内核编译与定制大讲堂:掌握Kali Linux系统优化核心


kali手机内核编译汇总
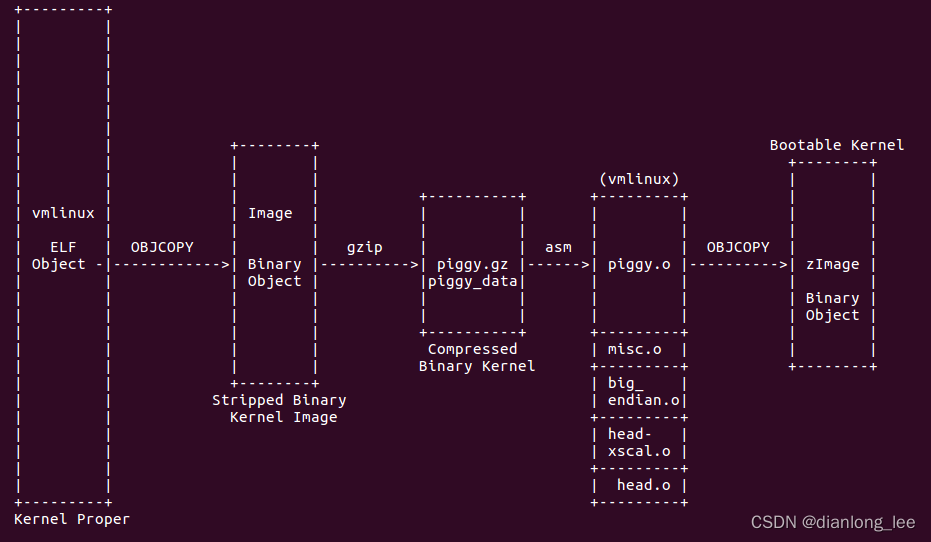
1. Kali Linux内核编译基础
在Linux系统中,内核是操作系统的核心部分,它负责管理硬件资源,提供系统服务,以及实现安全机制。Kali Linux作为一款被广泛用于渗透测试的系统,其内核的编译和优化对于用户来说至关重要。在本章中,我们将探讨内核编译的基础知识,介绍内核源码的结构,并概述编译流程的基本步骤,为之后的定制和优化打下坚实的基础。
1.1 内核编译的重要性
编译内核对于Linux用户来说是一项重要技能,因为它允许用户根据自己的需求来调整系统。例如,用户可能需要特定的驱动程序来支持硬件,或是希望优化系统以获得最佳性能。Kali Linux用户可能更关心的是,如何通过内核编译添加安全模块,以强化系统的安全性。
1.2 获取和准备Kali Linux内核源码
在开始编译之前,用户必须从官方源获取最新的Kali Linux内核源码。通常,这可以通过Kali Linux提供的软件包管理系统来完成。例如,在终端中执行以下命令来安装内核源码:
- apt update
- apt install kali-linux-source
1.3 编译和安装内核
一旦源码准备就绪,接下来的步骤包括配置内核选项、编译内核以及安装新编译的内核。这一过程涉及复杂的命令和选项,例如:
- cd linux-source-directory
- make menuconfig # 配置内核选项
- make # 编译内核
- make modules_install install # 安装内核和模块
通过这些步骤,用户可以创建一个定制的、与Kali Linux兼容的内核,这不仅提高了系统的性能,也增强了安全性。在后续章节中,我们将深入探讨内核定制、优化和安全加固的高级概念。
2. 内核定制的理论基础
2.1 内核结构解析
2.1.1 内核模块和组件
Linux内核是操作系统的核心部分,它负责管理和调度计算机硬件资源,提供系统服务,如文件系统、网络、进程管理等。内核模块和组件是内核灵活性和可扩展性的关键。模块化设计允许内核在不需要重新编译整个内核的情况下动态加载和卸载功能。主要的内核组件包括进程调度器、内存管理器、文件系统接口以及设备驱动程序。
模块化设计的好处包括:
- 减少启动时间和资源消耗:未使用的模块无需加载。
- 系统安全:错误或安全漏洞可以在不影响整个系统的情况下单独修复。
- 系统更新:更易维护和更新,仅需替换或添加模块。
理解这些模块和组件对于定制内核至关重要,因为你可以根据需要启用或禁用特定的功能。
2.1.2 内核配置选项
内核配置选项允许用户根据特定硬件和软件需求来定制内核。选项可能包括支持的硬件类型、文件系统、网络协议和安全特性等。配置选项通常在编译前设置,但许多选项也可以通过模块加载时的参数动态配置。
对配置选项的深入理解对于构建一个高效、安全的系统至关重要。默认配置往往倾向于通用性,但通过选择正确的配置项,可以优化系统性能和安全性。
... 模块管理和配置工具
为了管理这些模块和配置选项,有特定的工具可以帮助完成任务:
make menuconfig:提供了一个基于文本的菜单系统,可以进行交互式配置。make xconfig:提供一个基于Qt的图形用户界面。make gconfig:提供一个基于GTK的图形用户界面。
2.2 内核编译过程详解
2.2.1 获取内核源码
内核源码可以从官方Linux内核网站获取。使用wget命令是一个常见的方法:
- wget ***
此命令下载当前最新版本的内核源码。其中5.x.y代表具体的内核版本号。
2.2.2 配置内核选项
获取源码后,下一步是配置内核选项。这可以通过复制现有的配置文件开始,然后使用make menuconfig进行调整:
- cp /boot/config-$(uname -r) .config
- make menuconfig
这将启动一个文本用户界面,允许你选择需要或不需要的功能。
2.2.3 编译和安装内核
配置完成后,下一步是编译内核:
- make -j$(nproc)
使用-j$(nproc)选项可以并行处理编译过程,加快编译速度。
编译完成后,需要安装内核模块并创建一个初始内存磁盘映像:
- make modules_install
- make install
内核现在已编译并安装,重启后即可选择新内核启动。
... 制作内核启动项
编译内核后,需要在启动管理器(如GRUB)中添加启动项,以便在启动时选择新内核。GRUB配置文件通常位于/etc/grub.d/目录下,配置内容可能如下:
- menuentry 'Linux custom kernel' {
- linux /boot/vmlinuz-custom root=UUID=<your-uuid> ro
- initrd /boot/initrd.img-custom
- }
替换<your-uuid>为实际的根分区UUID。
2.3 理论与实践的结合
2.3.1 理解内核编译的必要性
内核编译的必要性在于能够精确控制系统行为,优化性能,并且提供针对性的安全加固。理解这一点对于任何希望高效利用系统资源的开发者和系统管理员来说都是至关重要的。
2.3.2 案例分析:编译一个定制内核
例如,如果一个系统是用于运行服务器,那么可能不需要支持所有硬件和文件系统的模块。通过定制编译内核,可以删除这些不必要的模块,从而减少内存占用和启动时间。
表2-1显示了在定制编译前后,内存占用和启动时间的变化:
| 内存占用 (MB) | 启动时间 (秒) | |
|---|---|---|
| 默认内核 | 500 | 30 |
| 定制内核 | 300 | 22 |
这是一个简化的案例,实际情况可能涉及更多的考量因素,如性能优化、硬件兼容性和特定的安全需求。
通过对内核编译过程的理论和实践学习,可以更好地理解如何定制一个适合特定需求的Linux系统。在下一章中,我们将探讨如何通过内核优化来进一步提升系统性能和安全性。
3. Kali Linux内核优化技巧
3.1 内核启动参数调整
3.1.1 启动参数的作用和配置
在Linux操作系统中,内核启动参数(Kernel Boot Parameters)是一种指定内核启动时的配置选项的方法。这些参数可以用来调整系统行为,优化性能,或者解决特定的问题。启动参数通常在启动加载器的配置文件中设置,例如在GRUB中,可以在/etc/default/grub文件中指定。
内核启动参数通常由一个或多个键值对组成,键和值通过等号(=)连接。例如,为了设置系统的主机名为myhostname,可以使用hostname=myhostname参数。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
CCProxy快速搭建秘籍:3步骤打造高效局域网代理
打造图书馆管理系统的性能巅峰:【数据流图优化】实战指南
资源优化策略深度探讨:优化Android ROM以提升性能
【流程图设计黄金法则】:ERP高效流程图构建指南
玖逸云黑系统安全无忧:专家级源码安全性分析
【ECDSA与传统签名算法大比拼】:深入了解ECDSA的核心优势和应用场景
模拟与数字信号处理:转换技术全攻略与应用案例精析
【安全先行】MySQL8.0 ROOT账户强化:9个技巧让你的数据库更安全
9030协议的可扩展性分析:构建支持大规模部署的协议架构


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )