PyTorch GPU加速秘术:自定义层计算效率的突破方法


Pytorch: 自定义网络层实例
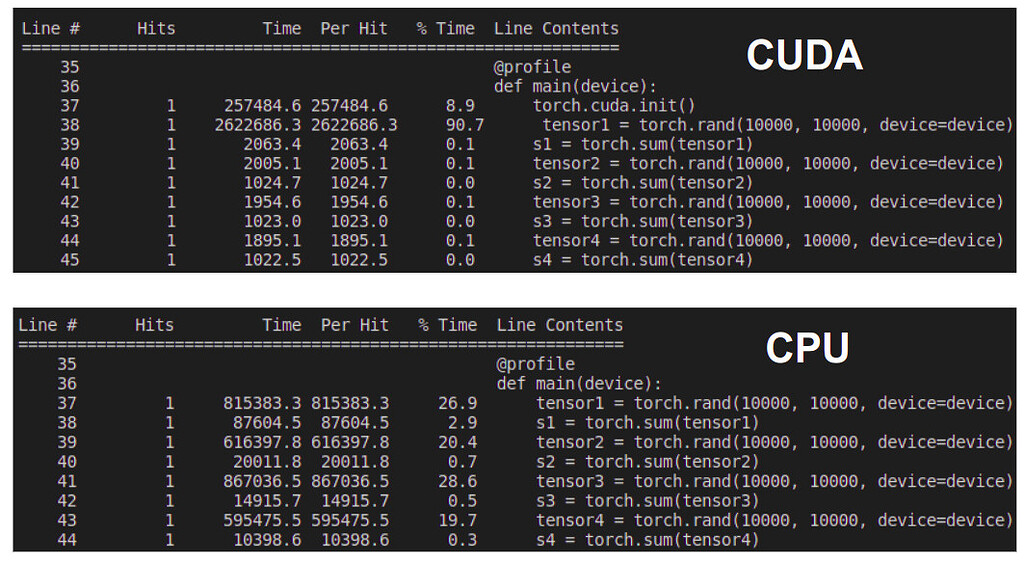
1. PyTorch GPU加速基础知识
随着深度学习模型的日益复杂和数据量的不断增加,GPU加速已经成为提高训练效率的关键技术之一。PyTorch作为当下流行的深度学习框架,它如何与GPU计算相结合,以及如何在PyTorch中使用CUDA和cuDNN来加速模型的训练,是本章的重点。
1.1 GPU计算与PyTorch的结合
GPU加速的核心在于其并行处理能力,能够在短时间内处理大量数据。PyTorch框架通过抽象出计算图(computational graph),将复杂操作分解为多个小的步骤,然后在GPU上执行这些步骤以实现加速。
1.2 CUDA和cuDNN在PyTorch中的作用
CUDA(Compute Unified Device Architecture)是NVIDIA推出的一种用于在其GPU上执行通用计算的技术。PyTorch使用CUDA来调用GPU资源进行计算。而cuDNN(CUDA Deep Neural Network library)是NVIDIA针对深度神经网络的一系列优化库,它能够进一步加速深度学习框架中的卷积、池化等操作。
- import torch
- # 检查是否有可用的GPU,以及如何利用
- device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
1.3 PyTorch中的设备和张量类型
在PyTorch中,模型、数据和其他张量对象可以在CPU或者一个或多个GPU上创建和操作。通过将数据移动到GPU(使用 .to(device) 方法),可以显著提高计算速度。在定义神经网络时,应确保网络的所有参数和计算都支持GPU操作。
- # 将张量移动到GPU
- tensor = torch.randn(3, 3).to(device)
- print(tensor.device)
通过本章的学习,你将掌握在PyTorch中启用和利用GPU加速的基础知识,为后续深入学习和优化GPU使用打下坚实的基础。
2. PyTorch自定义层的理论与实践
2.1 理解PyTorch中的自定义层
2.1.1 自定义层的创建和使用
在深度学习框架中,自定义层是构建新模型或扩展已有模型功能的重要手段。PyTorch中创建自定义层的基本方法是继承torch.nn.Module类,并实现其__init__和forward方法。
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
- class CustomLayer(nn.Module):
- def __init__(self):
- super(CustomLayer, self).__init__()
- # 在此初始化自定义层的参数
- self.weight = nn.Parameter(torch.Tensor(10, 10))
- self.bias = nn.Parameter(torch.Tensor(10))
- def forward(self, x):
- # 实现前向传播
- x = F.linear(x, self.weight, self.bias)
- return x
在上面的代码中,CustomLayer类定义了一个具有权重和偏置参数的全连接层。forward方法描述了输入数据如何通过该层进行前向计算。要使用这个自定义层,我们可以在模型定义中引入这个类的实例:
- class MyModel(nn.Module):
- def __init__(self):
- super(MyModel, self).__init__()
- self.custom_layer = CustomLayer()
- def forward(self, x):
- x = self.custom_layer(x)
- return x
2.1.2 自定义层与PyTorch内置层的比较
自定义层和PyTorch内置层相比,增加了灵活性,但是可能会牺牲一些性能。内置层是高度优化过的,对于特定的操作比如卷积和池化有专门的硬件加速支持。
- class MyModelWithBuiltIn(nn.Module):
- def __init__(self):
- super(MyModelWithBuiltIn, self).__init__()
- self.built_in_layer = nn.Linear(10, 10)
- def forward(self, x):
- x = self.built_in_layer(x)
- return x
内置层的实例化和使用都比自定义层简单,因为大部分工作都是在底层进行优化的。
2.2 实践:自定义层的基本操作
2.2.1 创建一个简单的自定义层
创建自定义层的过程中需要关注参数初始化、前向传播和可能的反向传播(梯度计算)。在实现自定义层时,通常会使用torch.nn.Parameter来定义可训练的参数。这样这些参数在反向传播过程中能够自动求导并更新。
- class SimpleCustomLayer(nn.Module):
- def __init__(self):
- super(SimpleCustomLayer, self).__init__()
- self.weight = nn.Parameter(torch.Tensor(1))
- self.bias = nn.Parameter(torch.Tensor(1))
- self.reset_parameters()
- def reset_parameters(self):
- nn.init.constant_(self.weight, 0.01)
- nn.init.constant_(self.bias, 0)
- def forward(self, x):
- return x * self.weight + self.bias
在上面的例子中,SimpleCustomLayer实现了一个简单的缩放和平移操作。这样的操作在某些情况下很有用,比如在神经网络中的特征缩放。
2.2.2 自定义层在模型中的应用示例
将自定义层集成到模型中需要确保输入输出尺寸兼容、梯度正确计算,并且在训练和评估模式下行为一致。
- class ModelWithSimpleLayer(nn.Module):
- def __init__(self):
- super(ModelWithSimpleLayer, self).__init__()
- self.simple_layer = SimpleCustomLayer()
- def forward(self, x):
- x = self.simple_layer(x)
- return x
模型中集成自定义层后,我们就可以像使用其他PyTorch模块一样使用它了,例如在数据预处理、模型训练和验证等环节。
2.2.3 总结
在这一小节中,我们了解了如何创建和使用PyTorch中的自定义层。通过继承torch.nn.Module类,我们能够创建出具有特定功能的层,并且与内置层进行比较。在实践中,创建自定义层需要注意参数初始化和确保前向传播逻辑的正确实现。通过这些操作,我们可以构建出更加

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PyTorch数据增强技术:泛化能力提升的10大秘诀
BD3201电路维修全攻略:从入门到高级技巧的必备指南
【功能完整性检查术】:保险费率计算软件的功能测试全解
【VS2010-MFC实战秘籍】:串口数据波形显示软件入门及优化全解析
PICKIT3故障无忧:24小时快速诊断与解决常见问题
【代码优化过程揭秘】:专家级技巧,20个方法让你的程序运行更快
Java开发者必备:Flink高级特性详解,一文掌握核心技术
【库卡机器人效率优化宝典】:外部运行模式配置完全指南


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )