ggpubr包高级功能:图形参数化与可重复研究指南
发布时间: 2024-11-07 14:25:31 阅读量: 29 订阅数: 28 

电力系统仿真:基于MATLAB-Simulink的详细指南及其应用
# 1. ggpubr包基础与安装
## 1.1 了解ggpubr包
`ggpubr` 是一个基于 `ggplot2` 的R语言包,旨在简化和加速创建出版质量的图形。它提供了许多方便的函数来定制和修饰图表,并使统计比较过程更加直观。对于那些希望避免深入了解ggplot2复杂语法的用户,`ggpubr` 是一个很好的选择。
## 1.2 安装和加载ggpubr包
要使用`ggpubr`包,首先需要确保已经安装了R语言环境。接下来,打开R或RStudio,并执行以下命令来安装`ggpubr`包:
```r
install.packages("ggpubr")
```
安装完成后,使用以下命令加载包:
```r
library(ggpubr)
```
## 1.3 体验ggpubr的第一张图形
让我们快速创建一个示例图形以感受`ggpubr`的便捷性。我们使用`mtcars`数据集,它包含关于汽车的各项性能数据:
```r
# 创建一个箱形图
ggboxplot(mtcars, x = "cyl", y = "mpg", color = "cyl", palette = "jco")
```
这条简单的命令创建了一个彩色的箱形图,展示了不同气缸数(`cyl`)汽车的每加仑英里数(`mpg`)分布情况。
以上内容介绍了`ggpubr`包的基本概念,安装方法以及如何快速生成一张基础图形。接下来的章节会逐步深入,带你学习如何进行更复杂的图形定制和参数化。
# 2. ggpubr包图形参数化基础
## 2.1 图形对象与ggplot2语法
### 2.1.1 理解ggplot2的图层系统
ggplot2是R语言中非常流行的绘图包,它引入了图层的概念,使得图形构建变得模块化和可扩展。在ggplot2中,一个图形是由多个图层叠加而成的。每个图层可以添加数据点、几何对象(geoms)、统计变换(stats)、坐标系统(coordinates)和分面(facets)。
在ggpubr包中,为了简化绘图流程,已经封装了许多基础ggplot2函数,使得用户不需要深入理解每个图层的具体用法,只需通过简单的函数调用即可完成复杂的图形绘制。然而,为了获得更精细的控制,深入理解ggplot2的图层系统仍然是非常有必要的。
```r
# 示例代码:创建一个基础的散点图
library(ggplot2)
library(ggpubr)
# 使用ggplot函数创建一个图形对象
p <- ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) +
geom_point() + # 添加数据点
labs(title = "Sepal Length vs. Sepal Width") # 添加标题
print(p)
```
在上述代码中,`ggplot`函数定义了数据源和基本的映射关系,`geom_point`添加了散点图层。随后使用`labs`函数添加了标题。这种分层的方式允许用户逐个添加细节,直到图形达到预期的视觉效果。
### 2.1.2 图形对象的创建与存储
一旦图形对象被创建,它就可以被存储在一个变量中。这样做的好处是可以对图形进行进一步的修改和优化。存储图形对象也使得批处理图形和自动化图形输出变得更加容易。
```r
# 存储图形对象以供后续使用
p <- ggplot(data = mtcars, aes(x = mpg, y = wt, color = cyl)) +
geom_point() +
theme_minimal()
# 可以通过修改图形对象p来创建新的图形版本
p_modified <- p + labs(title = "Modified plot")
print(p_modified)
```
在这个例子中,我们首先创建了一个散点图,并将其存储在变量`p`中。然后,我们通过添加一个标题来创建了一个修改过的图形`p_modified`,并打印出来。存储图形对象使得图形的迭代变得简单和高效。
## 2.2 图形的定制化与美观性
### 2.2.1 选择和修改主题
ggplot2提供了一系列内置的主题函数,例如`theme_gray`、`theme_bw`、`theme_minimal`等。这些主题帮助我们快速地设置图形的整体外观,包括背景、网格线、字体等。
```r
# 使用不同的主题
p <- ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) +
geom_point()
# 应用不同的主题并展示结果
p_theme_gray <- p + theme_gray() + labs(title = "Theme: Gray")
p_theme_bw <- p + theme_bw() + labs(title = "Theme: Black & White")
p_theme_minimal <- p + theme_minimal() + labs(title = "Theme: Minimal")
# 打印图形
print(p_theme_gray)
print(p_theme_bw)
print(p_theme_minimal)
```
上述代码展示了同一个散点图应用了三种不同主题。主题的选择完全取决于个人喜好和出版物的要求。用户也可以通过`theme`函数自定义主题,从而达到完全的个性化定制。
### 2.2.2 调整颜色、字体和比例
除了主题之外,ggplot2允许我们对图形中的各个元素进行详细的定制,包括颜色、字体和图形的比例等。
```r
# 调整颜色、字体和比例
p <- ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) +
geom_point() +
scale_color_manual(values = c("#999999", "#E69F00", "#56B4E9")) + # 自定义颜色
theme(text = element_text(family = "Times", size = 12)) + # 设置字体和大小
scale_y_continuous(expand = c(0, 0), limits = c(2, 5)) + # 调整y轴比例
scale_x_continuous(expand = c(0, 0), limits = c(4, 8)) # 调整x轴比例
print(p)
```
在上述代码中,我们使用`scale_color_manual`函数自定义了不同种类的鸢尾花的散点颜色,使用`theme`函数调整了字体设置,并使用`scale_x_continuous`和`scale_y_continuous`函数对坐标轴的比例进行了调整。这些定制化选项允许用户创建出符合特定需求的图形。
## 2.3 参数化图形的输出与保存
### 2.3.1 图形的保存格式与质量控制
在完成图形的定制和优化后,通常需要将图形保存为文件。ggplot2支持多种图形格式的输出,包括常见的位图(如PNG、JPEG)和矢量图形(如PDF、SVG)。
```r
# 保存图形为PNG文件
ggsave("scatter_plot.png", plot = p, width = 8, height = 6, dpi = 300)
```
在上述代码中,`ggsave`函数用于将图形对象`p`保存为PNG文件。`width`和`height`参数定义了输出图形的尺寸,`dpi`参数定义了图像的分辨率。这些参数的设定可以帮助用户控制输出图形的质量和尺寸。
### 2.3.2 批量输出和自动化脚本编写
在实际应用中,我们可能需要根据不同的数据集或参数批量输出大量的图形。ggplot2和ggpubr包使得这个过程变得自动化。
```r
# 创建批量输出函数
save_plots <- function(data, file_name_prefix, plot_function) {
for (i in seq_along(data)) {
p <- plot_function(data[[i]])
ggsave(paste0(file_name_prefix, "_", i, ".png"), plot = p, width = 8, height = 6, dpi = 300)
}
}
# 使用函数批量保存图形
save_plots(iris
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探索了 R 语言中强大的 ggpubr 数据包,提供了一系列教程和指南,涵盖从入门到高级应用的各个方面。从基础安装和应用到高级绘图技巧、定制图形、疑难杂症解决、数据可视化技巧、生物信息学应用、统计图形运用、自定义主题和样式、交互式图形、多变量数据可视化、R Markdown 集成、图形参数化、性能优化、与 dplyr 的协同,以及在临床和金融数据分析中的应用,本专栏提供了全面的资源,帮助数据科学家、研究人员和数据可视化从业者充分利用 ggpubr 的强大功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Android应用中的MAX30100集成完全手册:一步步带你上手
# 摘要
本文综合介绍了MAX30100传感器的搭建和应用,涵盖了从基础硬件环境的搭建到高级应用和性能优化的全过程。首先概述了MAX30100的工作原理及其主要特性,然后详细阐述了如何集成到Arduino或Raspberry Pi等开发板,并搭建相应的硬件环境。文章进一步介绍了软件环境的配置,包括Arduino IDE的安装、依赖库的集成和MAX30100库的使用。接着,通过编程实践展示了MAX30100的基本操作和高级功能的开发,包括心率和血氧饱和度测量以及与Android设备的数据传输。最后,文章探讨了MAX30100在Android应用中的界面设计、功能拓展和性能优化,并通过实际案例分析
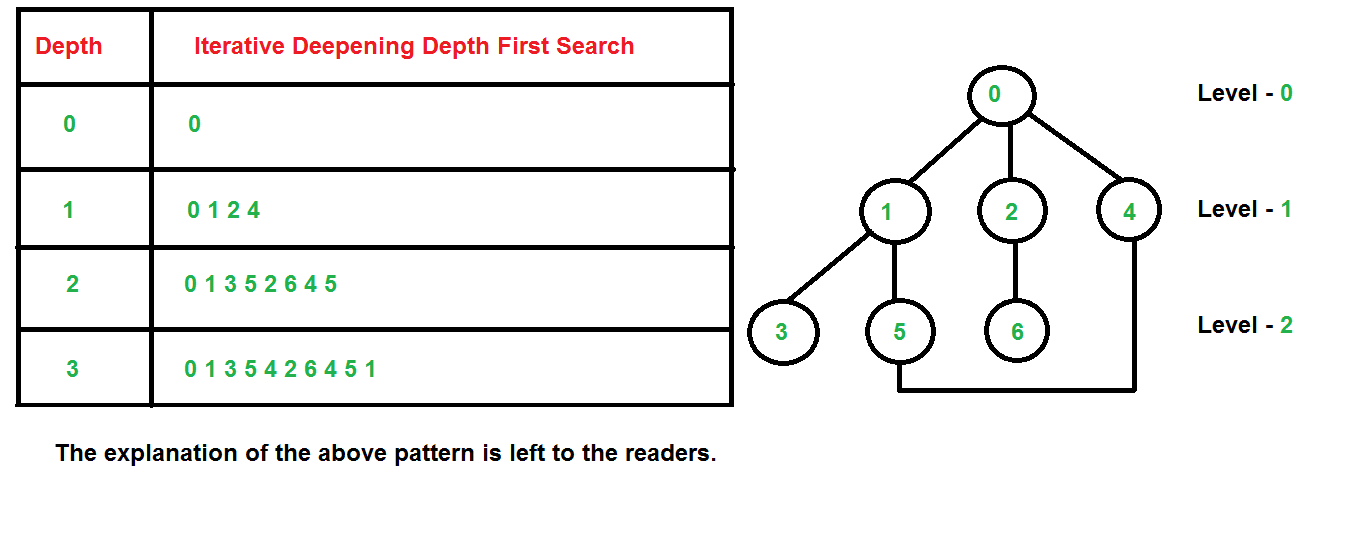
【AI高手】:掌握这些技巧,A*算法解决8数码问题游刃有余
# 摘要
A*算法是计算机科学中广泛使用的一种启发式搜索算法,尤其在路径查找和问题求解领域表现出色。本文首先概述了A*算法的基本概念,随后深入探讨了其理论基础,包括搜索算法的分类和评价指标,启发式搜索的原理以及评估函数的设计。通过结合著名的8数码问题,文章详细介绍了A*算法的实际操作流程、编码前的准备、实现步骤以及优化策略。在应用实例部分,文章通过具体问题的实例化和算法的实现细节,提供了深入的案例分析和问题解决方法。最后,本文展望
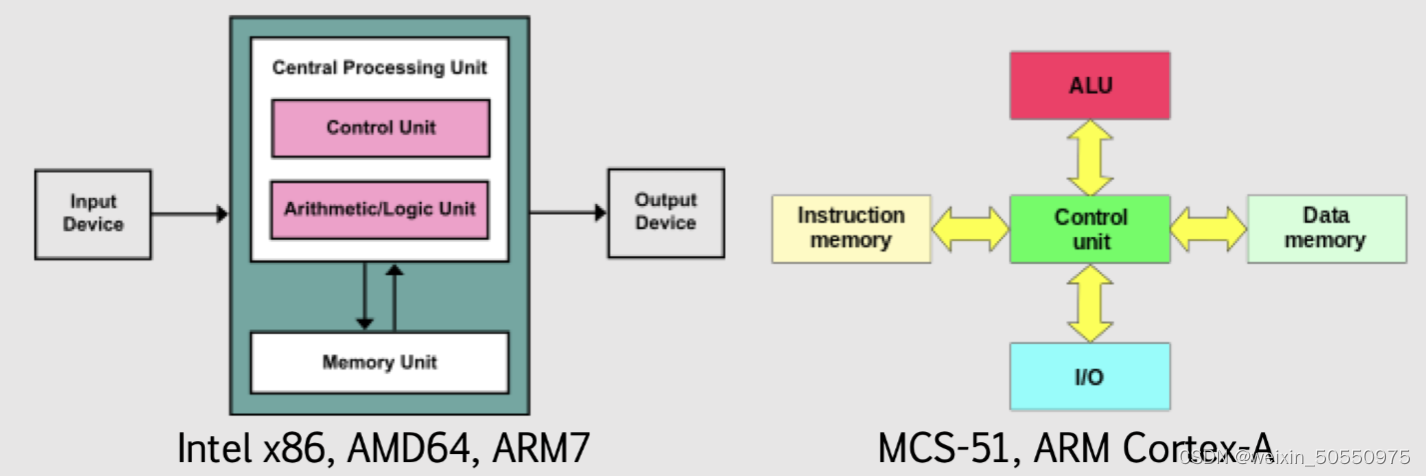
【硬件软件接口艺术】:掌握提升系统协同效率的关键策略
# 摘要
硬件与软件接口是现代计算系统的核心,它决定了系统各组件间的通信效率和协同工作能力。本文首先概述了硬件与软件接口的基本概念和通信机制,深入探讨了硬件通信接口标准的发展和主流技术的对比。接着,文章分析了软件接口的抽象层次,包括系统调用、API以及驱动程序的作用。此外,本文还详细介绍了同步与异步处理机制的原理和实践。在探讨提升系统协同效率的关键技术方面,文中阐述了缓存机制优化、多线程与并行处理,以及
PFC 5.0二次开发宝典:API接口使用与自定义扩展
# 摘要
本文深入探讨了PFC 5.0的技术细节、自定义扩展的指南以及二次开发的实践技巧。首先,概述了PFC 5.0的基础知识和标准API接口,接着详细分析了AP
【台达VFD-B变频器与PLC通信集成】:构建高效自动化系统的不二法门

# 摘要
本文综合介绍了台达VFD-B变频器与PLC通信的关键技术,涵盖了通信协议基础、变频器设置、PLC通信程序设计、实际应用调试以及高级功能集成等各个方面。通过深入探讨通信协议的基本理论,本文阐述了如何设置台达VFD-B变频器以实现与PLC的有效通信,并提出了多种调试技巧与参数优化策略,以解决实际应用中的常见问题。此外,本文
【ASM配置挑战全解析】:盈高经验分享与解决方案

# 摘要
自动存储管理(ASM)作为数据库管理员优化存储解决方案的核心技术,能够提供灵活性、扩展性和高可用性。本文深入介绍了ASM的架构、存储选项、配置要点、高级技术、实践操作以及自动化配置工具。通过探讨ASM的基础理论、常见配置问题、性能优化、故障排查以及与RAC环境的集成,本文旨在为数据库管理员提供全面的配置指导和操作建议。文章还分析了ASM在云环境中的应用前景、社区资源和
【自行车码表耐候性设计】:STM32硬件防护与环境适应性提升

# 摘要
本文详细探讨了自行车码表的设计原理、耐候性设计实践及软硬件防护机制。首先介绍自行车码表的基本工作原理和设计要求,随后深入分析STM32微控制器的硬件防护基础。接着,通过研究环境因素对自行车码表性能的影响,提出了相应的耐候性设计方案,并通过实验室测试和现场实验验证了设计的有效性。文章还着重讨论了软件防护机制,包括设计原则和实现方法,并探讨了软硬件协同防护
STM32的电源管理:打造高效节能系统设计秘籍
# 摘要
随着嵌入式系统在物联网和便携设备中的广泛应用,STM32微控制器的电源管理成为提高能效和延长电池寿命的关键技术。本文对STM32电源管理进行了全面的概述,从理论基础到实践技巧,再到高级应用的探讨。首先介绍了电源管理的基本需求和电源架构,接着深入分析了动态电压调节技术、电源模式和转换机制等管理策略,并探讨了低功耗模式的实现方法。进一步地,本文详细阐述了软件工具和编程技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )