R语言环境科学应用:数据分析与模型构建案例研究,北大李东风教材深度剖析
发布时间: 2024-12-21 19:35:20 阅读量: 4 订阅数: 9 

R语言数据分析课程设计-词云-北邮&北交.zip

# 摘要
本文系统地介绍了R语言在环境科学中的广泛应用,涵盖了数据分析的基础知识、处理技巧、描述性统计和可视化,以及高级分析方法和模型构建。通过对环境监测数据的处理分析、环境影响评估模型的构建,以及地理信息系统数据处理的讨论,本文展示了R语言在环境数据分析中的实用性。同时,文中探讨了时间序列分析、机器学习算法和生态模型构建等高级数据分析技术,并深入剖析了这些技术在环境科学案例研究中的应用。文章还展望了环境科学中R语言应用的前沿研究和教育意义,强调了R语言在推动环境科学领域研究进展中的重要作用。
# 关键字
R语言;环境科学;数据分析;描述性统计;时间序列分析;机器学习;生态模型;GIS数据处理
参考资源链接:[R语言入门教程:北大李东风讲义](https://wenku.csdn.net/doc/1ruuwnv5up?spm=1055.2635.3001.10343)
# 1. R语言在环境科学中的应用概述
环境科学作为一门跨学科的领域,需要融合各种工具和方法以充分理解复杂的环境现象。R语言,作为一种强大的开源统计软件,正因其在数据分析、可视化和统计建模上的卓越能力,在环境科学领域中得到了广泛应用。本章将为读者展示R语言在环境科学研究中的基本应用场景,涵盖从数据收集到结果解读的整个工作流程,强调其在促进环境决策和政策制定中的作用。
## 1.1 R语言在环境监测中的角色
环境监测是环境保护的基石,R语言通过自动化数据处理、分析和可视化等技术,能够高效地处理大量环境数据。例如,R语言的图形包可以轻松生成趋势图,有助于监测空气质量、水质变化等环境指标。
## 1.2 R语言在环境影响评估中的应用
环境影响评估(EIA)是预测项目对环境可能造成的影响并提出减缓措施的过程。R语言在数据管理和统计建模方面的能力,可以帮助研究人员构建评估模型,从而分析环境变化的潜在影响。
## 1.3 R语言与环境数据的集成
环境数据往往具有空间和时间的复杂性,R语言与地理信息系统(GIS)等工具的集成,能够提供强大的空间数据分析能力。这在绘制污染源分布图、监测环境变化等方面表现得尤为突出。
通过本章的介绍,读者将对R语言在环境科学中的应用有一个全面的了解,并对后续章节中更详细的数据处理和分析技术产生期待。
# 2. R语言数据分析基础
### 2.1 R语言的数据结构与类型
#### 2.1.1 基本数据结构介绍
R语言中的数据结构是进行数据分析的基础,它包括向量(vector)、因子(factor)、矩阵(matrix)、数组(array)、数据框(data.frame)等。向量是R中最基本的数据结构,用于存储一系列同一类型的元素。因子用于存储分类数据,它对数据的分析和可视化非常重要。矩阵和数组用于存储多维数据,矩阵是二维的,而数组可以扩展到多维。数据框(data.frame)是R语言中最为重要的数据结构之一,它是由不同类型的向量构成的,可以视为一个表格,每个向量相当于一列,而行则对应数据的观测值。
```R
# 向量创建示例
my_vector <- c(1, 2, 3, 4, 5)
# 因子创建示例
gender <- factor(c("male", "female", "female", "male"))
# 矩阵创建示例
my_matrix <- matrix(1:12, nrow = 3, ncol = 4)
# 数组创建示例
my_array <- array(1:24, dim = c(2, 3, 4))
# 数据框创建示例
my_data_frame <- data.frame(
ID = 1:4,
Name = c("Alice", "Bob", "Charlie", "David"),
Score = c(92, 84, 96, 78)
)
```
#### 2.1.2 特殊数据类型解析
除了基本的数据结构之外,R语言还提供了一些特殊的数据类型来处理特定的数据分析需求。例如,列表(list)可以包含不同类型的元素,包括数据框和其他列表。时间序列(ts)对象则专门用于处理时间序列数据。日期和日期时间(Date和POSIXct)类型则用于处理时间相关的数据。这些数据类型为处理复杂数据提供了便利。
```R
# 列表创建示例
my_list <- list(
vector = my_vector,
matrix = my_matrix,
data_frame = my_data_frame
)
# 时间序列创建示例
my_timeseries <- ts(my_vector, start = c(2020, 1), frequency = 12)
# 日期创建示例
my_date <- as.Date("2020-01-01")
# 日期时间创建示例
my_datetime <- as.POSIXct("2020-01-01 12:00:00", tz = "UTC")
```
### 2.2 数据处理与清洗技巧
#### 2.2.1 数据集的导入和导出
数据的导入和导出是数据处理的第一步。R语言支持多种数据格式的读取和写入,如CSV、TXT、XLSX、JSON、HTML等。主要函数包括`read.csv()`, `write.csv()`, `read.xlsx()`, `write.xlsx()`等。合理地导入和导出数据是保证数据完整性和后续分析准确性的前提。
```R
# CSV数据导入和导出示例
my_data <- read.csv("data.csv")
write.csv(my_data, "output_data.csv")
# XLSX数据导入和导出示例
library(readxl)
library(writexl)
my_data_xlsx <- read_excel("data.xlsx")
write_xlsx(my_data, "output_data.xlsx")
```
#### 2.2.2 缺失数据的处理方法
在数据分析过程中,经常会遇到含有缺失值(NA)的数据集。R语言提供了多种处理缺失数据的方法,例如删除含有缺失值的行`na.omit()`,或使用替代值填充缺失值,如使用平均值、中位数或众数等。选择合适的方法可以显著影响分析结果。
```R
# 删除含有缺失值的行示例
clean_data <- na.omit(my_data)
# 使用平均值填充缺失值示例
my_data[is.na(my_data)] <- mean(my_data, na.rm = TRUE)
```
#### 2.2.3 数据转换与重构
数据转换和重构是数据清洗过程中的重要环节。通过使用函数如`subset()`, `transform()`, `aggregate()`, 和 `reshape()`,可以对数据进行筛选、转换和重塑。这些操作可以灵活地帮助我们准备出适合进行分析的数据结构。
```R
# 数据框子集筛选示例
subset_data <- subset(my_data, Score > 80)
# 数据转换示例
transformed_data <- transform(my_data, Score = Score / 100)
# 数据重塑示例
# 将数据框从宽格式转换为长格式
library(reshape2)
long_data <- melt(my_data, id.vars = "ID")
```
### 2.3 描述性统计分析与可视化
#### 2.3.1 基本统计量的计算
描述性统计分析是理解数据集基本特征的有效手段,包括计算均值、中位数、众数、方差、标准差、偏度和峰度等。R语言中可以通过基础函数`mean()`, `median()`, `mode()`, `var()`, `sd()`, `skewness()`, `kurtosis()`等来执行这些操作,也可以使用`summary()`函数直接获得数据集的描述性统计摘要。
```R
# 均值计算示例
mean_value <- mean(my_data$Score)
# 方差计算示例
variance_value <- var(my_data$Score)
# 描述性统计摘要示例
summary(my_data)
```
#### 2.3.2 数据可视化的基本方法
数据可视化可以帮助我们直观地理解数据集的特点,R语言通过`plot()`, `barplot()`, `boxplot()`, `hist()`, `pie()`等函数提供数据可视化的基础方法。同时,借助`ggplot2`这样的高级绘图包,用户可以创建更加精细和专业水平的数据图形。
```R
# 直方图绘制示例
hist(my_data$Score)
# 散点图绘制示例
plot(my_data$Score, my_data$ID)
# 使用ggplot2绘图包绘制散点图
library(ggplot2)
ggplot(my_data, aes(x = Score, y = ID)) + geom_point()
```
### 2.4 实用案例:数据处理与可视化
为了加深对本章内容的理解,让我们通过一个实用案例来实际操作数据的导入、处理、统计分析和可视

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以北京大学李东风教授的《R语言基础教程》为基础,深入解读R语言的精髓。专栏内容涵盖R语言初学者必备的技巧、基础数据结构和操作、向量化操作、数据可视化、数据清洗和变换、概率和统计、时间序列分析、数据库交互、数据挖掘、文本分析、编程技巧提升、包开发、Web开发、生物信息学应用和环境科学应用等多个方面。通过对李东风教材的案例全面分析和深入剖析,专栏旨在帮助读者掌握R语言的应用和开发技能,成为R语言的专家。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深度剖析Renren Security:功能模块背后的架构秘密

# 摘要
Renren Security是一个全面的安全框架,旨在为Web应用提供强大的安全保护。本文全面介绍了Renren Security的核心架构、设计理念、关键模块、集成方式、实战应用以及高级特性。重点分析了认证授权机制、过滤器链设计、安全拦截器的运作原理和集成方法。通过对真实案例的深入剖析,本文展示了Renren Security在实际应用中的效能,并探讨了性能优化和安全监
电力系统稳定性分析:PSCAD仿真中的IEEE 30节点案例解析
# 摘要
本文详细探讨了电力系统稳定性及其在仿真环境中的应用,特别是利用PSCAD仿真工具对IEEE 30节点系统进行建模和分析。文章首先界定了电力系统稳定性的重要性并概述了仿真技术,然后深入分析了IEEE 30节点系统的结构、参数及稳定性要求。在介绍了PSCAD的功能和操作后,本文通过案例展示了如何在PSCAD中设置和运行IEEE 30节点模型,进行稳定性分析,并基于理论对仿真结果进行了详细分析
Infovision iPark高可用性部署:专家传授服务不间断策略
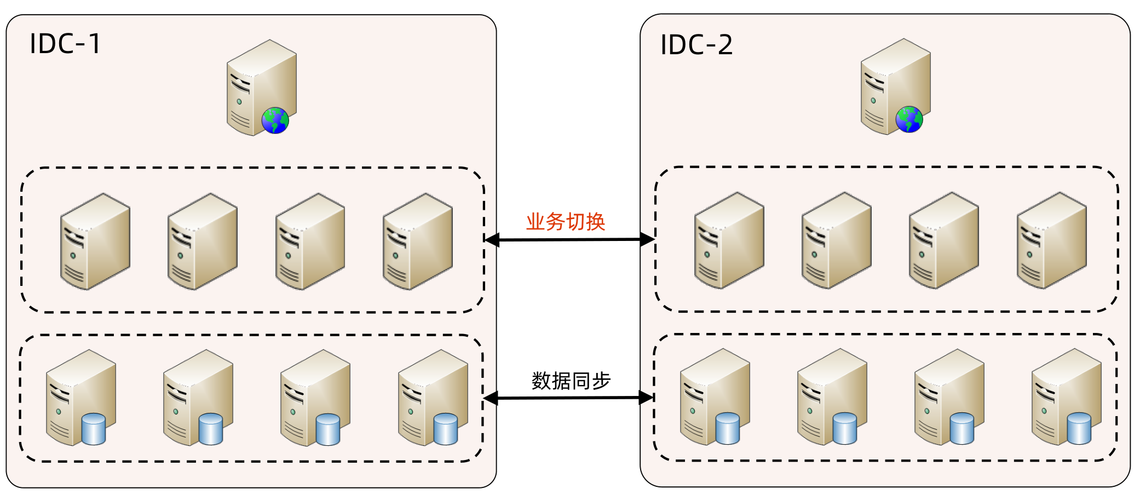
# 摘要
Infovision iPark作为一款智能停车系统解决方案,以其高可用性的设计,能够有效应对不同行业特别是金融、医疗及政府公共服务行业的业务连续性需求。本文首先介绍了Infovision iPark的基础架构和高可用性理论基础,包括高可用性的定义、核心价值及设计原则。其次,详细阐述了Infovision iPark在实际部署中的高可用性实践,包括环境配
USCAR38供应链管理:平衡质量与交付的7个技巧

# 摘要
供应链管理作为确保产品从原材料到终端用户高效流动的复杂过程,其核心在于平衡质量与交付速度。USCAR38的供应链管理概述了供应链管理的理论基础和实践技巧,同时着重于质量与交付之间的平衡挑战。本文深入探讨了供应链流程的优化、风险应对策略以及信息技术和自动化技术的应用。通过案例研究,文章分析了在实践中平衡质量与交付的成功与失败经验,并对供应链管理的未来发展趋
组合数学与算法设计:卢开澄第四版60页的精髓解析
# 摘要
本文系统地探讨了组合数学与算法设计的基本原理和方法。首先概述了算法设计的核心概念,随后对算法分析的基础进行了详细讨论,包括时间复杂度和空间复杂度的度量,以及渐进符号的使用。第三章深入介绍了组合数学中的基本计数原理和高级技术,如生成函数和容斥原理。第四章转向图论基础,探讨了图的基本性质、遍历算法和最短路径问题的解决方法。第五章重点讲解了动态规划和贪心算法,以及它们在
【Tomcat性能优化实战】:打造高效稳定的Java应用服务器

# 摘要
本文旨在深入分析并实践Tomcat性能优化方法。首先,文章概述了Tomcat的性能优化概览,随后详细解析了Tomcat的工作原理及性能
【BIOS画面定制101】:AMI BIOS初学者的完全指南
# 摘要
本文介绍了AMI BIOS的基础知识、设置、高级优化、界面定制以及故障排除与问题解决等关键方面。首先,概述了BIOS的功能和设置基础,接着深入探讨了性能调整、安全性配置、系统恢复和故障排除等高级设置。文章还讲述了BIOS画面定制的基本原理和实践技巧,包括界面布局调整和BIOS皮肤的更换、设计及优化。最后,详细介绍了BIOS更新、回滚、错误解决和长期维护
易康eCognition自动化流程设计:面向对象分类的优化路径

# 摘要
本文综述了易康eCognition在自动化流程设计方面的应用,并详细探讨了面向对象分类的理论基础、实践方法、案例研究、挑战与机遇以及未来发展趋势。文中从地物分类的概念出发,分析了面向对象分类的原理和精度评估方法。随后,通过实践章节展示如何在不同领域中应用易康eCognition进行流程设计和高级分类技术的实现。案例研究部分提供了城市用地、森林资
【变频器通讯高级诊断策略】:MD800系列故障快速定位与解决之道

# 摘要
本文系统阐述了变频器通讯的原理与功能,深入分析了MD800系列变频器的技术架构,包括其硬件组成、软件架构以及通讯高级功能。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )