数据科学探索:Anaconda数据库应用的深度分析与实践
发布时间: 2024-12-09 23:36:10 阅读量: 4 订阅数: 19 

Python数据分析详解与应用实践
# 1. Anaconda平台概述及其数据科学地位
## 1.1 Anaconda简介
Anaconda是一个开源的Python发行版本,它提供了包管理器Conda以及一系列预装的数据科学相关的库。Anaconda使得数据科学和机器学习的实践更加便捷,大幅降低了环境配置和依赖管理的复杂性。
## 1.2 数据科学的挑战与Anaconda的应对
数据科学通常需要处理多变的依赖和复杂的环境问题。Anaconda通过其强大的包管理和环境隔离机制,帮助数据科学家快速搭建工作环境,并确保项目的可复现性和团队间的高效协作。
## 1.3 Anaconda在行业中的地位
Anaconda已经成为数据科学、机器学习和人工智能领域里最受欢迎的平台之一。由于其广泛的用户基础和丰富的生态系统,Anaconda成为了初学者进入数据科学领域的桥梁,同时也是专业人员进行高级数据分析不可或缺的工具。
# 2. Anaconda数据库基础理论与技术
Anaconda是一个流行的Python发行版,它专注于数据科学和机器学习领域。它提供了一个简单易用的平台,用于安装和管理数据科学相关的包和环境。Anaconda数据库是围绕Conda这个包管理器构建的,它能够方便用户创建隔离的环境来处理不同项目依赖的库。本章将详细介绍Anaconda的数据库核心概念、Conda包管理器,以及如何使用Jupyter Notebook进行交互式的数据分析。
### 2.1 Anaconda数据库的核心概念
Anaconda数据库并不是一个传统意义上的数据库系统,比如MySQL或PostgreSQL。它是构建在Conda环境之上的包管理系统。这意味着它管理的是数据科学软件包及其依赖关系,而不仅仅是数据本身。
#### 2.1.1 数据库架构与组件
Anaconda数据库架构是基于Conda环境和包的管理,这些包通常是用于科学计算、数据分析和机器学习的Python库。其主要组件包括:
- **Conda**: 一个用于管理包和环境的命令行工具。
- **Anaconda仓库**: 存储了数以千计的开源包,以及这些包的预编译二进制文件。
- **环境**: Conda中可以创建多个隔离的环境,每个环境拥有自己的Python版本和包集合,互不干扰。
#### 2.1.2 数据存储与管理机制
Anaconda平台采用轻量级的数据存储方式,主要是通过Conda管理的包和环境来存储数据科学相关的代码和环境配置。Conda允许用户创建不同的环境,每一个环境都可以看作是一个轻量级的“虚拟机”,其中包含了数据科学家所需的所有依赖包。此外,Conda还提供了强大的依赖解析功能,确保环境之间的包不会发生冲突。
### 2.2 Anaconda的包管理器Conda
Conda是Anaconda生态中最重要的组成部分之一,它不仅是一个包管理器,也是一个环境管理工具。它允许用户快速安装、更新和管理数以千计的包和依赖关系。
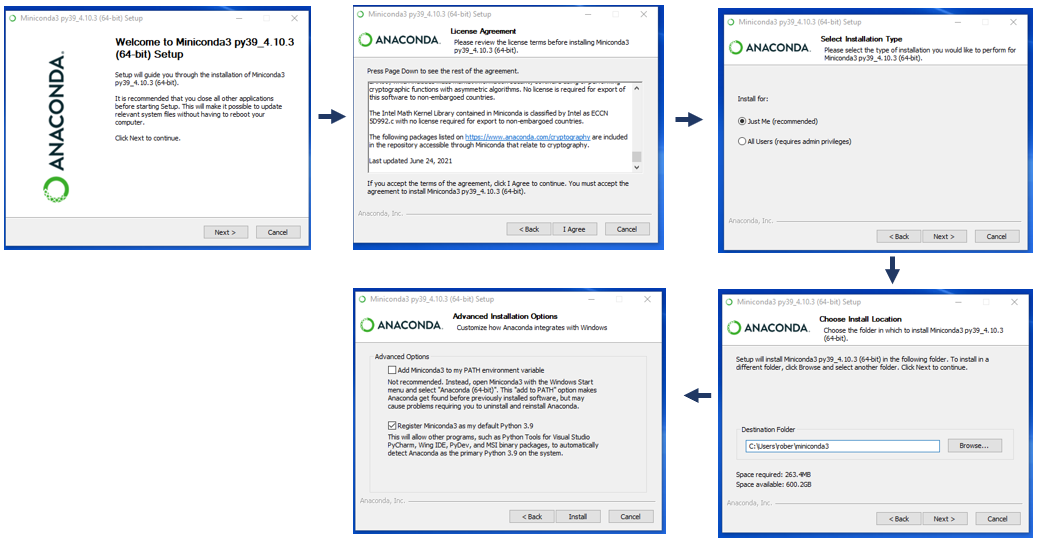
#### 2.2.1 Conda的安装与配置
安装Conda非常简单。用户可以从Anaconda的官方网站下载适合不同操作系统的安装包。安装过程通常只需要遵循几个步骤,如选择安装路径、接受许可协议等。安装完成后,Conda会在用户的系统路径中注册其二进制文件,用户可以通过命令行来使用它。
#### 2.2.2 环境的创建、管理和导出
创建Conda环境可以使用`conda create`命令,后接环境名称和所需的包。例如,创建一个名为`myenv`的环境,并安装Python和pandas包:
```bash
conda create -n myenv python pandas
```
使用`conda activate myenv`可以激活环境,`conda deactivate`则用于退出当前环境。通过`conda list`可以查看当前环境中安装的包。
环境的导出可以使用`conda env export`命令,此命令会导出当前环境的所有依赖关系到一个`yaml`文件中,例如:
```bash
conda env export > environment.yaml
```
之后可以使用`conda env create -f environment.yaml`命令在其他计算机上重建相同的环境。
### 2.3 Anaconda的Jupyter Notebook
Jupyter Notebook是一个开源的Web应用程序,允许用户创建和分享包含代码、可视化和解释性文本的文档。它非常适合数据科学工作,因为它支持交互式编程。
#### 2.3.1 Jupyter Notebook的安装和使用
安装Jupyter Notebook非常简单,通常与安装Anaconda一起完成。它与Conda环境集成,因此可以从特定的Conda环境启动Jupyter Notebook,确保了环境的一致性。
启动Jupyter Notebook使用`jupyter notebook`命令,这将打开默认浏览器并导航到本地服务器地址。在该界面中,用户可以创建新的Notebook文件,或打开已有的`.ipynb`文件。
#### 2.3.2 Notebook的扩展功能和插件
Jupyter Notebook具有很强的扩展性,开发者社区为其提供了丰富的插件。例如,为了更好地进行数据分析,可以安装nb_conda插件来在Notebook内直接管理Conda环境。插件的安装很简单:
```bash
conda install -c anaconda-nb-extensions nb_conda
```
安装后,Notebook界面会出现一个新的“Conda”标签页,允许用户直接在Notebook中创建和管理环境。
通过本章节的介绍,我们已经对Anaconda数据库的核心概念、Conda包管理器以及Jupyter Notebook有了深入的了解。接下来的章节中,我们将探索在Anaconda环境下进行数据分析的实际操作和技巧。
# 3. Anaconda环境下的数据分析实践
数据分析是数据科学的核心环节,它涉及到数据的探索、清洗、处理、可视化、统计分析以及机器学习。Anaconda平台为数据分析师提供了一个高效便捷的工作环境,大大简化了数据分析流程。在本章节中,我们将深入探讨如何在Anaconda环境下进行数据清洗、数据可视化以及初步的统计分析与机器学习。
## 3.1 数据清洗与预处理
数据分析的第一步通常是清洗和预处理数据,因为真实世界的数据往往包含错误、不一致性和缺失值。Pandas库是Python中用于数据分析的重要工具,它提供了一整套数据结构和操作工具,让我们能够轻松地处理各种数据。
### 3.1.1 利用Pandas进行数据操作
Pandas基于NumPy构建,提供了丰富的数据结构和操作函数,特别是它强大的DataFrame对象,可以轻松地处理表格数据。下面我们将通过一段代码来展示如何使用Pandas进行数据操作。
```python
import pandas as pd
# 读取数据
df = pd.read_csv('data.csv')
# 显示前5行数据
print(df.head())
# 数据基本描述统计
print(df.describe())
# 选择特定列
selected_columns = df[['column1', 'column2']]
# 数据过滤,比如选择某个列值大于某个值的行
filtered_data = df[df['column1'] > 100]
# 对数据进行排序
sorted_data = df.sort_values(by='column1', ascending=False)
# 删除缺失值
cleaned_data = df.dropna()
```
以上代码展示了如何读取数据,查看数据的基本情况,选择特定的列,过滤数据,以及如何删除缺失值等操作。每一步都有其特定的用途,为后续的数据分析打下了良好的基础。
### 3.1.2 缺失值处理和异常值检测
数据清洗过程中,缺失值和异常值的处理尤为关键。它们可能会对分析结果产生负面影响。Pandas库提供了一系列处理缺失值的工具,如`fillna`、`isnull`、`dropna`等。异常值检测通常依赖于数据分布的统计特性,比如可以使用标准差等方法。下面的代码展示了如何处理缺失值和检测异常值。
```python
# 填充缺失值,例如用0填充
df_filled = df.fillna(0)
# 检测缺失值
missing_values = df.is
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Anaconda 环境下数据库连接和使用的各个方面。从初学者指南到高级教程,它涵盖了各种数据库,包括 PostgreSQL、SQL Server、MongoDB、Cassandra 和 Redis。文章提供了详细的说明、代码示例和最佳实践,帮助读者建立高效的数据连接、优化查询、处理数据并集成 NoSQL 数据库。此外,专栏还介绍了 Jupyter Notebook 中的交互式连接技巧,以及 Hadoop 和 Spark 在 Anaconda 环境中的大数据连接策略。通过本专栏,读者将掌握在 Anaconda 环境中有效连接、使用和优化数据库所需的知识和技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【RTCM 3.3协议的10大秘密】:精通实时定位技术的终极指南

参考资源链接:[RTCM 3.3协议详解:全球卫星导航系统差分服务最新标准](https://wenku.csdn.net/doc/7mrszjnfag?spm=1055.2635.3001.10343)
# 1. RTCM 3.3协议概述
RTCM 3.3是实时差分全球定位系统(GNSS
【深度学习的交通预测力量】:构建上海轨道交通2030的智能预测模型

参考资源链接:[上海轨道交通规划图2030版-高清](https://wenku.csdn.net/doc/647ff0fc
升级你的IS903:固件更新全攻略,提升性能与稳定性的终极指南

参考资源链接:[银灿IS903优盘完整的原理图](https://wenku.csdn.net/doc/6412b558be7fbd1778d42d25?spm=1055.2635.3001.10343)
# 1. IS903固件更新的必要性和好处
## 理解固件更新的重要性
固件更新,对于任何智能设备来说,都是一个关键的维护步骤。IS903作为一款高性能的设备,其固件更新不仅仅是为了修
ROST软件高级用户必看:全面掌握工具每一个细节的独家技巧
参考资源链接:[ROST内容挖掘系统V6用户手册:功能详解与操作指南](https://wenku.csdn.net/doc/5c20fd2fpo?spm=1055.2635.3001.10343)
# 1. ROST软件概述与安装指南
## ROST
【cx_Oracle权威指南】:版本升级、环境配置与最佳实践案例解析

参考资源链接:[cx_Oracle使用手册](https://wenku.csdn.net/doc/6476de87543f84448808af0d?spm=1055.2635.3001.10343)
# 1. cx_Oracle简介与历史回顾
cx_Oracle 是一个流行的 Python 扩展,用于访问 Oracle 数据库。它提供了一个接口,允许 Python 程序
ZMODEM vs XMODEM vs YMODEM:三者的优劣比较分析及选型建议

参考资源链接:[ZMODEM传输协议深度解析](https://wenku.csdn.net/doc/647162cdd12cbe7ec3ff9be7?spm=1055.2635.3001.10343)
# 1. ZMODEM、XMODEM与YMODEM协议概述
在现代数据通
ARINC664协议的可靠性与安全性:详细案例分析与实战应用

参考资源链接:[AFDX协议/ARINC664中文详解:飞机数据网络](https://wenku.csdn.net/doc/66azonqm6a?spm=1055.2635.3001.10343)
# 1. ARINC664协议概述
ARINC664协议,作为一种在航空电子系统中广泛应用的数据通信标准,已经成为现代飞机通信网络的核心技术之一。它不仅确保了
HEC-GeoHMS在洪水风险评估中的应用实战:案例分析与操作技巧

参考资源链接:[HEC-GeoHMS操作详析:ArcGIS准备至流域处理全流程](https://wenku.csdn.net/doc/4o9gso36xa?spm=1055.2635.3001.10343)
# 1. HEC-GeoHMS概述与洪水风险评估基础
## 1.1 HEC-GeoHMS简介
HEC-GeoHMS是一个强大的GIS工具,用于洪水风险评估和洪水模型的前期准备工作。它是HEC-HMS(Hydro
MIPI CSI-2信号传输精髓:时序图分析专家指南
参考资源链接:[mipi-CSI-2-标准规格书.pdf](https://wenku.csdn.net/doc/64701608d12cbe7ec3f6856a?spm=1055.2635.3001.10343)
# 1. MIPI CSI-2信号传输基础
MIPI CSI-2 (Mobile Industry Processor
【系统维护】创维E900 4K机顶盒:更新备份全攻略,保持最佳状态

参考资源链接:[创维E900 4K机顶盒快速配置指南](https://wenku.csdn.net/doc/645ee5ad543f844488898b04?spm=1055.2635.3001.10343)
# 1. 创维E900 4K机顶盒概述
## 简介
创维E900 4K机顶盒是一款集成了最新技术的家用多媒体设备,支持4K超高清视频播放和多
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )