图神经网络正则化艺术:PyTorch中防止过拟合的技巧
发布时间: 2024-12-11 20:47:05 阅读量: 6 订阅数: 8 

PyTorch中的正则化:提升模型性能的秘诀
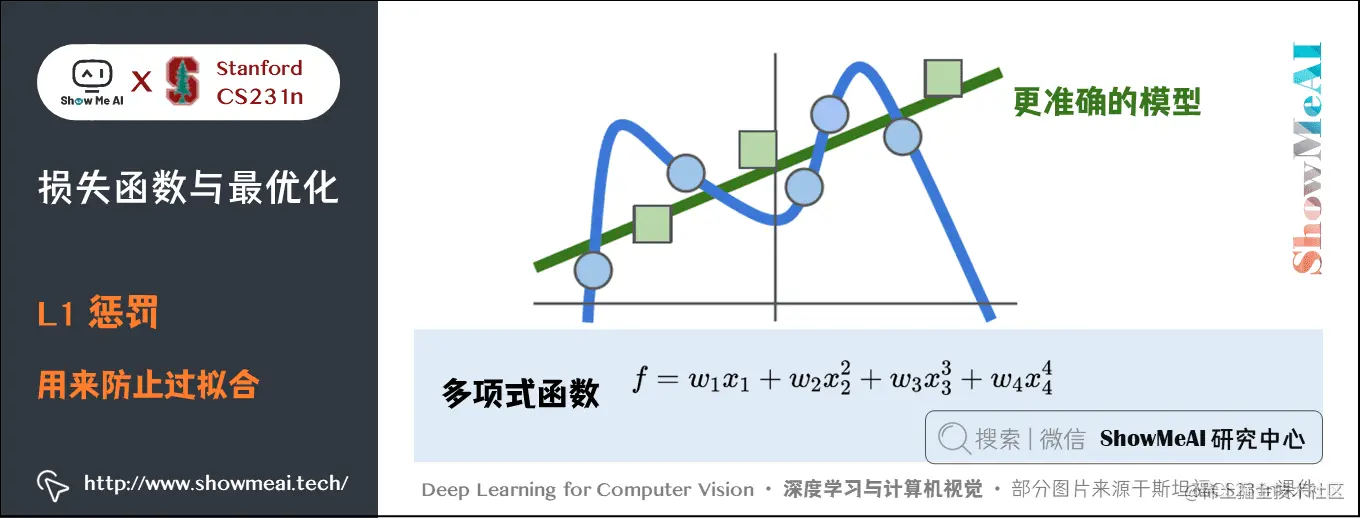
# 1. 图神经网络基础与过拟合问题
## 1.1 图神经网络的简介
图神经网络(GNNs)是深度学习中的一种特殊类型,专门为处理图结构化数据而设计。它能够处理非欧几里得数据,例如社交网络、生物信息学中的分子结构等。与传统神经网络相比,GNNs通过节点嵌入,能够捕捉图中节点的局部邻居信息及其相互关联的结构信息,这种能力是传统深度学习模型无法比拟的。
## 1.2 过拟合的定义及其影响
在机器学习领域,过拟合是指模型学习到了训练数据中的噪声和异常值,而不是真实数据的分布情况。这会导致模型在新的、未见过的数据上性能下降,因为它不能泛化到新的数据集。过拟合对图神经网络的影响尤为明显,因为图数据本身具有很强的结构特性和异质性,模型更容易在复杂的关系中捕获不具有一般性的特征。
## 1.3 过拟合问题的原因分析
过拟合通常发生在模型过于复杂,或者训练数据过小的情况下。对于图神经网络,过拟合的原因可能包括但不限于:
- **模型复杂度过高**:网络层次太深,参数量太大,模型具有高度的表达能力,能够记住训练数据。
- **训练数据有限**:由于图数据的收集和标注通常较为困难,因此常常面临数据不足的问题。
- **图的非均匀性**:不同图的结构、大小和节点属性可能差异很大,增加了过拟合的风险。
针对这些原因,图神经网络的正则化技术便显得尤为重要。通过引入正则化项,可以约束模型的复杂度,增加模型的泛化能力,避免过拟合。下一章,我们将深入探讨图神经网络的正则化理论及其具体实现。
# 2. 图神经网络正则化理论
## 2.1 正则化的基本概念
正则化是一种通过添加额外信息来解决不适定问题的技术。在机器学习和神经网络领域,正则化帮助缓解模型的过拟合问题,提高模型的泛化能力。
### 2.1.1 过拟合的定义和影响
过拟合发生在模型对训练数据集学习得太好,以至于它捕捉到了数据中的噪声和非代表性特征,导致模型在新数据上的表现较差。换言之,过拟合的模型在训练集上具有很高的准确率,但在验证集或测试集上的表现却明显下降。
当过拟合发生时,模型变得过于复杂,丧失了泛化能力。这限制了模型在真实世界数据中的应用效果,因为新数据可能与训练数据在分布上存在差异。
### 2.1.2 正则化的目的与效果
正则化旨在降低模型复杂度,增强其泛化能力。其核心思想是通过引入一个约束或惩罚项,防止模型过度拟合训练数据。正则化可以限制模型权重的大小或数量,或者通过其他机制迫使模型简单化。
应用正则化后,模型在训练集上的表现可能会有所下降,但是其在未见过的数据上的表现通常会得到提升,从而提高了整体性能。正则化效果的评价依赖于对验证集的测试,如果验证集的性能得到提升,则说明正则化起作用了。
## 2.2 正则化技术的种类
正则化技术可以大致分为三类:参数正则化、网络结构正则化,以及数据增强技术。
### 2.2.1 参数正则化(L1/L2 正则化)
L1和L2正则化是最常见的参数正则化形式。它们通过在损失函数中加入权重的L1或L2范数作为惩罚项来工作。
- L1正则化会导致权重的稀疏化,即一些权重变为零,有助于特征选择。
- L2正则化倾向于使权重的值变小但不会是零,有助于限制权重的大小。
代码块示例:
```python
# L2 正则化项添加至损失函数中
loss = criterion(outputs, labels) + weight_decay * torch.sum(torch.abs(model.parameters()))
```
### 2.2.2 网络结构正则化
网络结构正则化方法包括Dropout和批量归一化(Batch Normalization),它们通过改变网络结构或数据传递过程来减少过拟合。
- Dropout在训练过程中随机丢弃神经网络中的一些节点,强制网络学习更鲁棒的特征表示。
- 批量归一化则是在每一层输入上调整数据分布,减少内部协变量偏移。
代码块示例:
```python
# Dropout 层的实现
model.add_module('dropout', nn.Dropout(p=0.5))
# Batch Normalization 层的实现
model.add_module('batchnorm', nn.BatchNorm1d(num_features))
```
### 2.2.3 数据增强技术
数据增强是一种减少过拟合的流行方法,通过有策略地修改训练样本以生成新的训练样本来实现。
- 图数据的增强包括随机节点删除、边添加、特征扰动等。
- 通过数据增强,模型可以在更加多样化的数据上训练,提高其泛化性能。
## 2.3 正则化策略的选择与应用
选择合适的正则化方法并应用是解决过拟合问题的关键。这需要对模型和数据进行细致的分析和理解。
### 2.3.1 如何选择合适的正则化方法
选择正则化方法时,需要根据问题的性质和模型的结构来决定。参数正则化适用于权重过多或模型过于复杂的情况;网络结构正则化适用于网络结构本身存在问题;数据增强技术适用于数据集相对较小,容易过拟合的情况。
### 2.3.2 超参数调整与验证集的应用
超参数的选择需要通过交叉验证等方法不断调整,而验证集是检验模型性能和调整超参数的重要工具。
- 在训练模型时,使用验证集来评估模型的性能,并根据性能调整超参数,比如正则化系数。
- 在调整正则化超参数时,需要留意模型在验证集上的表现,避免在训练集上过拟合的同时,在验证集上欠拟合。
mermaid流程图示例:
```mermaid
graph TD;
A[开始模型训练] --> B[设置超参数];
B --> C[训练模型];
C --> D{验证集评估};
D -- 性能优秀 --> E[调整超参数];
E --> C;
D -- 性能不理想 --> F[停止训练];
F --> G[最终超参数确定];
G --> H[模型最终评估];
```
以上是对图神经网络正则化理论的基本介绍。接下来的章节,我们将深入了解如何在PyTorch框架中实现这些正则化技术,并探讨它们在高级应用中的潜力。
# 3. PyTorch中实现正则化技术
随着深度学习模型越来越复杂,正则化技术成为了防止过拟合、提高模型泛化能力的重要手段。本章将深入探讨如何在PyTorch框架中实现各种正则化技术,包括参数正则化、网络结构正则化以及数据增强方法,并分析它们对模型性能的影响。
## 3.1 参数正则化在PyTorch中的实现
### 3.1.1 L1和L2正则化项的添加方法
参数正则化是通过向损失函数添加一个额外的项(正则化项)来惩罚模型参数的复杂度。在PyTorch中,L1和L2正则化可以通过修改损失函数来实现。
```python
import torch
import torch.nn as nn
import torch.nn.functional as F
# 假设一个简单的线性模型
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = nn.Linear(in_features=10, out_features=1)
def forward(self, x):
return self.linear(x)
# 创建模型实例
model = LinearModel()
# 定义损失函数
criterion = nn.MSELoss()
# 正则化权重
lambd = 0.01
# 模型参数
parameters = model.parameters()
# 假设数据和目标
data = torch.randn(32, 10)
target = torch.randn(32, 1)
# 训练循环
optimizer = torch.optim.SGD(parameters, lr=0.01)
for epoch in range(100):
model.zero_grad()
# 前向传播
outputs = model(data)
loss = criterion(outputs, target)
# 计算正则化项
l1_norm = sum(p.abs().sum() for p in parameters)
l2_norm = sum(p.pow(2).sum() for p in parameters)
# 正则化损失
loss += lambd * (l1_norm + l2_norm)
# 反向传播
loss.backward()
optimizer.step()
```
在这个例子中,我们添加了L1正则化和L2正则化项到我们的损失函数中,通过`lambd`超参数控制正则化的强度。
### 3.1.2 正则化参数的选择技巧
选择合适的正则化参数(如L1和L2正则化中的`lambd`)是影响模型性能的关键。通常,这个参数是通过交叉验证来选择的,以找到最佳的正则化强度。可以使用`GridSearchCV`或者`RandomizedSearchCV`从`sklearn.model_selection`中来帮助自动化这个过程。
## 3.2 网络结构正则化技术
### 3.2.1 Dropout的使用与原理
Dropout是一种广泛使用的网络结构正则化技术。在训练过程中,它随机将网络中的部分节点输出置零,可以看作是训练多个子网络的一种集成学习策略。
```python
class DropoutModel(nn.Module):
def __init__(self):
super(DropoutModel, self).__init__()
self.linear = nn.Linear(in_features=10, out_features=1)
self.dropout = nn.Dropout(p=0.5) # Dropout率为0.5
def forward(self, x):
x = self.linear(x)
return self.dropout(x)
# Dropout模型实例
dropou
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 PyTorch 中图神经网络的各个方面,从基础概念到高级技术。它提供了全面的指南,涵盖了注意力机制、边缘特征处理、性能优化、正则化和跨领域应用。通过详细的示例和代码解析,专栏旨在帮助读者掌握图神经网络的原理和实践,并将其应用于各种现实世界问题中。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
西门子1200V90伺服系统:扭矩控制的原理与应用,你不容错过!

参考资源链接:[西门子V90PN伺服驱动参数读写教程](https://wenku.csdn.net/doc/6412b76abe7fbd1778d4a36a?spm=1055.2635.3001.10343)
# 1. 西门子1200V90伺服系统的概
【MAC版SAP GUI安装与配置秘籍】:一步到位掌握Mac上的SAP GUI安装与优化
参考资源链接:[MAC版SAP GUI快速安装与配置指南](https://wenku.csdn.net/doc/6412b761be7fbd1778d4a168?spm=1055.2635.3001.10343)
# 1. SAP GUI简介及安装前准备
## 1.1 SAP G
【平断面图的精通之路】:从入门到专家的全攻略

参考资源链接:[输电线路设计必备:平断面图详解与应用](https://wenku.csdn.net/doc/6dfbvqeah6?spm=1055.2635.3001.10343)
# 1. 平断面图基础知识介绍
## 1.1 平断面图的定义与作用
平断面图是一种工程图纸,它通过剖面形式展示了地形或结构物的水平和垂直切割面。在工程勘察、地质分析和建筑规划中,平断面图提供了直观的二维视图,便于设计人员和工程师理解地下情况
GT-POWER性能调优全攻略:案例分析与解决方案,立竿见影
参考资源链接:[GT-POWER基础培训手册](https://wenku.csdn.net/doc/64a2bf007ad1c22e79951b57?spm=1055.2635.3001.10343)
# 1. GT-POWER性能调优概述
在第一章中,我们将对GT-POWER性能调优进行概述,为读者搭建整体的知识框架。G
Python Requests异常处理从入门到精通:错误管理不求人

参考资源链接:[python requests官方中文文档( 高级用法 Requests 2.18.1 文档 )](https://wenku.csdn.net/doc/646c55d4543f844488d076df?spm=1055.2635.3001.10343)
# 1. Python Requests库基础
## 简介
Requests库是Python
硬件维修秘籍:破解联想L-IG41M主板的10大故障及实战解决方案
参考资源链接:[联想L-IG41M主板详细规格与接口详解](https://wenku.csdn.net/doc/1mnq1cxzd7?spm=1055.2635.3001.10343)
# 1. 硬件维修基础知识与主板概述
在硬件维修领域,掌握基础理论是至关重要的第一步。本章将介绍硬件维修的核心概念,并对主板进行基础性的概述,为后续更深入的维修实践奠定坚实的基
BIOS优化:提升启动速度和系统响应的策略
参考资源链接:[Beyond BIOS中文版:UEFI BIOS开发者必备指南](https://wenku.csdn.net/doc/64ab50a2b9988108f20f3a08?spm=1055.2635.3001.10343)
# 1. BIOS概述及优化必要性
## BIOS的历史和角色
BIOS,即基本输入输出系统
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )