Spring Data在大数据环境下的应用:拥抱Hadoop与Spark的实战技巧
发布时间: 2024-10-22 14:26:06 阅读量: 31 订阅数: 31 
# 1. 大数据环境与Spring Data概述
在信息技术快速发展的今天,大数据环境已经成为企业运营和决策的重要支撑。而Spring Data作为Spring框架中的一个模块,旨在简化数据持久化的操作,为大数据环境提供了一种更为高效的解决方案。Spring Data通过提供统一的数据访问层抽象,使得开发者能够更专注于业务逻辑的实现,而非底层数据访问细节。
## 1.1 大数据环境的挑战
大数据环境带来了数据量的爆炸性增长,数据类型多样化以及数据处理速度的提升等问题。这些挑战促使我们需要新的技术解决方案来应对,比如分布式存储、非关系型数据库、高性能计算框架等。
## 1.2 Spring Data的出现
Spring Data的出现,就是为了帮助开发者在大数据环境下更好地管理数据。它的设计哲学是简化数据访问层的代码,让开发者能够以声明性的方式进行数据操作,大大降低了大数据处理的复杂性。
## 1.3 Spring Data与大数据的结合
Spring Data与大数据技术的结合,为处理大规模数据集提供了更为灵活和强大的工具集。通过Spring Data,开发者可以轻松集成Hadoop、Spark等大数据框架,将传统的关系型数据库操作和非关系型数据操作无缝整合,实现高效的大数据处理。
在后续章节中,我们将深入探讨Spring Data的基本原理和特性,以及它在Hadoop和Spark等大数据生态系统中的应用和高级优化策略。通过具体案例分析,我们还将总结出在大数据环境下运用Spring Data的最佳实践。
# 2. Spring Data的基本原理和特性
## 2.1 Spring Data项目家族简介
### 2.1.1 Spring Data核心概念
Spring Data项目的核心理念是简化数据访问层(Repository layer)的实现,从而可以专注于业务逻辑的开发。Spring Data提供了一套统一的数据访问模板(Repository),针对不同的数据存储技术如关系数据库、非关系数据库、搜索引擎等,Spring Data都提供了对应的模板实现。开发者只需要遵循Spring Data的规则,便可以轻松实现数据访问层的编码。
### 2.1.2 Spring Data模块划分
Spring Data的项目家族十分庞大,包括了多个子项目,如Spring Data Commons、Spring Data JPA、Spring Data MongoDB等,这些子项目提供了对各种数据源的无缝支持。通过统一的接口设计,开发者可以很方便地在不同子项目之间进行切换,且几乎无需更改业务代码。例如,Spring Data JPA让开发者可以通过定义接口来实现对JPA实体的CRUD操作,而Spring Data MongoDB则提供了对应MongoDB数据库的类似功能。
## 2.2 Spring Data与大数据的融合
### 2.2.1 大数据框架支持概览
随着大数据技术的发展,Spring Data开始扩展其对大数据框架的支持。目前Spring Data已经能够支持如Hadoop、Apache Cassandra、Apache Solr等主流大数据技术。这些支持不仅仅包括了数据存储层面的交互,还包括了数据处理、查询优化等方面,极大地提高了开发效率。
### 2.2.2 Spring Data对于大数据场景的优势
Spring Data在大数据场景下具备以下优势:
- **高效的数据访问**:通过Spring Data的抽象,开发者可以编写更少的模板代码,从而快速实现对大数据存储的访问。
- **优秀的集成性**:Spring Data与Spring生态系统中的其他项目如Spring Batch、Spring Integration等集成紧密,可以快速构建复杂的大数据处理流程。
- **一致的编程模型**:无论底层使用的是哪种大数据技术,开发者都可以使用一致的编程模型来进行操作,减少了学习成本。
## 2.3 Spring Data的关键技术和实践
### 2.3.1 仓库接口的高级用法
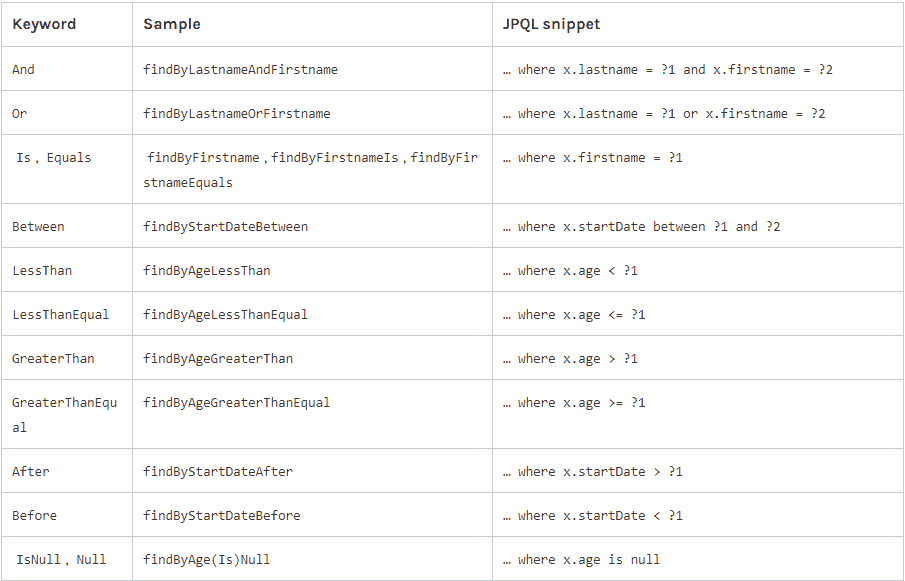
Spring Data的仓库接口(Repository interfaces)是其最核心的部分,支持高级用法,比如自定义查询方法。开发者可以通过方法命名约定来定义查询,而无需编写任何查询语句。例如,在Spring Data JPA中,只需要定义方法名如`findByFirstName`,Spring Data就会自动实现该方法的查询逻辑。
```java
public interface UserRepository extends JpaRepository<User, Long> {
List<User> findByFirstName(String firstName);
}
```
### 2.3.2 常见查询的实现技巧
在实际开发中,常见查询的实现需要考虑到性能和效率。Spring Data提供了一些实现技巧,例如使用@Query注解来编写原生查询、利用Pageable接口进行分页查询、通过@Lock注解优化数据一致性问题等。
```java
public interface CustomerRepository extends PagingAndSortingRepository<Customer, Long> {
@Query("SELECT c FROM Customer c WHERE c.age > ?1")
Page<Customer> findByAgeGreaterThan(int age, Pageable pageable);
}
```
在上述代码中,我们通过@Query注解来实现对客户的查询,同时利用Pageable接口来进行分页处理。这种高级用法使得开发者可以快速应对复杂查询场景。
通过Spring Data提供的这些高级特性,开发者能够以最少的代码来实现强大的数据操作功能。而这些功能不仅仅局限于传统的关系数据库,还扩展到了各种大数据存储解决方案,从而极大地提升了大数据环境下应用开发的效率和质量。
# 3. 拥抱Hadoop:Spring Data在Hadoop生态的应用
### 3.1 Hadoop生态系统简述
#### 3.1.1 Hadoop核心组件介绍
Hadoop是一个由Apache基金会开发的开源分布式存储和计算框架,旨在存储和处理大规模数据。核心组件包括HDFS(Hadoop Distributed File System)、YARN(Yet Another Resource Negotiator)和MapReduce。
- **HDFS**:Hadoop分布式文件系统是Hadoop生态的基础,负责数据的存储。它将大数据集分散存储在集群中的多台机器上,并提供了高吞吐量的数据访问,非常适合于大数据集的应用。
- **YARN**:YARN是一个资源管理平台,负责集群资源管理和任务调度。它允许用户编写自己的数据处理程序,并由YARN提供运行所需资源。
- **MapReduce**:MapReduce是一种编程模型和处理大数据的计算框架,用于并行处理大规模数据集。
通过这三个核心组件的相互配合,Hadoop提供了在分布式环境下处理数据的强大能力。
#### 3.1.2 Hadoop生态系统工具概览
Hadoop生态系统不断扩展,包含许多附加组件和工具,能够支持更加复杂的数据处理任务。主要工具包括:
- **Hive**:一个建立在Hadoop上的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,方便对Hadoop数据进行查询和分析。
- **Pig**:为Hadoop提供了一个高层次的数据流语言和执行框架,称为Pig Latin。它旨在简化MapReduce作业的编写。
- **HBase**:是一个构建在HDFS之上的分布式、可扩展的NoSQL数据库,适用于存储非结构化和半结构化数据。
- **Zookeeper**:是一个开源的分布式服务协调和配置管理系统,用于管理分布式应用的配置信息、命名信息等。
- **Sqoop**:是一个用于高效地在Hadoop和关系数据库、数据仓库间传输大量数据的工具。
Hadoop生态系统提供的这些工具,为开发者提供了灵活的方式来处理和分析大数据。
### 3.2 Spring Data Hadoop的应用实践
#### 3.2.1 Spring Data Hadoop入门
在开始使用Spring Data Hadoop之前,需要确保已经配置了适用于Spring的Hadoop环境。通常情况下,需要配置相关的依赖项以及与Hadoop集群通信的配置文件。
```xml
<!-- POM dependencies for Spring Data Hadoop -->
<dependencies>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-hadoop</artifactId>
<version>最新版本号</version>
</dependency>
</dependencies>
```
一旦添加了依赖项,可以通过Spring Data Hadoop提供的模板类来进行HDFS文件操作。
```java
@Autowired
private FileSystemTemplate fsTemplate;
public void writeData() {
// 创建HDFS路径
Path path = new Path("/user/hadoop/out.txt");
// 打开文件流
FSDataOutputStream out = fsTemplate.create(path);
// 写入数据
out.writeUTF("Hello Hadoop World!");
// 关闭流
out.close();
}
```
以上是一个简单的例子,展示了如何使用Spring Data Hadoop模板来写入数据到HDFS。
#### 3.2

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Java Spring Data,一种用于高效数据访问的强大框架。从初学者到专家级,它涵盖了各种主题,包括:
* Spring Data JPA 学习攻略,快速掌握数据访问技术。
* 高级查询和优化技巧,提升数据访问性能。
* 存储库接口的深入解析,探索代码优先和声明优先方法。
* Spring Data 与 Hibernate 和 MyBatis 的整合,比较性能和最佳实践。
* 分页和排序优化,提高数据处理效率。
* 事务管理,掌握高级事务控制。
* 缓存策略,优化数据访问性能。
* Criteria API,提升查询性能。
* 自定义仓库实现,掌握面向接口编程。
* 扩展机制,构建定制化数据访问模块。
* 微服务架构中的应用,解决分布式数据访问挑战。
* 安全性指南,保障数据访问安全。
* 集成测试实战,从单元测试到集成测试。
* 异步数据访问,提升应用响应性能。
* 大数据环境中的应用,拥抱 Hadoop 和 Spark。
* 事务传播行为详解,掌握事务边界管理。
* 扩展点详解,实现自定义查询方法。
* 与 RESTful 服务构建,最佳实践和案例分析。
* 数据库迁移策略,从 Schema.sql 到 Flyway 的全解析。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
LM324运放芯片揭秘
# 摘要
LM324运放芯片是一款广泛应用于模拟电路设计的四运算放大器集成电路,以其高性能、低成本和易用性受到电路设计师的青睐。本文首先对LM324的基本工作原理进行了深入介绍,包括其内部结构、电源供电需求、以及信号放大特性。随后,详细阐述了LM324在实际应用中的电路设计,包括构建基本的放大器电路和电压比较器电路,以及在滤波器设计中的应用。为了提高设计的可靠性,本文还提供了选型指南和故障排查方法。最后,通过实验项目和案例分析,展示了LM324的实际应用,并对未来发展趋势进行了展望,重点讨论了其在现代电子技术中的融合和市场趋势。
# 关键字
LM324运放芯片;内部结构;电源供电;信号放大;
提升RFID效率:EPC C1G2协议优化技巧大公开
# 摘要
本文全面概述了EPC C1G2协议的重要性和技术基础,分析了其核心机制、性能优化策略以及在不同行业中的应用案例。通过深入探讨RFID技术与EPC C1G2的关系,本文揭示了频率与信号调制方式、数据编码与传输机制以及标签与读取器通信协议的重要性。此外,文章提出了提高读取效率、优化数据处理流程和系统集成的策略。案例分析展示了EPC C1G2协议在制造业、零售业和物流行业中的实际应用和带来的效益。最后,本文展望了EPC C1G2协议的未来发展方向,包括技术创新、标准化进程、面临挑战以及推动RFID技术持续进步的策略。
# 关键字
EPC C1G2协议;RFID技术;性能优化;行业应用;技
【鼎捷ERP T100数据迁移专家指南】:无痛切换新系统的8个步骤
# 摘要
本文详细介绍了ERP T100数据迁移的全过程,包括前期准备工作、实施计划、操作执行、系统验证和经验总结优化。在前期准备阶段,重点分析了数据迁移的需求和环境配置,并制定了相应的数据备份和清洗策略。在实施计划中,本文提出了迁移时间表、数据迁移流程和人员角色分配,确保迁移的顺利进行。数据迁移操作执行部分详细阐
【Ansys压电分析最佳实践】:专家分享如何设置参数与仿真流程

# 摘要
本文系统地探讨了压电分析的基本理论及其在不同领域的应用。首先介绍了压电效应和相关分析方法的基础知识,然后对Ansys压电分析软件及其在压电领域的应用优势进行了详细的介绍。接着,文章深入讲解了如何在Ansys软件中设置压电分析参数,包括材料属性、边界条件、网格划分以及仿真流
【提升活化能求解精确度】:热分析实验中的变量控制技巧
# 摘要
热分析实验是研究材料性质变化的重要手段,而活化能概念是理解化学反应速率与温度关系的基础。本文详细探讨了热分析实验的基础知识,包括实验变量控制的理论基础、实验设备的选择与使用,以及如何提升实验数据精确度。文章重点介绍了活化能的计算方法,包括常见模型及应用,及如何通过实验操作提升求解技巧。通过案例分析,本文展现了理论与实践相结合的实验操作流程,以及高级数据分析技术在活化能测定中的应用。本文旨在为热分析实验和活化能计算提供全面的指导,并展望未来的技术发展趋势。
# 关键字
热分析实验;活化能;实验变量控制;数据精确度;活化能计算模型;标准化流程
参考资源链接:[热分析方法与活化能计算:
STM32F334开发速成:5小时搭建专业开发环境
# 摘要
本文是一份关于STM32F334微控制器开发速成的全面指南,旨在为开发者提供从基础设置到专业实践的详细步骤和理论知识。首先介绍了开发环境的基础设置,包括开发工具的选择与安装,开发板的设置和测试,以及环境的搭建。接着,通过理论知识和编程基础的讲解,帮助读者掌握STM32F334微控制器的核心架构、内存映射以及编程语言应用。第四章深入介绍了在专业开发环境下的高
【自动控制原理的现代解读】:从经典课件到现代应用的演变
# 摘要
自动控制原理是工程领域中不可或缺的基础理论,涉及从经典控制理论到现代控制理论的广泛主题。本文首先概述了自动控制的基本概念,随后深入探讨了经典控制理论的数学基础,包括控制系统模型、稳定性的数学定义、以及控制理论中的关键概念。第三章侧重于自动控制系统的设计与实现,强调了系统建模、控制策略设计,以及系统实现与验证的重要性。第四章则
自动化测试:提升收音机测试效率的工具与流程

# 摘要
随着软件测试行业的发展,自动化测试已成为提升效率、保证产品质量的重要手段。本文全面探讨了自动化测试的理论基础、工具选择、流程构建、脚本开发以及其在特定场景下的应用。首先,我们分析了自动化测试的重要性和理论基础,接着阐述了不同自动化测试工具的选择与应用场景,深入讨论了测试流程的构建、优化和管理。文章还详细介绍了自动化测试脚本的开发与
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )