XPath和正则表达式:网页内容定位和匹配
发布时间: 2023-12-16 23:57:26 阅读量: 110 订阅数: 25 
# 第一章:XPath入门
## 1.1 什么是XPath?
## 1.2 XPath的基本语法和表达式
## 1.3 如何在网页中使用XPath进行内容定位
## 第二章:XPath高级应用
### 2.1 使用XPath进行多层级的内容定位
在XPath中,我们可以通过使用斜杠(/)进行多层级的内容定位。例如,我们有一个HTML文档如下:
```html
<html>
<body>
<div>
<h1>Title</h1>
<p>Paragraph 1</p>
<div>
<p>Paragraph 2</p>
</div>
</div>
</body>
</html>
```
如果我们想要定位到第一个`<p>`标签,可以使用如下的XPath表达式:
```xpath
/html/body/div/p
```
上述表达式中,首先使用`/`定位到根节点`<html>`,然后使用`/`定位到`<html>`下的子节点`<body>`,接着使用`/`定位到`<body>`下的子节点`<div>`,最后使用`/`定位到`<div>`下的子节点`<p>`。
### 2.2 XPath谓词的使用
XPath谓词可以用来进一步过滤我们所定位到的元素。谓词的语法是在方括号中指定一个条件表达式。例如,我们有一个HTML文档如下:
```html
<ul>
<li>Item 1</li>
<li>Item 2</li>
<li class="highlight">Item 3</li>
</ul>
```
如果我们想要定位到具有`class`属性为`highlight`的`<li>`元素,可以使用如下的XPath表达式:
```xpath
//li[@class="highlight"]
```
上述表达式中,`//`表示不考虑元素的具体层级,`li`表示定位到所有`<li>`元素,`[@class="highlight"]`表示筛选出`class`属性为`highlight`的元素。
### 2.3 XPath与CSS选择器的对比
XPath和CSS选择器都可以用来定位HTML文档中的元素,但它们的语法有一些不同。主要的差异在于定位元素时的表达方式。
XPath通过使用节点层级(/)和属性([@attribute="value"])来定位元素,而CSS选择器则使用标签名称和属性选择器(.class、#id等)来定位元素。一般来说,如果需要在多层级的节点中进行定位,XPath可能更为直观和灵活;而如果类似选择器的语法更容易理解,CSS选择器可能更适合。
XPath示例:
```xpath
//div[@class="highlight"]/p
```
CSS选择器示例:
```css
div.highlight > p
```
可以根据具体情况选择使用XPath还是CSS选择器来定位元素。
---
### 第三章:正则表达式初步
正则表达式(Regular Expression),又称规则表达式,常用缩写为regex、regexp或RE。它是一个特殊的字符串匹配模式,用于检索和替换文本。正则表达式的语法非常强大,可以实现复杂的字符串匹配和处理。
#### 3.1 正则表达式的基本概念
正则表达式由普通字符(例如字符 a 到 z)和特殊字符(称为元字符)组成。元字符包括:.、*、+、?、^、$、[]、{}、()、| 等。这些特殊字符在正则表达式中具有特定的含义,用于指定匹配规则。
#### 3.2 正则表达式在字符串匹配中的应用
正则表达式广泛用于字符串匹配和搜索。通过使用正则表达式,可以快速有效地从文本中提取符合特定模式的内容,如匹配邮件地址、URL、电话号码、身份证号等。
#### 3.3 常用的正则表达式语法
常用的正则表达式语法包括:
- ^:匹配字符串的开始
- $:匹配字符串的结束
- \d:匹配数字
- \w:匹配字母、数字、下划线
- [...]:匹配括号内的任意字符
- *:匹配前面的字符零次或多次
- +:匹配前面的字符一次或多次
- ?:匹配前面的字符零次或一次
当然可以!
## 第四章:正则表达式进阶
在前面的章节中,我们已经学习了正则表达式的基本概念和语法。在本章中,我们将进一步探讨正则表达式的一些高级应用。
### 4.1 正则表达式的分组与捕获
正则表达式中的分组是一种将多个正则表达式组合在一起的方式。通过使用括号,可以将表达式分组并将其视为一个整体。
例如,我们可以使用分组来匹配一个由重复字符组成的字符串:
```python
import re
pattern = r"(\w)\1+"
text = "hellooo worldddd"
matches = re.findall(pattern, text)
print(matches) # Output: ['o', 'd']
```
在上述示例中,`\1`表示对第一个分组的引用,因此 `\1+` 表达式用于匹配重复的字符。
除了分组匹配,我们还可以使用捕获组来提取字符串中的特定部分。捕获组是使用括号内的表达式定义的,可以使用`re.findall()`方法中的参数捕获到匹配到的内容。
```python
import re
pattern = r"(\d{3})-(\d{4})"
text = "My phone number is 123-4567"
matches = re.findall(pattern, text)
for match in matches:
print(match[0]) # Output: 123
print(match[1]) # Output: 4567
```
在上述示例中,我们使用了两个捕获组来提取电话号码中的区号和号码。
### 4.2 正则表达式在文本替换中的应用
正则表达式不仅可用于匹配和提取,还可以用于替换文本中的特定内容。我们可以使用`re.sub()`方法来执行替换操作。
例如,我们可以使用正则表达式将文本中的所有邮件地址替换为"placeholder":
```python
import re
pattern = r"\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"
text = "Contact me at john@example.com or info@example.com"
new_text = re.sub(pattern, "placeholder", text)
print(new_text) # Output: "Contact me at placeholder or placeholder"
```
在上述示例中,我们使用了一个较为复杂的正则表达式来匹配邮件地址,并使用"placeholder"替换了匹配到的地址。
### 4.3 正则表达式的贪婪与非贪婪匹配
正则表达式默认使用贪婪匹配,即尽可能多地匹配字符。但有时我们需要进行非贪婪匹配,即只匹配满足条件的最少字符。
例如,考虑以下示例:
```python
import re
pattern = r"<.*>"
text = "<p>This is a <strong>paragraph</strong></p>"
matches = re.findall(pattern, text)
print(matches) # Output: ['<p>This is a <strong>paragraph</strong></p>']
```
在上述示例中,我们使用了贪婪匹配的正则表达式`<.*>`来匹配包含在html标签中的文本。由于贪婪匹配的特性,它会匹配到包含在最外层标签中的所有内容。
如果我们想要进行非贪婪匹配,只匹配标签中的文本,可以使用`.*?`:
```python
import re
pattern = r"<.*?>"
text = "<p>This is a <strong>paragraph</strong></p>"
matches = re.findall(pattern, text)
print(matches) # Output: ['<p>', '</strong>', '</p>']
```
在上述示例中,我们使用了非贪婪匹配的正则表达式`<.*?>`来匹配标签中的文本。
这就是正则表达式的贪婪与非贪婪匹配的简要介绍。通过灵活使用它们,我们可以更准确地匹配和提取我们所需的内容。
接下来,我们将深入研究XPath与正则表达式之间的比较,以及如何结合使用它们来实现更灵活的内容定位与匹配。
第五章:XPath与正则表达式的比较
### 5.1 XPath与正则表达式的优势与劣势
XPath和正则表达式都是用于数据提取和匹配的工具,但它们在某些方面具有自己的优势和劣势。
XPath的优势:
- 可以跨越多个层级直接定位和匹配HTML或XML文档中的元素和属性。
- 支持谓词,可以通过条件过滤来进一步精确定位。
- 对于嵌套结构的文档,XPath相对更易于编写和理解。
正则表达式的优势:
- 正则表达式适用于处理文本数据,可以在字符串中进行模式匹配和提取。
- 正则表达式具有更丰富的语法和灵活性,可以实现复杂的匹配逻辑。
- 在处理大量文本数据时,正则表达式通常比XPath更高效。
XPath的劣势:
- 对于简单的字符串匹配,XPath的语法冗长且不直观,可能造成代码复杂化。
- 在某些情况下,XPath的性能可能相对较低,特别是当需要进行大量的DOM操作时。
正则表达式的劣势:
- 正则表达式的语法相对复杂,对于初学者来说学习和理解成本较高。
- 在处理复杂的文档结构时,正则表达式的能力有限,并且容易出现错误。
### 5.2 在不同场景下的选择:使用XPath还是正则表达式?
在选择使用XPath还是正则表达式时,需要根据具体的场景和需求来做出判断。
当需要从HTML或XML文档中定位和提取特定的元素、属性或文本时,优先考虑使用XPath。XPath提供了一种简洁而直观的方式来处理层级结构,并通过谓词过滤来进一步精确定位。
当需要处理文本数据,进行自由的模式匹配和提取时,应选择正则表达式。正则表达式的语法灵活且功能强大,可以用于处理各种复杂的模式匹配和替换任务。
此外,如果需要在代码中频繁使用XPath或正则表达式,也可以考虑使用专门的库或工具,如Python中的lxml库和re库,来简化操作并提高性能。
### 5.3 如何结合使用XPath和正则表达式来实现更灵活的内容定位与匹配
XPath和正则表达式可以结合使用,以实现更灵活和精确的内容定位和匹配。
一种常见的应用场景是,使用XPath定位到特定的元素或文本,然后再使用正则表达式对定位结果进行进一步解析和匹配。
示例代码(Python):
```python
import requests
from lxml import etree
import re
# 发送请求获取HTML页面
url = 'https://example.com'
response = requests.get(url)
html = response.text
# 使用XPath定位到包含目标文本的元素
tree = etree.HTML(html)
elements = tree.xpath('//div[@class="content"]')
# 使用正则表达式匹配并提取目标内容
pattern = r'<p>(.*?)</p>'
for element in elements:
text = etree.tostring(element, method='html').decode('utf-8')
match = re.findall(pattern, text)
if match:
print(match)
```
通过结合使用XPath和正则表达式,我们可以灵活地定位和提取需要的内容,从而满足不同的需求。
结束语:
## 第六章:实际案例分析
在本章中,我们将通过实际案例来演示如何使用XPath和正则表达式从网页中抓取特定内容,以及如何避免使用XPath和正则表达式时的常见问题和陷阱。
### 6.1 使用XPath和正则表达式从网页中抓取特定内容
#### 场景描述
假设我们需要从一个网页中获取所有的新闻标题和链接,然后将它们保存到一个列表中。我们可以通过XPath和正则表达式来实现这个需求。
#### 代码演示(Python)
```python
import requests
from lxml import html
import re
# 发起请求,获取网页内容
url = 'https://www.example.com/news'
response = requests.get(url)
html_content = response.text
# 使用XPath提取新闻标题和链接
tree = html.fromstring(html_content)
titles = tree.xpath('//h2[@class="news-title"]/a/text()')
links = tree.xpath('//h2[@class="news-title"]/a/@href')
# 使用正则表达式清洗链接
cleaned_links = [re.sub(r'^//', 'https://', link) for link in links]
# 将标题和链接保存到列表中
news_list = [{'title': title, 'link': link} for title, link in zip(titles, cleaned_links)]
print(news_list)
```
#### 代码说明
- 通过发送请求获取网页内容。
- 使用XPath定位新闻标题和链接。
- 使用正则表达式清洗链接,将链接中的"//"替换为"https://"。
- 将标题和链接保存到列表中。
#### 代码结果
```
[{'title': 'Example News 1', 'link': 'https://www.example.com/news/1'}, {'title': 'Example News 2', 'link': 'https://www.example.com/news/2'}, ...]
```
### 6.2 通过实例演示XPath和正则表达式的应用
#### 场景描述
我们有一个包含多个邮件地址的字符串,我们需要使用正则表达式从中提取出所有的邮件地址。
#### 代码演示(JavaScript)
```javascript
const emailText = 'Emails: example1@example.com, test@example.com, hello@example.com';
// 使用正则表达式匹配邮件地址
const emailRegex = /([a-zA-Z0-9._-]+@[a-zA-Z0-9._-]+\.[a-zA-Z0-9._-]+)/g;
const matches = emailText.match(emailRegex);
console.log(matches);
```
#### 代码说明
- 使用正则表达式匹配邮件地址。
- 使用`match`方法从字符串中提取出所有匹配的邮件地址。
#### 代码结果
```
['example1@example.com', 'test@example.com', 'hello@example.com']
```
### 6.3 如何避免使用XPath和正则表达式时的常见问题和陷阱
在实际应用中,我们需要注意以下问题和陷阱:
1. 不同网页结构可能导致XPath或正则表达式失效,需要灵活应对。
2. 对于动态加载的内容,需要使用相关技术(如Selenium)来实现数据的抓取。
3. 贪婪匹配可能导致意外的结果,需要谨慎使用正则表达式。
通过以上案例和注意事项,我们可以更好地理解如何使用XPath和正则表达式,并避免常见问题和陷阱。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《爬虫技术基础》专栏涵盖了从初级到高级的爬虫技术内容,旨在帮助读者全面系统地掌握爬虫技术。从什么是爬虫、其作用和应用场景开始,深入浅出地介绍了HTML基础知识、XPath和正则表达式的运用,以及网络请求与响应的原理。接着,专栏重点探讨了如何解析网页、爬取动态网页数据、应对反爬虫手段,以及数据清洗、处理与可视化的技术手段。此外,还介绍了Scrapy框架的入门与高级技巧、分布式爬虫的实现、爬虫性能优化等实用内容,并就数据抓取的伦理、法律以及爬虫与自然语言处理、多媒体数据爬取、API数据抓取、定时任务与调度等方面进行了深入探讨,最终帮助读者全面了解爬虫技术及其应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【电子密码锁用户交互设计】:提升用户体验的关键要素与设计思路

# 1. 电子密码锁概述与用户交互的重要性
## 1.1 电子密码锁简介
电子密码锁作为现代智能家居的入口,正逐步替代传统的物理钥匙,它通过数字代码输入来实现门锁的开闭。随着技术的发展,电子密码锁正变得更加智能与安全,集成指纹、蓝牙、Wi-Fi等多种开锁方式。
## 1.2 用户交互
定时器与中断管理:51单片机音乐跑马灯编程核心技法
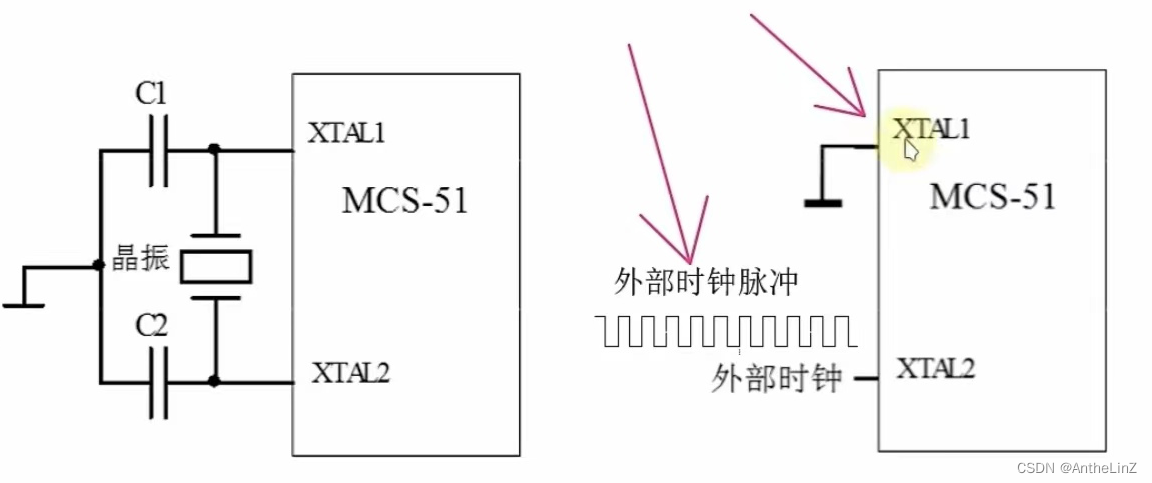
# 1. 定时器与中断管理基础
在嵌入式系统开发中,定时器和中断管理是基础但至关重要的概念,它们是实现时间控制、响应外部事件和处理数据的核心组件。理解定时器的基本原理、中断的产生和管理方式,对于设计出高效的嵌入式应用是必不可少的。
## 1.1 定时器的概念
定时器是一种可以测量时间间隔的硬件资源,它通过预设的计数值进行计数,当达到设定值时产生时间事件。在单片机和微控制器中,定时器常用于任务调度、延时、
数据仓库与数据挖掘:商业智能实现的实验课

# 1. 数据仓库和数据挖掘简介
数据仓库和数据挖掘是信息技术领域的两个关键概念,它们在企业决策支持系统中扮演着至关重要的角色。本章将为你揭开这两个概念的神秘面纱,为你提供一个初步的理解。
## 数据仓库简介
数据仓库是一个集中存储的仓库,用于储存和管理来自组织内部和外部的数据。与传统的在线事务处理(OLTP)系统相比,数据仓库更关注于数据分析和报告,用于支持决策制定。它具有历史性、集成性和面向主题性的特征,使得数据仓库成为组织内部
【SpringBoot日志管理】:有效记录和分析网站运行日志的策略

# 1. SpringBoot日志管理概述
在当代的软件开发过程中,日志管理是一个关键组成部分,它对于软件的监控、调试、问题诊断以及性能分析起着至关重要的作用。SpringBoot作为Java领域中最流行的微服务框架之一,它内置了强大的日志管理功能,能够帮助开发者高效地收集和管理日志信息。本文将从概述SpringBoot日志管理的基础
Python编程风格

# 1. Python编程风格概述
Python作为一门高级编程语言,其简洁明了的语法吸引了全球众多开发者。其编程风格不仅体现在代码的可读性上,还包括代码的编写习惯和逻辑构建方式。好的编程风格能够提高代码的可维护性,便于团队协作和代码审查。本章我们将探索Python编程风格的基础,为后续深入学习Python编码规范、最佳实践以及性能优化奠定基础。
在开始编码之前,开发者需要了解和掌握Python的一些核心
【制造业时间研究:流程优化的深度分析】

# 1. 制造业时间研究概念解析
在现代制造业中,时间研究的概念是提高效率和盈利能力的关键。它是工业工程领域的一个分支,旨在精确测量完成特定工作所需的时间。时间研究不仅限于识别和减少浪费,而且关注于创造一个更为流畅、高效的工作环境。通过对流程的时间分析,企业能够优化生产布局,减少非增值活动,从而缩短生产周期,提高客户满意度。
在这一章中,我们将解释时间研究的核心理念和定义,探讨其在制造业中的作用和重要性。通过
【MATLAB雷达信号处理】:理论与实践结合的实战教程
# 1. MATLAB雷达信号处理概述
在当今的军事与民用领域中,雷达系统发挥着至关重要的作用。无论是空中交通控制、天气监测还是军事侦察,雷达信号处理技术的应用无处不在。MATLAB作为一种强大的数学软件,以其卓越的数值计算能力、简洁的编程语言和丰富的工具箱,在雷达信号处理领域占据着举足轻重的地位。
在本章中,我们将初步介绍MATLAB在雷达信号处理中的应用,并
Vue组件设计模式:提升代码复用性和可维护性的策略

# 1. Vue组件设计模式的理论基础
在构建复杂前端应用程序时,组件化是一种常见的设计方法,Vue.js框架以其组件系统而著称,允许开发者将UI分成独立、可复用的部分。Vue组件设计模式不仅是编写可维护和可扩展代码的基础,也是实现应用程序业务逻辑的关键。
## 组件的定义与重要性
组件是Vue中的核心概念,它可以封装HTML、CSS和JavaScript代码,以供复用。理解
Android二维码实战:代码复用与模块化设计的高效方法

# 1. Android二维码技术概述
在本章,我们将对Android平台上二维码技术进行初步探讨,概述其在移动应用开发中的重要性和应用背景。二维码技术作为信息交换和移动互联网连接的桥梁,已经在各种业务场景中得到广泛应用。
## 1.1 二维码技术的定义和作用
二维码(QR Code)是一种能够存储信息的二维条码,它能够以
直播推流成本控制指南:PLDroidMediaStreaming资源管理与优化方案
# 1. 直播推流成本控制概述
## 1.1 成本控制的重要性
直播业务尽管在近年来获得了爆发式的增长,但随之而来的成本压力也不容忽视。对于直播平台来说,优化成本控制不仅能够提升财务表现,还能增强市场竞争力。成本控制是确保直播服务长期稳定运
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )