【Java Spring Data精通之路】:从入门到专家级别的深度解析
发布时间: 2024-10-22 13:37:22 订阅数: 2 

# 1. Spring Data的简介与核心概念
## 1.1 Spring Data概述
Spring Data项目旨在通过减少数据访问层(DAL)的代码量来简化数据持久化任务。它提供了对各种持久化存储的抽象和标准化接口,使得开发者能够轻松切换不同类型的存储而无需重写代码。Spring Data的核心在于Repository抽象,它是数据访问代码和业务逻辑之间的桥梁。
## 1.2 核心组件
Spring Data的核心组件包括:
- **Repository接口**: 提供数据访问层的通用CRUD操作。
- **模块特定的扩展**: 如Spring Data JPA、Spring Data MongoDB,为特定技术提供特定操作。
- **Commons模块**: 包含不依赖于特定存储技术的核心功能,如分页和排序。
## 1.3 核心概念解读
Spring Data的另一核心概念是**自动实现Repository接口**。开发者定义接口,Spring Data自动提供实现,实现依赖注入,简化了代码量。例如,定义一个`UserRepository`接口继承`CrudRepository`,Spring Data将自动实现基本的CRUD操作。
下面是一个简单的例子:
```java
public interface UserRepository extends CrudRepository<User, Long> {
}
```
无需编写任何实现代码,Spring Data就为这个接口提供了增加、删除、查询、更新等操作的具体实现。这种模式极大地减少了样板代码,使开发者可以更专注于业务逻辑的实现。
# 2. Spring Data基础操作
## 2.1 Spring Data JPA快速入门
### 2.1.1 配置Spring Data JPA环境
要开始使用Spring Data JPA,首先需要配置相关的环境。这涉及到在项目中添加Spring Data JPA依赖,配置数据源和JPA的属性,以及定义实体管理器工厂和事务管理器。以下是一个基本的Spring Boot项目配置示例,它展示了如何快速搭建一个Spring Data JPA环境。
```xml
<!-- pom.xml中添加Spring Boot的起步依赖 -->
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 其他依赖,例如数据库驱动依赖等 -->
</dependencies>
<!-- application.properties中配置数据源和JPA属性 -->
spring.datasource.url=jdbc:mysql://localhost:3306/spring_data_jpa
spring.datasource.username=root
spring.datasource.password=yourpassword
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.jpa.hibernate.ddl-auto=update
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5InnoDBDialect
```
在这个配置中,我们添加了`spring-boot-starter-data-jpa`依赖来简化JPA的集成,并且通过`application.properties`配置了数据源连接信息和JPA的一些必要属性。`spring.jpa.hibernate.ddl-auto`用于控制JPA的数据库迁移行为,`update`模式意味着JPA会在启动时检查数据库模式,并根据实体类的定义来更新数据库表结构。
### 2.1.2 实体类与Repository接口
一旦环境配置完成,我们就可以定义实体类和Repository接口来完成数据持久化的相关操作。下面是一个简单的用户实体类和对应的Repository接口示例。
```java
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
import org.springframework.data.jpa.repository.JpaRepository;
@Entity
@Table(name = "user")
public class User {
@Id
private Long id;
private String name;
// 省略getter和setter方法
}
public interface UserRepository extends JpaRepository<User, Long> {
// 这里可以声明一些自定义查询方法
}
```
`User`类使用`@Entity`注解来标记它为一个JPA实体,并通过`@Table`指定了数据库表名。`@Id`注解标记了实体的主键字段。`UserRepository`接口继承自`JpaRepository`,这提供了基本的CRUD操作和一些常用的方法。
通过以上两节的介绍,我们已经搭建起了Spring Data JPA的环境,并定义了基本的实体和Repository接口。这些步骤为后续操作打下了基础,接下来我们将深入到具体的CRUD操作中。
## 2.2 Spring Data的CRUD操作
### 2.2.1 基本的增删改查方法
Spring Data JPA为基本的CRUD操作提供了通用的接口方法,开发者无需编写具体实现,这些方法可以直接使用。接下来,我们将学习如何使用这些方法,并了解它们的内部工作机制。
```java
// 假设已经有一个User实体和UserRepository接口
public class UserService {
@Autowired
private UserRepository userRepository;
public User createUser(User user) {
return userRepository.save(user);
}
public User getUser(Long id) {
return userRepository.findById(id).orElse(null);
}
public User updateUser(Long id, String name) {
User user = userRepository.findById(id).orElse(null);
if (user != null) {
user.setName(name);
userRepository.save(user);
}
return user;
}
public void deleteUser(Long id) {
userRepository.deleteById(id);
}
}
```
以上示例中,`createUser`方法使用`save()`方法来创建或更新一个实体,`getUser`方法通过`findById()`方法来获取一个实体。如果实体存在,则返回该实体,否则返回null。`updateUser`方法首先通过`findById()`检查实体是否存在,如果存在则修改并保存。`deleteUser`方法则通过`deleteById()`方法来删除指定ID的实体。
### 2.2.2 自定义查询方法
在某些情况下,内置的CRUD方法可能无法满足我们的需求,这时我们可以定义一些自定义查询方法。Spring Data JPA允许我们通过方法名约定或者使用`@Query`注解来定义复杂的查询。
```java
public interface UserRepository extends JpaRepository<User, Long> {
List<User> findByName(String name); // 通过方法名约定查询用户名为指定值的用户
@Query("SELECT u FROM User u WHERE u.id = :id AND u.name = :name")
User findByIdAndName(@Param("id") Long id, @Param("name") String name); // 使用@Query自定义查询
}
```
方法名约定查询是通过遵循一定的命名规则来实现的,例如`findByName`方法会自动解析为按照`name`属性进行查询。`@Query`注解则提供了更大的灵活性,允许我们编写自定义的JPQL(Java Persistence Query Language)或SQL语句来执行查询。
## 2.3 Spring Data中的事务管理
### 2.3.1 事务的声明与传播
在Spring Data JPA中,事务管理主要通过在业务逻辑层的方法上添加`@Transactional`注解来声明。这告诉Spring框架,该方法需要在事务上下文中执行。事务的传播行为定义了事务应该如何在不同方法间传播,也就是一个事务方法被另一个事务方法调用时,事务的边界如何处理。
```java
@Transactional
public class UserService {
// 假设上面的方法已经定义
public void performUserOperations() {
User user = createUser(new User(1L, "Alice"));
updateUser(user.getId(), "Alice Updated");
deleteUser(user.getId());
}
}
```
在上述例子中,`performUserOperations`方法中的三个操作都被一个事务所覆盖。这意味着,如果任何一个操作失败,整个事务都将回滚。
### 2.3.2 事务的隔离级别和回滚规则
事务的隔离级别定义了一个事务可能受其他并发事务影响的程度。Spring Data JPA允许我们通过`@Transactional`注解的属性来设置事务的隔离级别。
```java
@Transactional(isolation = Isolation.READ_COMMITTED)
public void performUserOperations() {
// 同上
}
```
此外,事务的回滚规则可以通过`rollbackFor`属性来指定哪些异常会导致事务回滚。默认情况下,只有运行时异常会触发回滚。
```java
@Transactional(rollbackFor = {IllegalStateException.class, IllegalArgumentException.class})
public void performUserOperations() {
// 同上
}
```
通过本节的介绍,我们了解了Spring Data JPA提供的基础操作功能,包括基本的CRUD操作和事务管理。这些操作构成了Spring Data JPA使用的核心,是进行数据持久化操作的基础。在下一节中,我们将探索Spring Data的进阶特性,这些特性进一步提高了数据访问的灵活性和效率。
# 3. Spring Data进阶特性
## 3.1 Spring Data与NoSQL数据库的集成
### 3.1.1 MongoDB的基本使用
MongoDB作为一种流行的NoSQL数据库,它的灵活性和高性能对于许多应用来说是巨大的优势。Spring Data通过Spring Data MongoDB模块提供了与MongoDB的无缝集成。
**MongoDB集成的关键步骤**:
1. **添加依赖**:首先需要在项目中添加Spring Data MongoDB的依赖。在`pom.xml`中添加如下依赖:
```xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
```
2. **配置MongoDB**:接下来需要配置MongoDB连接。在`application.properties`中指定MongoDB的地址和端口:
```properties
spring.data.mongodb.uri=mongodb://localhost:27017/testdb
```
3. **创建实体类**:创建一个简单的实体类`Person`,使用`@Document`注解来标记这个类对应MongoDB中的一个集合。
```java
@Document(collection = "person")
public class Person {
@Id
private String id;
private String name;
private int age;
// getters and setters
}
```
4. **操作MongoDB**:通过Spring Data的MongoRepository接口,我们可以直接进行CRUD操作。
```java
public interface PersonRepository extends MongoRepository<Person, String> {
}
```
MongoDB提供了灵活的文档存储方式和丰富的查询能力,Spring Data使这些操作更加简单和直观。
### 3.1.2 Redis的键值操作与高级特性
Redis是一个开源的高性能键值数据库,常用于缓存、消息队列等场景。Spring Data Redis提供了对Redis操作的高级抽象。
**Redis集成的关键步骤**:
1. **添加依赖**:添加Spring Data Redis的依赖到项目中。
```xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
```
2. **配置Redis**:配置连接Redis所需的参数。
```properties
spring.redis.host=localhost
spring.redis.port=6379
```
3. **使用RedisTemplate**:通过`RedisTemplate`可以进行复杂的Redis操作。`RedisTemplate`提供了对Redis各种操作的抽象。
```java
@Autowired
private RedisTemplate<String, String> redisTemplate;
public void setValue(String key, String value) {
redisTemplate.opsForValue().set(key, value);
}
public String getValue(String key) {
return redisTemplate.opsForValue().get(key);
}
```
4. **高级特性**:Redis提供了订阅发布模式、事务、Lua脚本等高级特性,Spring Data Redis也提供了相应的支持。
```java
// 订阅消息
public void subscribe(String channel, MessageListener listener) {
redisTemplate.execute((RedisCallback<Void>) connection -> {
connection.subscribe(new RedisChannelTopic(channel), listener);
return null;
});
}
```
借助于Spring Data Redis,对Redis的使用变得简单,同时还能保证高性能和可靠性。
## 3.2 Spring Data的复杂查询与视图
### 3.2.1 SpEL与方法表达式
Spring表达式语言(SpEL)是Spring框架的核心功能之一,它提供了丰富强大的表达式定义能力,可用于查询方法的定义。
**使用SpEL的步骤**:
1. **方法命名约定**:通过方法名中使用特殊的表达式来定义查询。
```java
public interface EmployeeRepository extends JpaRepository<Employee, Long> {
List<Employee> findByDepartmentName(String deptName);
}
```
2. **使用@Query注解**:可以通过@Query注解来使用SpEL定义复杂查询。
```java
@Query("select e from Employee e where e.salary > ?#{[0]} and e.department.name = ?#{[1]}")
List<Employee> findHighSalaryEmployees(Long salaryThreshold, String deptName);
```
SpEL提供了强大的灵活性,可以支持复杂的查询逻辑和动态参数的处理。
### 3.2.2 存储过程与视图的使用
在某些数据库操作中,使用存储过程可以实现更加复杂的业务逻辑。Spring Data同样提供了对存储过程的集成。
**存储过程的关键步骤**:
1. **配置存储过程**:通过配置文件或代码定义存储过程。
```java
@Procedure(name = "getEmployeeByDept")
List<Employee> findEmployeesByDepartmentName(@Param("deptName") String deptName);
```
2. **调用存储过程**:通过Repository接口方法直接调用存储过程。
```java
List<Employee> employees = employeeRepository.findEmployeesByDepartmentName("IT");
```
对于视图(View)的使用,Spring Data也提供了类似的支持,允许开发者将视图作为实体进行查询。
## 3.3 Spring Data的分页与排序
### 3.3.1 分页的基本实现
分页是处理大量数据时常见的需求。Spring Data提供了开箱即用的分页支持。
**分页实现的步骤**:
1. **定义Pageable参数**:在方法参数中使用`Pageable`来指定分页参数。
```java
public Page<Employee> findAll(Pageable pageable);
```
2. **构造Pageable对象**:可以通过`PageRequest`类来构造`Pageable`对象。
```java
PageRequest pageRequest = PageRequest.of(0, 10);
Page<Employee> page = repository.findAll(pageRequest);
```
3. **返回Page对象**:方法返回类型为`Page<T>`,它包含了分页数据以及分页信息(如总数、当前页码等)。
```java
List<Employee> employees = page.getContent();
long totalElements = page.getTotalElements();
```
### 3.3.2 排序与条件查询的结合应用
在分页的基础上,我们经常会结合排序操作。Spring Data支持在查询方法中直接指定排序规则。
**排序实现的示例**:
1. **方法命名约定**:使用`Sort`对象或直接在方法名中指定排序参数。
```java
List<Employee> findByAgeGreaterThanOrderBySalaryDesc(int age);
```
2. **使用Pageable进行排序**:结合`Pageable`进行分页和排序。
```java
public Page<Employee> findByDepartmentName(String deptName, Pageable pageable);
```
Spring Data的强大分页和排序支持极大地简化了分页和排序操作的代码量,提升了开发效率。
```mermaid
sequenceDiagram
participant U as 用户
participant A as 应用程序
participant D as 数据库
U->>A: 请求分页数据
A->>D: 执行分页查询
D-->>A: 返回数据
A-->>U: 显示分页数据
```
以上只是对Spring Data进阶特性中与NoSQL数据库的集成、复杂查询与视图以及分页与排序相关特性的初步探讨。通过这些章节内容的学习,开发者可以更加深入地理解和掌握Spring Data的进阶使用技巧,从而在实际开发中更加高效地实现数据持久化与查询操作。
# 4. ```
# 第四章:Spring Data项目实战
## 4.1 Spring Data在业务中的应用
### 4.1.1 领域驱动设计(DDD)与Spring Data
领域驱动设计(Domain-Driven Design,DDD)是一种软件开发方法,它侧重于业务领域模型的开发,并试图减少技术问题对业务领域的影响。在使用Spring Data时,DDD可以有效地管理复杂的业务需求,并将数据存储与业务逻辑分离。Spring Data的Repository接口天然适合DDD架构,因为它们可以作为领域对象和数据存储之间的桥梁。
在DDD中,一个核心概念是聚合根(Aggregate Root),它代表了一组相关领域的对象。这些对象通过聚合根与其他领域对象交互。Spring Data通过自定义Repository接口支持聚合模式,允许开发者定义复杂的数据操作逻辑。
下面的例子展示了如何定义一个聚合根以及相应的Repository接口:
```java
// 领域对象,例如订单聚合根
public class Order {
@Id
private Long id;
// 其他属性、方法
}
// 对应的Repository接口
public interface OrderRepository extends Repository<Order, Long> {
// 定义一些复杂查询方法
}
```
通过这种方式,Spring Data允许我们专注于领域模型,而将数据持久化的细节交给框架处理。这使得我们可以轻松地实现业务逻辑,并在代码中清晰地表达业务规则。
### 4.1.2 复杂业务场景下的数据持久化策略
在复杂的业务场景中,数据持久化策略需要考虑如何高效地处理大量数据、如何维护数据的一致性,以及如何优化性能。Spring Data提供了多种策略来应对这些挑战。
例如,当业务场景涉及到大量数据的查询和处理时,可以利用Spring Data的分页和排序功能。这不仅可以帮助管理内存使用,还能提高查询效率。下面是一个简单的分页查询示例:
```java
public interface CustomerRepository extends PagingAndSortingRepository<Customer, Long> {
}
// 在业务层中使用分页
Pageable pageable = PageRequest.of(pageNumber, pageSize);
Page<Customer> customers = customerRepository.findAll(pageable);
```
对于需要维护一致性的场景,Spring Data支持事务管理,允许开发者通过声明式的方式管理事务。可以指定事务的传播行为、隔离级别和回滚规则,确保数据操作的原子性和一致性。
在性能优化方面,Spring Data提供了缓存机制,可以有效地减少对数据库的访问次数。开发者可以通过注解来声明哪些方法应该被缓存,以及缓存的策略。例如:
```java
@Cacheable(value = "customers")
public Customer findCustomerById(Long id) {
return customerRepository.findById(id).orElse(null);
}
```
通过这种方式,频繁查询相同的客户信息时,Spring Data将从缓存中返回结果,而不需要每次都访问数据库。
## 4.2 Spring Data性能优化
### 4.2.1 查询优化技巧
在处理大型数据库时,查询优化是提高应用性能的关键。Spring Data通过多种方式帮助开发者优化查询。
首先,可以使用Spring Data的 Criteria API 或 QueryDSL 来创建动态查询,这允许开发者在运行时构建查询语句,而不需要硬编码。这不仅可以根据需要定制查询,还能在数据库表结构变化时快速适应。
```java
// 使用Criteria API创建查询
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Customer> query = builder.createQuery(Customer.class);
Root<Customer> root = query.from(Customer.class);
query.select(root);
query.where(builder.equal(root.get("id"), 1L));
List<Customer> customers = entityManager.createQuery(query).getResultList();
```
其次,可以使用Spring Data的@Query注解直接编写JPQL或原生SQL语句,以进行更细粒度的控制。例如:
```java
public interface CustomerRepository extends JpaRepository<Customer, Long> {
@Query("SELECT c FROM Customer c WHERE c.name = ?1")
List<Customer> findByName(String name);
}
```
最后,可以利用数据库索引来加速查询。确保在数据库表中为经常查询的字段创建索引,可以大幅提高查询速度。
### 4.2.2 高效缓存机制的应用
缓存是提高数据库操作性能的常用技术。Spring Data支持多种缓存技术,如Ehcache、Redis、Caffeine等,并提供了简单的方式启用和配置缓存。
缓存可以应用于不同层次,比如方法级别的缓存、类级别的缓存,甚至是特定查询的缓存。使用@Cacheable注解可以轻松地启用方法级别的缓存:
```java
@Cacheable(value = "orders")
public Order getOrderById(Long id) {
return orderRepository.findById(id).orElse(null);
}
```
在配置中,可以定义缓存的过期策略、容量限制等,以满足不同的业务需求。缓存机制的合理使用,可以显著减少数据库的访问量,提高整体系统的响应速度。
## 4.3 Spring Data的扩展与集成
### 4.3.1 自定义Repository扩展
Spring Data的Repository接口为开发者提供了一种方便的方式来实现数据访问层,但它同样支持扩展以满足更复杂的业务需求。自定义Repository是Spring Data扩展性的一个重要方面。
自定义Repository可以通过继承标准的Repository接口,并添加自定义方法来实现。例如:
```java
public interface CustomOrderRepository {
List<Order> findOrdersByCustomCriteria(Map<String, Object> criteria);
}
public interface OrderRepository extends JpaRepository<Order, Long>, CustomOrderRepository {
// 此接口将继承JpaRepository和CustomOrderRepository的方法
}
```
在实现类中,可以编写具体的方法逻辑:
```java
@Service
public class OrderRepositoryImpl implements CustomOrderRepository {
@PersistenceContext
private EntityManager entityManager;
@Override
public List<Order> findOrdersByCustomCriteria(Map<String, Object> criteria) {
// 根据传入的criteria构建并执行查询逻辑
}
}
```
通过这种方式,开发者可以根据特定的业务场景,添加任意复杂的查询逻辑。
### 4.3.2 Spring Boot与Spring Data的集成
Spring Boot是Spring提供的一个快速应用开发平台,它与Spring Data完美集成,大大简化了项目设置和配置。在Spring Boot项目中,几乎不需要编写任何XML配置文件,就可以通过简单的注解来启动和运行Spring Data。
Spring Boot自动配置(auto-configuration)机制可以自动检测项目中添加的库,并配置相应组件。例如,如果你在项目中加入了Spring Data JPA的依赖,Spring Boot会自动配置EntityManagerFactory、TransactionManager等。
```java
@SpringBootApplication
@EnableJpaRepositories(basePackages = "com.example.project.repository")
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
```
在Spring Boot应用中使用Spring Data,你可以通过继承CrudRepository或JpaRepository来快速实现数据访问逻辑。这种集成大大加快了开发速度,并使得项目的结构更加清晰。
在性能优化方面,Spring Boot也提供了许多有用的特性,如自动配置数据源、优化的嵌入式数据库支持、以及针对生产环境的性能调整选项。
通过Spring Boot和Spring Data的集成,开发者可以构建出简洁、高效、易于维护的现代Java应用。
```
# 5. Spring Data高级主题
## 5.1 Spring Data与Spring Cloud的整合
Spring Data与Spring Cloud的整合为开发分布式系统提供了极大的便利。Spring Cloud的众多组件如Eureka、Hystrix、Zuul和Config Server等与Spring Data的结合使得构建微服务架构变得简单而强大。
### 5.1.1 分布式数据存储解决方案
在微服务架构中,每个服务通常拥有自己的数据存储,而不是所有的服务共享一个数据库。这样的分布式数据存储解决方案可以提高系统的可扩展性和可维护性。以Spring Cloud Netflix Eureka作为服务发现组件,可以配合Spring Data实现服务的自动注册与发现。
```java
@EnableEurekaClient
@SpringBootApplication
public class MyServiceApplication {
public static void main(String[] args) {
SpringApplication.run(MyServiceApplication.class, args);
}
}
```
在上面的代码中,`@EnableEurekaClient`注解表明此服务将注册到Eureka Server。
接下来,Spring Data可以连接到对应的服务数据库,例如:
```java
@Configuration
@EnableJpaRepositories(basePackages = "com.example.repository")
public class PersistenceJPAConfig extends PersistenceContextConfiguration {
// 配置数据库连接
}
```
这将自动扫描指定包下的Repository接口,并使用JPA进行数据库操作。
### 5.1.2 微服务架构下的数据一致性问题
在微服务架构中,服务之间可能需要共享数据,这就引出了分布式数据一致性的问题。Spring Cloud与Spring Data的结合使用,可以利用消息队列、分布式事务等技术来解决数据一致性问题。
在使用Spring Cloud Stream作为消息驱动的技术框架时,我们可以为数据变更发布消息,例如:
```java
@Service
public class MessageProducer {
@Autowired
private MessageChannel output;
public void send(String message) {
output.send(MessageBuilder.withPayload(message).build());
}
}
```
这段代码定义了一个消息发送服务,用于在数据变更后发送消息。
为了处理复杂的数据一致性问题,可以采用两阶段提交协议,结合Spring Cloud Sleuth和Zipkin实现分布式追踪,保证系统事务的一致性。
## 5.2 Spring Data的模块化与定制化
Spring Data的模块化与定制化为开发者提供了灵活性,允许在现有框架之上构建更加专业化的数据访问层。
### 5.2.1 模块化的数据访问策略
模块化的数据访问策略意味着不同的数据访问技术可以独立存在。Spring Data支持多种数据存储解决方案,包括但不限于关系数据库、文档型数据库和键值存储。通过定义不同的Repository接口,开发者可以选择最适合自己业务需求的数据访问策略。
例如,创建一个继承自`CrudRepository`的接口来操作数据:
```java
public interface PersonRepository extends CrudRepository<Person, Long> {
List<Person> findByLastname(String lastname);
}
```
该接口继承了Spring Data JPA的`CrudRepository`,可以直接使用基本的CRUD操作,并添加了自定义查询方法。
### 5.2.2 定制化Repository实现
当Spring Data提供的标准操作无法满足特定需求时,可以通过实现`CustomRepository`来创建定制化的操作。这种方式为开发者提供了强大的扩展能力。
假设我们有一个特殊需求需要实现对数据的复杂处理:
```java
public interface CustomUserRepository {
User findUserAndRoles(Long id);
}
```
开发者可以实现这个接口,编写具体的逻辑:
```java
@Service
public class CustomUserRepositoryImpl implements CustomUserRepository {
@PersistenceContext
private EntityManager entityManager;
@Override
public User findUserAndRoles(Long id) {
// 自定义的JPA查询
return entityManager.createQuery("SELECT u FROM User u JOIN FETCH u.roles WHERE u.id = :id", User.class)
.setParameter("id", id)
.getSingleResult();
}
}
```
这段代码展示了如何实现一个需要联表查询的定制方法。
## 5.3 Spring Data安全与监控
随着应用程序变得越来越复杂,数据安全和监控逐渐成为开发中不可忽视的要素。Spring Data通过集成Spring Security和Spring Boot Actuator为数据操作提供了安全性和监控能力。
### 5.3.1 为数据操作添加安全性
Spring Data可以与Spring Security无缝集成,以实现数据操作的安全性。开发者可以通过配置来实现认证和授权,从而保护敏感数据。
例如,在Spring Security配置中添加对数据访问的控制:
```java
@EnableWebSecurity
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.antMatchers("/data/**").hasRole("USER")
.anyRequest().authenticated()
.and()
.httpBasic();
}
}
```
这段配置要求所有访问`/data/**`路径的请求都必须通过HTTP基本认证。
### 5.3.2 Spring Data的健康检查与监控
Spring Boot Actuator提供了应用程序的健康检查和监控。这在生产环境中至关重要,它允许开发者对数据库连接、缓存、内存使用、线程状态等关键指标进行监控。
```java
@Component
public class CustomHealthIndicator implements HealthIndicator {
@Override
public Health health() {
// 检查数据源状态
DataSource dataSource = // 获取数据源
int health = // 检查数据源可用性
if (health == // 数据源可用) {
return Health.up().withDetail("status", "UP").build();
}
return Health.down().withDetail("status", "DOWN").build();
}
}
```
这段代码实现了一个自定义的健康指示器,用于检查数据源的状态。
通过上述各个方面的深入理解与应用,Spring Data不仅仅局限于简单的数据访问,它已经成为构建高效、安全、可监控的现代数据存储解决方案的核心框架。随着Spring Data模块的不断演进和扩展,其在IT行业中的应用只会更加广泛和深入。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
std::any多态实现:策略模式的新视角
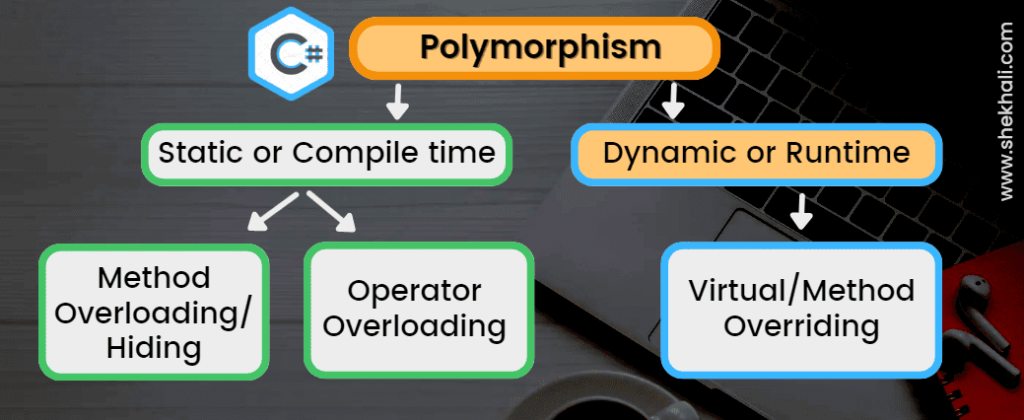
# 1. std::any多态实现的基础概念
在现代C++编程实践中,类型擦除是一种常用的技术,允许我们编写能够处理不同类型的代码,而无需知道具体的类型信息。std::any是C++17中引入的一个类型擦除容器,它能够存储任意类型的值,为多态实现提供了便利。std::any的最大优势在于能够替代void指针的使用场景,同时避免了运行时类型识别(RTTI)的开销,增强了类型安
【Web应用安全升级指南】:12种***授权机制深入解析与实战应用
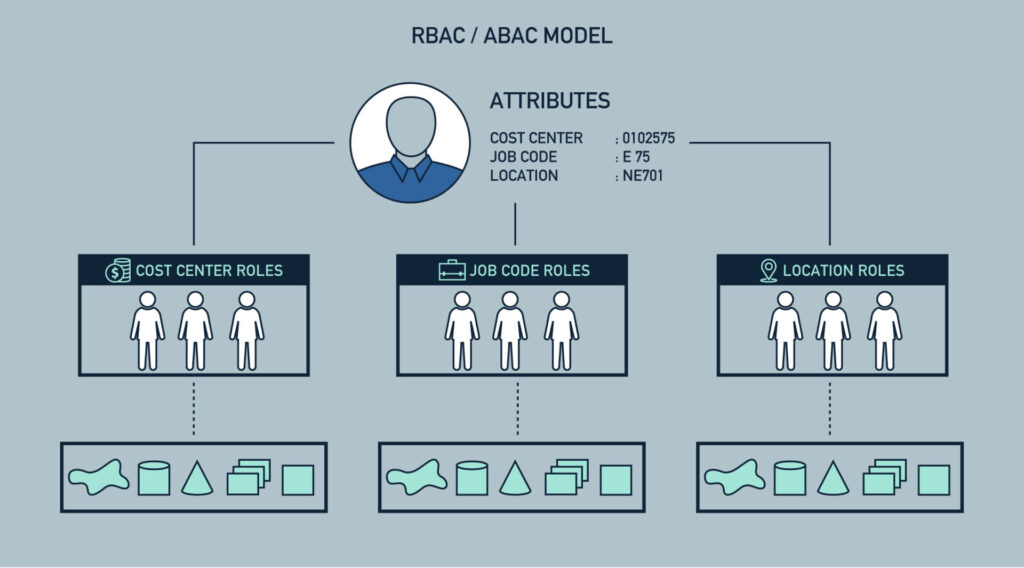
# 1. Web应用安全基础概述
## 1.1 安全的定义与重要性
Web应用安全是确保网站和网络应用程序免受恶意攻击和非法访问的一系列措施。随着数字信息的爆发性增长,安全已成为开发和维护Web应用的核心要求。安全性不仅保护了企业资产,也维护了用户信任,是企业长期成功的关键
GORM自定义类型处理:映射复杂数据结构的解决方案
# 1. GORM自定义类型处理概述
GORM是一个流行的Go语言ORM库,它为开发者提供了便捷的方式来实现Go结构体与数据库表的映射。在处理复杂的数据模型时,经常需要自定义类型来适应特定的业务需求。GORM提供了一套灵活的类型处理机制,允许开发者通过自定义类型映射来扩展其功能。本章旨在概述GORM自定义类型处理的基本概念和重要性,为后续章节对类型映射机制、自定义适配器、高级应用以及最佳实践的深入分析和案
Go语言中的GraphQL订阅】:实时数据交互的实现指南

# 1. GraphQL订阅基础
## 1.1 GraphQL简介
GraphQL是一种由Facebook开发的用于API的查询语言。它允许客户端精确地指定他们需要什么数据,以此取代传统REST API中通过多个端点获取数据的方式。GraphQL不仅仅局限于查询,还可以进行变更和订阅。
## 1.2 订阅与REST API的对比
相较于REST API通过轮询或长轮询来实现数据
【安全加固】:C#自定义视图组件安全最佳实践的专家建议
# 1. C#自定义视图组件安全基础
## 1.1 安全基础的重要性
C#自定义视图组件的安全性对于构建可靠的应用程序至关重要。组件安全不仅涉及防止恶意攻击,还包括保证数据的完整性和保密性。本章将概述在设计和实现自定义视图组件时需要考虑的安全基础。
## 1.2 安全编程的概念
安全编程是指在编写代码时采用一系列的策略和技术以减少软件中潜在的安全风险。在C#中,这包括对输入的验证、输出的编码、错误处理和使用安全的API。
## 1.3 安全编程的原则
本章还会介绍一些基本的安全编程原则,如最小权限原则、权限分离、防御深度和安全默认设置。这些原则将为后续章节中关于视图组件安全实践和高
C#自定义身份验证的稀缺技巧:确保***应用的安全性(专家建议)
# 1. C#自定义身份验证概述
在数字化时代,安全地验证用户身份是软件开发的关键组成部分。C#作为.NET平台的主力开发语言,提供了强大的工具来实现复杂的自定义身份验证方案。本章将概述自定义身份验证的基本概念,为理解后续章节的深度探讨打下基础。我们将简要介绍身份验证的重要性以及如何在C#应用程序中实现它,同时提及在安全性方面的初步考虑。通过了解这些基本原理,
从std::monostate到std::variant:C++类型多态的演进之路

# 1. C++类型多态基础
C++作为一种支持面向对象编程的语言,其类型多态是实现代码复用和扩展性的核心机制之一。多态允许我们通过统一的接口来操作不同的对象类型,这通常通过继承和虚函数来实现。在本章节中,我们将对多态进行简要的回顾,为后续深入探讨C++17引入的std::monostate和std::variant提供基础。
## 1.1 多态的基本概念
多态可以简单理解
Go语言数据库连接池的架构设计与最佳实践:打造高效系统

# 1. Go语言数据库连接池概述
数据库连接池是一种用来管理应用程序与数据库之间连接的技术,它可以有效提高系统性能并减少资源消耗。在Go语言中,连接池不仅能够优化数据库操作的响应时间,还可以在高并发环境下保持程序的稳定运行。
Go语言作为一种高性能编程语言,广泛应用于构建高效的
JAX-RS与JSON处理:性能优化与最佳实践的结合

# 1. JAX-RS与JSON处理的基础
在现代Web应用开发中,JAX-RS(Java API for RESTful Web Services)和JSON(JavaScript Object Notation)已成为构建RESTful服务的基石。JAX-RS提供了一套标准的Java API,用于开发符合REST架构风格的Web服务。而JSON作为一种轻量级的数据交换格式
Java MicroProfile多语言支持:Polyglot微服务架构构建指南
# 1. Java MicroProfile简介与多语言支持概述
在现代软件架构领域中,Java MicroProfile作为一种针对微服务优化的Java企业版(Java EE)标准,已经成为开发高效、可扩展微服务架构的首选。然而,在微服务的实践中,技术的多样性是不可避
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )