模糊C均值聚类算法实战指南:从入门到精通
发布时间: 2024-08-21 23:53:42 阅读量: 32 订阅数: 24 

# 1. 模糊C均值聚类算法概述
模糊C均值聚类算法(FCM)是一种基于模糊理论的聚类算法,它允许数据点同时属于多个簇。与传统的硬聚类算法不同,FCM将数据点分配给簇的程度量化为一个介于0和1之间的隶属度值。
FCM算法的优点在于它能够处理数据的不确定性和噪声,并且可以识别重叠的簇。它广泛应用于图像分割、文本聚类和数据挖掘等领域。
# 2. 模糊C均值聚类算法实现
### 2.1 算法原理和流程
模糊C均值聚类算法是一种基于模糊理论的聚类算法。其基本思想是将每个数据点分配给多个聚类,并根据数据点与聚类中心的相似度赋予不同的隶属度。
#### 2.1.1 模糊化
模糊化过程将每个数据点分配给多个聚类,并计算其隶属度。隶属度表示数据点属于某个聚类的程度,取值范围为[0, 1]。
#### 2.1.2 聚类中心更新
聚类中心更新过程根据数据点的隶属度更新每个聚类的中心。新的聚类中心是属于该聚类的所有数据点的加权平均值,其中权重为隶属度。
#### 2.1.3 收敛判断
收敛判断过程检查算法是否达到收敛状态。收敛状态是指聚类中心不再发生显著变化。通常使用欧几里得距离来衡量聚类中心的变化。
### 2.2 算法实现步骤
#### 2.2.1 数据预处理
数据预处理包括数据归一化、缺失值处理和异常值处理。归一化可以消除数据量纲的影响,缺失值处理可以填充缺失的数据,异常值处理可以去除对聚类结果产生较大影响的异常数据。
#### 2.2.2 参数初始化
参数初始化包括聚类数目、模糊化系数和最大迭代次数的设置。聚类数目是算法需要划分的聚类数量,模糊化系数控制隶属度的模糊程度,最大迭代次数限制算法的运行时间。
#### 2.2.3 迭代计算
迭代计算是算法的核心部分,包括模糊化、聚类中心更新和收敛判断三个步骤。算法不断迭代执行这三个步骤,直到达到收敛状态。
### 2.3 算法实现代码
#### 2.3.1 Python实现
```python
import numpy as np
def fcm(data, k, m, max_iter=100):
"""
模糊C均值聚类算法
参数:
data: 数据集
k: 聚类数目
m: 模糊化系数
max_iter: 最大迭代次数
返回:
聚类中心
隶属度矩阵
"""
# 数据预处理
data = normalize(data)
# 参数初始化
n, d = data.shape
centers = init_centers(data, k)
u = init_membership(n, k, m)
# 迭代计算
for i in range(max_iter):
# 模糊化
u = update_membership(data, centers, u, m)
# 聚类中心更新
centers = update_centers(data, u)
# 收敛判断
if check_convergence(u, centers):
break
return centers, u
```
#### 2.3.2 Java实现
```java
import java.util.Arrays;
public class FCM {
private double[][] data;
private int k;
private double m;
private int maxIter;
public FCM(double[][] data, int k, double m, int maxIter) {
this.data = data;
this.k = k;
this.m = m;
this.maxIter = maxIter;
}
public double[][] cluster() {
// 数据预处理
data = normalize(data);
// 参数初始化
int n = data.length;
int d = data[0].length;
double[][] centers = initCenters(data, k);
double[][] u = initMembership(n, k, m);
// 迭代计算
for (int i = 0; i < maxIter; i++) {
// 模糊化
u = updateMembership(data, centers, u, m);
// 聚类中心更新
centers = updateCenters(data, u);
// 收敛判断
if (checkConvergence(u, centers)) {
break;
}
}
return centers;
}
// 其他方法...
}
```
# 3.1 图像分割
#### 3.1.1 图像预处理
图像分割是将图像划分为具有相似特征的区域的过程。在应用模糊C均值聚类算法进行图像分割之前,需要对图像进行预处理,以提高算法的性能。图像预处理通常包括以下步骤:
- **灰度化:**将彩色图像转换为灰度图像,去除颜色信息,简化图像处理。
- **噪声去除:**使用滤波器(如中值滤波或高斯滤波)去除图像中的噪声,提高图像质量。
- **图像增强:**通过调整对比度、亮度等参数,增强图像的细节和特征。
#### 3.1.2 聚类算法应用
图像预处理完成后,即可应用模糊C均值聚类算法进行图像分割。算法步骤如下:
1. **初始化:**设置聚类数目c、模糊化系数m和最大迭代次数。
2. **模糊化:**计算每个像素属于每个聚类中心的隶属度矩阵U。
3. **聚类中心更新:**根据隶属度矩阵更新每个聚类中心的坐标。
4. **收敛判断:**计算目标函数值,如果变化小于阈值或达到最大迭代次数,则算法收敛。
#### 3.1.3 分割结果评估
模糊C均值聚类算法应用于图像分割后,需要对分割结果进行评估。常见的评估指标包括:
- **Rand指数:**衡量分割结果与真实分割之间的相似性。
- **Jaccard指数:**衡量分割结果与真实分割之间的重叠程度。
- **轮廓完整性:**衡量分割结果中对象轮廓的完整性和准确性。
通过这些指标,可以评估模糊C均值聚类算法在图像分割中的性能。
# 4. 模糊C均值聚类算法优化
### 4.1 参数优化
模糊C均值聚类算法的性能受两个主要参数的影响:聚类数目和模糊化系数。
#### 4.1.1 聚类数目选择
聚类数目是算法的一个关键参数,它决定了聚类的数量。选择最佳聚类数目是一个挑战,因为没有通用的规则可以适用于所有数据集。
一种常见的聚类数目选择方法是肘部法。肘部法将聚类数目与聚类误差(例如,平方误差)绘制成曲线。最佳聚类数目通常对应于曲线中拐点(肘部)的位置,因为此时聚类误差的增加开始急剧减缓。
```python
import numpy as np
import matplotlib.pyplot as plt
# 数据集
data = np.random.rand(100, 2)
# 聚类数目范围
num_clusters = range(2, 11)
# 计算每个聚类数目的平方误差
errors = []
for k in num_clusters:
# 运行模糊C均值聚类算法
model = FCM(n_clusters=k)
model.fit(data)
errors.append(model.inertia_)
# 绘制肘部曲线
plt.plot(num_clusters, errors)
plt.xlabel('聚类数目')
plt.ylabel('平方误差')
plt.show()
```
#### 4.1.2 模糊化系数选择
模糊化系数控制聚类成员度的模糊程度。较高的模糊化系数导致更模糊的聚类,而较低的模糊化系数导致更清晰的聚类。
最佳模糊化系数的选择取决于数据集和特定的聚类任务。一般来说,对于噪声较大的数据集,较高的模糊化系数可以帮助抑制噪声的影响。对于清晰度较高的数据集,较低的模糊化系数可以产生更清晰的聚类。
### 4.2 算法加速
模糊C均值聚类算法是一个迭代算法,可能需要大量计算。为了提高算法的效率,可以采用以下优化策略:
#### 4.2.1 并行计算
模糊C均值聚类算法可以并行化,因为不同的数据点可以独立地聚类。通过利用多核处理器或分布式计算环境,可以显著提高算法的计算速度。
#### 4.2.2 启发式优化
启发式优化技术可以用于改进模糊C均值聚类算法的收敛速度。例如,可以采用模拟退火或遗传算法来搜索最佳聚类中心。这些技术可以帮助算法避免陷入局部最优解,从而找到更好的聚类结果。
# 5.1 加权模糊C均值聚类
### 5.1.1 加权函数设计
加权模糊C均值聚类算法在传统模糊C均值聚类算法的基础上,引入了权重因子,对数据点的影响进行加权。权重函数的设计是加权模糊C均值聚类算法的关键。
常用的权重函数有:
- **距离权重函数:**根据数据点与聚类中心的距离进行加权,距离越近,权重越大。
- **密度权重函数:**根据数据点周围的密度进行加权,密度越大,权重越大。
- **邻域权重函数:**根据数据点与邻近数据点的关系进行加权,邻近数据点越多,权重越大。
### 5.1.2 算法实现和应用
加权模糊C均值聚类算法的实现步骤与传统模糊C均值聚类算法类似,主要的区别在于在计算聚类中心更新时加入了权重因子:
```python
# 计算加权聚类中心
for j in range(c):
num = 0
den = 0
for i in range(n):
w = weight_function(x[i], c[j]) # 计算权重
num += w * x[i]
den += w
c[j] = num / den
```
加权模糊C均值聚类算法可以应用于各种数据聚类任务,例如:
- **图像分割:**通过对图像像素的加权,增强图像中不同区域的分割效果。
- **文本聚类:**通过对文本文档的加权,提高文本聚类的准确性和鲁棒性。
- **客户细分:**通过对客户数据的加权,实现更精细的客户细分和营销策略制定。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
模糊C均值聚类技术专栏深入探讨了这一强大的数据挖掘算法,从其数学基础到实际应用。专栏文章涵盖了算法的原理、实战指南、在图像处理、自然语言处理和生物信息学中的应用。通过揭示模糊C均值聚类算法的秘密,该专栏旨在为读者提供从入门到精通的全面指南,帮助他们利用这一技术解决各种数据分析问题。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Tau包社交网络分析】:掌握R语言中的网络数据处理与可视化
# 1. Tau包社交网络分析基础
社交网络分析是研究个体间互动关系的科学领域,而Tau包作为R语言的一个扩展包,专门用于处理和分析网络数据。本章节将介绍Tau包的基本概念、功能和使用场景,为读者提供一个Tau包的入门级了解。
## 1.1 Tau包简介
Tau包提供了丰富的社交网络分析工具,包括网络的创建、分析、可视化等,特别适合用于研究各种复杂网络的结构和动态。它能够处理有向或无向网络,支持图形的导入和导出,使得研究者能够有效地展示和分析网络数据。
## 1.2 Tau与其他网络分析包的比较
Tau包与其他网络分析包(如igraph、network等)相比,具备一些独特的功能和优势。
R语言数据包安全使用指南:规避潜在风险的策略
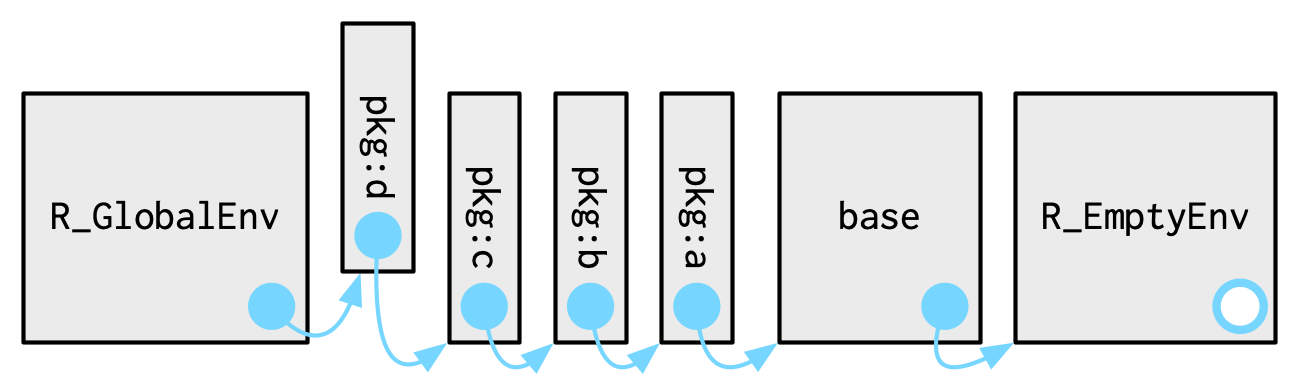
# 1. R语言数据包基础知识
在R语言的世界里,数据包是构成整个生态系统的基本单元。它们为用户提供了一系列功能强大的工具和函数,用以执行统计分析、数据可视化、机器学习等复杂任务。理解数据包的基础知识是每个数据科学家和分析师的重要起点。本章旨在简明扼要地介绍R语言数据包的核心概念和基础知识,为
【数据子集可视化】:lattice包高效展示数据子集的秘密武器

# 1. 数据子集可视化简介
在数据分析的探索阶段,数据子集的可视化是一个不可或缺的步骤。通过图形化的展示,可以直观地理解数据的分布情况、趋势、异常点以及子集之间的关系。数据子集可视化不仅帮助分析师更快地发现数据中的模式,而且便于将分析结果向非专业观众展示。
数据子集的可视化可以采用多种工具和方法,其中基于R语言的`la
R语言与SQL数据库交互秘籍:数据查询与分析的高级技巧
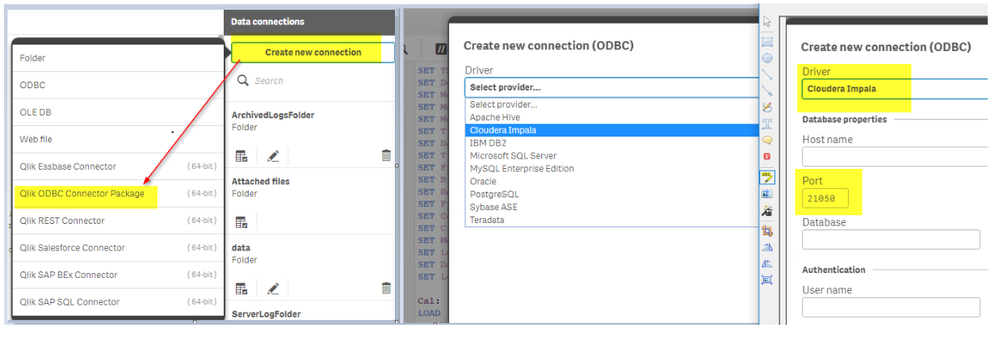
# 1. R语言与SQL数据库交互概述
在数据分析和数据科学领域,R语言与SQL数据库的交互是获取、处理和分析数据的重要环节。R语言擅长于统计分析、图形表示和数据处理,而SQL数据库则擅长存储和快速检索大量结构化数据。本章将概览R语言与SQL数据库交互的基础知识和应用场景,为读者搭建理解后续章节的框架。
## 1.
R语言tm包中的文本聚类分析方法:发现数据背后的故事

# 1. 文本聚类分析的理论基础
## 1.1 文本聚类分析概述
文本聚类分析是无监督机器学习的一个分支,它旨在将文本数据根据内容的相似性进行分组。文本数据的无结构特性导致聚类分析在处理时面临独特挑战。聚类算法试图通过发现数据中的自然分布来形成数据的“簇”,这样同一簇内的文本具有更高的相似性。
## 1.2 聚类分
【R语言地理信息数据分析】:chinesemisc包的高级应用与技巧
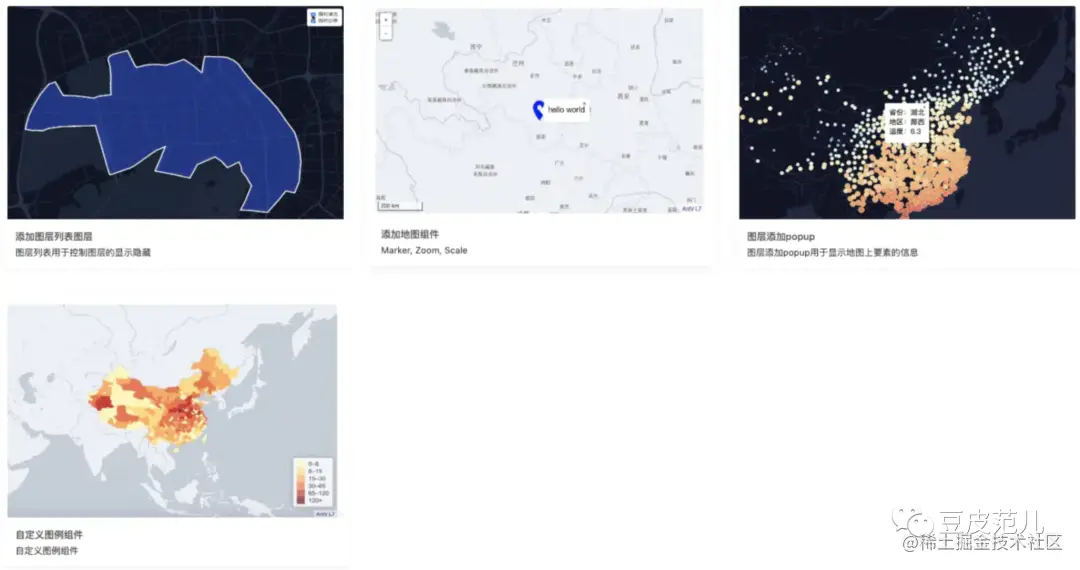
# 1. R语言与地理信息数据分析概述
R语言作为一种功能强大的编程语言和开源软件,非常适合于统计分析、数据挖掘、可视化以及地理信息数据的处理。它集成了众多的统计包和图形工具,为用户提供了一个灵活的工作环境以进行数据分析。地理信息数据分析是一个特定领域
【R语言qplot深度解析】:图表元素自定义,探索绘图细节的艺术(附专家级建议)

# 1. R语言qplot简介和基础使用
## qplot简介
`qplot` 是 R 语言中 `ggplot2` 包的一个简单绘图接口,它允许用户快速生成多种图形。`qplot`(快速绘图)是为那些喜欢使用传统的基础 R 图形函数,但又想体验 `ggplot2` 绘图能力的用户设
R语言交互式图表制作:aplpack包与shiny应用的完美结合
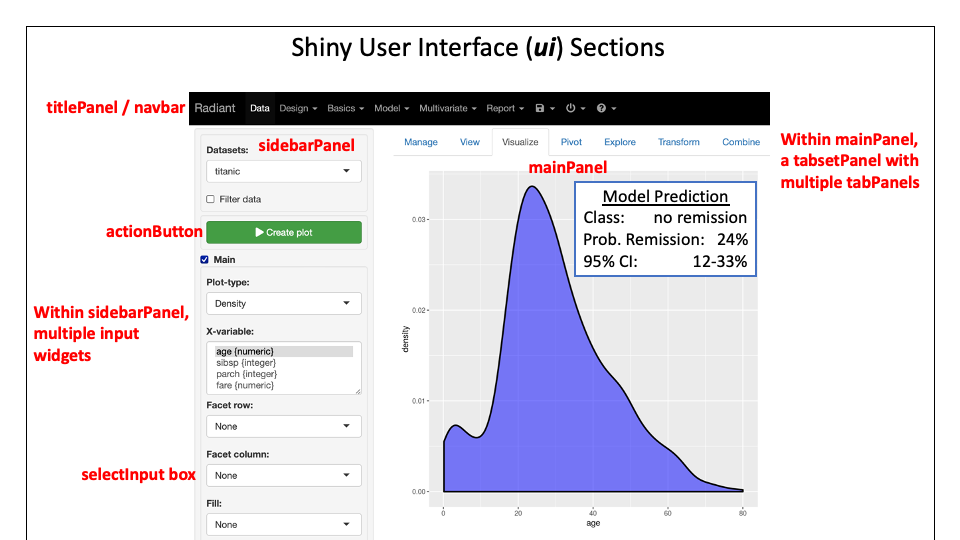
# 1. R语言交互式图表的概述
在数据分析领域,可视化是解释和理解复杂数据集的关键工具。R语言,作为一个功能强大的统计分析和图形表示工具,已广泛应用于数据科学界。交互式图表作为可视化的一种形式,它提供了一个动态探索和理解数据的平台。本章将概述R语言中交互式图表的基本概念,包括它们如何帮助分析师与数据进行互动,以及它们在各种应用中的重要性。通过了解交互式图表的基本原理,我们将为接下来深
R语言数据包性能监控:实时跟踪使用情况的高效方法
# 1. R语言数据包性能监控概述
在当今数据驱动的时代,对R语言数据包的性能进行监控已经变得越来越重要。本章节旨在为读者提供一个关于R语言性能监控的概述,为后续章节的深入讨论打下基础。
## 1.1 数据包监控的必要性
随着数据科学和统计分析在商业决策中的作用日益增强,R语言作为一款强大的统计分析工具,其性能监控成为确保数据处理效率和准确性的重要环节。性能监控能够帮助我们识别潜在的瓶颈,及时优化数据包的使用效率,提
模型结果可视化呈现:ggplot2与机器学习的结合
# 1. ggplot2与机器学习结合的理论基础
ggplot2是R语言中最受欢迎的数据可视化包之一,它以Wilkinson的图形语法为基础,提供了一种强大的方式来创建图形。机器学习作为一种分析大量数据以发现模式并建立预测模型的技术,其结果和过程往往需要通过图形化的方式来解释和展示。结合ggplot2与机器学习,可以将复杂的数据结构和模型结果以视觉友好的形式展现
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )