Python Decorators高级应用:类与装饰器结合的5种创新用法
发布时间: 2024-10-16 18:58:58 阅读量: 24 订阅数: 26 

python-装饰器Decorators.pdf
# 1. Python Decorators概述
Python Decorators是一种设计模式,允许用户在不修改原有函数或方法定义的情况下,动态地给它们添加新的功能。这种模式在保持原有功能的基础上,为函数的执行提供了额外的控制层。Decorators通常用于日志记录、性能测试、权限检查等场景。
## 装饰器的基本概念和结构
在Python中,装饰器本质上是一个函数,它接受一个函数作为参数,并返回一个新的函数。新的函数通常会包含对原始函数的调用,并在其前后增加一些额外的操作。以下是一个简单的装饰器示例:
```python
def my_decorator(func):
def wrapper():
print("Something is happening before the function is called.")
func()
print("Something is happening after the function is called.")
return wrapper
@my_decorator
def say_hello():
print("Hello!")
say_hello()
```
在这个例子中,`my_decorator`是一个装饰器,它定义了一个内部函数`wrapper`,该函数在调用原始函数`say_hello`之前和之后打印一些文本。使用`@my_decorator`语法,我们可以将这个装饰器应用到`say_hello`函数上,无需修改其内部逻辑。
装饰器的使用使得代码更加模块化和可复用,同时也提供了一种优雅的方式来修改或增强函数的行为。接下来的章节我们将深入探讨装饰器与类结合的创新用法,以及它们在实际应用中的高级实践和案例分析。
# 2. 类与装饰器的基础
## 2.1 装饰器的基本概念和结构
在Python中,装饰器是一种设计模式,它允许用户在不修改原有函数定义的情况下,为函数添加新的功能。装饰器本质上是一个函数,它接受另一个函数作为参数,并返回一个新的函数。这个新函数通常会在原函数的基础上增加一些额外的操作,比如日志记录、性能监控、权限验证等。
装饰器的结构通常包含以下几个部分:
1. **定义装饰器函数**:这是一个接受函数作为参数的函数,它本身也返回一个函数。
2. **原始函数的包装**:在装饰器函数内部,通常会定义一个内部函数,这个内部函数会调用原始函数,并添加额外的代码。
3. **返回包装函数**:装饰器函数最后返回内部函数。
```python
def decorator(func):
def wrapper():
# 在原始函数执行前执行的代码
result = func() # 调用原始函数
# 在原始函数执行后执行的代码
return result
return wrapper
```
在本章节中,我们将深入探讨类与装饰器结合的基础知识,为后续章节的学习打下坚实的基础。
## 2.2 类的基本概念和特性
类是面向对象编程的基础,它定义了一组属性(变量)和方法(函数)的蓝图。通过类,可以创建具有相同属性和方法的对象,这些对象被称为类的实例。
类的特性主要包括:
- **封装**:类可以将数据(属性)和行为(方法)封装在一起,隐藏内部实现细节,只暴露必要的接口。
- **继承**:类可以继承另一个类的属性和方法,从而复用代码。
- **多态**:不同类的对象可以对同一消息做出不同的响应。
## 2.3 类与装饰器结合的理论基础
当装饰器与类结合时,我们可以创建类装饰器,这些装饰器可以用于修改类的行为或增强类的功能。类装饰器通常是接受一个类作为参数,并返回一个新类的函数。
类装饰器的基本结构如下:
```python
def class_decorator(cls):
# 在这里修改类的行为或增强类的功能
return cls
```
通过类装饰器,我们可以在不修改类定义的情况下,实现以下功能:
- **修改类的元数据**:如类名、文档字符串等。
- **修改类的方法**:动态地添加、修改或删除类的方法。
- **实现单例模式**:确保类只创建一个实例。
通过本章节的介绍,我们可以看到类与装饰器结合的基本概念和理论基础。在下一章中,我们将探索类与装饰器结合的五种创新用法,并通过实例深入理解它们的应用。
# 3. 类与装饰器结合的五种创新用法
#### 3.1 用法一:缓存实例状态
##### 3.1.1 实例方法的缓存策略
在Python中,缓存实例状态是一种常见的性能优化手段。当我们创建类的实例时,可能会执行一些计算成本较高的操作,这时候我们可以利用装饰器来缓存这些操作的结果,避免重复计算。这种策略在处理具有昂贵计算开销的实例方法时尤其有用。
例如,我们可以创建一个装饰器来缓存一个方法的结果,如下所示:
```python
def method_cache(func):
cache = {}
def wrapper(self, *args):
if (func, args) in cache:
return cache[(func, args)]
else:
result = func(self, *args)
cache[(func, args)] = result
return result
return wrapper
class MyClass:
@method_cache
def compute_expensive(self, arg):
# 这里假设是一个复杂的计算过程
return sum([i for i in range(1000000)])
```
在这个例子中,`method_cache` 装饰器会检查缓存中是否已经存在某个方法的结果,如果存在,则直接返回缓存的结果;如果不存在,则执行方法,并将结果存入缓存中。
##### 3.1.2 类变量的应用和限制
类变量是属于类的属性,而不是类的实例属性。这意味着它们被类的所有实例共享。在缓存实例状态时,如果我们使用类变量来存储缓存结果,可能会导致不期望的共享行为。但是,如果我们合理地使用类变量,它也可以成为一种有效的缓存策略。
例如,我们可以在类级别定义一个缓存字典:
```python
class MyClass:
_cache = {}
def __init__(self):
self.cache_key = None
def get_cached_data(self, key):
return MyClass._cache.get(key)
def set_cached_data(self, key, value):
MyClass._cache[key] = value
@classmethod
def clear_cache(cls):
cls._cache.clear()
```
在这个例子中,我们可以使用类方法 `get_cached_data` 和 `set_cached_data` 来存取缓存数据。这种方式的好处是缓存与类的实例解耦,可以在不同的实例之间共享数据。
#### 3.2 用法二:动态添加方法
##### 3.2.1 动态方法的原理
动态添加方法是面向对象编程中的一个高级特性,它允许我们在运行时向类添加方法。这种技术可以在不修改类定义的情况下,为类增加新的行为。在Python中,我们可以利用装饰器来实现这一功能。
例如,我们可以定义一个装饰器来动态添加一个方法:
```python
def add_method(cls):
def decorator(func):
setattr(cls, func.__name__, func)
return func
return decorator
@add_method(MyClass)
def new_method(self):
return "Hello, World!"
```
在这个例子中,`add_method` 装饰器接受一个类作为参数,并返回一个新的装饰器。这个新的装饰器接受一个函数作为参数,并使用 `setattr` 将该函数作为类的一个属性。
##### 3.2.2 实现动态方法的步骤和示例
为了实现动态方法,我们需要定义一个装饰器工厂 `add_method`,它返回一个装饰器,这个装饰器将函数添加到类的属性中。这个过程分为以下几个步骤:
1. 定义一个装饰器工厂 `add_method`,它接受一个类作为参数。
2. 在 `add_method` 中定义一个装饰器,它接受一个函数 `func` 作为参数。
3. 使用 `setattr` 将 `func` 作为类的属性,这样就可以在类的实例上调用这个函数。
以下是完整的示例代码:
```python
class MyClass:
pass
def add_method(cls):
def decorator(func):
setattr(cls, func.__name__, func)
return func
return decorator
@add_method(MyClass)
def new_method(self):
return "Hello, World!"
my_instance = MyClass()
print(my_instance.new_method()) # 输出: Hello, World!
```
在这个例子中,我们成功地为 `MyClass` 类动态添加了一个名为 `new_method` 的方法。这个方法在类的实例上调用时会返回一个字符串。
#### 3.3 用法三:创建上下文管理器
##### 3.3.1 上下文管理器的基本概念
上下文管理器是Python中的一种资源管理机制,它允许我们管理资源的分配和释放,确保资源在使用后能够被正确地释放。上下文管理器通常通过实现 `__enter__` 和 `__exit__` 方法来创建。这两个方法分别在进入和退出代码块时被调用。
上下文管理器的一个典型应用是 `with` 语句,它可以自动管理资源的生命周期。
##### 3.3.2 结合类和装饰器创建上下文管理器
我们可以结合类和装饰器来创建上下文管理器,这样可以使代码更加简洁和优雅。下面是一个示例:
```python
from contextlib import contextmanager
class MyClass:
def __init__(self):
self.conn = None
@contextmanager
def open_connection(self, url):
self.conn = self.connect_to_database(url)
yield
self.disconnect_from_database()
def connect_to_database(self, url):
print(f"Connecting to {url}")
# 这里应该是连接数据库的代码
return "conn"
def disconnect_from_database(self):
print("Disconnecting")
# 这里应该是断开数据库连接的代码
# 使用上下文管理器
my_instance = MyClass()
with my_instance.open_connection("***") as conn:
print(f"Using {conn}")
# 输出:
# Connecting to ***
```
在这个例子中,我们定义了一个 `MyClass` 类,它有一个 `open_connection` 方法,这个方法使用 `contextmanager` 装饰器来创建一个上下文管理器。这个上下文管理器负责连接和断开数据库连接。使用 `with` 语句时,`__enter__` 方法会被自动调用以建立连接,而 `__exit__` 方法会在退出 `with` 代码块时被调用以断开连接。
#### 3.4 用法四:实现单例模式
##### 3.4.1 单例模式的定义和用途
单例模式是一种设计模式,它确保一个类只有一个实例,并提供一个全局访问点来获取这个实例。单例模式在需要确保全局只有一个实例的情况下非常有用,例如,对于数据库连接或者配置管理器等。
##### 3.4.2 利用装饰器实现单例模式
我们可以利用装饰器来实现单例模式。下面是一个示例:
```python
def singleton(cls):
instances = {}
def get_instance(*args, **kwargs):
if cls not in instances:
instances[cls] = cls(*args, **kwargs)
return instances[cls]
return get_instance
@singleton
class MyClass:
def __init__(self, value):
self.value = value
my_instance1 = MyClass(10)
my_instance2 = MyClass(20)
print(my_instance1.value) # 输出: 10
print(my_instance2.value) # 输出: 10
print(my_instance1 is my_instance2) # 输出: True
```
在这个例子中,`singleton` 装饰器接受一个类 `cls` 作为参数,并返回一个函数 `get_instance`。这个函数检查 `instances` 字典中是否已经存在 `cls` 的一个实例,如果不存在,则创建一个新的实例;如果存在,则返回已有的实例。这样,无论我们创建多少次 `MyClass` 的实例,都只会得到同一个实例。
#### 3.5 用法五:装饰器的类型检查
##### 3.5.1 类型提示和类型检查的必要性
随着Python版本的更新,类型提示(Type Hints)已经被引入到Python中,它允许开发者在代码中指定变量、函数参数和返回值的类型。类型检查可以帮助我们在代码运行前发现潜在的类型错误,提高代码的可读性和可维护性。
##### 3.5.2 结合类和装饰器进行类型检查
我们可以结合类和装饰器来进行类型检查。下面是一个示例:
```python
from typing import TypeVar, Callable, Dict
from functools import wraps
T = TypeVar('T')
def type_check(cls: T) -> T:
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
assert all(isinstance(arg, cls) for arg in args), "All arguments must be instances of MyClass"
return func(*args, **kwargs)
return wrapper
return decorator
class MyClass:
def __init__(self, value):
self.value = value
@type_check(MyClass)
def process_instance(instance: MyClass):
return instance.value
my_instance = MyClass(10)
print(process_instance(my_instance)) # 输出: 10
# 下面的调用将会抛出断言错误,因为参数不是 MyClass 的实例
try:
process_instance(10)
except AssertionError as e:
print(e) # 输出: All arguments must be instances of MyClass
```
在这个例子中,`type_check` 装饰器接受一个类 `cls` 作为参数,并返回一个新的装饰器 `decorator`。这个装饰器接受一个函数 `func` 作为参数,并使用 `wraps` 来保留原函数的元数据。装饰器的 `wrapper` 函数会检查所有参数是否为 `cls` 的实例,如果不是,则抛出断言错误。这样,我们就可以在函数调用时进行类型检查,确保参数的类型正确。
通过本章节的介绍,我们了解了类与装饰器结合的五种创新用法,包括缓存实例状态、动态添加方法、创建上下文管理器、实现单例模式以及装饰器的类型检查。这些用法展示了类与装饰器结合的强大功能,以及在实际开发中的应用价值。下一章我们将探讨类与装饰器的高级实践,包括构建装饰器工厂、装饰器的性能优化以及装饰器的调试和测试。
# 4. 类与装饰器的高级实践
在本章节中,我们将深入探讨类与装饰器结合的高级实践,这些实践不仅能够帮助我们更好地理解装饰器的工作原理,还能够提升我们的代码质量,优化性能,并且提高代码的可维护性和可测试性。我们将从构建装饰器工厂、性能优化、调试和测试三个方面进行探讨。
## 实践一:构建装饰器工厂
装饰器工厂是装饰器的一个高级应用,它可以让我们根据不同的需求动态创建装饰器。这种模式在需要根据外部参数改变装饰器行为的场景中非常有用。
### 工厂模式的基本原理
工厂模式是一种创建型设计模式,用于创建对象时,让子类决定实例化哪一个类。工厂方法让类的实例化推迟到子类中进行。在装饰器工厂中,我们通常会定义一个接受参数的工厂函数,该函数返回一个装饰器。
### 创建可配置的装饰器工厂
下面是一个简单的装饰器工厂的例子,它接受一个参数并返回一个装饰器,该装饰器记录函数调用次数。
```python
from functools import wraps
import time
def timer_factory(prefix=""):
def timer_decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
print(f"{prefix}{func.__name__} took {end_time - start_time}s")
return result
return wrapper
return timer_decorator
# 使用装饰器工厂
@timer_factory(prefix="Operation: ")
def my_function():
time.sleep(2)
my_function()
```
在这个例子中,`timer_factory`是一个工厂函数,它接受一个`prefix`参数,并返回一个`timer_decorator`装饰器。`timer_decorator`装饰器记录被装饰函数的执行时间,并打印出来。
## 实践二:装饰器的性能优化
装饰器虽然功能强大,但也可能引入性能瓶颈。本小节将介绍如何优化装饰器性能,并提供实践案例。
### 装饰器的性能瓶颈
装饰器可能会引入额外的函数调用,这些调用会增加函数执行的开销。例如,如果我们有一个简单的装饰器:
```python
import functools
def simple_decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
print("Decorator called")
return func(*args, **kwargs)
return wrapper
@simple_decorator
def my_function():
print("Function called")
```
在这个例子中,每次调用`my_function`时,`simple_decorator`都会先被调用。如果`my_function`是一个高频调用的函数,这种额外的调用可能会成为一个性能瓶颈。
### 优化策略和实践案例
为了避免性能瓶颈,我们可以采用一些优化策略:
1. 使用缓存减少重复调用。
2. 减少装饰器内部的计算量。
3. 使用内置函数或库提供的装饰器来减少额外开销。
例如,我们可以使用`functools.lru_cache`来缓存装饰器的结果:
```python
import functools
@functools.lru_cache(maxsize=None)
def my_decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
print("Decorator called")
return func(*args, **kwargs)
return wrapper
@my_decorator
def my_function():
print("Function called")
```
在这个例子中,`my_decorator`使用了`lru_cache`来缓存装饰器的结果,从而减少了不必要的函数调用。
## 实践三:装饰器的调试和测试
调试和测试装饰器是确保代码质量和可维护性的关键步骤。本小节将介绍如何调试和测试装饰器。
### 装饰器调试的技术和方法
装饰器的调试可能比较复杂,因为它涉及到函数的封装和元编程。以下是一些常用的调试技术:
1. 使用`functools.wraps`保留被装饰函数的元信息。
2. 打印日志来跟踪函数的调用和返回。
3. 使用`pdb`等调试工具进行断点调试。
### 测试装饰器的策略和工具
装饰器的测试需要确保装饰器的行为符合预期。以下是一些常用的测试策略:
1. 测试装饰器的基本功能,如参数包装、返回值修改等。
2. 测试装饰器的边界条件和异常情况。
3. 使用`unittest.mock`库中的`patch`功能来模拟装饰器的行为。
例如,我们可以使用`unittest`框架来测试一个简单的装饰器:
```python
import unittest
from unittest.mock import patch
def simple_decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
print("Decorator called")
return func(*args, **kwargs)
return wrapper
@simple_decorator
def my_function():
print("Function called")
class TestDecorator(unittest.TestCase):
@patch('builtins.print')
def test_decorator(self, mock_print):
my_function()
mock_print.assert_called_once_with("Decorator called")
if __name__ == '__main__':
unittest.main()
```
在这个例子中,我们使用`unittest`和`patch`来测试`simple_decorator`装饰器是否按预期打印出装饰器调用的消息。
# 5. 类与装饰器的案例分析
在本章节中,我们将深入探讨类与装饰器在不同领域的实际应用案例,以及它们如何在真实世界中发挥作用。通过对这些案例的分析,我们不仅能够理解类与装饰器结合的强大功能,还能够学习如何将这些概念应用到我们自己的项目中。
## 案例一:Web框架中的装饰器应用
Web框架如Django和Flask都广泛使用装饰器来实现各种功能。装饰器在这里被用来处理HTTP请求和响应,进行身份验证、权限检查、路由分发等。我们将通过分析Flask中的路由装饰器来了解装饰器在Web开发中的应用。
### Flask中的路由装饰器
Flask使用装饰器`@app.route`来将一个函数绑定到一个URL上,这是装饰器在Web开发中最直观的应用之一。下面是一个简单的示例:
```python
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'
if __name__ == '__main__':
app.run(debug=True)
```
在这个例子中,`@app.route('/')`是一个装饰器,它告诉Flask当用户访问根URL('/')时,应该调用`hello_world`函数。装饰器背后的工作原理是通过修改函数对象的`__dict__`属性来实现的,这样Flask就可以知道URL和处理函数之间的映射关系。
#### 实现自定义路由装饰器
我们可以自己实现一个类似的装饰器来加深理解:
```python
def my_route(rule, **options):
def decorator(func):
def wrapper(*args, **kwargs):
return func(*args, **kwargs)
app.add_url_rule(rule, endpoint=func.__name__, view_func=wrapper, **options)
return wrapper
return decorator
app = Flask(__name__)
@app.my_route('/about')
def about():
return 'About Us'
if __name__ == '__main__':
app.run(debug=True)
```
在这个自定义装饰器中,我们首先定义了一个装饰器工厂`my_route`,它接受URL规则和选项,并返回一个新的装饰器。这个装饰器修改了传入函数的`__dict__`属性,并将新的路由规则添加到Flask应用中。
### 参数说明和逻辑分析
在这个自定义路由装饰器的实现中,`my_route`是一个装饰器工厂函数,它接受URL规则(`rule`)和可选的关键字参数(`**options`)。这个工厂函数返回一个新的装饰器,这个装饰器接受一个函数`func`作为参数,并返回一个包装函数`wrapper`。
当`wrapper`被调用时,它实际上调用的是原始函数`func`。`app.add_url_rule`是Flask的一个方法,用于添加一个URL规则到Flask应用中,其中`endpoint`参数是这个URL规则的唯一标识符,`view_func`参数是处理这个URL的视图函数。
## 案例二:自动化测试框架中的装饰器应用
在自动化测试框架中,如pytest,装饰器被用来标记测试函数、设置测试环境、收集测试数据等。我们将分析pytest中的`@pytest.mark`装饰器,它用于标记测试函数以便进行特定的处理。
### 使用pytest.mark进行测试标记
pytest允许我们使用`@pytest.mark`装饰器来标记测试函数,这样我们可以根据标记来选择运行特定的测试。这是一个常见的用法示例:
```python
import pytest
@pytest.mark.parametrize("test_input,expected", [(1, 2), (2, 3)])
def test_increment(test_input, expected):
assert increment(test_input) == expected
def increment(x):
return x + 1
```
在这个例子中,`@pytest.mark.parametrize`是一个装饰器,它接受一个参数列表和预期结果列表,用于数据驱动测试。
#### 代码逻辑解读
`@pytest.mark.parametrize`装饰器接受一个字符串参数`test_input`和一个整数参数`expected`。这个装饰器的作用是为`test_increment`函数提供多组输入和预期输出,以便进行数据驱动测试。
当pytest运行测试时,它会自动为每组输入和预期输出调用`test_increment`函数。这样,我们就可以验证`increment`函数对不同输入的处理是否正确。
## 案例三:数据处理框架中的装饰器应用
在数据处理框架如Pandas中,装饰器可以用来优化数据处理流程,缓存中间结果,或者修改DataFrame的行为。我们将通过一个例子来了解如何在Pandas中使用装饰器来缓存DataFrame转换的结果。
### 使用装饰器缓存DataFrame转换结果
在数据科学中,经常需要对DataFrame进行多次转换,这些转换可能是计算密集型的。使用装饰器来缓存转换结果可以显著提高性能。
```python
from functools import lru_cache
import pandas as pd
@lru_cache(maxsize=128)
def transform_dataframe(df):
# 假设这是一个计算密集型的转换
return df.applymap(lambda x: x.upper())
data = {'Name': ['Tom', 'Nick', 'Krish', 'Jack'], 'Age': [20, 21, 19, 18]}
df = pd.DataFrame(data)
# 转换DataFrame
transformed_df = transform_dataframe(df)
```
在这个例子中,我们使用了`functools.lru_cache`装饰器来缓存`transform_dataframe`函数的结果。这个装饰器使用最近最少使用(LRU)算法来缓存函数调用结果。
#### 代码逻辑解读
`@lru_cache(maxsize=128)`装饰器被应用到`transform_dataframe`函数上。这个函数接受一个DataFrame对象`df`,并返回一个新的DataFrame对象,其中所有的字符串都被转换为大写。
当`transform_dataframe`函数被调用时,`lru_cache`装饰器会检查这个函数调用是否已经被缓存过。如果是,它会直接返回缓存的结果,否则它会执行函数并缓存结果。
### 总结
在本章节中,我们通过分析类与装饰器在Web框架、自动化测试框架和数据处理框架中的实际应用案例,深入了解了它们在不同领域的强大功能。这些案例展示了装饰器如何被用来简化代码、提高性能和增加功能灵活性。通过对这些案例的学习,我们可以更好地理解装饰器和类结合的潜力,并将这些概念应用到我们自己的项目中,从而提高我们的开发效率和代码质量。
# 6. 类与装饰器的未来趋势
随着Python语言的不断进化,类与装饰器的结合使用也在不断地发展和演变。在这一章节中,我们将探讨装饰器在Python新版本中的改进、类与装饰器在其他编程范式中的应用,以及类与装饰器结合的新兴技术趋势。
## 6.1 装饰器在Python新版本中的改进
Python作为一门不断进步的语言,其新版本中对装饰器的支持也在不断增强。从Python 3.5开始,装饰器相关的PEP提案(如PEP 484)引入了类型提示,这为装饰器带来了类型检查的能力。到了Python 3.9,我们已经可以使用更清晰的语法来定义装饰器工厂。
```python
from typing import Callable, TypeVar, Any, cast
T = TypeVar('T')
def my_decorator(f: Callable[..., T]) -> Callable[..., T]:
def wrapper(*args, **kwargs):
print("Something is happening before the function is called.")
result = f(*args, **kwargs)
print("Something is happening after the function is called.")
return result
return wrapper
@my_decorator
def say_hello(name: str) -> str:
return f"Hello, {name}!"
print(say_hello("Alice"))
```
在这个例子中,我们定义了一个装饰器工厂`my_decorator`,它可以接受任何函数`f`并返回一个包装函数`wrapper`,该包装函数在原函数执行前后添加了额外的行为。
## 6.2 类与装饰器在其他编程范式中的应用
虽然装饰器和类的组合在面向对象编程中非常常见,但它们也可以在其他编程范式中发挥作用。例如,在函数式编程中,装饰器可以用于创建高阶函数,它们可以接受其他函数作为参数并返回一个新的函数。
```python
def repeat(times: int):
def decorator(f: Callable):
def wrapper(*args, **kwargs):
for _ in range(times):
result = f(*args, **kwargs)
return result
return wrapper
return decorator
@repeat(times=3)
def greet(name: str) -> str:
return f"Hello, {name}!"
print(greet("Bob"))
```
在这个例子中,`repeat`装饰器创建了一个高阶函数,它重复执行被装饰的函数指定的次数。这展示了装饰器在不直接涉及类的情况下如何用于函数式编程。
## 6.3 类与装饰器结合的新兴技术趋势
随着技术的不断发展,类与装饰器的结合也在新兴技术中找到了应用。例如,在云计算和微服务架构中,装饰器可以用于自动化的资源管理和分布式跟踪。
```python
from flask import Flask, request
import opentelemetry
app = Flask(__name__)
@opentelemetry.Decorator()
def trace_function(f):
def wrapper(*args, **kwargs):
with opentelemetry.tracer.start_as_current_span(f.__name__):
return f(*args, **kwargs)
return wrapper
@app.route('/hello')
@trace_function
def hello():
return f"Hello, World!"
app.run(debug=True)
```
在这个例子中,我们使用了`opentelemetry`库来跟踪每个Web请求的处理过程。装饰器`trace_function`自动为被装饰的函数添加了跟踪代码,这使得分布式系统的监控和调试变得更加容易。
通过上述内容,我们可以看到类与装饰器的结合不仅仅是面向对象编程的工具,它们在其他编程范式和技术趋势中也有着广泛的应用前景。随着Python语言的不断发展,我们可以预见类与装饰器的结合将在未来发挥更加重要的作用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 装饰器学习专栏!本专栏将深入探讨 Python 装饰器,从入门基础到高级应用,提供全面而实用的指南。
我们将揭秘 7 个打造高效装饰器的秘密技巧,掌握自定义装饰器的策略,探索类与装饰器结合的创新用法,以及编写可读装饰器的最佳实践。此外,还将深入分析装饰器的性能优化、调试方法、与其他高阶函数的对比,以及在 Web 开发、异步编程、安全性、兼容性、日志记录、缓存、参数校验、权限控制、单元测试、装饰器链、性能监控和异常处理中的应用。通过本专栏,您将全面掌握 Python 装饰器的方方面面,提升您的编程技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
微信小程序前端开发必读:表单交互的单选与多选按钮逻辑

# 摘要
微信小程序作为快速发展的应用平台,其表单元素的设计与实现对于用户体验至关重要。本文首先介绍了微信小程序表单元素的基础知识,重点讨论了单选按钮和多选按钮的实现原理、前端逻辑以及样式美化和用户体验优化。在第四章中,探讨了单选与多选在表单交互设计中的整合,以及数据处理和实际应用案例。第五章分析了表单数据的性能优化和安全性考虑,包括防止XSS和CSRF攻击以及数据加密。最后,第六章通过实战演
高级机器人控制算法实现:Robotics Toolbox深度剖析与实践
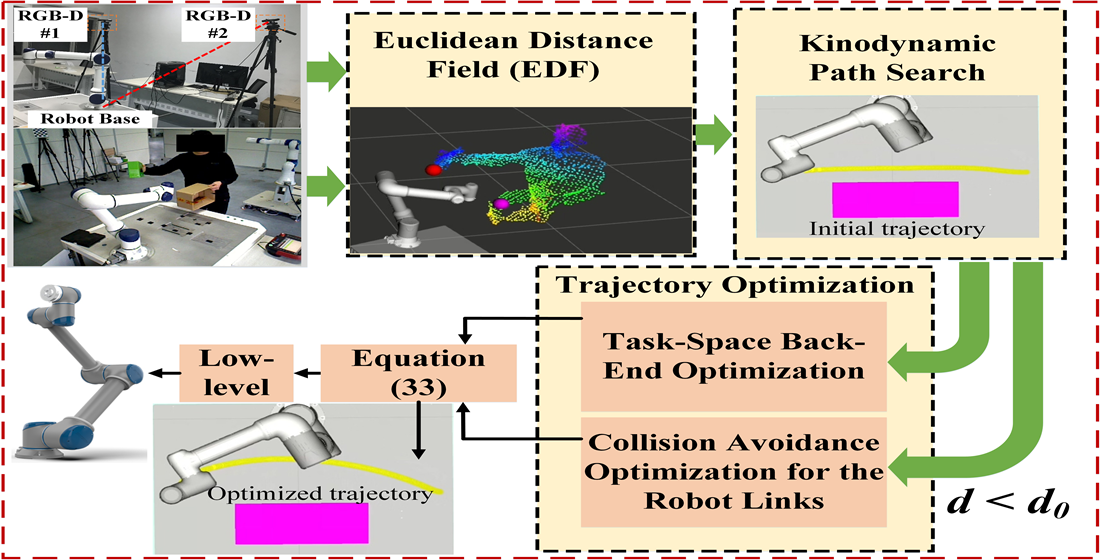
# 摘要
本文全面介绍机器人控制算法的理论基础和实践应用,重点讲解了Robotics Toolbox的理论与应用,并探讨了机器人视觉系统集成的有效方法。文章从基础理论出发,详细阐述了机器人运动学与动力学模型、控制策略以及传感器集成,进而转向实践,探讨了运动学分析、动力学仿真、视觉反馈控制策略及
TerraSolid实用技巧:提升你的数据处理效率,专家揭秘进阶操作详解!

# 摘要
TerraSolid软件作为专业的遥感数据处理工具,广泛应用于土木工程、林业监测和城市规划等领域。本文首先概述了TerraSolid的基本操作和数据处理核心技巧,强调了点云数据处理、模型构建及优化的重要性。随后,文章深入探讨了脚本自动化与自定义功能,这些功能能够显著提高工作效率和数据处理能力。在特定领域应用技巧章节中,本文分析了TerraSolid在土木、林
【目标代码生成技术】:从编译原理到机器码的6大步骤
# 摘要
本文旨在全面探讨目标代码生成技术,从编译器前端的词法分析和语法分析开始,详细阐述了抽象语法树(AST)的构建与优化、中间代码的生成与变换,到最终的目标代码生成与调度。文章首先介绍了词法分析器构建的关键技术和错误处理机制,然后讨论了AST的形成过程和优化策略,以
公钥基础设施(PKI)深度剖析:构建可信的数字世界
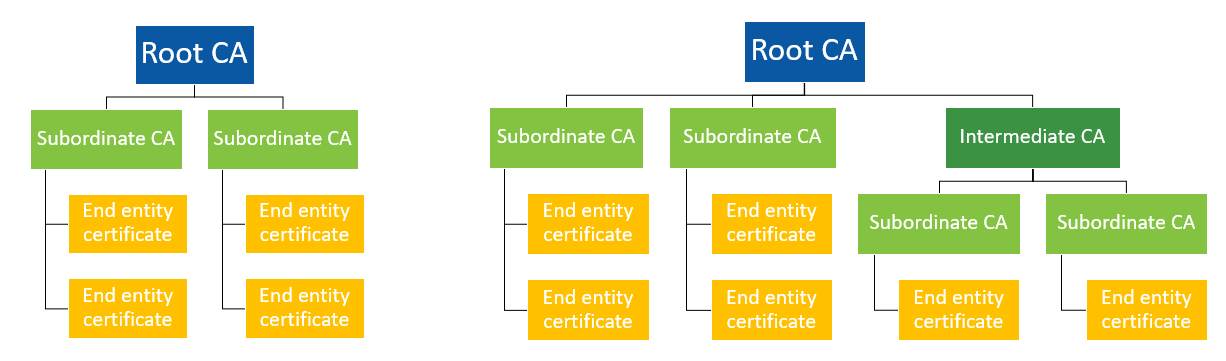
# 摘要
公钥基础设施(PKI)是一种广泛应用于网络安全领域的技术,通过数字证书的颁发与管理来保证数据传输的安全性和身份验证。本文首先对PKI进行概述,详细解析其核心组件包括数字证书的结构、证书认证机构(CA)的职能以及证书颁发和撤销过程。随后,文章探讨了PKI在SSL/TLS、数字签名与身份验证、邮件加密等领域的应用实践,指出其在网络安全中的重要性。接着,分析了PKI实施过程中的
硬件测试新视角:JESD22-A104F标准在电子组件环境测试中的应用
# 摘要
本文对JESD22-A104F标准进行了全面的概述和分析,包括其理论基础、制定背景与目的、以及关键测试项目如高温、低温和温度循环测试等。文章详细探讨了该标准在实践应用中的准备工作、测试流程的标准化执行以及结果评估与改进。通过应用案例分析,本文展示了JESD22-A104F标准在电子组件开发中的成功实践和面临的挑战,并提出了相应的解决方案。此外,本文还预测了标准的未来发展趋势,讨论了新技术、新材料的适应性,以及行业面临的挑战和合作交流的重要性。
# 关键字
JESD22-A104F标准;环境测试;高温测试;低温测试;温度循环测试;电子组件质量改进
参考资源链接:[【最新版可复制文字
MapReduce常见问题解决方案:大数据实验者的指南

# 摘要
MapReduce是一种广泛应用于大数据处理的编程模型,它通过简化的编程接口,允许开发者在分布式系统上处理和生成大规模数据集。本文首先对MapReduce的概念、核心工作流程、以及其高级特性进行详细介绍,阐述了MapReduce的优化策略及其在数据倾斜、作业性能调优、容错机制方面的常见问题和解决方案。接下来,文章通过实践案例,展示了MapReduce在不同行业的应用和效果。最后,本
【Omni-Peek教程】:掌握网络性能监控与优化的艺术

# 摘要
网络性能监控与优化是确保网络服务高效运行的关键环节。本文首先概述了网络性能监控的重要性,并对网络流量分析技术以及网络延迟和丢包问题进行了深入分析。接着,本文介绍了Omni-Peek工具的基础操作与实践应用,包括界面介绍、数据包捕获与解码以及实时监控等。随后,文章深入探讨了网络性能问题的诊断方法,从应用层和网络层两方面分析问题,并探讨了系统资源与网络性能之间的关系。最后,提出了网络性能优
【PCB设计:电源完整性的提升方案】
# 摘要
电源完整性作为电子系统性能的关键因素,对现代电子设备的稳定性和可靠性至关重要。本文从基本概念出发,深入探讨了电源完整性的重要性及其理论基础,包括电源分配网络模型和电源噪声控制理论。通过分析电源完整性设计流程、优化技术以及测试与故障排除策略,本文提供了电源完整性设计实践中的关键要点,并通过实际案例分析展示了高
【组合数学在电影院座位设计中的角色】:多样布局的可能性探索

# 摘要
本文探讨了组合数学与电影院座位设计的交汇,深入分析了组合数学基础及其在座位设计中的实际应用。文章详细讨论了集合与排列组合、组合恒等式与递推关系在空间布局中的角色,以及如何通过数学建模解决座位设计中的优化问题。此外,研究了电影院座位布局多样性、设计优化策略,以及实际案例分析,包括创新技术的应用与环境可持续性考量。最后,对电影院座位设计的未来趋势进行了预测,并讨论了相关挑战与应对策略。本文旨在提供一个全面的视角,将理论与实践相
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )