ggpubr在生物信息学中的应用:数据可视化案例研究
发布时间: 2024-11-07 13:57:14 阅读量: 34 订阅数: 47 

MATLAB在ThingSpeak中应用信号处理与数据可视化的技术实现
# 1. ggpubr包概述与安装
## 1.1 ggpubr包简介
ggpubr(ggplot2-based publication ready plots)是一个R语言包,旨在提供易于使用且满足学术出版需求的图形。它建立在强大的ggplot2包之上,简化了绘图的过程,使得生成高质量的统计图形变得简单快捷。ggpubr封装了许多定制化的图形绘制功能,例如为图形自动添加统计分析结果、自定义颜色主题等。
## 1.2 安装和加载ggpubr包
为了使用ggpubr包,需要先通过CRAN仓库进行安装。在R控制台中执行以下命令进行安装:
```R
install.packages("ggpubr")
```
安装完成后,通过以下代码加载该包:
```R
library(ggpubr)
```
## 1.3 ggpubr包的安装与检查
安装ggpubr包之后,建议进行简单的检查以确认包已正确安装并且功能正常。可以使用`ggsignif()`函数尝试绘制带有统计标记的图形,以验证包是否正常工作。
```R
# 绘制一个带有显著性标记的散点图
data("mtcars")
ggplot(mtcars, aes(x=factor(cyl), y=mpg)) +
geom_boxplot() +
geom_signif(comparisons=list(c("4", "6"), c("6", "8")),
map_signif_level=TRUE) # 显示显著性水平
```
以上代码展示了如何加载ggpubr包,并进行基础的图形绘制与验证,确保包的功能符合预期。在后续章节中,我们将更深入地探讨ggpubr包的各项功能。
# 2. ggpubr基础图形生成
在数据可视化的世界里,ggpubr包是一个将复杂数据转换成直观图形的强大工具。本章将介绍ggpubr包的图形绘制功能、常用图形的绘制方法以及如何进行个性化定制。通过本章节的学习,读者将能够掌握使用ggpubr包进行数据展示的基础知识。
## 2.1 ggpubr包的图形绘制功能
### 2.1.1 ggpubr图形的基本组成
ggpubr图形的基础结构包括坐标轴、图例、标题和标签等元素。这些基本组成在ggpubr中通过函数参数进行调整,以实现数据的清晰展示。ggpubr为R语言的ggplot2包提供了额外的图层和主题选项,使得创建高质量图形更为方便快捷。
```r
library(ggpubr)
# 创建一个基础条形图
bar_plot <- ggplot(data = diamonds, aes(x = cut, fill = cut)) +
geom_bar() +
theme_pubr() # 使用ggpubr提供的主题
print(bar_plot)
```
在上述代码中,`ggplot` 函数用于创建一个图形对象,`aes` 函数定义了x轴和填充颜色的映射,`geom_bar` 用于生成条形图,最后使用`theme_pubr`应用ggpubr提供的主题设置,使得图形更加美观。
### 2.1.2 ggpubr与ggplot2的关系
ggpubr包与ggplot2包关系密切,后者是R语言中非常流行的图形生成包。ggpubr包在ggplot2的基础上进行了功能扩展和优化,提供了一些方便的函数来生成出版级别的图形。同时,ggpubr也保持了与ggplot2的兼容性,使得ggplot2用户可以无缝地使用ggpubr进行图形定制。
```r
# 使用ggplot2创建基础图形
library(ggplot2)
base_plot <- ggplot(data = mtcars, aes(x = wt, y = mpg)) +
geom_point() +
theme_minimal() # ggplot2的主题
# 在ggplot2的基础上应用ggpubr的图层
final_plot <- base_plot + stat_compare_means(method = "t.test") +
labs(title = "MPG vs. Weight", x = "Weight", y = "Miles/(US) gallon")
print(final_plot)
```
在上述例子中,我们首先使用`ggplot2`创建了一个散点图,然后通过`stat_compare_means`函数添加了t检验的统计比较标记,该函数是ggpubr包提供的,用以在图中展示统计分析的结果。
## 2.2 常用图形的绘制方法
### 2.2.1 条形图和柱状图的绘制
条形图和柱状图是基础统计图形,ggpubr包提供了简单易用的函数来生成这些图形。下面的代码展示了如何使用ggpubr绘制一个分组柱状图。
```r
# 使用ggpubr绘制分组柱状图
grouped_bar <- ggplot(data = ToothGrowth, aes(x = factor(dose), fill = supp)) +
geom_bar(position = position_dodge(width = 0.8), stat = "count") +
theme_pubr()
print(grouped_bar)
```
在这里,`position_dodge`用于调整分组条形之间的水平距离,`stat = "count"`表示我们根据因子的组合进行计数,而不仅仅是简单地展示数据量。
### 2.2.2 箱线图和小提琴图的绘制
箱线图和小提琴图非常适合展示数据的分布情况,它们可以突出数据的中位数、四分位数范围、异常值以及数据的密度分布。ggpubr包中相关的函数可以方便地绘制这些图形。
```r
# 绘制箱线图
box_plot <- ggplot(data = ToothGrowth, aes(x = dose, y = len, fill = supp)) +
geom_boxplot() +
theme_pubr()
print(box_plot)
# 绘制小提琴图
violin_plot <- ggplot(data = ToothGrowth, aes(x = dose, y = len, fill = supp)) +
geom_violin(trim = FALSE) +
theme_pubr()
print(violin_plot)
```
在这两个例子中,`geom_boxplot`和`geom_violin`函数分别用于生成箱线图和小提琴图。小提琴图中的`trim`参数控制是否剪裁小提琴图的边缘,以展示数据点的范围。
### 2.2.3 点图和散点图的绘制
点图和散点图在展示两个变量之间的关系时非常有用。ggpubr包中的相关函数可以很容易地生成这些图形。
```r
# 绘制散点图
scatter_plot <- ggplot(data = diamonds, aes(x = carat, y = price, color = cut)) +
geom_point() +
theme_pubr()
print(scatter_plot)
```
在上述代码中,`geom_point`函数被用来绘制基本的散点图,其中`color`参数用于根据钻石的切割质量来着色散点。
## 2.3 图形的个性化定制
### 2.3.1 颜色和主题的选择
ggpubr包允许用户在图形中选择不同的颜色方案和主题。颜色和主题的选择对于传达信息和吸引观众非常关键。
```r
# 绘制条形图并自定义颜色
custom_color_bar <- ggplot(data = ToothGrowth, aes(x = supp, y = len, fill = supp)) +
geom_bar(stat = "identity") +
scale_fill_manual(values = c("dodgerblue2", "coral3")) + # 自定义颜色
theme_pubr()
print(custom_color_bar)
```
在这段代码中,`scale_fill_manual`函数用于自定义填充颜色,而`theme_pubr`函数提供了出版级别的图形主题。
### 2.3.2 添加注释和图例
在任何图形中添加注释和图例都是重要的步骤,它可以帮助观众更好地理解图形所展示的内容。
```r
# 在散点图中添加注释和图例
annotated_scatter <- scatter_plot +
annotate("text", x = 1.5, y = 1600, label = "Most expensive
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探索了 R 语言中强大的 ggpubr 数据包,提供了一系列教程和指南,涵盖从入门到高级应用的各个方面。从基础安装和应用到高级绘图技巧、定制图形、疑难杂症解决、数据可视化技巧、生物信息学应用、统计图形运用、自定义主题和样式、交互式图形、多变量数据可视化、R Markdown 集成、图形参数化、性能优化、与 dplyr 的协同,以及在临床和金融数据分析中的应用,本专栏提供了全面的资源,帮助数据科学家、研究人员和数据可视化从业者充分利用 ggpubr 的强大功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Catia曲线曲率分析深度解析:专家级技巧揭秘(实用型、权威性、急迫性)
# 摘要
本文全面介绍了Catia软件中曲线曲率分析的理论、工具、实践技巧以及高级应用。首先概述了曲线曲率的基本概念和数学基础,随后详细探讨了曲线曲率的物理意义及其在机械设计中的应用。文章第三章和第四章分别介绍了Catia中曲线曲率分析的实践技巧和高级技巧,包括曲线建模优化、问题解决、自动化定制化分析方法。第五章进一步探讨了曲率分析与动态仿真、工业设计中的扩展应用,以及曲率分析技术的未来趋势。最后,第六章对Catia曲线曲率分析进行了
【MySQL日常维护】:运维专家分享的数据库高效维护策略
# 摘要
本文全面介绍了MySQL数据库的维护、性能监控与优化、数据备份与恢复、安全性和权限管理以及故障诊断与应对策略。首先概述了MySQL基础和维护的重要性,接着深入探讨了性能监控的关键性能指标,索引优化实践,SQL语句调优技术。文章还详细讨论了数据备份的不同策略和方法,高级备份工具及技巧。在安全性方面,重点分析了用户认证和授权机制、安全审计以及防御常见数据库攻击的策略。针对故障诊断,本文提供了常
EMC VNX5100控制器SP硬件兼容性检查:专家的完整指南

# 摘要
本文旨在深入解析EMC VNX5100控制器的硬件兼容性问题。首先,介绍了EMC VNX5100控制器的基础知识,然后着重强调了硬件兼容性的重要性及其理论基础,包括对系统稳定性的影响及兼容性检查的必要性。文中进一步分析了控制器的硬件组件,探讨了存储介质及网络组件的兼容性评估。接着,详细说明了SP硬件兼容性检查的流程,包括准备工作、实施步骤和问题解决策略。此外
【IT专业深度】:西数硬盘检测修复工具的专业解读与应用(IT专家的深度剖析)
# 摘要
本文旨在全面介绍硬盘的基础知识、故障检测和修复技术,特别是针对西部数据(西数)品牌的硬盘产品。第一章对硬盘的基本概念和故障现象进行了概述,为后续章节提供了理论基础。第二章深入探讨了西数硬盘检测工具的理论基础,包括硬盘的工作原理、检测软件的分类与功能,以及故障检测的理论依据。第三章则着重于西数硬盘修复工具的使用技巧,包括修复前的准备工作、实际操作步骤和常见问题的解决方法。第四章与第五章进一步探讨了检测修复工具的深入应
【永磁电机热效应探究】:磁链计算如何影响电机温度管理
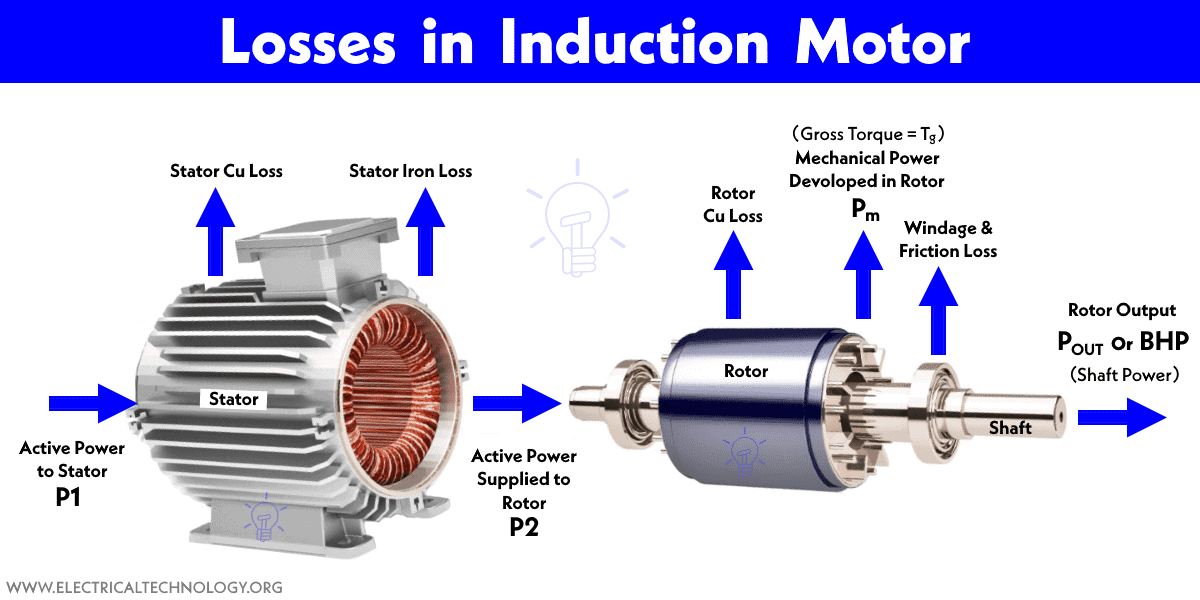
# 摘要
本论文对永磁电机的基础知识及其热效应进行了系统的概述。首先,介绍了永磁电机的基本理论和热效应的产生机制。接着,详细探讨了磁链计算的理论基础和计算方法,以及磁链对电机温度的影响。通过仿真模拟与分析,评估了磁链计算在电机热效应分析中的应用,并对仿真结果进行了验证。进一步地,本文讨论了电机温度管理的实际应用,包括热效应监测技术和磁链控制策略的
【代码重构在软件管理中的应用】:详细设计的革新方法

# 摘要
代码重构是软件维护和升级中的关键环节,它关注如何提升代码质量而不改变外部行为。本文综合探讨了代码重构的基础理论、深
【SketchUp设计自动化】

# 摘要
本文系统地探讨了SketchUp设计自动化在现代设计行业中的概念与重要性,着重介绍了SketchUp的基础操作、脚本语言特性及其在自动化任务中的应用。通过详细阐述如何通过脚本实现基础及复杂设计任务的自动化
【CentOS 7时间同步终极指南】:掌握NTP配置,提升系统准确性
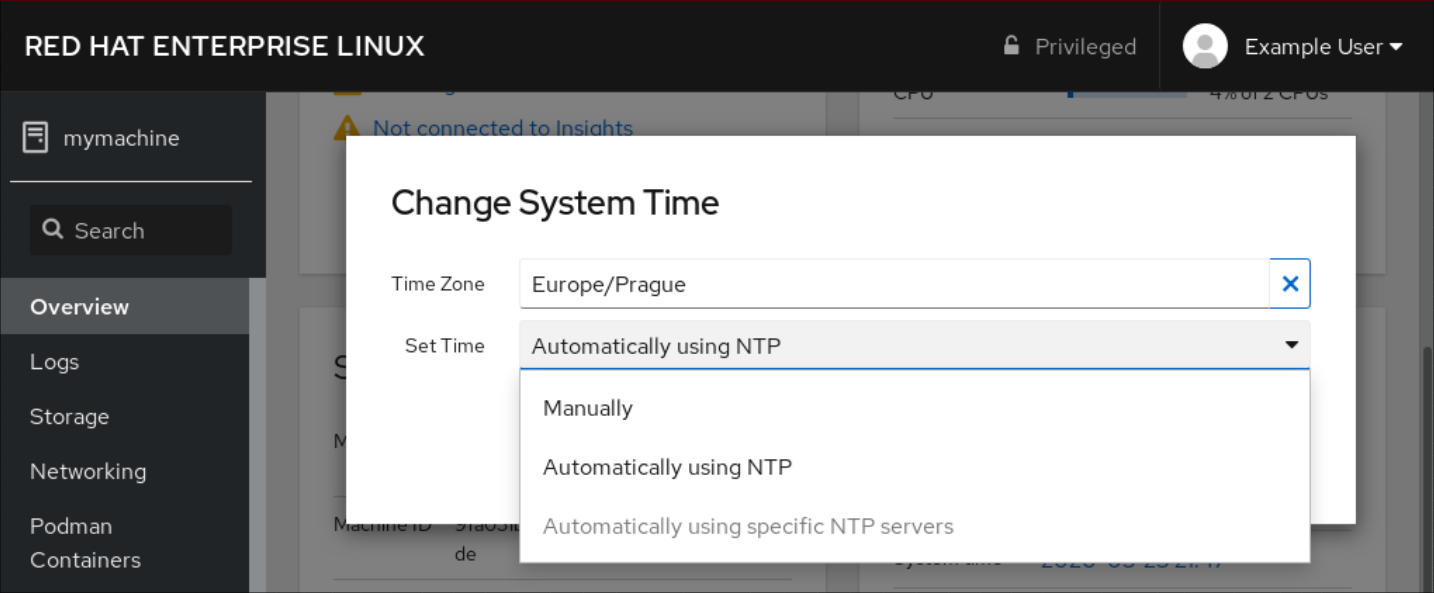
# 摘要
本文深入探讨了CentOS 7系统中时间同步的必要性、NTP(Network Time Protocol)的基础知识、配置和高级优化技术。首先阐述了时
轮胎充气仿真深度解析:ABAQUS模型构建与结果解读(案例实战)

# 摘要
轮胎充气仿真是一项重要的工程应用,它通过理论基础和仿真软件的应用,能够有效地预测轮胎在充气过程中的性能和潜在问题。本文首先介绍了轮胎充气仿真的理论基础和应用,然后详细探讨了ABAQUS仿真软件的环境配置、工作环境以及前处理工具的应用。接下来,本文构建了轮胎充气模型,并设置了相应的仿真参数。第四章分析了仿真的结果,并通过后处理技术和数值评估方法进行了深入解读。最后,通过案例实战演练,本文演示了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )