【Python云存储实践】:boto3.s3.connection模块的多线程应用秘籍
发布时间: 2024-10-17 17:20:59 阅读量: 42 订阅数: 36 

LABVIEW程序实例-DS写属性数据.zip

# 1. Python云存储与boto3简介
## 1.1 云存储的基本概念
在当今的数据密集型世界中,云存储已成为IT基础设施的关键组成部分。云存储是一种通过互联网将数据存储在远程服务器上的服务,这些服务器由第三方服务提供商维护。与传统的本地存储相比,云存储提供了更高的可扩展性、可访问性和成本效益。
## 1.2 Python与云服务的结合
Python作为一种高级编程语言,以其简洁的语法和强大的库支持而闻名,非常适合与云服务进行交互。通过使用专门的库,如`boto3`,开发者可以轻松地编写代码来管理云资源,实现自动化操作和优化管理流程。
## 1.3 boto3简介
`boto3`是AWS(Amazon Web Services)官方提供的Python库,它允许开发者直接与AWS服务进行交互。使用`boto3`,可以管理多种AWS资源,包括S3(Simple Storage Service)、EC2(Elastic Compute Cloud)、Lambda等。在本文中,我们将重点介绍如何使用`boto3`操作S3,这是一个广泛用于存储和检索任意数量数据的云存储服务。
# 2. boto3.s3.connection模块核心功能
## 2.1 连接AWS S3服务
### 2.1.1 认证和授权
在本章节中,我们将深入探讨如何使用boto3库的s3.connection模块来连接AWS S3服务,并详细说明认证和授权的过程。boto3是AWS的官方SDK,它提供了一种简单且直接的方式来与AWS服务进行交互。对于S3服务来说,认证和授权是连接过程中的第一步,确保了只有被授权的用户才能访问或操作资源。
认证通常涉及到AWS的访问密钥和密钥ID,这些信息可以从AWS管理控制台中的安全凭证部分获取。授权则是指通过IAM(Identity and Access Management)角色或策略来决定用户可以访问哪些资源以及执行哪些操作。
为了安全起见,AWS推荐使用IAM角色而非直接将密钥存储在代码中。这样可以避免密钥泄露的风险,并且可以更灵活地管理访问权限。
### 2.1.2 创建连接实例
在了解了认证和授权的基本概念后,我们现在将演示如何创建一个连接实例。在boto3中,这可以通过调用`s3.connection.S3Connection`方法并传入认证信息来完成。
```python
import boto3
# 通过boto3创建S3连接实例
# 注意:在实际应用中,应避免硬编码密钥,推荐使用环境变量或IAM角色
access_key = 'YOUR_ACCESS_KEY'
secret_key = 'YOUR_SECRET_KEY'
s3_connection = boto3.s3.connection.S3Connection(
aws_access_key_id=access_key,
aws_secret_access_key=secret_key
)
```
在上述代码中,我们首先导入了boto3库,并使用我们从AWS控制台获取的`access_key`和`secret_key`创建了一个S3连接实例。在实际应用中,我们应当避免将这些敏感信息硬编码在代码中,而是使用环境变量或IAM角色来管理这些密钥。
创建连接实例后,我们就可以使用这个实例来操作S3服务,例如访问桶和对象、上传下载文件等。
## 2.2 操作S3对象和桶
### 2.2.1 桶的创建与管理
在本章节中,我们将介绍如何使用boto3的s3.connection模块来创建和管理AWS S3中的桶(Bucket)。桶是存储对象的容器,每个对象都位于特定的桶中。在创建桶之前,我们需要考虑地理位置、访问权限等因素,因为这些将影响到桶的性能和安全性。
### 创建桶
创建一个桶的基本步骤如下:
```python
# 创建一个桶
bucket = s3_connection.create_bucket('my-bucket-name', location='us-west-1')
```
在上述代码中,我们使用`s3_connection.create_bucket`方法创建了一个名为`my-bucket-name`的新桶,并指定其位置为`us-west-1`。请注意,桶的名称必须是全局唯一的,因此在尝试创建之前,你可能需要检查该名称是否已被占用。
### 管理桶的属性
创建桶后,我们可以设置桶的属性,例如访问控制列表(ACL)、存储类等。例如,我们可以设置桶的ACL为公开读取:
```python
# 设置桶的ACL为公开读取
bucket.set_acl('public-read')
```
通过设置不同的ACL,我们可以控制谁可以访问桶中的对象。例如,`public-read`表示任何人都可以读取桶中的对象,但只有桶的所有者可以写入对象。
### 2.2.2 文件的上传与下载
在本章节中,我们将深入探讨如何使用boto3的s3.connection模块来上传和下载S3对象。上传和下载文件是S3服务中最为常见的操作之一,对于构建各种应用程序至关重要。
#### 上传文件
上传文件到S3桶的基本步骤如下:
```python
# 上传文件到S3桶
file_path = '/path/to/local/file'
key = 'my-object-key'
with open(file_path, 'rb') as f:
bucket.upload_fileobj(f, key)
```
在上述代码中,我们首先指定了本地文件的路径`file_path`和在S3桶中对象的键`key`。然后,我们使用`bucket.upload_fileobj`方法将文件上传到S3桶。这里我们使用了`with`语句来打开文件,这样可以确保文件在上传后被正确关闭。
#### 下载文件
下载文件的基本步骤如下:
```python
# 下载文件从S3桶
file_path = '/path/to/local/file'
key = 'my-object-key'
with open(file_path, 'wb') as f:
bucket.download_fileobj(key, f)
```
在上述代码中,我们使用`bucket.download_fileobj`方法将S3桶中的对象下载到本地文件。同样地,我们使用了`with`语句来打开文件,确保文件在下载后被正确关闭。
## 2.3 高级特性探索
### 2.3.1 配置访问日志
在本章节中,我们将介绍如何使用boto3的s3.connection模块来配置S3桶的访问日志。访问日志可以帮助我们了解谁在何时访问了桶中的哪些对象,这对于安全审计和故障排查非常有用。
#### 开启访问日志
开启S3桶的访问日志的基本步骤如下:
```python
# 开启S3桶的访问日志
target_bucket = 'my-target-bucket' # 日志存储的桶名称
target_key = 'logs' # 日志对象的键前缀
bucket.enable_logging(bucket_name=target_bucket, key_prefix=target_key)
```
在上述代码中,我们使用`bucket.enable_logging`方法开启了访问日志功能。我们需要指定一个桶来存储日志文件(`target_bucket`),以及日志对象的键前缀(`target_key`)。日志文件将以`AWSLogs/[AWS账号ID]/[桶名称]/[日志对象前缀]`的形式存储。
### 2.3.2 设置生命周期规则
在本章节中,我们将探讨如何使用boto3的s3.connection模块来设置S3桶的生命周期规则。生命周期规则允许我们自动管理桶中对象的存储策略,例如将不再访问的对象转移到较低成本的存储类别,甚至删除它们。
#### 创建生命周期规则
创建生命周期规则的基本步骤如下:
```python
# 创建生命周期规则
lifecycle_configuration = {
'Rules': [
{
'ID': 'Rule-1',
'Filter': {
'Prefix': 'logs/' # 只对前缀为logs的对象应用此规则
},
'Status': 'Enabled',
'Transitions': [
{
'Days': 30,
'StorageClass': 'GLACIER'
}
]
}
]
}
bucket.put_lifecycle_configuration(LifecycleConfiguration=lifecycle_configuration)
```
在上述代码中,我们首先定义了一个包含规则的字典`lifecycle_configuration`。这个规则包含了一个ID、过滤器、状态以及转换设置。在这个例子中,我们指定了对象前缀为`logs/`的对象,在它们被创建30天后,将会被转换到更低成本的存储类别`GLACIER`。
然后,我们使用`bucket.put_lifecycle_configuration`方法将生命周期规则应用到桶上。这样设置后,S3会自动根据定义的规则来管理桶中的对象。
以上内容为第二章的核心部分,介绍了boto3.s3.connection模块的连接、操作、以及一些高级特性的使用。在实际应用中,这些知识对于管理和操作AWS S3服务是至关重要的。
# 3. boto3.s3.connection模块的多线程实践
## 4.1 设计多线程上传下载方案
### 4.1.1 分块上传策略
在处理大型文件上传到AWS S3时,分块上传是一种常见的优化策略。这种策略可以将大文件分成多个小块,每个小块可以并行上传,从而提高效率。boto3库提供了`TransferConfig`类,允许我们设置分块上传的参数。
在本章节中,我们将详细介绍如何使用`TransferConfig`来实现分块上传,并解释每个参数的作用。此外,我们还将探讨如何利用多线程来进一步提升上传速度。
#### 分块上传的基本原理
分块上传的基本原理是将大文件分割成多个小块(通常称为part),然后分别上传这些小块到S3。当所有小块都上传完成后,这些小块会被合并成一个完整的文件。这个过程对用户是透明的,用户只需要上传原始的大文件即可。
#### TransferConfig类参数详解
`TransferConfig`类提供了多个参数来控制分块上传的行为。以下是一些常用的参数:
- `multipart_chunksize`:每个分块的大小(以字节为单位)。默认值是8 MiB,可以根据需要调整,以便优化上传速度。
- `max_concurrency`:同时上传的线程数。默认值是5,可以根据网络状况和硬件性能调整。
- `multipart_threshold`:文件大小的阈值,低于此阈值将使用单一上传,而不是分块上传。默认值是8 MiB。
- `use_threads`:是否使用多线程进行分块上传。默认值为False。
#### 使用TransferConfig实现分块上传
以下是一个使用`TransferConfig`实现分块上传的示例代码:
```python
import boto3
from botocore.exceptions import ClientError
def upload_file_with_multipart(file_path, bucket, object_name=None):
if object_name is None:
object_name = file_path
# 创建S3客户端
s3_client = boto3.client('s3')
# 设置分块上传配置
transfer_config = boto3.s3.transfer.TransferConfig(
multipart_chunksize=8 * 1024 * 1024, # 8 MiB
max_concurrency=5,
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 库 boto3.s3.connection,旨在帮助您掌握高效连接 AWS S3 的秘诀。从连接管理的基础知识到高级特性,如安全连接、访问控制、故障排除和性能优化,该专栏提供了全面的指导。通过深入的分析、实战案例和最佳实践,您将了解如何利用 boto3.s3.connection 模块构建高效、可扩展的云存储解决方案。涵盖的主题包括连接池、自定义扩展、事件处理、多线程应用和高级功能,如跨区域复制和数据迁移。本专栏适合希望精通 boto3.s3.connection 模块并充分利用其功能的 Python 开发人员和云存储专业人士。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
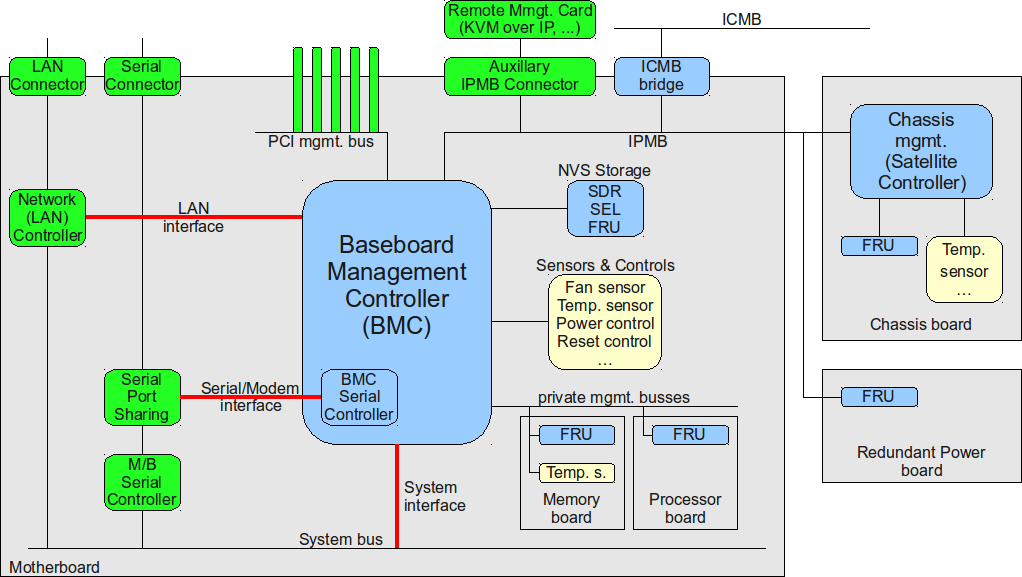
IPMI标准V2.0与物联网:实现智能设备自我诊断的五把钥匙
# 摘要
本文旨在深入探讨IPMI标准V2.0在现代智能设备中的应用及其在物联网环境下的发展。首先概述了IPMI标准V2.0的基本架构和核心理论,重点分析了其安全机制和功能扩展。随后,本文讨论了物联网设备自我诊断的必要性,并展示了IPMI标准V2.0在智能硬件设备和数据中心健康管理中的应用实例。最后,本文提出了实现智能设备IPMI监控系统的设计与开发指南,
【EDID兼容性高级攻略】:跨平台显示一致性的秘诀

# 摘要
电子显示识别数据(EDID)是数字视频接口中用于描述显示设备特性的标准数据格式。本文全面介绍了EDID的基本知识、数据结构以及兼容性问题的诊断与解决方法,重点关注了数据的深度解析、获取和解析技术。同时,本文探讨了跨平台环境下EDID兼容性管理和未来技术的发展趋势,包括增强型EDID标准的发展和自动化配置工具的前景。通过案例研究与专家建议,文章提供了在多显示器设置和企业级显示管理中遇到的ED
PyTorch张量分解技巧:深度学习模型优化的黄金法则

# 摘要
PyTorch张量分解技巧在深度学习领域具有重要意义,本论文首先概述了张量分解的概念及其在深度学习中的作用,包括模型压缩、加速、数据结构理解及特征提取。接着,本文详细介绍了张量分解的基础理论,包括其数学原理和优化目标,随后探讨了在PyTorch中的操作实践,包括张量的创建、基本运算、分解实现以及性能评估。论文进一步深入分析了张量分解在深度学习模型中的应用实例,展示如何通过张量分解技术实现模型
【参数校准艺术】:LS-DYNA材料模型方法与案例深度分析
# 摘要
本文全面探讨了LS-DYNA软件在材料模型参数校准方面的基础知识、理论、实践方法及高级技术。首先介绍了材料模型与参数校准的基础知识,然后深入分析了参数校准的理论框架,包括理论与实验数据的关联以及数值方法的应用。文章接着通过实验准备、模拟过程和案例应用详细阐述了参数校准的实践方法。此外,还探
系统升级后的验证:案例分析揭秘MAC地址修改后的变化

# 摘要
本文系统地探讨了MAC地址的基础知识、修改原理、以及其对网络通信和系统安全性的影响。文中详细阐述了软件和硬件修改MAC地址的方法和原理,并讨论了系统升级对MAC地址可能产生的变化,包括自动重置和保持不变的情况。通过案例分析,本文进一步展示了修改MAC地址后进行系统升级的正反两面例子。最后,文章总结了当前研究,并对今后关于MAC地址的研究方向进行了展望。
# 关键字
华为交换机安全加固:5步设置Telnet访问权限
# 摘要
随着网络技术的发展,华为交换机在企业网络中的应用日益广泛,同时面临的安全威胁也愈加复杂。本文首先介绍了华为交换机的基础知识及其面临的安全威胁,然后深入探讨了Telnet协议在交换机中的应用以及交换机安全设置的基础知识,包括用户认证机制和网络接口安全。接下来,文章详细说明了如何通过访问控制列表(ACL)和用户访问控制配置来实现Telnet访问权限控制,以增强交换机的安全性。最后,通过具体案例分析,本文评估了安
【软硬件集成测试策略】:4步骤,提前发现并解决问题
# 摘要
软硬件集成测试是确保产品质量和稳定性的重要环节,它面临诸多挑战,如不同类型和方法的选择、测试环境的搭建,以及在实践操作中对测试计划、用例设计、缺陷管理的精确执行。随着技术的进步,集成测试正朝着性能、兼容性和安全性测试的方向发展,并且不断优化测试流程和数据管理。未来趋势显示,自动化、人工智能和容器化等新兴技术的应用,将进一步提升测试效率和质量。本文系统地分析了集成测试的必要性、理论基础、实践操作
CM530变频器性能提升攻略:系统优化的5个关键技巧

# 摘要
本文综合介绍了CM530变频器在硬件与软件层面的优化技巧,并对其性能进行了评估。首先概述了CM530的基本功能与性能指标,然后深入探讨了硬件升级方案,包括关键硬件组件选择及成本效益分析,并提出了电路优化和散热管理的策略。在软件配置方面,文章讨论了软件更新流程、固件升级准备、参数调整及性能优化方法。系统维护与故障诊断部分提供了定期维护的策略和故障排除技巧。最后,通过实战案例分析,展示了CM530在特定应用中的优化效果,并对未来技术发展和创新
CMOS VLSI设计全攻略:从晶体管到集成电路的20年技术精华
# 摘要
本文对CMOS VLSI设计进行了全面概述,从晶体管级设计基础开始,详细探讨了晶体管的工作原理、电路模型以及逻辑门设计。随后,深入分析了集成电路的布局原则、互连设计及其对信号完整性的影响。文章进一步介绍了高级CMOS电路技术,包括亚阈值电路设计、动态电路时序控制以及低功耗设计技术。最后,通过VLSI设计实践和案例分析,阐述了设计流程、
三菱PLC浮点数运算秘籍:精通技巧全解

# 摘要
本文系统地介绍了三菱PLC中浮点数运算的基础知识、理论知识、实践技巧、高级应用以及未来展望。首先,文章阐述了浮点数运算的基础和理论知识,包括表示方法、运算原理及特殊情况的处理。接着,深入探讨了三菱PLC浮点数指令集、程序设计实例以及调试与优化方法。在高级应用部分,文章分析了浮点数与变址寄存器的结合、高级算法应用和工程案例。最后,展望了三菱PLC浮点数运算技术的发展趋势,以及与物联网的结合和优化
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )