基于神经网络的翻译模型初探
发布时间: 2024-02-22 05:12:04 阅读量: 38 订阅数: 25 
# 1. 翻译模型概述
## 1.1 传统机器翻译与神经网络翻译模型的对比
在本节中,我们将对传统机器翻译方法和神经网络翻译模型进行对比分析,探讨它们的优缺点和应用场景。
## 1.2 神经网络翻译模型的发展历程
本节将介绍神经网络翻译模型从起源发展至今的历程,包括各种经典模型的提出和改进。
## 1.3 神经网络翻译模型的基本原理
在这一节中,我们将深入探讨神经网络翻译模型的基本原理,包括编码器-解码器结构、注意力机制等核心概念。
# 2. 神经网络在翻译模型中的应用
神经网络在翻译模型中扮演着至关重要的角色,它通过深度学习的方式实现了对文本数据的建模与处理,从而提高了翻译质量和效率。本章将深入探讨神经网络在翻译模型中的具体应用。
### 2.1 神经网络在文本特征提取中的作用
在翻译模型中,神经网络通过编码器-解码器结构进行文本特征提取和转换。编码器负责将源语言文本编码成语义向量表示,解码器则根据这些语义向量生成目标语言文本。神经网络通过多层神经元网络学习源语言句子的语义信息,从而更好地理解和翻译文本。
```python
import tensorflow as tf
class Encoder(tf.keras.layers.Layer):
def __init__(self, vocab_size, embedding_dim, enc_units, batch_sz):
super(Encoder, self).__init__()
self.batch_sz = batch_sz
self.enc_units = enc_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(self.enc_units, return_sequences=True, return_state=True)
def call(self, x, hidden):
x = self.embedding(x)
output, state = self.gru(x, initial_state=hidden)
return output, state
def initialize_hidden_state(self):
return tf.zeros((self.batch_sz, self.enc_units))
# 实例化编码器
encoder = Encoder(vocab_size, embedding_dim, enc_units, batch_sz)
```
### 2.2 神经网络在翻译模型中的架构设计
神经网络翻译模型通常采用Seq2Seq结构,包括编码器和解码器两部分。编码器将源语言句子编码成固定长度的向量表示,解码器通过这个向量生成目标语言句子。神经网络的架构设计直接影响着翻译质量和性能,如注意力机制的引入可以提高对长距离依赖的处理能力。
```python
import tensorflow as tf
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W1 = tf.keras.layers.Dense(units)
self.W2 = tf.keras.layers.Dense(units)
self.V = tf.keras.layers.Dense(1)
def call(self, query, values):
query_with_time_axis = tf.expand_dims(query, 1)
score = self.V(tf.nn.tanh(self.W1(query_with_time_axis) + self.W2(values)))
attention_weights = tf.nn.softmax(score, axis=1)
context_vector = attention_weights * values
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights
# 实例化注意力机制
attention_layer = BahdanauAttention
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《统计机器翻译》专栏深度探究了统计机器翻译领域的诸多关键技术和发展趋势。从词对齐技术在翻译中的作用到短语和句子的翻译模型,再到语言模型对翻译的影响,全面解析了统计机器翻译的关键环节。此外,专栏更关注基于神经网络的翻译模型应用,深入讨论了神经网络翻译模型的训练与优化,以及注意力机制在神经网络机器翻译中的应用。此外,还研究了Transformer模型的特性及其在机器翻译中的应用,以及无监督学习在统计机器翻译中的潜力。最后,专栏聚焦领域自适应翻译技术的发展与应用,以及多语种翻译模型的设计与挑战。通过这些深入剖析,读者可以全面了解统计机器翻译领域的最新动态和发展趋势。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【色彩理论揭秘】:RGB与CMYK对比分析,专家告诉你如何选择
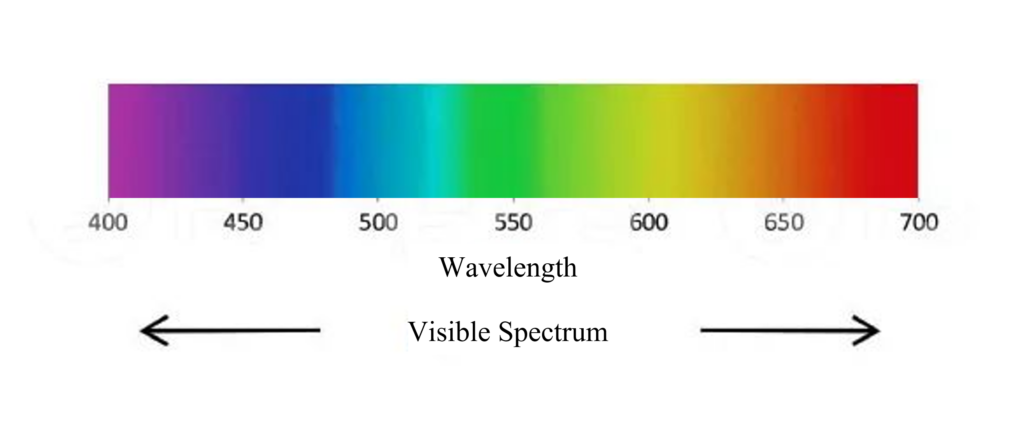
参考资源链接:[色温所对及应的RGB颜色表](https://wenku.csdn.net/doc/6412b77bbe7fbd1778d4a745?spm=1055.2635.3001.10343)
# 1. 色彩理论基础
色彩理论是视觉设计的基石,它涉及到光、视觉感知和色彩的应用。本章将对色彩
【负载均衡】:掌握MetroPro负载均衡策略,提升系统吞吐量
.webp)
参考资源链接:[Zygo MetroPro干涉仪分析软件用户指南](https://wenku.csdn.net/doc/2tzyqsmbur?spm=1055.2635.3001.10343)
# 1. 负载均衡基础概念解析
## 1.1 负载均衡的定义
负载均衡是现代网络架构中不可或缺的一部分,其主要作用是将访问流量分发到多台服务器,以
【Keil uVision4中代码覆盖率分析】:提升代码质量的利器
参考资源链接:[Keil uVision4:单片机开发入门与工程创建指南](https://wenku.csdn.net/doc/64930b269aecc961cb2ba7f9?spm=1055.2635.3001.10343)
# 1. 代码覆盖率分析概述
代码覆盖率分析是软件质量保证中的一项关键
STM32F407基础教程

参考资源链接:[STM32F407中文手册:ARM内核微控制器详细指南](https://wenku.csdn.net/doc/6412b69dbe7fbd1778d475ae?spm=1055.2635.3001.10343)
# 1. STM32F407微控制器概述
## 1.1 STM32F407简介
STM32F407是STMicroelectronics(意法半导体)生产的一款高性能ARM Cortex-M4微控制器
Linux数据库管理:MySQL与PostgreSQL服务器配置精讲

参考资源链接:[Linux命令大全完整版(195页).pdf](https://wenku.csdn.net/doc/6461a4a65928463033b2078b?spm=1055.2635.3001.10343)
# 1. Linux数据库管理概述
Linux操作系统作为开源软件的典范,广泛
市场趋势与行业分析:GL3227E的现状与未来展望
参考资源链接:[GL3227E USB 3.1 Gen1 eMMC控制器详细数据手册](https://wenku.csdn.net/doc/6401abbacce7214c316e947e?spm=1055.2635.3001.10343)
# 1. GL3227E市场概述与技术基础
## 1.1 GL3227E的市场定位
GL3227E是一款在市场上具有独特定位
基恩士SR-1000扫码枪行业应用案例:探索不同领域的高效解决方案
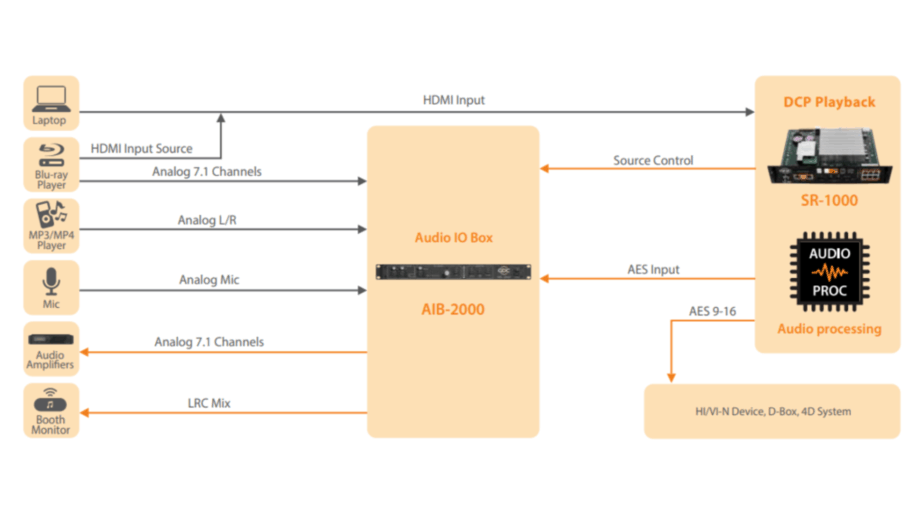
参考资源链接:[基恩士SR-1000系列扫码枪详细配置与通信指南](https://wenku.csdn.net/doc/tw17ibkwe9?spm=1055.2635.3001.10343)
# 1. 基恩士SR-1000扫码枪概述
在当今数字化管理的浪潮中,基恩士SR-1000扫码枪作为一款高效的数据采集工具,在工业自动化与信息化领域扮演
【消费电子趋势预测】:复旦微电子PSOC的应用前景分析

参考资源链接:[复旦微电子FMQL10S400/FMQL45T900可编程融合芯片技术手册](https://wenku.csdn.net/doc/7rt5s6sm0s?spm=1055.2635.3001.10343)
# 1. 消费电子行业与微电子技术概览
## 微电子技术的起源与进化
微电子技术,作为20世纪后半叶科技革命的重要推手,其起源可追溯至1958年集成电路的发明。从那时起,这项技术便伴随着摩尔定律不断进化,推动
【动态系统分析】:从理论到实战,Vensim的深入解读

参考资源链接:[Vensim模拟软件中文教程:快速参考与操作指南](https://wenku.csdn.net/doc/82bzhbrtyb?spm=1055.2635.3001.10343)
# 1. 动态系统分析概述
## 1.1 动态系统分析的定
3Par存储多站点复制与灾备:解决方案,打造企业数据安全网

参考资源链接:[3Par存储详尽配置指南:初始化与管理详解](https://wenku.csdn.net/doc/6412b6febe7fbd1778d48b52?spm=1055.2635.3001.10343)
# 1. 3Par存储与多站点复制基础
## 1.1 3Par存储技术简介
3Par存储技术,由Hewlet
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )