sum_result <- add_numbers(3, 4)
print(sum_result)
```
在上述代码中,我们定义了一个名为add_numbers的函数,它可以将两个数值相加并返回结果。通过定义函数,我们能够创建可重用的代码块,这对于复杂数据分析任务至关重要。
# 3. 数据包的运用与管理
在本章节中,我们将深入了解R语言中数据包的运用与管理,这是R语言使用者必须掌握的技能之一。数据包是R语言中扩展功能和共享分析方法的重要方式,包含了许多特定领域的函数和数据集,为数据分析提供了丰富的资源。本章节将从数据包的安装和加载开始,逐步介绍如何探索和使用数据包,以及分享一些高级操作技巧,如创建和分享自定义数据包,以及进行版本控制和更新。
## 3.1 数据包的安装和加载
### 3.1.1 从CRAN安装数据包
在R语言中,从CRAN(The Comprehensive R Archive Network)安装数据包是最直接和常见的方法。CRAN是一个托管R语言包的网络平台,提供了大量的数据包供用户下载安装。安装数据包的基本命令是:
```r
install.packages("package_name")
```
在上述命令中,“package_name”是用户希望安装的数据包名称,需要被双引号包围。例如,如果用户想要安装一个名为“dplyr”的数据处理包,可以使用如下命令:
```r
install.packages("dplyr")
```
此命令会自动下载最新的“dplyr”包,并安装到R的库目录中。
为了更加方便的管理安装多个包,可以使用向量化操作:
```r
packages <- c("ggplot2", "dplyr", "tidyr")
install.packages(packages)
```
### 3.1.2 管理已安装的数据包
安装数据包后,如何管理和维护这些包是接下来需要掌握的技能。R提供了一些内置函数,比如 `library()` 或 `require()` 来加载数据包,`installed.packages()` 来查看已安装的包列表,以及 `remove.packages()` 来移除不再需要的包。
加载数据包以便其功能可用于当前会话:
```r
library(dplyr)
```
或
```r
require(dplyr)
```
上述两种方式都可以加载“dplyr”包,但`library()` 通常被用来加载包,而 `require()` 更多用于函数依赖的检查。
查看已安装的包列表:
```r
installed_packages <- installed.packages()
```
移除不再需要的包:
```r
remove.packages("package_name")
```
移除包时,R会询问是否删除包含包的目录,通常选择“是”。
## 3.2 数据包的探索和使用
### 3.2.1 查看数据包文档
了解如何查看和阅读数据包的文档是使用数据包的第一步。每个R数据包都包含了一系列的文档,这些文档通常以 vignettes 或 help pages 的形式存在。使用 `help()` 函数或 `?` 操作符可以查看包内特定函数的帮助文档。例如:
```r
help(package = "dplyr")
```
或者
```r
?select
```
上述命令将会显示关于“dplyr”包的总览文档,或“select”函数的详细文档。
### 3.2.2 数据包中的函数和数据集
除了函数外,R数据包中常常会包含一些示例数据集,这些数据集可以用于演示包内函数的使用方法,或者用于学习和教学。要查看一个包中所有可用的示例数据集,可以使用 `data()` 函数,不带参数时会列出所有可用的数据集名称:
```r
data(package = "ggplot2")
```
加载特定的数据集:
```r
data(mtcars, package = "ggplot2")
```
加载后,数据集 `mtcars` 将出现在R的工作空间中,用户可以对其进行操作和分析。
## 3.3 高级数据包操作技巧
### 3.3.1 创建和分享自定义数据包
创建自己的数据包是分享分析方法和代码的绝佳方式。创建数据包的过程涉及编写一个规范的包结构,包括 `DESCRIPTION` 文件、`NAMESPACE` 文件和R脚本。一个简易的数据包结构通常可以使用 `devtools` 包中的 `create()` 函数生成:
```r
devtools::create("my_package")
```
上述命令会创建一个名为 `my_package` 的新数据包目录,包含基本的目录结构和文件。
一旦数据包创建好,就可以添加自己的函数和数据集。使用 `setwd()` 命令可以设置工作目录为包目录,进行编辑和修改。
完成包的编写后,可以使用 `devtools` 包的 `build()` 函数来构建包:
```r
devtools::build()
```
构建完成后,包就可以通过 `install()` 函数安装:
```r
devtools::install()
```
自定义数据包可以被分享到GitHub或CRAN,这为开源合作提供了便利。
### 3.3.2 数据包的版本控制和更新
随着项目的推进,数据包也需要定期更新和维护。使用版本控制工具如Git进行版本控制可以让这一过程变得更加高效。每个版本的更新都可以被记录,并可随时回滚。R包的更新通常包括文档的更新、依赖关系的检查和测试。
使用 `devtools` 包可以方便地管理包的版本。例如,添加版本号:
```r
usethis::use_version("major")
```
上述命令将更新 `DESCRIPTION` 文件中的版本号。此外,检查依赖关系是否发生变化,确保数据包的兼容性:
```r
devtools::check_win_devel()
```
若包是通过GitHub发布,可以利用 `devtools` 来发布新版本:
```r
devtools::release()
```
如果更新是因为某些依赖的包更新导致的,可以使用 `devtools` 的 `update_packages()` 函数来同步更新。
## 表格
为了展示安装与管理数据包的最佳实践,下面是一个总结性的表格:
| 数据包操作 | 描述 | 示例命令 |
| --- | --- | --- |
| 安装数据包 | 从CRAN下载并安装数据包 | `install.packages("dplyr")` |
| 加载数据包 | 在当前R会话中激活数据包 | `library(dplyr)` |
| 查看数据包 | 列出包内可用函数和数据集 | `help(package = "ggplot2")` |
| 加载数据集 | 导入包中的数据集 | `data(mtcars, package = "ggplot2")` |
| 创建数据包 | 使用devtools创建数据包结构 | `devtools::create("my_package")` |
| 版本控制 | 管理数据包的版本更新 | `usethis::use_version("major")` |
| 发布数据包 | 将数据包发布到GitHub或CRAN | `devtools::release()` |
## 代码块和逻辑分析
在使用 `devtools` 的 `release()` 函数进行数据包发布时,需要遵循一定的逻辑和步骤。首先,确保所有的文档和函数都已经被适当地编写和更新。其次,使用 `check()` 函数检查包的兼容性和问题:
```r
devtools::check()
```
如果检查没有问题,然后可以使用 `build()` 函数构建包:
```r
devtools::build()
```
构建完成后,包就可以提交到CRAN。如果提交被拒绝,需要根据CRAN的反馈进行修改并重复上述过程。
## 本小节总结
通过本小节的介绍,您应该已经学会了如何在R语言环境中安装、加载、探索以及创建和管理数据包。掌握了这些技能,您就可以更加高效地利用R语言进行数据分析和研究工作。而版本控制和更新的技巧可以帮助您维护和升级您的自定义数据包,确保其质量和功能性。在下一小节,我们将深入探索如何使用R语言中的基础图形绘制功能,这是数据可视化的第一步。
# 4. R语言基础图形绘制
## 4.1 基础图形系统介绍
### 4.1.1 基本图形函数
R语言提供了多种基础图形函数,这些函数可以用来绘制简单的图形,例如点图、线图、条形图等。这些函数包括但不限于`plot()`, `hist()`, `barplot()`, 和 `boxplot()`等。通过这些基本函数,用户可以快速地生成图形,并进行初步的数据可视化。
一个简单的例子是使用`plot()`函数绘制一个散点图:
```r
# 创建一个简单的散点图
x <- 1:10
y <- rnorm(10)
plot(x, y)
```
上述代码中,`x`和`y`是两组数据,分别代表了横轴和纵轴的值。`plot()`函数将这两组数据转换为一个基本的散点图。
### 4.1.2 高级图形参数设置
在基础图形系统中,通过设置图形参数可以对图形进行定制。这些参数可以帮助用户调整图形的颜色、字体、标题、坐标轴标签等。例如,使用`col`参数来改变点的颜色:
```r
plot(x, y, col = "blue")
```
这里我们将散点图中的点颜色设置为蓝色。同样,使用`main`参数可以为图形添加标题:
```r
plot(x, y, main = "Scatterplot of X vs Y")
```
以上只是基础图形系统参数设置的冰山一角。R语言中有着丰富的参数可以调整,用户可以根据自己的需求进行修改和优化。
## 4.2 常见图形类型绘制
### 4.2.1 条形图和直方图
条形图是数据可视化中经常使用的图形类型之一,用于显示类别数据的频数。在R中可以使用`barplot()`函数来绘制条形图。
```r
# 创建一个条形图
categories <- c("A", "B", "C", "D")
frequencies <- c(12, 4, 5, 9)
barplot(frequencies, names.arg = categories)
```
上述代码中,`categories`列表示各个类别的名称,`frequencies`是对应的频数值。`barplot()`函数根据这些数据生成条形图。
直方图则是用于展示数值型数据分布的图形,可以使用`hist()`函数来绘制:
```r
# 创建一个直方图
data <- rnorm(100)
hist(data)
```
这里我们生成了一组正态分布的随机数,并用`hist()`函数绘制了其直方图。
### 4.2.2 线图和散点图
线图适用于显示连续数据随时间或其他连续变量变化的趋势,`plot()`函数配合`type = "l"`参数可以绘制线图。
```r
# 创建一个线图
plot(x, y, type = "l")
```
与线图类似,散点图是用来展示两个变量之间关系的图形。前面已经通过`plot()`函数生成了散点图的示例。
### 4.2.3 盒须图和饼图
盒须图是一种用来展示数据集中分布情况的图形,通过`boxplot()`函数可以绘制。
```r
# 创建一个盒须图
boxplot(data)
```
饼图则可以使用`pie()`函数来绘制,它通过图形的方式展示了数据各部分的比例关系。
```r
# 创建一个饼图
slices <- c(10, 12, 4, 16, 8)
names(slices) <- c("Blue", "Green", "Red", "Yellow", "Purple")
pie(slices)
```
在这里,我们创建了一个包含五个部分的饼图,每个部分代表一个颜色类别,并显示了它们的占比。
## 4.3 图形的定制和美化
### 4.3.1 图形元素的添加和修改
为了使图形更加美观和信息量更加丰富,用户可以添加图形元素,比如图例、文本标签、网格线等。以下是如何在图形中添加图例的示例:
```r
plot(x, y, type = "p", pch = 19)
legend("topright", legend = "Data Points", pch = 19, col = "blue")
```
这里,`legend()`函数在图形的右上角添加了一个图例,指出了数据点的含义,并设置了图例的样式。
### 4.3.2 多个图形的组合与排列
当需要在同一个画布上展示多个图形时,可以使用`par(mfrow)`函数或者`layout()`函数来排列它们。
```r
par(mfrow = c(1, 2))
plot(x, y, main = "Plot 1")
plot(categories, frequencies, main = "Plot 2")
```
以上代码将创建一个1行2列的图形布局,左侧是散点图,右侧是条形图。
通过这些基础图形绘制方法的学习,我们可以对数据进行初步的可视化。然而,在下一章节中,我们将探讨如何利用R语言中的高级可视化包如`ggplot2`来进一步提高我们的数据可视化技能。
# 5. R语言中的数据可视化进阶技巧
## 5.1 ggplot2图形库简介
### 5.1.1 ggplot2的基本概念
ggplot2是一个广泛使用的R包,专门用于数据可视化。它由Hadley Wickham开发,并基于“图形语法”的理念。ggplot2的设计哲学是将图形分解为多个组成部分,即图层,每个图层都是独立的,并可以独立控制。这种分解允许用户通过简单地添加或修改图层来创建复杂、定制化的图形。
要开始使用ggplot2,您首先需要安装并加载该包:
```R
install.packages("ggplot2")
library(ggplot2)
```
基本的ggplot2图形创建语法遵循以下结构:
```R
ggplot(data = <DATA>) +
<GEOM_FUNCTION>(mapping = aes(<MAPPINGS>), <OTHER OPTIONS>)
```
这里`<DATA>`指的是您的数据集,`<GEOM_FUNCTION>`指图形类型(如点图、条形图等),而`aes()`函数内是关于映射的美学属性。
### 5.1.2 ggplot2的图层系统
ggplot2的图层系统允许用户按顺序叠加多个图形元素,从而构建复杂且富有表现力的图形。最核心的图层类型包括数据层、几何对象层、统计变换层、坐标系层和分面层。
- **数据层**:所有ggplot2图形的起点,指定数据来源。
- **几何对象层**:定义数据如何在图形中表示,例如点、线、形状等。
- **统计变换层**:ggplot2提供了一系列统计变换,如计数、平均值、回归线等。
- **坐标系层**:定义图形的坐标系统,如笛卡尔坐标系、极坐标系等。
- **分面层**:分面允许将数据分割成子集,并在多个图形中展示。
下面是一个添加几何对象层的示例代码:
```R
ggplot(data = iris) +
geom_point(mapping = aes(x = Sepal.Length, y = Sepal.Width))
```
此代码创建了一个散点图,显示了iris数据集中萼片长度与宽度的关系。`geom_point()`函数添加了一个点图的几何层,`aes()`函数用于设置x轴和y轴。
## 5.2 ggplot2高级图形定制
### 5.2.1 自定义图例和坐标轴
ggplot2提供了高级定制选项来改善图形的可读性和美观性。自定义图例和坐标轴是数据可视化中重要的环节。
图例通常根据数据的映射自动生成,但可以通过修改`scale_`系列函数来自定义。例如,如果您想要改变图例的名称,可以使用`scale_xxx_discrete`或`scale_xxx_continuous`函数(取决于您映射的变量类型):
```R
ggplot(data = iris) +
geom_point(mapping = aes(x = Sepal.Length, y = Sepal.Width, color = Species)) +
scale_color_discrete(name = "Species", labels = c("Setosa", "Versicolor", "Virginica"))
```
在上面的例子中,我们通过`scale_color_discrete`函数自定义了颜色图例的名称和标签。
自定义坐标轴同样重要,尤其是在调整轴刻度或标题时。`scale_xxx_continuous`和`scale_xxx_discrete`函数允许您控制轴的格式:
```R
ggplot(data = iris) +
geom_bar(mapping = aes(x = Species)) +
scale_x_discrete(name = "Species", labels = c("Setosa", "Versicolor", "Virginica"))
```
这里`scale_x_discrete`函数被用来修改x轴的名称和标签。
### 5.2.2 主题和样式的定制
ggplot2提供了一系列内置主题,如`theme_bw()`, `theme_minimal()`, `theme_classic()`等,您可以通过这些主题快速改变图形的整体外观。
例如,若要使用暗色主题,可以这样做:
```R
ggplot(data = iris) +
geom_point(mapping = aes(x = Sepal.Length, y = Sepal.Width)) +
theme_bw()
```
如果您需要进行更细致的定制,ggplot2还允许您自定义几乎所有的图形元素,包括字体大小、颜色、边距等,通过`theme()`函数实现。例如:
```R
ggplot(data = iris) +
geom_point(mapping = aes(x = Sepal.Length, y = Sepal.Width)) +
theme(
plot.title = element_text(size = 20, face = "bold"),
axis.title = element_text(size = 14),
legend.title = element_text(size = 12)
)
```
这里,`theme()`函数用于调整标题、轴标题和图例标题的样式。
### 5.2.3 图形的保存和导出
创建完精美的图形后,您可能需要将它们保存下来或导出为不同的格式,如PNG、JPEG、PDF或SVG等。ggplot2中的`ggsave()`函数可以轻松完成这一任务:
```R
my_plot <- ggplot(data = iris) +
geom_point(mapping = aes(x = Sepal.Length, y = Sepal.Width))
ggsave("my_plot.png", plot = my_plot, width = 10, height = 8, dpi = 300)
```
在上面的代码中,`ggsave()`函数保存了之前创建的图形`my_plot`为PNG格式。您可以指定保存的文件名、图形尺寸、分辨率(dpi)等参数。
## 5.3 其他可视化包的探索
### 5.3.1 lattice包的多变量数据可视化
虽然ggplot2在R中非常流行,但lattice包也是一个强大的数据可视化工具,特别是在多变量数据可视化方面。lattice使用trellis图形,可以同时展示数据的多个视图,非常适合多变量分析。
以下是一个简单的lattice散点图示例:
```R
library(lattice)
xyplot(Sepal.Length ~ Sepal.Width | Species, data = iris)
```
在这个例子中,`xyplot()`函数被用来创建按品种分组的散点图。这展示了lattice包如何轻松地在单一图形中展示分类变量。
### 5.3.2 plotly包的交互式图形
plotly是R中另一个强大的可视化工具,尤其适合创建交互式图形。plotly包中的图形允许用户通过鼠标交互来探索数据,如缩放、悬停提示以及在不同视图间切换。
安装并加载plotly包:
```R
install.packages("plotly")
library(plotly)
```
创建一个交互式散点图:
```R
p <- ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) +
geom_point()
ggplotly(p)
```
在这个例子中,`ggplotly()`函数将ggplot2创建的散点图转换为一个交互式图形。用户可以通过点击图例中的任何物种来过滤数据点,或使用工具栏调整视图。
### 小结
本章节介绍了R语言中数据可视化进阶技巧,重点介绍了ggplot2的高级定制方法、lattice包的多变量数据可视化以及plotly包的交互式图形创建。这些技能对于提升数据的展示能力和用户交互体验都至关重要。通过实践这些技巧,您可以创建更加专业和吸引人的数据视觉作品。
# 6. R语言在数据分析中的应用案例
## 6.1 数据清洗和预处理
### 6.1.1 缺失值处理
在数据分析中,面对不完整的数据集是常见的问题。R语言提供了多种方法来处理缺失值(NA)。
首先,我们可以用`is.na()`函数来识别数据集中的缺失值。然后根据需要采取相应策略,例如删除含有缺失值的记录、填充缺失值,或者用统计方法如均值、中位数等进行替代。
```r
# 创建一个包含缺失值的数据框
df <- data.frame(
x = c(1, 2, NA, 4, 5),
y = c("A", "B", "C", "D", NA)
)
# 查找缺失值
na_rows <- apply(df, 1, function(x) any(is.na(x)))
# 删除含有缺失值的行
df_clean <- df[!na_rows, ]
# 或者填充缺失值
df_filled <- df
df_filled[is.na(df_filled)] <- 0
```
### 6.1.2 异常值检测和处理
异常值可以严重影响数据分析的结果,因此检测和处理异常值是数据预处理的重要环节。
异常值的检测可以基于统计方法,比如使用标准差检测离群点,或者使用箱线图方法。处理异常值的方法包括修改异常值、删除异常值或者使用聚类等方法将异常值归类。
```r
# 使用箱线图方法检测异常值
boxplot.stats(df$x)$out
# 删除异常值
df_no_outliers <- df[abs(scale(df$x)) < 2, ]
```
## 6.2 数据分析实战技巧
### 6.2.1 描述性统计分析
描述性统计分析是数据分析的起点,它包括对数据集的中心趋势(如均值、中位数、众数)、离散程度(如方差、标准差、四分位数)以及分布形态(如偏度、峰度)的计算。
R语言中的`summary()`函数可以为数据集提供描述性统计概览,而`describe()`函数则可以在`psych`包中找到。
```r
# 使用summary()函数获取描述性统计概览
summary(df$x)
# 加载psych包并使用describe()函数
library(psych)
describe(df)
```
### 6.2.2 探索性数据分析(EDA)
探索性数据分析(EDA)是在对数据有初步理解后,进一步通过图形化和统计手段来揭示数据中的模式、异常点、相关性和结构的过程。
R语言中`ggplot2`包提供强大的图形系统,可以通过绘制散点图、箱线图、直方图等图形进行数据探索。
```r
# 使用ggplot2绘制数据的直方图
library(ggplot2)
ggplot(df, aes(x = x)) + geom_histogram(binwidth = 1)
# 使用箱线图查看y变量的分布
ggplot(df, aes(x = y, y = x)) + geom_boxplot()
```
## 6.3 数据报告和演示
### 6.3.1 制作动态报告
R Markdown是一个非常有用的工具,它允许你创建包含文本、代码和结果的动态文档。通过R Markdown,你可以生成包含实时数据分析和可视化的报告。
```r
# 创建一个R Markdown文档,选择HTML输出格式
title: "数据分析报告"
output: html_document
## 数据概览
这是一个数据分析报告的简单示例。这里是描述性统计结果:
```{r summary}
summary(df)
```
### 6.3.2 制作交互式数据仪表板
`shiny`包允许你创建交互式Web应用程序,可以用于制作动态数据仪表板,仪表板允许用户通过图形化界面探索数据。
```r
# 一个简单的shiny应用示例
library(shiny)
ui <- fluidPage(
titlePanel("交互式数据仪表板"),
sidebarLayout(
sidebarPanel(
selectInput("xvar", "选择X轴变量:", choices = names(df)),
selectInput("yvar", "选择Y轴变量:", choices = names(df), selected = names(df)[2])
),
mainPanel(
plotOutput("plot")
)
)
)
server <- function(input, output) {
output$plot <- renderPlot({
plot(df[[input$xvar]], df[[input$yvar]])
})
}
shinyApp(ui, server)
```
以上就是R语言在数据分析中应用案例的详细介绍。这些方法和技巧对于5年以上的IT从业者来说,既能巩固基础知识,也能探索更高级的应用场景。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面介绍 R 语言中 scatterplot3d 数据包,提供从入门到精通的详细教程。通过一系列深入的文章,您将掌握数据包的运用技巧、基础图形绘制、三维数据展示、图表美学提升、交互式图表制作、高级绘图技术、个性化绘图、三维数据探索、统计图表构建、图表输出与分享、数据分析、动态交互设计、性能优化、3D 图形定制、图形模板创建、参数设置、案例研究、图形美学提升以及多变量分析等方面的知识。无论您是 R 语言新手还是经验丰富的用户,本专栏都将帮助您提升数据可视化技能,从基础图表到高级三维散点图,全面掌握 R 语言的绘图能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【EmuELEC全面入门与精通】:打造个人模拟器环境(7大步骤)

# 摘要
EmuELEC是一款专为游戏模拟器打造的嵌入式Linux娱乐系统,旨在提供一种简便、快速的途径来设置和运行经典游戏机模拟器。本文首先介绍了EmuELEC的基本概念、硬件准备、固件获取和初步设置。接着,深入探讨了如何定制EmuELEC系统界面,安装和配置模拟器核心,以及扩展其功能。文章还详细阐述了游戏和媒体内容的管理方法,包括游戏的导入、媒体内容的集成和网络功能的
【TCAD仿真流程全攻略】:掌握Silvaco,构建首个高效模型
# 摘要
本文首先介绍了TCAD仿真和Silvaco软件的基础知识,然后详细讲述了如何搭建和配置Silvaco仿真环境,包括软件安装、环境变量设置、工作界面和仿真
【数据分析必备技巧】:0基础学会因子分析,掌握数据背后的秘密
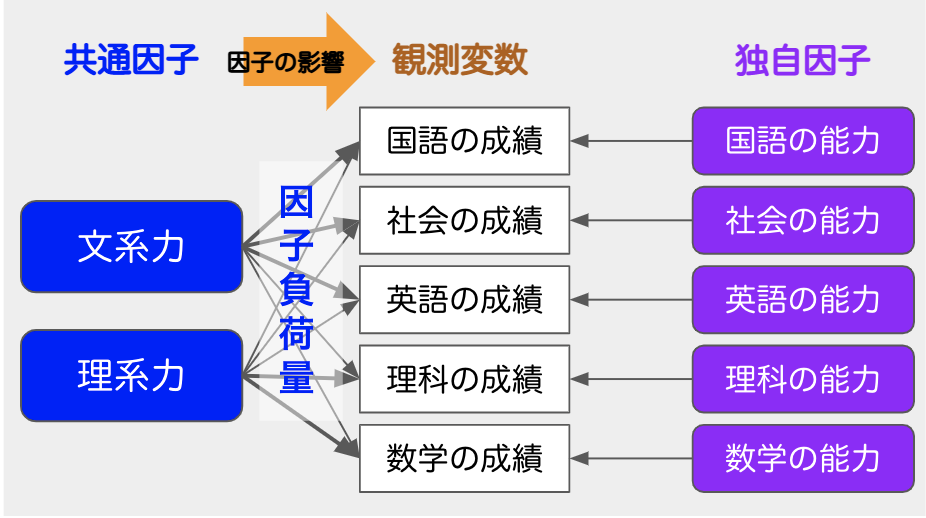
# 摘要
因子分析是一种强有力的统计方法,被广泛用于理解和简化数据结构。本文首先概述了因子分析的基本概念和统计学基础,包括描述性统计、因子分析理论模型及适用场景。随后,文章详细介绍了因子分析的实际操作步骤,如数据的准备、预处理和应用软件操作流程,以及结果的解读与报告撰写。通过市场调研、社会科学统计和金融数据分析的案例实战,本文展现了因子分析在不同领域的应用价值。最后,文章探讨了因子分析
【树莓派声音分析宝典】:从零开始用MEMS麦克风进行音频信号处理

# 摘要
本文详细介绍了基于树莓派的MEMS麦克风音频信号获取、分析及处理技术。首先概述了MEMS麦克风的基础知识和树莓派的音频接口配置,进而深入探讨了模拟信号数字化处理的原理和方法。随后,文章通过理论与实践相结合的方式,分析了声音信号的属性、常用处理算法以及实际应用案例。第四章着重于音频信号处理项目的构建和声音事件的检测响应,最后探讨了树莓派音频项目的拓展方向、
西门子G120C变频器维护速成

# 摘要
西门子G120C变频器作为工业自动化领域的一款重要设备,其基础理论、操作原理、硬件结构和软件功能对于维护人员和使用者来说至关重要。本文首先介绍了西门子G120C变频器的基本情况和理论知识,随后阐述了其硬件组成和软件功能,紧接着深入探讨了日常维护实践和常见故障的诊断处理方法。此外
【NASA电池数据集深度解析】:航天电池数据分析的终极指南
# 摘要
本论文提供了航天电池技术的全面分析,从基础理论到实际应用案例,以及未来发展趋势。首先,本文概述了航天电池技术的发展背景,并介绍了NASA电池数据集的理论基础,包括电池的关键性能指标和数据集结构。随后,文章着重分析了基于数据集的航天电池性能评估方法,包括统计学方法和机器学习技术的应用,以及深度学习在预测电池性能中的作用。此外,本文还探讨了数据可视化在分析航天电池数据集中的重要性和应用,包括工具的选择和高级可视化技巧。案例研究部分深入分析了NASA数据集中的故障模式识别及其在预防性维护中的应用。最后,本文预测了航天电池数据分析的未来趋势,强调了新兴技术的应用、数据科学与电池技术的交叉融合
HMC7044编程接口全解析:上位机软件开发与实例分析
# 摘要
本文全面介绍并分析了HMC7044编程接口的技术规格、初始化过程以及控制命令集。基于此,深入探讨了在工业控制系统、测试仪器以及智能传感器网络中的HMC7044接口的实际应用案例,包括系统架构、通信流程以及性能评估。此外,文章还讨论了HMC7044接口高级主题,如错误诊断、性能优化和安全机制,并对其在新技术中的应用前景进行了展望。
# 关键字
HMC7044;编程接口;数据传输速率;控制命令集;工业控制;性能优化
参考资源链接:[通过上位机配置HMC7044寄存器及生产文件使用](https://wenku.csdn.net/doc/49zqopuiyb?spm=1055.2635
【COMSOL Multiphysics软件基础入门】:XY曲线拟合中文操作指南
# 摘要
本文全面介绍了COMSOL Multiphysics软件在XY曲线拟合中的应用,旨在帮助用户通过高级拟合功能进行高效准确的数据分析。文章首先概述了COMSOL软件,随后探讨了XY曲线拟合的基本概念,包括数学基础和在COMSOL中的应用。接着,详细阐述了在COMSOL中进行XY曲线拟合的具体步骤,包括数据准备、拟合过程,
【GAMS编程高手之路】:手册未揭露的编程技巧大公开!
# 摘要
本文全面介绍了一种高级建模和编程语言GAMS(通用代数建模系统)的使用方法,包括基础语法、模型构建、进阶技巧以及实践应用案例。GAMS作为一种强大的工具,在经济学、工程优化和风险管理领域中应用广泛。文章详细阐述了如何利用GAMS进行模型创建、求解以及高级集合和参数处理,并探讨了如何通过高级
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )